本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
設計 GraphQL 結構描述GraphQL 結構描述是任何 GraphQL 伺服器實作的基礎。每個 GraphQL API 都由單一結構描述定義,其中包含描述請求資料如何填入的類型和欄位。流經 API 的資料和執行的操作必須針對結構描述進行驗證。
一般而言,GraphQL 類型系統會描述 GraphQL 伺服器的功能,並用來判斷查詢是否有效。伺服器類型系統通常稱為該伺服器的結構描述,可包含不同的物件類型、純量類型、輸入類型等。GraphQL 是宣告式和強式類型,這表示類型將在執行時間妥善定義,並且只會傳回指定的類型。
AWS AppSync 可讓您定義和設定 GraphQL 結構描述。下一節說明如何使用 AWS AppSync的服務從頭開始建立 GraphQL 結構描述。
建構 GraphQL 結構描述
GraphQL 是實作 API 服務的強大工具。根據 GraphQL 的網站,GraphQL 如下:
「GraphQL 是 APIs的查詢語言,也是使用現有資料完成這些查詢的執行時間。GraphQL 提供 API 中資料的完整且易於理解的描述,讓用戶端能夠詢問他們確切需要什麼,什麼都不做,讓隨著時間發展 APIs 變得更容易,並啟用強大的開發人員工具。」
本節涵蓋 GraphQL 實作的第一部分:結構描述。使用上述引號,結構描述扮演「提供 API 中資料的完整且可理解描述」的角色。換言之,GraphQL 結構描述是服務資料、操作及其之間關係的文字表示。結構描述會被視為 GraphQL 服務實作的主要進入點。令人意外的是,這通常是您在專案中做的第一件事之一。建議您先檢閱結構描述區段,再繼續。
若要引用結構描述區段,GraphQL 結構描述會以結構描述定義語言 (SDL) 撰寫。SDL 由具有已建立結構的類型和欄位組成:
-
類型:類型是 GraphQL 如何定義資料的形狀和行為。GraphQL 支援多種類型,稍後將在本節中說明。結構描述中定義的每個類型都會包含自己的範圍。在範圍內,一個或多個欄位可以包含 GraphQL 服務中使用的值或邏輯。類型會填入許多不同的角色,最常見的是物件或純量 (基本值類型)。
-
欄位:欄位存在於 類型的範圍內,並保留從 GraphQL 服務請求的值。這些與其他程式設計語言的變數非常相似。您在欄位中定義的資料形狀將決定資料在請求/回應操作中的結構。這可讓開發人員預測傳回的內容,而不知道服務的後端如何實作。
最簡單的結構描述將包含三種不同的資料類別:
-
結構描述根目錄:根目錄定義結構描述的進入點。它指向將對資料執行一些操作的欄位,例如新增、刪除或修改某個項目。
-
類型:這些是用來代表資料形狀的基本類型。您幾乎可以將這些視為物件或具有定義特性之物件的抽象表示法。例如,您可以製作代表資料庫中人員的Person物件。每個人的特性都會Person在 中定義為 欄位。它們可以是人員的名稱、年齡、工作、地址等。
-
特殊物件類型:這些是定義結構描述中操作行為的類型。每個特殊物件類型在每個結構描述中定義一次。它們會先放置在結構描述根目錄,然後在結構描述內文中定義。特殊物件類型中的每個欄位都會定義您的解析程式要實作的單一操作。
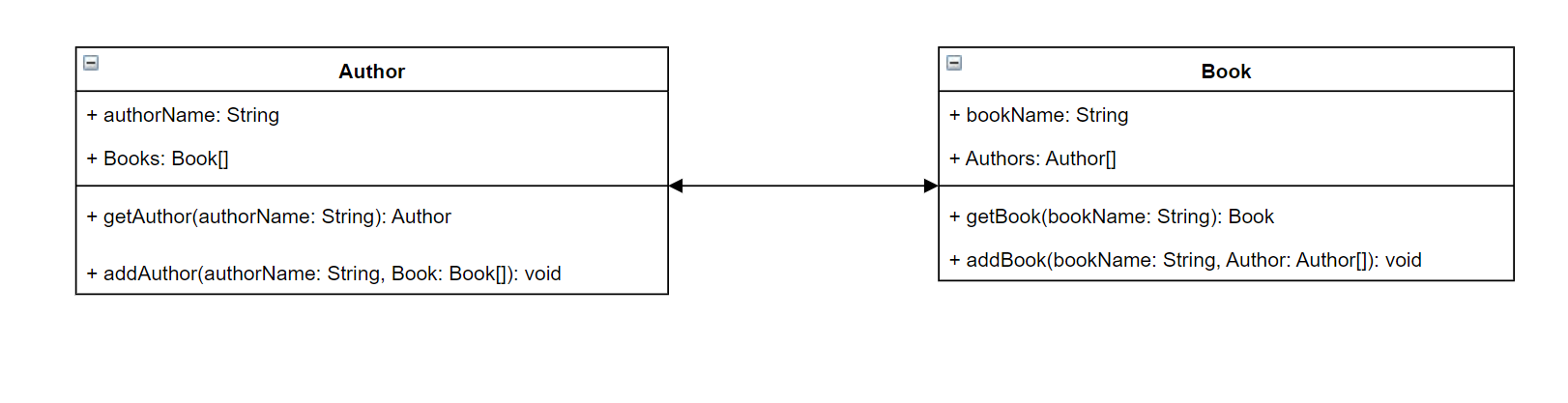
假設您正在建立可存放作者和他們所撰寫書籍的服務,以將其納入考量。每個作者都有一個名稱和他們撰寫的書籍陣列。每本書都有一個名稱和相關聯的作者清單。我們也希望能夠新增或擷取書籍和作者。此關係的簡單 UML 表示方式可能如下所示:
在 GraphQL 中,實體Author和 Book代表結構描述中的兩種不同的物件類型:
type Author {
}
type Book {
}
Author 包含 authorName和 Books,而 Book包含 bookName和 Authors。這些可以表示為您類型範圍內的欄位:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
如您所見,類型表示法非常接近圖表。不過,這些方法會變得較棘手。這些將放置在幾個特殊物件類型之一做為欄位。它們的特殊物件分類取決於其行為。GraphQL 包含三種基本的特殊物件類型:查詢、變動和訂閱。如需詳細資訊,請參閱特殊物件。
由於 getAuthor和 getBook 都是請求資料,因此它們會放置在Query特殊物件類型中:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
操作會連結至查詢,而查詢本身會連結至結構描述。新增結構描述根將定義特殊物件類型 (Query在此案例中為 ) 做為其中一個進入點。您可以使用 schema關鍵字來完成此操作:
