Creación de una aplicación de procesamiento de archivos sin servidor
Uno de los casos de uso más comunes de Lambda es llevar a cabo tareas de procesamiento de archivos. Por ejemplo, puede utilizar una función de Lambda para crear archivos PDF de forma automática a partir de archivos HTML o imágenes, o para crear miniaturas cuando un usuario carga una imagen.
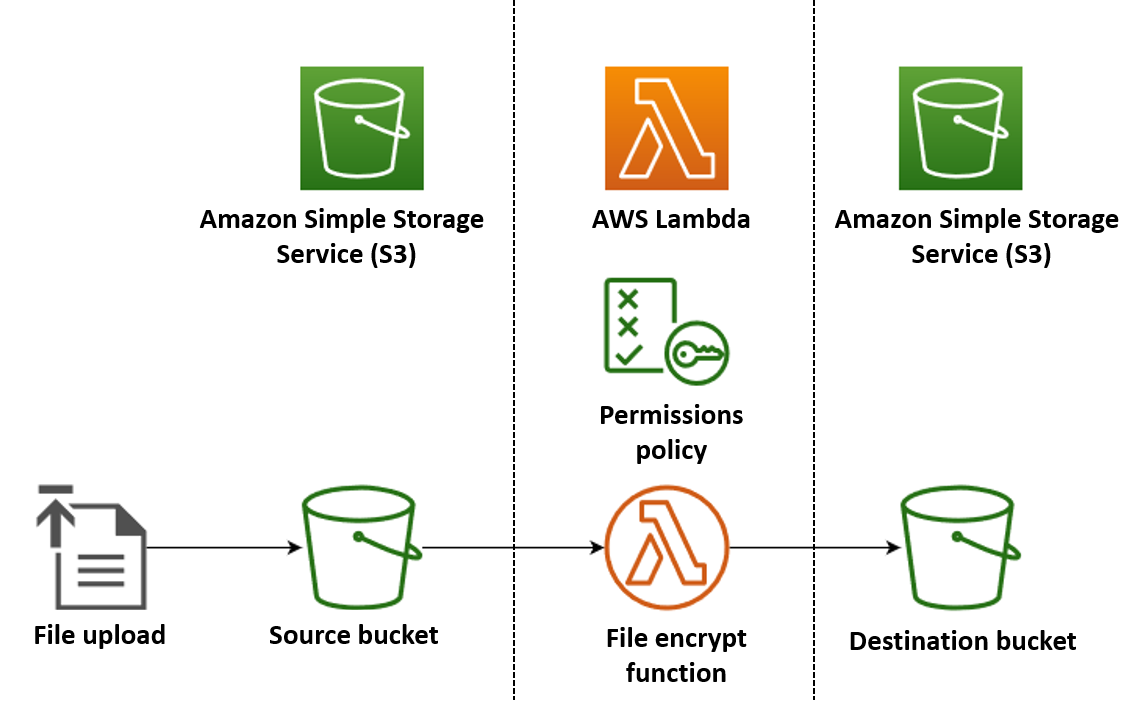
En este ejemplo, crea una aplicación que cifra los archivos PDF de forma automática cuando se cargan en un bucket de Amazon Simple Storage Service (Amazon S3). Para implementar esta aplicación, necesita crear los siguientes recursos:
-
Un bucket de S3 para que los usuarios puedan cargar los archivos PDF
-
Una función de Lambda en Python que lea el archivo cargado y cree una versión cifrada y protegida por contraseña
-
Un segundo bucket de S3 en el que Lambda pueda guardar el archivo cifrado
También debe crear una política de AWS Identity and Access Management (IAM) para conceder permiso a la función de Lambda para llevar a cabo operaciones de lectura y escritura en los buckets de S3.
sugerencia
Si es la primera vez que utiliza Lambda, recomendamos que comience por el tutorial de Creación de su primera función de Lambda antes de crear esta aplicación de ejemplo.
Para implementar la aplicación de forma manual, cree y configure los recursos mediante la Consola de administración de AWS o con la AWS Command Line Interface (AWS CLI). También puede implementar la aplicación mediante AWS Serverless Application Model (AWS SAM). AWS SAM es una herramienta de Infraestructura como código (IaC). Con la IaC no se crean recursos de forma manual, sino que se definen en código y, a continuación, se implementan automáticamente.
Si desea obtener más información sobre el uso de Lambda con la IaC antes de implementar esta aplicación de ejemplo, consulte Uso de Lambda con la infraestructura como código (IaC).
