Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Diseño de esquemas de GraphQLEl esquema GraphQL es la base de cualquier implementación de servidor GraphQL. Cada API de GraphQL se define mediante un solo esquema que contiene tipos y campos que describen cómo se rellenarán los datos de las solicitudes. Los datos que fluyen a través de la API y las operaciones realizadas deben validarse con respecto al esquema.
En general, el sistema de tipos de GraphQL describe las funcionalidades de un servidor GraphQL y se utiliza para determinar si una consulta es válida. El sistema de tipos de un servidor suele denominarse esquema de ese servidor y puede constar de diferentes tipos de objetos, tipos escalares, tipos de entradas, etc. GraphQL es declarativo y tiene establecimiento inflexible de tipos, lo que significa que los tipos estarán bien definidos en tiempo de ejecución y solo devolverán lo que se haya especificado.
AWS AppSync permite definir y configurar esquemas de GraphQL. La siguiente sección describe cómo crear esquemas de GraphQL desde cero utilizando AWS AppSync los servicios.
Estructuración de un esquema de GraphQL
Recomendamos consultar la sección Esquemas antes de continuar.
GraphQL es una poderosa herramienta para implementar servicios de API. Según el sitio web de GraphQL, GraphQL es lo siguiente:
«GraphQL es un lenguaje de consulta APIs y un entorno de ejecución para completar esas consultas con los datos existentes. GraphQL proporciona una descripción completa y comprensible de los datos de tu API, da a los clientes la posibilidad de pedir exactamente lo que necesitan y nada más, facilita la evolución APIs con el tiempo y habilita potentes herramientas para desarrolladores. »
Esta sección cubre la primera parte de la implementación de GraphQL, el esquema. Siguiendo la cita anterior, un esquema cumple la función de “proporcionar una descripción completa y comprensible de los datos de su API”. En otras palabras, un esquema GraphQL es una representación textual de los datos, las operaciones y las relaciones entre ellos de su servicio. El esquema se considera el punto de entrada principal para la implementación del servicio GraphQL. Como era de esperar, suele ser una de las primeras cosas que hace en su proyecto. Recomendamos consultar la sección Esquemas antes de continuar.
Para citar la sección Esquemas, los esquemas de GraphQL se escriben en el lenguaje de definición de esquema (SDL). SDL está compuesto por tipos y campos con una estructura establecida:
-
Tipos: los tipos son la forma en que GraphQL define la forma y el comportamiento de los datos. GraphQL admite una multitud de tipos que se explicarán más adelante en esta sección. Cada tipo que se defina en su esquema tendrá su propio ámbito. Dentro del ámbito habrá uno o más campos que pueden contener un valor o una lógica que se utilice en el servicio GraphQL. Los tipos cumplen muchos roles diferentes, siendo las más comunes los objetos o los escalares (tipos de valores primitivos).
-
Campos: los campos existen dentro del ámbito de un tipo y contienen el valor que se solicita al servicio GraphQL. Se parecen mucho a las variables de otros lenguajes de programación. La forma de los datos que defina en sus campos determinará cómo se estructuran los datos en una request/response operación. Esto permite a los desarrolladores predecir lo que se va a devolver sin saber cómo se implementa el backend del servicio.
Los esquemas más simples contendrán tres categorías de datos diferentes:
-
Raíces del esquema: las raíces definen los puntos de entrada de su esquema. Señala los campos que realizarán alguna operación con los datos, como añadir, eliminar o modificar algo.
-
Tipos: son tipos básicos que se utilizan para representar la forma de los datos. Casi se puede pensar en ellos como objetos o representaciones abstractas de algo con características definidas. Por ejemplo, podría crear un objeto Person que represente a una persona en una base de datos. Las características de cada persona se definirán dentro de Person como campos. Pueden ser cualquier cosa, como el nombre, la edad, el trabajo, la dirección, etc. de la persona.
-
Tipos de objetos especiales: son los tipos que definen el comportamiento de las operaciones del esquema. Cada tipo de objeto especial se define una vez por cada esquema. Primero se colocan en la raíz del esquema y, a continuación, se definen en el cuerpo del esquema. Cada campo de un tipo de objeto especial define una sola operación que debe implementar el solucionador.