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
查看最後兩種方法,addAuthoraddBook並將資料新增至您的資料庫,因此它們將以Mutation特殊物件類型定義。不過,從類型頁面,我們也知道不允許直接參考物件的輸入,因為它們是嚴格輸出類型。在這種情況下,我們無法使用 Author或 Book,因此我們需要使用相同的欄位建立輸入類型。在此範例中,我們新增了 AuthorInput和 BookInput,兩者都接受其各自類型的相同欄位。然後,我們使用輸入做為參數來建立變動:
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
讓我們檢閱剛執行的操作:
-
我們已使用 Book和 Author類型建立結構描述,以代表我們的實體。
-
我們新增了包含實體特性的欄位。
-
我們新增了查詢,以從資料庫擷取此資訊。
-
我們新增了變動來操作資料庫中的資料。
-
我們新增輸入類型來取代變動中的物件參數,以符合 GraphQL 的規則。
-
我們已將查詢和變動新增至根結構描述,以便 GraphQL 實作了解根類型位置。
如您所見,建立結構描述的程序通常需要資料建模 (特別是資料庫建模) 的許多概念。您可以將結構描述視為符合來源資料的形狀。它也可以做為解析程式將實作的模型。在下列各節中,您將了解如何使用各種 AWS支援的工具和服務建立結構描述。
以下各節中的範例並非要在真正的應用程式中執行。它們只用來展示命令,因此您可以建置自己的應用程式。
建立結構描述
您的結構描述將位於名為 schema.graphql. AWS AppSync 的檔案中,允許使用者使用各種方法為其 GraphQL APIs 建立新的結構描述。在此範例中,我們將建立空白 API 以及空白結構描述。
- Console
-
-
登入 AWS 管理主控台 並開啟 AppSync 主控台。
-
在儀表板上,選擇 Create API (建立 API)。
-
在 API 選項下,選擇 GraphQL APIs、從頭開始設計,然後選擇下一步。
-
針對 API 名稱,請將預先填入的名稱變更為應用程式所需的名稱。
-
如需聯絡詳細資訊,您可以輸入聯絡點來識別 API 的管理員。此為選用欄位。
-
在私有 API 組態下,您可以啟用私有 API 功能。私有 API 只能從設定的 VPC 端點 (VPCE) 存取。如需詳細資訊,請參閱私有 APIs。
不建議在此範例中啟用此功能。檢閱您的輸入後,請選擇下一步。
-
在建立 GraphQL 類型下,您可以選擇建立 DynamoDB 資料表以用作資料來源,或略過此項目並在稍後執行。
在此範例中,選擇稍後建立 GraphQL 資源。我們將在單獨的區段中建立資源。
-
檢閱您的輸入,然後選擇建立 API。
-
您將位於特定 API 的儀表板中。您可以指出 ,因為 API 的名稱會位於儀表板頂端。如果不是這種情況,您可以在 Sidebar 中選取 APIs,然後在 API 儀表板中選擇您的 APIs。
-
在 API 名稱下方的 Sidebar 中,選擇結構描述。
-
在結構描述編輯器中,您可以設定 schema.graphql 檔案。它可以是空的或填滿從模型產生的類型。在右側,您有將解析程式連接至結構描述欄位的解析程式區段。我們不會在本節中查看解析程式。
- CLI
-
-
如果您尚未這麼做,請 AWS 安裝 CLI,然後新增您的組態。
-
執行 create-graphql-api命令來建立 GraphQL API 物件。
您需要為此特定命令輸入兩個參數:
-
您 API name的 。
-
authentication-type,或用於存取 API 的登入資料類型 (IAM、OIDC 等)。
Region 必須設定 等其他參數,但通常會預設為您的 CLI 組態值。
範例命令可能如下所示:
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
輸出會在 CLI 中傳回。範例如下:
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
這是選用的命令,採用現有的結構描述,並使用 base-64 Blob 將其上傳至 AWS AppSync 服務。基於此範例,我們不會使用此命令。
執行 start-schema-creation 命令。
您需要為此特定命令輸入兩個參數:
-
上一個步驟api-id的 。
-
結構描述definition是 base-64 編碼的二進位 Blob。
範例命令可能如下所示:
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
將傳回輸出:
{
"status": "PROCESSING"
}
