Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen Sie ein Studio-Notebook mit Amazon MSK
In diesem Tutorial wird beschrieben, wie Sie ein Studio-Notebook erstellen, das einen Amazon-MSK-Cluster als Quelle verwendet.
Dieses Tutorial enthält die folgenden Abschnitte:
Einen Amazon MSK-Cluster einrichten
Für dieses Tutorial benötigen Sie einen Amazon-MSK-Cluster, der Klartextzugriff ermöglicht. Wenn Sie noch keinen Amazon MSK-Cluster eingerichtet haben, folgen Sie dem Tutorial Erste Schritte mit Amazon MSK, um eine Amazon VPC, einen Amazon MSK-Cluster, ein Thema und eine Amazon EC2-Client-Instance zu erstellen.
Gehen Sie beim Befolgen des Tutorials wie folgt vor:
Ändern Sie in Schritt 3: Amazon MSK-Cluster erstellen bei Schritt 4 den
ClientBroker-Wert vonTLSaufPLAINTEXT.
Fügen Sie Ihrer VPC ein NAT-Gateway hinzu
Wenn Sie einen Amazon MSK-Cluster erstellt haben, indem Sie dem Tutorial Erste Schritte mit Amazon MSK gefolgt sind, oder wenn Ihre bestehende Amazon VPC noch kein NAT-Gateway für ihre privaten Subnetze hat, müssen Sie Ihrer Amazon VPC ein NAT-Gateway hinzufügen. Das folgende Diagramm zeigt die Architektur.
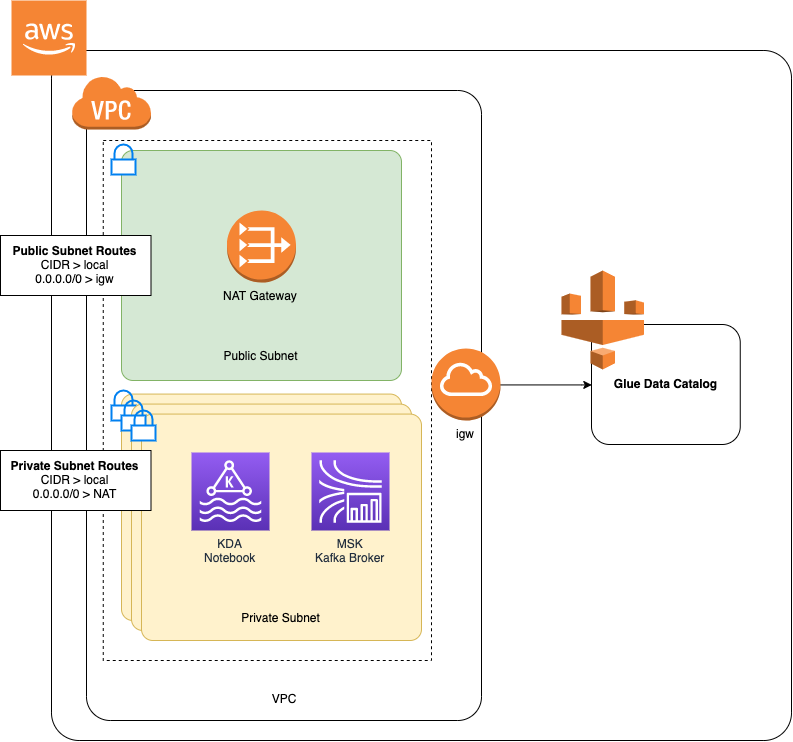
Gehen Sie wie folgt vor, um ein NAT-Gateway für Ihre Amazon VPC zu erstellen:
Öffnen Sie die Amazon-VPC-Konsole unter https://console.aws.amazon.com/vpc/
. Wählen Sie in der linken Navigationsleiste NAT-Gateway aus.
Wählen Sie auf der Seite NAT-Gateways die Option NAT-Gateway erstellen aus.
Geben Sie auf der Seite NAT-Gateway erstellen die folgenden Werte an:
Name — optional ZeppelinGatewaySubnetz AWS KafkaTutorialSubnet1 Elastische IP-Zuweisungs-ID Wählen Sie eine verfügbare Elastic IP aus. Wenn keine Elastic IPs verfügbar sind, wählen Sie Allocate Elastic IP und dann die Elastic IP aus, die die Konsole erstellt. Wählen Sie NAT-Gateway erstellen aus.
Wählen Sie in der linken Navigationsleiste Routing-Tabellen aus.
Klicken Sie auf Create Route Table (Routing-Tabelle erstellen).
Geben Sie auf der Seite Routing-Tabelle erstellen folgende Informationen ein:
Name-Tag:
ZeppelinRouteTableVPC: Wählen Sie Ihre VPC (z. B. AWS KafkaTutorialVPC).