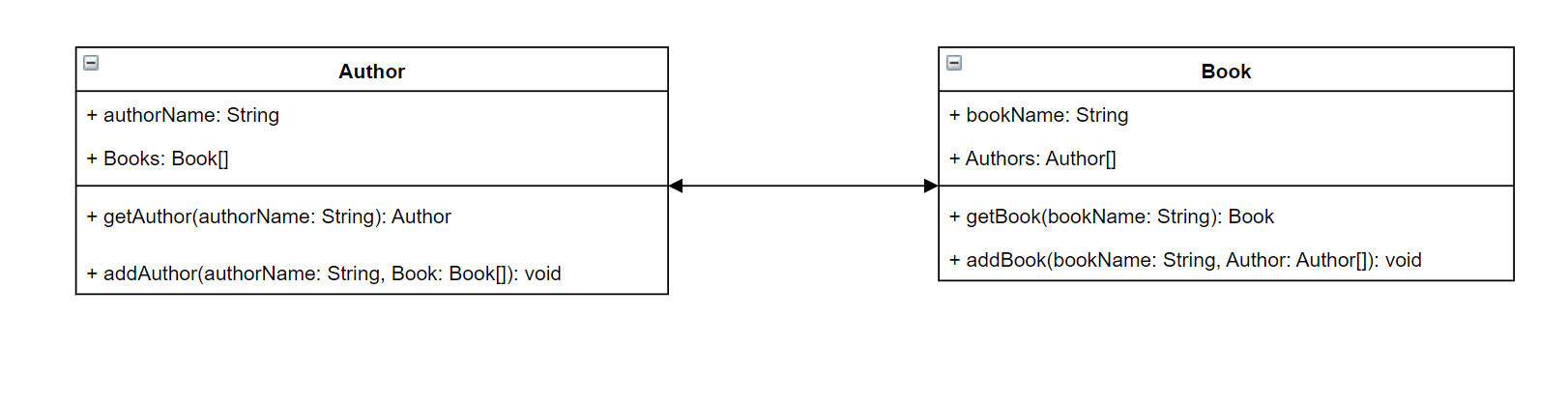
Para poner esto en perspectiva, imagine que está creando un servicio que almacena autores y los libros que han escrito. Cada autor tiene un nombre y una serie de libros que han escrito. Cada libro tiene un nombre y una lista de autores asociados. También queremos poder añadir o recuperar libros y autores. Una representación UML simple de esta relación puede tener este aspecto:
En GraphQL, las entidades Author y Book representan dos tipos de objetos diferentes en el esquema:
type Author {
}
type Book {
}
Author contiene authorName y Books, mientras que Book contiene bookName y Authors. Estos se pueden representar como los campos incluidos en el ámbito de sus tipos:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
Como puede ver, las representaciones de tipos se parecen mucho al diagrama. Sin embargo, los métodos son algo más complicados. Se colocarán como campo en uno de algunos tipos de objetos especiales. La categorización de los objetos especiales depende de su comportamiento. GraphQL contiene tres tipos de objetos especiales fundamentales: consultas, mutaciones y suscripciones. Para obtener más información sobre los objetos, consulte Objetos especiales.
Como tanto getAuthor como getBook solicitan datos, se colocarán en un tipo de objeto especial de Query:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Las operaciones están vinculadas a la consulta, que a su vez está vinculada al esquema. Cuando se añade una raíz de esquema, se define el tipo de objeto especial (en este caso, Query) como uno de los puntos de entrada. Esto se puede hacer con la palabra clave schema:
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Si nos fijamos en los dos últimos métodos, addAuthor y addBook añaden datos a la base de datos, por lo que se definirán en un tipo de objeto Mutation especial. Sin embargo, por la página Tipos, también sabemos que no se permiten entradas que hagan referencia directamente a objetos porque son estrictamente tipos de salida. En este caso, no podemos usar Author ni Book, por lo que necesitamos crear un tipo de entrada con los mismos campos. En este ejemplo, añadimos AuthorInput yBookInput, que aceptan los mismos campos de sus tipos correspondientes. A continuación, creamos nuestra mutación usando las entradas como parámetros:
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
Repasemos lo que acabamos de hacer:
-
Hemos creado un esquema con los tipos Book y Author para representar nuestras entidades.