此命令不會在處理後傳回最終輸出。您必須使用單獨的命令 get-schema-creation-status來查看結果。請注意,這兩個命令是非同步的,因此即使結構描述仍在建立中,您也可以檢查輸出狀態。
- CDK
-
-
CDK 的起點略有不同。理想情況下,應該已建立您的schema.graphql檔案。您只需要使用副檔名建立新的.graphql檔案。這可以是空白檔案。
-
一般而言,您可能需要將匯入指令新增至您正在使用的服務。例如,它可能會遵循以下表單:
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
若要新增 GraphQL API,您的堆疊檔案需要匯入 AWS AppSync 服務:
import * as appsync from 'aws-cdk-lib/aws-appsync';
這表示我們正在appsync關鍵字下匯入整個服務。若要在您的應用程式中使用此功能,您的 AWS AppSync 建構會使用 格式 appsync.construct_name。例如,如果我們想要製作 GraphQL API,我們會說 new appsync.GraphqlApi(args_go_here)。下列步驟描述了這一點。
-
最基本的 GraphQL API 將包含 name API 和 schema 路徑的 。
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
讓我們檢閱此程式碼片段的功能。在 範圍內api,我們呼叫 來建立新的 GraphQL APIappsync.GraphqlApi(scope: Construct, id: string, props: GraphqlApiProps)。範圍為 this,是指目前的物件。ID 是 API_ID,其將在建立 CloudFormation 時做為 GraphQL API 的資源名稱。GraphqlApiProps 包含 GraphQL API name的 和 schema。schema 將透過搜尋.graphql檔案的絕對路徑 (SchemaFile.fromAsset) (schema_name.graphql) 來產生結構描述 (__dirname)。在實際案例中,您的結構描述檔案可能位於 CDK 應用程式內。
若要使用對 GraphQL API 所做的變更,您必須重新部署應用程式。
將類型新增至結構描述
現在您已新增結構描述,您可以開始同時新增輸入和輸出類型。請注意,此處的類型不應用於真實程式碼;它們只是協助您了解程序的範例。
首先,我們會建立物件類型。在真實程式碼中,您不需要從這些類型開始。只要您遵循 GraphQL 的規則和語法,您可以隨時進行您想要的類型。
接下來的幾個區段將使用結構描述編輯器,因此請保持開啟狀態。
- Console
-
-
您可以使用 type關鍵字以及 類型的名稱來建立物件類型:
type Type_Name_Goes_Here {}
在類型範圍內,您可以新增代表物件特性的欄位:
type Type_Name_Goes_Here {
# Add fields here
}
範例如下:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
在此步驟中,我們新增了一個一般物件類型,其中包含存放為 的必要id欄位ID、存放為 title的欄位String,以及存放為 date的欄位AWSDateTime。若要查看類型和欄位清單及其用途,請參閱結構描述。若要查看純量清單及其用途,請參閱類型參考。
- CLI
-
-
您可以執行 create-type命令來建立物件類型。
您需要為此特定命令輸入幾個參數:
-
您 API api-id的 。
-
definition或 類型的內容。在主控台範例中,這是:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
您輸入的 format 。在此範例中,我們使用 SDL。
範例命令可能如下所示:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
輸出會在 CLI 中傳回。範例如下:
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
在此步驟中,我們新增了一個一般物件類型,其中包含存放為 的必要id欄位ID、存放為 title的欄位String,以及存放為 date的欄位AWSDateTime。若要查看類型和欄位清單及其用途,請參閱結構描述。若要查看純量清單及其用途,請參閱類型參考。
另請注意,您可能已意識到輸入定義直接適用於較小的類型,但無法用於新增較大的或多種類型。您可以選擇在.graphql檔案中新增所有內容,然後將其做為輸入傳遞。
- CDK
-
