Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Migración de datos desde bases de datos PostgreSQL con migraciones de datos homogéneas en AWS DMS
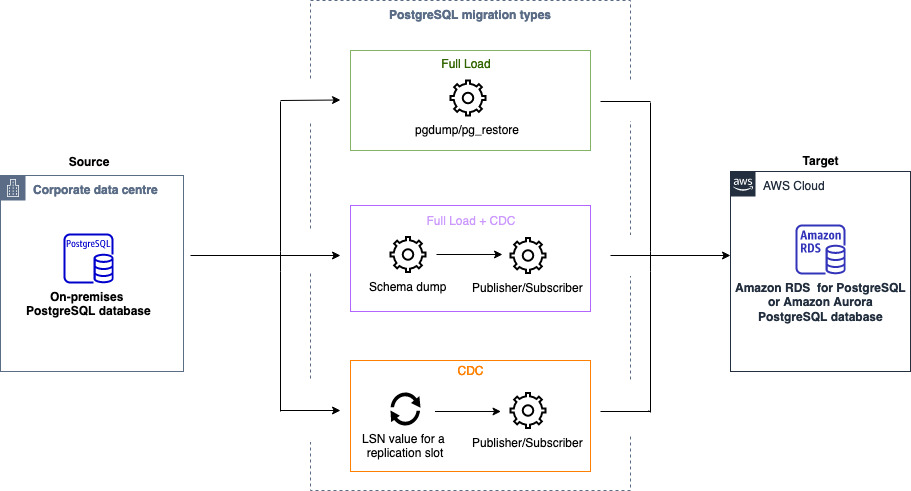
Puede utilizar Migraciones de datos homogéneas para migrar una base de datos de PostgreSQL autoadministrada a RDS para PostgreSQL o Aurora PostgreSQL. AWS DMS crea un entorno sin servidor para la migración de datos. Para diferentes tipos de migraciones de datos, AWS DMS utiliza diferentes herramientas de bases de datos de PostgreSQL nativas.
Para migraciones de datos homogéneas del tipo de carga completa, AWS DMS utiliza pg_dump para leer los datos de la base de datos de origen y almacenarlos en el disco conectado al entorno sin servidor. Después de AWS DMS leer todos los datos de origen, utiliza pg_restore en la base de datos de destino para restaurarlos.
Para las migraciones de datos homogéneas del tipo Full Load and Change Data Capture (CDC), se AWS DMS utiliza pg_dump para leer objetos de esquema sin datos de tablas de la base de datos de origen y almacenarlos en el disco conectado al entorno sin servidor. Después, usa pg_restore en la base de datos de destino para restaurar los objetos del esquema. Una vez AWS DMS finalizado el pg_restore proceso, cambia automáticamente a un modelo de publicador y suscriptor para la replicación lógica, con la Initial Data Synchronization opción de copiar los datos iniciales de la tabla directamente de la base de datos de origen a la base de datos de destino y, a continuación, inicia la replicación continua. En este modelo, uno o más suscriptores se suscriben a una o más publicaciones en un nodo publicador.
Para las migraciones de datos homogéneas del tipo Change Data Capture (CDC), se AWS DMS requiere el punto de partida nativo para iniciar la replicación. Si proporciona el punto de inicio nativo, AWS DMS captura los cambios desde ese punto. Otra opción, elija Inmediatamente en la configuración de migración de datos para capturar automáticamente el punto de inicio de la replicación cuando comience la migración de datos real.
nota
Para que CDC-only la migración funcione correctamente, todos los esquemas y objetos de la base de datos de origen deben estar ya presentes en la base de datos de destino. Sin embargo, es posible que el destino tenga objetos que no estén presentes en el origen.
Puede usar el siguiente ejemplo de código para obtener el punto de inicio nativo de la base de datos de PostgreSQL.
select confirmed_flush_lsn from pg_replication_slots where slot_name=‘migrate_to_target';
Esta consulta utiliza la vista pg_replication_slots de la base de datos de PostgreSQL para capturar el valor del número de secuencia de registro (LSN).
Después de AWS DMS establecer el estado de la migración de datos homogéneos de PostgreSQL en Detenida, Fallida o Eliminada, el editor y la replicación no se eliminan. Si no desea reanudar la migración, elimine la ranura de replicación y el publicador mediante el siguiente comando.
SELECT pg_drop_replication_slot('migration_subscriber_{ARN}'); DROP PUBLICATION publication_{ARN};
El siguiente diagrama muestra el proceso de usar migraciones de datos homogéneas para migrar una base de datos de PostgreSQL AWS DMS a RDS para PostgreSQL o Aurora PostgreSQL.
Prácticas recomendadas para usar una base de datos PostgreSQL como origen para migraciones de datos homogéneas
Para acelerar la sincronización inicial de los datos por parte del suscriptor en la tarea de carga completa y captura de datos de cambios, debe ajustar
max_logical_replication_workersymax_sync_workers_per_subscription. El aumento de estos valores acelera la velocidad de sincronización de la tabla.max_logical_replication_workers: especifica el número máximo de trabajos de replicación lógica. Esto incluye tanto los trabajos de aplicación del lado del suscriptor como los trabajos de sincronización de tablas.
max_sync_workers_per_subscription: el aumento de
max_sync_workers_per_subscriptionsolo afecta al número de tablas que se sincronizan en paralelo, no al número de trabajos por tabla.
nota
max_logical_replication_workersno debe superarmax_worker_processesymax_sync_workers_per_subscriptiondebe ser menor o igual quemax_logical_replication_workers.Para migrar tablas de gran tamaño, considere la posibilidad de dividirlas en tareas independientes mediante reglas de selección. Por ejemplo, puede dividir las tablas grandes en tareas individuales independientes y las tablas pequeñas en otra tarea individual.
Supervise el uso de la CPU y el disco por parte del suscriptor para mantener un rendimiento óptimo.