-
Hemos añadido los campos que contienen las características de nuestras entidades.
-
Hemos añadido una consulta para recuperar esta información de la base de datos.
-
Hemos añadido una mutación para manipular los datos de la base de datos.
-
Hemos añadido tipos de entrada para reemplazar los parámetros de nuestro objeto en la mutación y cumplir con las reglas de GraphQL.
-
Hemos añadido la consulta y la mutación a nuestro esquema de raíz para que la implementación de GraphQL entienda la ubicación del tipo de raíz.
Como puede ver, el proceso de creación de un esquema requiere muchos conceptos del modelado de datos (especialmente del modelado de bases de datos) en general. Puede considerarse que el esquema se ajusta a la forma de los datos de la fuente. También sirve como modelo que el solucionador implementará. En las siguientes secciones, aprenderá a crear un esquema utilizando diversas herramientas y servicios AWS respaldados por ellos.
Los ejemplos de las secciones siguientes no están pensados para ejecutarse en una aplicación real. Con ellos solo se pretende mostrar los comandos para que pueda crear sus propias aplicaciones.
Creación de esquemas
El esquema estará en un archivo llamadoschema.graphql. AWS AppSync permite a los usuarios crear nuevos esquemas para su APIs GraphQL utilizando varios métodos. En este ejemplo, crearemos una API en blanco junto con un esquema en blanco.
- Console
-
-
Inicia sesión en la consola Consola de administración de AWS y ábrelaAppSync.
-
En el Panel, elija Crear API.
-
En Opciones de API, selecciona GraphQL APIs, Diseña desde cero y, a continuación, Siguiente.
-
En Nombre de la API, cambie el nombre previamente cumplimentado por el que su aplicación necesite.
-
Para obtener los detalles de contacto, puede introducir un punto de contacto para identificar al administrador de la API. Se trata de un campo opcional.
-
En Configuración de API privada, puede habilitar las características de API privadas. Solo se puede acceder a una API privada desde un punto de conexión de VPC (VPCE) configurado. Para obtener más información, consulta Privado APIs.
No le recomendamos habilitar esta característica para este ejemplo. Seleccione Siguiente después de revisar sus entradas.
-
En Crear un tipo de GraphQL, puede elegir crear una tabla de DynamoDB para utilizarla como origen de datos u omitir este paso y hacerlo más adelante.
Para este ejemplo, elija Crear recursos de GraphQL más adelante. Crearemos un recurso en una sección aparte.
-
Revise la información indicada y, a continuación, seleccione Crear API.
-
Estará en el panel de control de tu API específica. Lo notará porque el nombre de la API aparecerá en la parte superior del panel de control. Si este no es el caso, puedes seleccionarla APIsen la barra lateral y, a continuación, elegir tu API en el APIs panel de control.
-
En la barra lateral situada debajo del nombre de la API, seleccione Esquema.
-
En el Editor de esquemas, puede configurar su archivo schema.graphql. Puede estar vacío o lleno de tipos generados a partir de un modelo. A la derecha, tiene la sección Solucionadores para asociar solucionadores a los campos del esquema. En esta sección no nos fijaremos en los solucionadores.
- CLI
-
Cuando utilice la CLI, asegúrese de tener los permisos correctos para acceder y crear recursos en el servicio. Es posible que desee establecer políticas de privilegios mínimos para los usuarios que no sean administradores y que necesiten acceder al servicio. Para obtener más información sobre AWS AppSync las políticas, consulte Administración de identidad y acceso para. AWS AppSync
Además, le recomendamos leer primero la versión de consola si aún no lo ha hecho.
-
Si aún no lo ha hecho, instale la CLI de AWS
y añadas su configuración.
-
Cree un objeto de API de GraphQL ejecutando el comando create-graphql-api.