Wählen Sie Erstellen aus.
Wählen Sie in der Liste der Routentabellen. ZeppelinRouteTable Klicken Sie auf der Registerkarte Routen auf Routen bearbeiten.
Wählen Sie auf der Seite Routen bearbeiten die Option Route hinzufügen aus.
Geben Sie im Für-Ziel
0.0.0.0/0ein. Wählen Sie für Target die Option NAT Gateway, ZeppelinGateway. Wählen Sie Routen speichern aus. Klicken Sie auf Schließen.Wählen Sie auf der Seite Routing-Tabellen die ZeppelinRouteTableOption „Subnetzzuordnungen“ aus. Wählen Sie Subnetzzuordnungen bearbeiten aus.
Wählen Sie auf der Seite Subnetzzuordnungen bearbeiten die Option und aus AWS KafkaTutorialSubnet2. AWS KafkaTutorialSubnet3 Wählen Sie Speichern.
Erstellen Sie eine AWS Glue Verbindung und eine Tabelle
Ihr Studio-Notebook verwendet eine AWS Glue-Datenbank für Metadaten zu Ihrer Amazon MSK-Datenquelle. In diesem Abschnitt erstellen Sie eine AWS Glue Verbindung, die beschreibt, wie Sie auf Ihren Amazon MSK-Cluster zugreifen können, und eine AWS Glue Tabelle, die beschreibt, wie Sie die Daten in Ihrer Datenquelle für Clients wie Ihr Studio-Notebook präsentieren.
Eine Verbindung erstellen
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die AWS Glue Konsole unter https://console.aws.amazon.com/glue/
. Wenn Sie noch keine AWS Glue Datenbank haben, wählen Sie in der linken Navigationsleiste Datenbanken aus. Wählen Sie Datenbank hinzufügen. Geben Sie im Fenster Datenbank hinzufügen
defaultals Namen der Datenbank ein. Wählen Sie Erstellen aus.Wählen Sie in der linken Navigationsleiste Verbindungen aus. Wählen Sie Verbindung hinzufügen aus.
Geben Sie im Fenster Verbindung hinzufügen die folgenden Werte ein:
Geben Sie für Verbindungsname
ZeppelinConnectionein.Wählen Sie für Verbindungstyp den Eintrag Kafka.
Geben Sie für Kafka-Bootstrap-Server-URLs die Bootstrap-Broker-Zeichenfolge für Ihren Cluster an. Sie können die Bootstrap-Broker entweder über die MSK-Konsole oder durch Eingabe des folgenden CLI-Befehls abrufen:
aws kafka get-bootstrap-brokers --region us-east-1 --cluster-arnClusterArnDeaktivieren Sie das Kontrollkästchen SSL-Verbindung erforderlich.
Wählen Sie Weiter aus.
Geben Sie auf der VPC-Seite die folgenden Werte an:
Wählen Sie für VPC den Namen Ihrer VPC (z. B. AWS KafkaTutorialVPC).
Wählen Sie für Subnet. AWS KafkaTutorialSubnet2
Wählen Sie für Sicherheitsgruppen alle verfügbaren Gruppen aus.
Wählen Sie Weiter aus.
Wählen Sie auf der Seite Verbindungseigenschaften / Verbindungszugriff die Option Fertigstellen aus.
Erstellen einer Tabelle
Anmerkung
Sie können die Tabelle entweder manuell erstellen, wie in den folgenden Schritten beschrieben, oder Sie können den Konnektorcode zum Erstellen einer Tabelle für Managed Service für Apache Flink in Ihrem Notebook innerhalb von Apache Zeppelin verwenden, um Ihre Tabelle über eine DDL-Anweisung zu erstellen. Sie können dann einchecken AWS Glue , um sicherzustellen, dass die Tabelle korrekt erstellt wurde.
Wählen Sie in der linken Navigationsleiste die Option Tabellen. Wählen Sie auf der Seite Tabellen die Optionen Tabellen hinzufügen, Tabelle manuell hinzufügen aus.
Geben Sie auf der Seite Eigenschaften Ihrer Tabelle einrichten
stockals Tabellennamen ein. Stellen Sie sicher, dass Sie die Datenbank auswählen, die Sie zuvor erstellt haben. Wählen Sie Weiter aus.Wählen Sie auf der Seite Datenspeicher hinzufügen die Option Kafka aus. Geben Sie als Themennamen Ihren Themennamen ein (z. B. AWS KafkaTutorialTopic). Wählen Sie für Verbindung ZeppelinConnection.
Wählen Sie auf der Seite Klassifikation die Option JSON aus. Wählen Sie Weiter aus.