若要新增類型,您需要將其新增至您的 .graphql 檔案。例如,主控台範例為:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
您可以將類型直接新增至結構描述,就像任何其他檔案一樣。
若要使用對 GraphQL API 所做的變更,您必須重新部署應用程式。
物件類型具有純量類型的欄位,例如字串和整數。 AWS AppSync 也可讓您除了基本 GraphQL 純量AWSDateTime之外,使用 等增強純量類型。此外,結尾為驚嘆號的任何欄位都是必要的。
特別是ID純量類型是唯一識別符,可以是 String或 Int。您可以在解析程式程式碼中控制這些項目以進行自動指派。
特殊物件類型之間有相似之處,例如 Query和上述範例的「一般」物件類型,因為它們都使用type關鍵字並被視為物件。不過,對於特殊物件類型 (Query、 和 Subscription)Mutation,其行為非常不同,因為它們會公開為 API 的進入點。它們也與塑造操作而非資料有關。如需詳細資訊,請參閱查詢和變動類型。
在特殊物件類型的主題上,下一個步驟可能是新增一或多個物件,以對形狀資料執行操作。在實際案例中,每個 GraphQL 結構描述至少必須具有請求資料的根查詢類型。您可以將查詢視為 GraphQL 伺服器的其中一個進入點 (或端點)。讓我們新增查詢做為範例。
- Console
-
-
若要建立查詢,只需將其新增至結構描述檔案,就像任何其他類型一樣。查詢需要Query類型和根目錄中的項目,如下所示:
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
請注意,生產環境中的 Name_of_Query Query 在大多數情況下只會被呼叫。我們建議將其保留在此值。在查詢類型中,您可以新增欄位。每個欄位都會在請求中執行 操作。因此,如果不是全部,這些欄位大部分都會連接到解析程式。不過,我們在本節中並不關心這一點。關於欄位操作的格式,可能如下所示:
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
範例如下:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
在此步驟中,我們新增了 Query類型,並將其定義在我們的schema根目錄中。我們的Query類型定義了傳回Obj_Type_1物件清單getObj的欄位。請注意, Obj_Type_1是上一個步驟的物件。在生產程式碼中,您的欄位操作通常會使用 這類物件所塑造的資料Obj_Type_1。此外, 等欄位getObj通常會有解析程式來執行商業邏輯。這將在不同的章節中涵蓋。
另請注意, 會在匯出期間 AWS AppSync 自動新增結構描述根目錄,因此在技術上您不需要將其直接新增至結構描述。我們的服務會自動處理重複的結構描述。我們將這裡新增為最佳實務。
- CLI
-
-
執行 create-type命令,以建立具有 query定義的schema根目錄。
您需要為此特定命令輸入幾個參數:
-
您 API api-id的 。
-
definition或 類型的內容。在主控台範例中,這是:
schema {
query: Query
}
-
您輸入的 format 。在此範例中,我們使用 SDL。
範例命令可能如下所示:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
輸出會在 CLI 中傳回。範例如下:
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
請注意,如果您未在create-type命令中正確輸入內容,您可以執行 update-type命令來更新結構描述根目錄 (或結構描述中的任何類型)。在此範例中,我們將暫時變更結構描述根目錄以包含subscription定義。
您需要為此特定命令輸入幾個參數:
-
您 API api-id的 。
-
type-name 您 類型的 。在主控台範例中,這是 schema。
-
definition或 類型的內容。在主控台範例中,這是:
schema {
query: Query
}
新增 後的結構描述subscription如下所示:
schema {
query: Query
subscription: Subscription
}
-
您輸入的 format 。在此範例中,我們使用 SDL。
範例命令可能如下所示:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
輸出會在 CLI 中傳回。範例如下:
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
在此範例中,新增預先格式化的檔案仍然有效。
-
執行 create-type命令來建立 Query 類型。