Deberá escribir dos parámetros para este comando concreto:
-
El name de su API.
-
El authentication-type o el tipo de credenciales utilizado para acceder a la API (IAM, OIDC, etc.).
Otros parámetros, como Region, deben configurarse pero normalmente se utilizarán de forma predeterminada en los valores de configuración de la CLI.
Un comando de ejemplo puede tener este aspecto:
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
Aparecerá un resultado en la CLI. A continuación se muestra un ejemplo:
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
Se trata de un comando opcional que toma un esquema existente y lo carga en el servicio de AWS AppSync mediante un blob de base 64. No utilizaremos este comando para este ejemplo.
Ejecute el comando start-schema-creation.
Deberá escribir dos parámetros para este comando concreto:
-
Su api-id del paso anterior.
-
La definition del esquema es un blob binario codificado en base 64.
Un comando de ejemplo puede tener este aspecto:
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
Se devolverá un resultado:
{
"status": "PROCESSING"
}
Este comando no devolverá el resultado final después del procesamiento. Para ver el resultado, debe usar un comando diferente, get-schema-creation-status. Tenga en cuenta que estos dos comandos son asíncronos, por lo que puede comprobar el estado de la salida incluso mientras se crea el esquema.
- CDK
-
Antes de usar la CDK, te recomendamos que consultes la documentación oficial de la CDK junto con AWS AppSync su referencia.
Los pasos que se indican a continuación solo mostrarán un ejemplo general del fragmento de código utilizado para añadir un recurso concreto. No se pretende que esta sea una solución funcional en su código de producción. También, se presupone que ya tiene una aplicación en funcionamiento.
-
El punto de partida del CDK es ligeramente diferente. Lo ideal es que el archivo schema.graphql ya esté creado. Solo necesita crear un nuevo archivo con la extensión de archivo .graphql. Puede ser un archivo vacío.
-
En general, puede que tenga que añadir la directiva de importación al servicio que utilice. Por ejemplo, puede seguir estas formas:
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
Para añadir una API de GraphQL, tu archivo de pila debe importar el AWS AppSync servicio:
import * as appsync from 'aws-cdk-lib/aws-appsync';
Esto significa que vamos a importar todo el servicio con la palabra clave appsync. Para usar esto en tu aplicación, tus AWS AppSync construcciones usarán el formato. appsync.construct_name Por ejemplo, si quisiéramos crear una API de GraphQL, diríamos new appsync.GraphqlApi(args_go_here). En el siguiente paso se describe esto.
-
La API de GraphQL más básica incluirá un name para la API y la ruta de schema.
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
Repasemos lo que hace este fragmento de código. Dentro del ámbito de api, creamos una nueva API de GraphQL llamando a appsync.GraphqlApi(scope: Construct, id:
string, props: GraphqlApiProps). El alcance es this, que hace referencia al objeto actual. El id esAPI_ID, que será el nombre del recurso de tu API de GraphQL CloudFormation cuando se cree. GraphqlApiProps contiene el name de la API de GraphQL y el schema. schemaGenerará un esquema (SchemaFile.fromAsset) buscando el .graphql archivo (__dirname) en la ruta absoluta (schema_name.graphql). En un escenario real, es probable que su archivo de esquema esté dentro de la aplicación del CDK.
Para usar los cambios realizados en la API de GraphQL, deberá volver a implementar la aplicación.
Adición de tipos a los esquemas
Ahora que ha añadido su esquema, puede empezar a agregar los tipos tanto de entrada como de salida. Tenga en cuenta que los tipos que aparecen aquí no deben usarse en código real; son solo ejemplos que le ayudarán a entender el proceso.
En primer lugar, crearemos un tipo de objeto. En el código real, no es necesario empezar con estos tipos. Puede crear cualquier tipo que desee en cualquier momento siempre que siga las reglas y la sintaxis de GraphQL.
Las siguientes secciones usarán el editor de esquemas, así que manténgalo abierto.