Wählen Sie auf der Seite Schema definieren die Option „Spalte hinzufügen“, um eine Spalte hinzuzufügen. Fügen Sie Spalten mit den folgenden Eigenschaften hinzu:
Name der Spalte Datentyp tickerstringpricedoubleWählen Sie Weiter aus.
Überprüfen Sie auf der nächsten Seite Ihre Einstellungen und wählen Sie Fertigstellen.
-
Wählen Sie die neu erstellte Tabelle aus der Liste der Tabellen aus.
-
Wählen Sie Tabelle bearbeiten und fügen Sie die folgenden Eigenschaften hinzu:
-
Schlüssel:
managed-flink.proctimeWert:proctime -
Schlüssel:
flink.properties.group.idWert:test-consumer-group -
Schlüssel:
flink.properties.auto.offset.resetWert:latest -
Schlüssel:
classificationWert:json
Ohne diese key/value Paare tritt im Flink-Notebook ein Fehler auf.
-
-
Wählen Sie Anwenden aus.
Erstellen Sie ein Studio-Notebook mit Amazon MSK
Nachdem Sie die Ressourcen erstellt haben, die Ihre Anwendung verwendet, erstellen Sie Ihr Studio-Notebook.
Sie können Ihre Anwendung entweder mit AWS-Managementkonsole oder mit dem erstellen. AWS CLI
Anmerkung
Sie können ein Studio-Notebook auch von der Amazon MSK-Konsole aus erstellen, indem Sie einen vorhandenen Cluster auswählen und dann Daten in Echtzeit verarbeiten wählen.
Erstellen Sie ein Studio-Notizbuch mit dem AWS-Managementkonsole
Wählen Sie auf der Seite Managed Service für Apache Flink-Anwendungen die Registerkarte Studio aus. Wählen Sie Studio-Notebook erstellen.
Anmerkung
Um ein Studio-Notebook über die Amazon MSK- oder Kinesis Data Streams-Konsolen zu erstellen, wählen Sie Ihren Amazon MSK-Eingabe-Cluster oder Kinesis Data Stream aus und wählen Sie dann Daten in Echtzeit verarbeiten aus.
Geben Sie auf der Seite Notebook-Instance erstellen folgende Informationen ein:
-
Geben Sie
MyNotebookals Studio-Notebookname. Wählen Sie Standard für die AWS -Glue-Datenbank.
Wählen Sie Studio-Notebook erstellen.
-
Wählen Sie auf der Seite die Registerkarte Konfiguration aus MyNotebook. Wählen Sie im Abschnitt Netzwerk die Option Bearbeiten.
Wählen Sie auf der MyNotebook Seite Netzwerk bearbeiten für die VPC-Konfiguration basierend auf dem Amazon MSK-Cluster aus. Wählen Sie Ihren Amazon MSK-Cluster für den Amazon MSK-Cluster aus. Wählen Sie Änderungen speichern aus.
Wählen Sie auf der MyNotebookSeite die Option Ausführen aus. Warten Sie, bis der Status Wird ausgeführt angezeigt wird.
Erstellen Sie ein Studio-Notizbuch mit dem AWS CLI
Gehen Sie wie folgt vor AWS CLI, um Ihr Studio-Notizbuch mit dem zu erstellen:
Stellen Sie sicher, dass Sie über die folgenden Informationen verfügen: Sie benötigen diese Werte, um Ihre Anwendung zu erstellen.
Ihre Konto-ID.
Die Subnetz-IDs und Sicherheitsgruppen-ID für die Amazon-VPC, die Ihren Amazon-MSK-Cluster enthält.
Erstellen Sie eine Datei mit dem Namen
create.jsonund den folgenden Inhalten. Ersetzen Sie die Platzhalterwerte durch Ihre Informationen.{ "ApplicationName": "MyNotebook", "RuntimeEnvironment": "ZEPPELIN-FLINK-3_0", "ApplicationMode": "INTERACTIVE", "ServiceExecutionRole": "arn:aws:iam::AccountID:role/ZeppelinRole", "ApplicationConfiguration": { "ApplicationSnapshotConfiguration": { "SnapshotsEnabled": false }, "VpcConfigurations": [ { "SubnetIds": [ "SubnetID 1", "SubnetID 2", "SubnetID 3" ], "SecurityGroupIds": [ "VPC Security Group ID" ] } ], "ZeppelinApplicationConfiguration": { "CatalogConfiguration": { "GlueDataCatalogConfiguration": { "DatabaseARN": "arn:aws:glue:us-east-1:AccountID:database/default" } } } } }Um Ihre Anwendung zu erstellen, führen Sie den folgenden Befehl aus.