您需要為此特定命令輸入幾個參數:
-
您 API api-id的 。
-
definition或 類型的內容。在主控台範例中,這是:
type Query {
getObj: [Obj_Type_1]
}
-
您輸入的 format 。在此範例中,我們使用 SDL。
範例命令可能如下所示:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
輸出會在 CLI 中傳回。範例如下:
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
在此步驟中,我們新增了 Query類型,並將其定義在您的schema根目錄中。我們的Query類型定義了傳回Obj_Type_1物件清單getObj的欄位。
在schema根碼 中query: Query, query:部分表示已在結構描述中定義查詢,而 Query部分表示實際的特殊物件名稱。
- CDK
-
您需要將查詢和結構描述根新增至 .graphql 檔案。我們的範例看起來像以下範例,但您會想要將其取代為實際的結構描述程式碼:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
您可以將類型直接新增至結構描述,就像任何其他檔案一樣。
更新結構描述根目錄是選用的。我們在此範例中新增了此範例做為最佳實務。
若要使用對 GraphQL API 所做的變更,您必須重新部署應用程式。
您現在已看到建立物件和特殊物件 (查詢) 的範例。您也會看到如何互相連結來描述資料和操作。您可以只具有資料描述和一或多個查詢的結構描述。不過,我們希望新增另一個操作,將資料新增至資料來源。我們會新增另一個名為 的特殊物件類型Mutation來修改資料。
- Console
-
-
變動將稱為 Mutation。如同 Query,內部的欄位操作Mutation將描述 操作,並將連接到解析程式。此外,請注意,我們需要在schema根中定義它,因為它是一種特殊的物件類型。以下是變動的範例:
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
典型的變動會在根目錄中列出,例如查詢。變動是使用type關鍵字和名稱來定義。Name_of_Mutation 通常稱為 Mutation,因此我們建議您以這種方式保留它。每個欄位也會執行 操作。關於欄位操作的格式,可能如下所示:
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
範例如下:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
在此步驟中,我們新增了具有 addObj 欄位的Mutation類型。讓我們總結此欄位的功能:
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
addObj 正在使用 Obj_Type_1 物件來執行 操作。這是顯而易見的,因為 欄位,但語法在: Obj_Type_1傳回類型中證明這一點。在 中addObj,它接受Obj_Type_1來自 物件的 title、 id和 date 欄位做為參數。如您所見,它看起來很像方法宣告。不過,我們尚未說明方法的行為。如前所述,結構描述只會用來定義資料和操作的內容,而不是它們的運作方式。當我們建立第一個解析程式時,實作實際的商業邏輯會稍後出現。
完成結構描述後,您可以選擇將其匯出為 schema.graphql 檔案。在結構描述編輯器中,您可以選擇匯出結構描述,以支援的格式下載檔案。
另請注意, 會在匯出期間 AWS AppSync 自動新增結構描述根目錄,因此在技術上您不需要將其直接新增至結構描述。我們的服務會自動處理重複的結構描述。我們將這裡新增為最佳實務。
- CLI
-
-
執行 update-type命令來更新您的根結構描述。
您需要為此特定命令輸入幾個參數:
-
您 API api-id的 。
-
type-name 您 類型的 。在主控台範例中,這是 schema。
-
definition或 類型的內容。在主控台範例中,這是:
schema {
query: Query
mutation: Mutation
}
-
您輸入的 format 。在此範例中,我們使用 SDL。
範例命令可能如下所示:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
輸出會在 CLI 中傳回。範例如下:
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
執行 create-type命令來建立 Mutation 類型。
您需要為此特定命令輸入幾個參數:
-
您 API api-id的 。