- Console
-
-
Puede crear un tipo de objeto utilizando la palabra clave type junto con el nombre del tipo:
type Type_Name_Goes_Here {}
Dentro del ámbito del tipo, puede añadir campos que representen las características del objeto:
type Type_Name_Goes_Here {
# Add fields here
}
A continuación se muestra un ejemplo:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
En este paso, hemos añadido un tipo de objeto genérico con un campo id obligatorio almacenado como ID, un campo title almacenado como String y un campo date almacenado como AWSDateTime. Para ver una lista de tipos y campos, y lo que hacen, consulte Esquemas. Para ver una lista de escalares y lo que hacen, consulte Referencia de tipos.
- CLI
-
Le recomendamos leer primero la versión de consola si aún no lo ha hecho.
-
Puede crear un tipo de objeto ejecutando el comando create-type.
Para este comando en particular, deberá introducir varios parámetros:
-
El api-id de su API.
-
La definition o el contenido de su tipo. En el ejemplo de la consola, esto era:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
El format de su entrada. En este ejemplo, usaremos SDL.
Un comando de ejemplo puede tener este aspecto:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
Aparecerá un resultado en la CLI. A continuación se muestra un ejemplo:
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
En este paso, hemos añadido un tipo de objeto genérico con un campo id obligatorio almacenado como ID, un campo title almacenado como String y un campo date almacenado como AWSDateTime. Para ver una lista de tipos y campos, y lo que hacen, consulte Esquemas. Para ver una lista de escalares y lo que hacen, consulte Referencia de tipos.
Por otra parte, puede que se haya dado cuenta de que introducir la definición directamente funciona para tipos más pequeños pero no es factible para añadir tipos más grandes o múltiples. Puede optar por añadir todo el contenido en un archivo .graphql y, a continuación, pasarlo como entrada.
- CDK
-
Antes de usar la CDK, le recomendamos que consulte la documentación oficial de la CDK junto con AWS AppSync su referencia.
Los pasos que se indican a continuación solo mostrarán un ejemplo general del fragmento de código utilizado para añadir un recurso concreto. No se pretende que esta sea una solución funcional en su código de producción. También, se presupone que ya tiene una aplicación en funcionamiento.
Para añadir un tipo, debe añadirlo a su archivo .graphql. El ejemplo de la consola era:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Puede añadir sus tipos directamente al esquema como cualquier otro archivo.
Para usar los cambios realizados en la API de GraphQL, deberá volver a implementar la aplicación.
El tipo de objeto tiene campos que son de tipo escalar, como cadenas y números enteros. AWS AppSync también te permite usar tipos escalares mejorados, AWSDateTime además de los escalares básicos de GraphQL. Además, todos los campos que terminen con un signo de exclamación son obligatorios.
El tipo escalar ID en concreto es un identificador exclusivo que puede ser String o Int. Puede controlarlos en el código de resolución para la asignación automática.
Existen similitudes entre los tipos de objetos especiales, como Query y los tipos de objetos “normales”, como en el ejemplo anterior, en el sentido de que ambos utilizan la palabra clave type y se consideran objetos. Sin embargo, en el caso de los tipos de objetos especiales (Query, Mutation, y Subscription), su comportamiento es muy diferente, ya que se exponen como puntos de entrada a la API. También se centran más en dar forma a las operaciones que a los datos. Para obtener más información, consulte la sección sobre tipos de consultas y mutaciones.
En cuanto a los tipos de objetos especiales, el siguiente paso podría ser añadir uno o más para realizar operaciones con los datos con forma. En un escenario real, cada esquema de GraphQL debe tener al menos un tipo de consulta raíz para solicitar datos. Puede considerar la consulta como uno de los puntos de entrada (o puntos de conexión) de su servidor GraphQL. Añadamos una consulta como ejemplo.