aws kinesisanalyticsv2 create-application --cli-input-json file://create.jsonWenn der Befehl abgeschlossen ist, sollte eine Ausgabe wie die folgende angezeigt werden, die die Details für Ihr neues Studio-Notebook enthält:
{ "ApplicationDetail": { "ApplicationARN": "arn:aws:kinesisanalyticsus-east-1:012345678901:application/MyNotebook", "ApplicationName": "MyNotebook", "RuntimeEnvironment": "ZEPPELIN-FLINK-3_0", "ApplicationMode": "INTERACTIVE", "ServiceExecutionRole": "arn:aws:iam::012345678901:role/ZeppelinRole", ...Um Ihre Anwendung zu starten, führen Sie den folgenden Befehl aus. Ersetzen Sie die Beispielwerte durch Ihre Konto-ID.
aws kinesisanalyticsv2 start-application --application-arn arn:aws:kinesisanalyticsus-east-1:012345678901:application/MyNotebook\
Senden Sie Daten an Ihren Amazon MSK-Cluster
In diesem Abschnitt führen Sie ein Python-Skript in Ihrem Amazon EC2-Client aus, um Daten an Ihre Amazon MSK-Datenquelle zu senden.
Stellen Sie eine Verbindung zu Ihrem Amazon EC2-Client her.
Führen Sie die folgenden Befehle aus, um Python Version 3, Pip und das Kafka für Python-Paket zu installieren, und bestätigen Sie die Aktionen:
sudo yum install python37 curl -O https://bootstrap.pypa.io/get-pip.py python3 get-pip.py --user pip install kafka-pythonKonfigurieren Sie das AWS CLI auf Ihrem Client-Computer, indem Sie den folgenden Befehl eingeben:
aws configureGeben Sie Ihre Kontoanmeldeinformationen ein, und
us-east-1für dieregion.Erstellen Sie eine Datei mit dem Namen
stock.pyund den folgenden Inhalten. Ersetzen Sie den Beispielwert durch die Bootstrap Brokers-Zeichenfolge Ihres Amazon MSK-Clusters und aktualisieren Sie den Themennamen, falls Ihr Thema nicht: AWS KafkaTutorialTopicfrom kafka import KafkaProducer import json import random from datetime import datetime BROKERS = "<<Bootstrap Broker List>>" producer = KafkaProducer( bootstrap_servers=BROKERS, value_serializer=lambda v: json.dumps(v).encode('utf-8'), retry_backoff_ms=500, request_timeout_ms=20000, security_protocol='PLAINTEXT') def getStock(): data = {} now = datetime.now() str_now = now.strftime("%Y-%m-%d %H:%M:%S") data['event_time'] = str_now data['ticker'] = random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']) price = random.random() * 100 data['price'] = round(price, 2) return data while True: data =getStock() # print(data) try: future = producer.send("AWSKafkaTutorialTopic", value=data) producer.flush() record_metadata = future.get(timeout=10) print("sent event to Kafka! topic {} partition {} offset {}".format(record_metadata.topic, record_metadata.partition, record_metadata.offset)) except Exception as e: print(e.with_traceback())Führen Sie das Skript mit dem folgenden Befehl aus:
$ python3 stock.pyLassen Sie das Skript laufen, während Sie den folgenden Abschnitt abschließen.
Testen Sie Ihr Studio-Notebook
In diesem Abschnitt verwenden Sie Ihr Studio-Notebook, um Daten aus Ihrem Amazon MSK-Cluster abzufragen.
Wählen Sie auf der Seite Managed Service für Apache Flink-Anwendungen die Registerkarte Studio-Notebook aus. Wählen Sie MyNotebook.
Wählen Sie auf der MyNotebookSeite „In Apache Zeppelin öffnen“.
Die Oberfläche von Apache Zeppelin wird in einer neuen Registerkarte geöffnet.
Auf der Seite Willkommen bei Zeppelin! wählen Sie Zeppelin neue Notiz aus.
Geben Sie auf der Seite Zeppelin Notiz die folgende Abfrage in eine neue Notiz ein:
%flink.ssql(type=update) select * from stockWählen Sie das Ausführungssymbol.
Die Anwendung zeigt Daten aus dem Amazon MSK-Cluster an.
Um das Apache Flink-Dashboard für Ihre Anwendung zu öffnen und betriebliche Aspekte zu sehen, wählen Sie FLINK JOB. Weitere Informationen zum Flink-Dashboard finden Sie unter Apache Flink-Dashboard im Managed Service für Apache Flink Entwicklerhandbuch.
Weitere Beispiele für Flink-Streaming-SQL-Abfragen finden Sie unter Abfragen