-
definition或 類型的內容。在主控台範例中,這是
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
您輸入的 format 。在此範例中,我們使用 SDL。
範例命令可能如下所示:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
輸出會在 CLI 中傳回。範例如下:
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
您需要將查詢和結構描述根新增至 .graphql 檔案。我們的範例看起來像以下範例,但您會想要將其取代為實際的結構描述程式碼:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
更新結構描述根目錄是選用的。我們將此範例新增為最佳實務。
若要使用對 GraphQL API 所做的變更,您必須重新部署應用程式。
選用考量 - 使用列舉做為狀態
此時,您知道如何建立基本結構描述。不過,您可以新增許多項目來增加結構描述的功能。在應用程式中發現的一個常見情況是使用列舉做為狀態。您可以使用列舉來強制在呼叫時選擇一組值中的特定值。這對您知道不會長時間發生劇烈變化的事物來說非常有用。假設我們可以新增列舉,在回應中傳回狀態碼或字串。
例如,假設我們製作的社交媒體應用程式正在後端儲存使用者的文章資料。我們的結構描述包含代表個別文章資料的Post類型:
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
我們的 Post 將包含一個唯一的 id、貼文 title和一個名為 date的列舉PostStatus,代表應用程式處理貼文時的狀態。對於我們的操作,我們將有一個查詢,會傳回所有文章資料:
type Query {
getPosts: [Post]
}
我們也會有一個變動,將文章新增至資料來源:
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
查看我們的結構描述,PostStatus列舉可能有數種狀態。我們可能會希望名為 success(已成功處理文章)、 pending (正在處理文章) 和 error(無法處理文章) 的三個基本狀態。若要新增列舉,我們可以執行下列動作:
enum PostStatus {
success
pending
error
}
完整的結構描述可能如下所示:
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
如果使用者Post在應用程式中新增 ,則會呼叫 addPost操作來處理該資料。當連接至 的解析程式addPost處理資料時,它會持續更新poststatus具有 操作狀態的 。查詢時, Post將包含資料的最終狀態。請記住,我們只會描述我們希望資料在結構描述中的運作方式。我們假設許多有關 解析程式的實作 (將實作實際的商業邏輯來處理資料以滿足請求)。
選用考量 - 訂閱
訂閱 in AWS AppSync 會叫用為變動的回應。您可利用結構描述之中的 Subscription 類型及 @aws_subscribe() 指令進行設定,表示哪些變動用於叫用一項以上的訂閱。如需設定訂閱的詳細資訊,請參閱即時資料。
選用考量 - 關係和分頁
假設您在 DynamoDB 資料表中Posts存放了一百萬個資料,而且您想要傳回其中一些資料。不過,上述提供的範例查詢只會傳回所有文章。您不會想要在每次提出請求時擷取所有這些項目。反之,您會想要分頁它們。請對結構描述進行下列變更:
-
在 getPosts欄位中,新增兩個輸入引數: nextToken(迭代器) 和 limit(迭代限制)。
-
新增包含 Posts(擷取Post物件清單) 和 nextToken(迭代器) 欄位的新PostIterator類型。
-
變更 ,getPosts使其傳回 PostIterator ,而不是Post物件清單。
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
PostIterator 類型可讓您傳回Post物件清單的一部分,以及nextToken用於取得下一個部分的 。在 中PostIterator,有一個使用分頁字符 ([Post]) 傳回Post的項目清單 (nextToken)。In AWS AppSync,這會透過解析程式連接到 Amazon DynamoDB,並自動產生為加密字符。這會將 limit 引數的值轉換成 maxResults 參數,並將 nextToken 引數轉換成 exclusiveStartKey 參數。如需 AWS AppSync 主控台中的範例和內建範本範例,請參閱解析程式參考 (JavaScript)。