- Console
-
-
Para crear una consulta, basta con añadirla al archivo de esquema como cualquier otro tipo. Una consulta requeriría un tipo Query y una entrada en la raíz de la manera siguiente:
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
Ten en cuenta que Name_of_Query en un entorno de producción simplemente se llamará Query en la mayoría de los casos. Se recomienda mantenerlo en este valor. Dentro del tipo de consulta, puede añadir campos. Cada campo realizará una operación en la solicitud. El resultado es que la mayoría de estos campos, si no todos, se asociarán a un solucionador. Sin embargo, en esta sección o abordaremos eso. En cuanto al formato de la operación de campo, podría ser como este:
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
A continuación se muestra un ejemplo:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
En este paso, agregamos un tipo Query y lo definimos en nuestra raíz de schema. Nuestro tipo Query definió un campo getObj que devuelve una lista de objetos Obj_Type_1. Tenga en cuenta que Obj_Type_1 es el objeto del paso anterior. En el código de producción, sus operaciones de campo normalmente funcionarán con datos moldeados por objetos como Obj_Type_1. Además, campos como getObj suelen tener un solucionador para ejecutar la lógica empresarial. Este tema se tratará en otra sección.
Como nota adicional, agrega AWS AppSync automáticamente una raíz del esquema durante las exportaciones, por lo que técnicamente no es necesario agregarla directamente al esquema. Nuestro servicio procesará automáticamente los esquemas duplicados. Lo añadimos aquí como práctica recomendada.
- CLI
-
Le recomendamos leer primero la versión de consola si aún no lo ha hecho.
-
Cree una raíz de schema con una definición query ejecutando el comando create-type.
Para este comando en particular, deberá introducir varios parámetros:
-
El api-id de su API.
-
La definition o el contenido de su tipo. En el ejemplo de la consola, esto era:
schema {
query: Query
}
-
El format de su entrada. En este ejemplo, usaremos SDL.
Un comando de ejemplo puede tener este aspecto:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
Aparecerá un resultado en la CLI. A continuación se muestra un ejemplo:
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
Tenga en cuenta que si no ha introducido algo correctamente en el comando create-type, puede actualizar la raíz del esquema (o cualquier tipo del esquema) ejecutando el comando update-type. En este ejemplo, cambiaremos temporalmente la raíz del esquema para que contenga una definición de subscription.
Para este comando en particular, deberá introducir varios parámetros:
-
El api-id de su API.
-
El type-name de su tipo. En el ejemplo de la consola, esto era schema.
-
La definition o el contenido de su tipo. En el ejemplo de la consola, esto era:
schema {
query: Query
}
El esquema después de añadir una subscription será como el siguiente:
schema {
query: Query
subscription: Subscription
}
-
El format de su entrada. En este ejemplo, usaremos SDL.
Un comando de ejemplo puede tener este aspecto:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
Aparecerá un resultado en la CLI. A continuación se muestra un ejemplo:
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
En este ejemplo, seguirá funcionando la adición de archivos preformateados.
-
Cree un tipo de Query ejecutando el comando create-type.
Para este comando en particular, deberá introducir varios parámetros:
-
El api-id de su API.
-
La definition o el contenido de su tipo. En el ejemplo de la consola, esto era:
type Query {
getObj: [Obj_Type_1]
}
-
El format de su entrada. En este ejemplo, usaremos SDL.
Un comando de ejemplo puede tener este aspecto:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
Aparecerá un resultado en la CLI. A continuación se muestra un ejemplo:
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
En este paso, hemos añadido un tipo Query y lo hemos definido en su raíz de schema. Nuestro tipo Query ha definido un campo getObj que devuelve una lista de objetos Obj_Type_1.
En el código de raíz de schema query: Query, la parte query: indica que se ha definido una consulta en el esquema, mientras que la parte Query indica el nombre real del objeto especial.
- CDK
-
Antes de usar la CDK, te recomendamos que consultes la documentación oficial de la CDK junto con AWS AppSync su referencia.
Los pasos que se indican a continuación solo mostrarán un ejemplo general del fragmento de código utilizado para añadir un recurso concreto. No se pretende que esta sea una solución funcional en su código de producción. También, se presupone que ya tiene una aplicación en funcionamiento.
Deberá añadir la consulta y la raíz del esquema al archivo .graphql. Nuestro caso era parecido al ejemplo siguiente, pero en este lo sustituirá con su código de esquema actual:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Puede añadir sus tipos directamente al esquema como cualquier otro archivo.
Actualizar la raíz del esquema es opcional. Lo hemos añadido a este ejemplo como práctica recomendada.
Para usar los cambios realizados en la API de GraphQL, deberá volver a implementar la aplicación.
Ahora ya ha visto un ejemplo de creación tanto de objetos como de objetos especiales (consultas). También ha visto cómo se pueden interconectar para describir datos y operaciones. Puede tener esquemas con solo la descripción de los datos y una o más consultas. Sin embargo, nos gustaría añadir otra operación para añadir datos al origen de datos. Vamos a añadir otro tipo de objeto especial denominado Mutation que modifica los datos.
- Console
-
-
Una mutación se llamará Mutation. Como en Query, las operaciones de campo de dentro de Mutation describirán una operación y se asociarán a un solucionador. Tenga en cuenta también que debemos definirla en la raíz schema porque es un tipo de objeto especial. Aquí tiene un ejemplo de mutación:
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
Una mutación típica aparecerá en la raíz en forma de consulta. La mutación se define con la type palabra clave junto con el nombre. Name_of_Mutationnormalmente se llamaráMutation, por lo que recomendamos mantenerlo así. Cada campo realizará también una operación. En cuanto al formato de la operación de campo, podría ser como este:
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
A continuación se muestra un ejemplo:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
En este paso, hemos añadido un tipo Mutation con un campo addObj. Vamos a resumir lo que hace este campo:
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
addObj está utilizando el objeto Obj_Type_1 para realizar una operación. Esto es evidente debido a los campos, pero la sintaxis lo demuestra en el tipo de retorno : Obj_Type_1. Dentro de addObj, acepta los campos id, title y date del objeto Obj_Type_1 como parámetros. Como puede ver, es muy parecido a la declaración de un método. Sin embargo, aún no hemos descrito el comportamiento de nuestro método. Como se ha afirmado antes, el esquema solo está ahí para definir cuáles serán los datos y las operaciones, no cómo funcionan. La lógica empresarial real se implementará más adelante, cuando creemos nuestros primeros solucionadores.
Una vez que haya terminado con su esquema, hay una opción para exportarlo como archivo schema.graphql. En el editor de esquemas, puede elegir Exportar esquema para descargar el archivo en un formato compatible.
Como nota adicional, agrega AWS AppSync automáticamente una raíz del esquema durante las exportaciones, por lo que técnicamente no es necesario agregarla directamente al esquema. Nuestro servicio procesará automáticamente los esquemas duplicados. Lo añadimos aquí como práctica recomendada.
- CLI
-
Le recomendamos leer primero la versión de consola si aún no lo ha hecho.
-
Actualice su esquema de raíz ejecutando el comando update-type.
Para este comando en particular, deberá introducir varios parámetros:
-
El api-id de su API.
-
El type-name de su tipo. En el ejemplo de la consola, esto era schema.
-
La definition o el contenido de su tipo. En el ejemplo de la consola, esto era:
schema {
query: Query
mutation: Mutation
}
-
El format de su entrada. En este ejemplo, usaremos SDL.
Un comando de ejemplo puede tener este aspecto:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
Aparecerá un resultado en la CLI. A continuación se muestra un ejemplo:
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
Cree un tipo de Mutation ejecutando el comando create-type.
Para este comando en particular, deberá introducir varios parámetros:
-
El api-id de su API.
-
La definition o el contenido de su tipo. En el ejemplo de la consola, esto era:
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
El format de su entrada. En este ejemplo, usaremos SDL.
Un comando de ejemplo puede tener este aspecto:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
Aparecerá un resultado en la CLI. A continuación se muestra un ejemplo:
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
Antes de usar la CDK, te recomendamos que consultes la documentación oficial de la CDK junto con AWS AppSync su referencia.
Los pasos que se indican a continuación solo mostrarán un ejemplo general del fragmento de código utilizado para añadir un recurso concreto. No se pretende que esta sea una solución funcional en su código de producción. También, se presupone que ya tiene una aplicación en funcionamiento.
Deberá añadir la consulta y la raíz del esquema al archivo .graphql. Nuestro caso era parecido al ejemplo siguiente, pero en este lo sustituirá con su código de esquema actual:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
Actualizar la raíz del esquema es opcional. Lo hemos añadido a este ejemplo como práctica recomendada.
Para usar los cambios realizados en la API de GraphQL, deberá volver a implementar la aplicación.
Consideraciones opcionales: uso de enumeraciones como estados
Llegados a este punto, ya sabe cómo hacer un esquema básico. Sin embargo, hay muchas cosas que se pueden añadir para aumentar la funcionalidad del esquema. Una característica común que se encuentra en las aplicaciones es el uso de enumeraciones como estados. Puede usar una enumeración para forzar la elección de un valor específico de un conjunto de valores cuando se invoque. Esto es adecuado para cosas que sabe que no van a cambiar drásticamente durante largos períodos de tiempo. Hipotéticamente, podríamos añadir una enumeración que devuelva el código de estado o cadena en la respuesta.
Como ejemplo, supongamos que vamos a crear una aplicación de redes sociales que almacene los datos de las publicaciones de un usuario en el backend. Nuestro esquema contiene un tipo Post que representa los datos de una publicación individual:
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
Nuestra Post contendrá un id único, un título de title, una date de publicación y una enumeración denominada PostStatus que representa el estado de la publicación a medida que la aplicación la procesa. Para nuestras operaciones, tendremos una consulta que devolverá todos los datos de la publicación:
type Query {
getPosts: [Post]
}
También tendremos una mutación que añade publicaciones al origen de datos:
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
Si observamos nuestro esquema, la enumeración PostStatus podría tener varios estados. Tal vez que queramos que los tres estados básicos se llamen success (publicación procesada correctamente), pending (publicación procesada) y error (publicación que no se puede procesar). Para añadir la enumeración, podemos hacer lo siguiente:
enum PostStatus {
success
pending
error
}
El esquema completo podría ser como este:
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
Si un usuario añade una Post en la aplicación, se llamará a la operación addPost para procesar esos datos. A medida que el solucionador adjunto a addPost procese los datos, actualizará continuamente poststatus con el estado de la operación. Cuando se consulte, Post contendrá el estado final de los datos. Tenga en cuenta que solo estamos describiendo cómo queremos que funcionen los datos en el esquema. Estamos haciendo muchas suposiciones sobre la implementación de nuestros solucionadores, que implementarán la lógica empresarial real para gestionar los datos a fin de cumplir con la solicitud.
Consideraciones opcionales: suscripciones
Las suscripciones en AWS AppSync se invocan como respuesta a una mutación. Se puede configurar con un tipo Subscription y una directiva @aws_subscribe() en el esquema para indicar qué mutaciones invocan una o varias suscripciones. Para obtener más información sobre cómo configurar suscripciones, consulte Datos en tiempo real.
Consideraciones opcionales: relaciones y paginación
Supongamos que tiene un millón de Posts almacenadas en una tabla de DynamoDB y desea devolver algunos de esos datos. Sin embargo, la consulta de ejemplo anterior solo devuelve todas las publicaciones. No le interesa buscarlas todas cada vez que realice una solicitud. Más bien, le interesa paginarlas. Realice los cambios siguientes en su esquema:
-
En el campo getPosts, añada dos argumentos de entrada: nextToken (iterador) y limit (límite de iteración).
-
Añada un nuevo tipo de PostIterator que contenga los campos Posts (recupera la lista de objetos Post) y nextToken (iterador).
-
Modifique getPosts para que devuelva PostIterator y no una lista de objetos de Post.
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
El tipo PostIterator le permite devolver una parte de la lista de objetos de Post y un nextToken para obtener la parte siguiente. Dentro de PostIterator, hay una lista de elementos de Post ([Post]) que se devuelve con un token de paginación (nextToken). En AWS AppSync, se conectaría a Amazon DynamoDB a través de un solucionador y se generaría automáticamente como un token cifrado. Así se convierte el valor del argumento limit en el parámetro maxResults y el argumento nextToken en el parámetro exclusiveStartKey. Para ver ejemplos y los ejemplos de plantillas integradas en la AWS AppSync consola, consulte Resolver reference () JavaScript.