Crear los archivos de código fuente de la función de Lambda
Cree los siguientes archivos en el directorio del proyecto:
-
lambda_function.py: es el código de la función Python para la función de Lambda que lleva a cabo el cifrado de archivos -
requirements.txt: es un archivo de manifiesto que define las dependencias que requiere el código de la función de Python
Expanda las siguientes secciones para ver el código y obtener más información sobre la función de cada archivo. Para crear los archivos en la máquina local, copie y pegue el siguiente código o descargue los archivos del repositorio de GitHub aws-lambda-developer-guide
Copie y pegue el siguiente código en un archivo denominado lambda_function.py.
from pypdf import PdfReader, PdfWriter import uuid import os from urllib.parse import unquote_plus import boto3 # Create the S3 client to download and upload objects from S3 s3_client = boto3.client('s3') def lambda_handler(event, context): # Iterate over the S3 event object and get the key for all uploaded files for record in event['Records']: bucket = record['s3']['bucket']['name'] key = unquote_plus(record['s3']['object']['key']) # Decode the S3 object key to remove any URL-encoded characters download_path = f'/tmp/{uuid.uuid4()}.pdf' # Create a path in the Lambda tmp directory to save the file to upload_path = f'/tmp/converted-{uuid.uuid4()}.pdf' # Create another path to save the encrypted file to # If the file is a PDF, encrypt it and upload it to the destination S3 bucket if key.lower().endswith('.pdf'): s3_client.download_file(bucket, key, download_path) encrypt_pdf(download_path, upload_path) encrypted_key = add_encrypted_suffix(key) s3_client.upload_file(upload_path, f'{bucket}-encrypted', encrypted_key) # Define the function to encrypt the PDF file with a password def encrypt_pdf(file_path, encrypted_file_path): reader = PdfReader(file_path) writer = PdfWriter() for page in reader.pages: writer.add_page(page) # Add a password to the new PDF writer.encrypt("my-secret-password") # Save the new PDF to a file with open(encrypted_file_path, "wb") as file: writer.write(file) # Define a function to add a suffix to the original filename after encryption def add_encrypted_suffix(original_key): filename, extension = original_key.rsplit('.', 1) return f'{filename}_encrypted.{extension}'
nota
En este código de ejemplo, la contraseña del archivo cifrado (my-secret-password) está codificada en el código de la función. En aplicaciones de producción, no incluya información confidencial como contraseñas en el código de la función. En su lugar, cree un secreto de AWS Secrets Manager y, a continuación, utilice la extensión de Lambda AWS Parameters and Secrets para recuperar las credenciales en la función de Lambda.
El código de la función de Python contiene tres funciones: la función de controlador que Lambda ejecuta cuando se invoca la función y dos funciones independientes denominadas add_encrypted_suffix y encrypt_pdf a las que el controlador llama para que lleve a cabo el cifrado del PDF.
Cuando Amazon S3 invoca la función, Lambda pasa un argumento de evento con formato JSON a la función que contiene detalles sobre el evento que provocó la invocación. En este caso, la información incluye el nombre del bucket de S3 y las claves de objeto de los archivos cargados. Para obtener más información sobre el formato del objeto de evento de Amazon S3, consulte Procese las notificaciones de eventos de Amazon S3 con Lambda..
A continuación, la función utiliza AWS SDK para Python (Boto3) para descargar los archivos PDF especificados en el objeto de evento a su directorio de almacenamiento temporal local, antes de cifrarlos mediante la biblioteca pypdf
Por último, la función utiliza el SDK de Boto3 para almacenar el archivo cifrado en el bucket de destino de S3.
Copie y pegue el siguiente código en un archivo denominado requirements.txt.
boto3 pypdf
En este ejemplo, el código de la función solo tiene dos dependencias que no forman parte de la biblioteca estándar de Python: el SDK para Python (Boto3) y el paquete pypdf que la función utiliza para cifrar el PDF.
nota
Como parte del tiempo de ejecución de Lambda, se incluye una versión del SDK para Python (Boto3), de modo que el código se ejecute sin agregar Boto3 al paquete de implementación de la función. Sin embargo, para mantener el control total de las dependencias de la función y evitar posibles problemas de alineación de versiones, la práctica recomendada para Python es incluir todas las dependencias de la función en el paquete de implementación de la función. Consulte Dependencias de tiempo de ejecución en Python para obtener más información.
Implementar la aplicación
Puede crear e implementar los recursos para esta aplicación de ejemplo de forma manual o mediante AWS SAM. En un entorno de producción, recomendamos que utilice una herramienta de IaC como AWS SAM para implementar aplicaciones sin servidor de forma rápida y repetible sin utilizar procesos manuales.
Para implementar la aplicación manualmente:
-
Cree buckets de Amazon S3 de origen y de destino
-
Cree una función de Lambda que cifre un archivo PDF y guarde la versión cifrada de este en un bucket de S3
-
Configure un desencadenador de Lambda que invoque la función cuando se carguen objetos en el bucket de origen
Antes de comenzar, asegúrese de que Python
Cree dos buckets de S3
Primero, cree dos buckets de S3. El primer bucket es el bucket de origen al que subirá los archivos PDF. Lambda utiliza el segundo bucket para guardar el archivo cifrado cuando se invoca la función.
Creación de un rol de ejecución
Un rol de ejecución es un rol de IAM que concede a la función de Lambda permiso para acceder a servicios y recursos de Servicios de AWS. Para conceder acceso de lectura y escritura a Amazon S3 a la función, debe adjuntar la política administrada de AWS AmazonS3FullAccess.
Crear el paquete de despliegue de la función
Para crear una función, debe crear un paquete de despliegue que contenga el código y las dependencias de la función. Para esta aplicación, el código de la función utiliza una biblioteca independiente para el cifrado de PDF.
Creación del paquete de implementación
-
Navegue hasta el directorio del proyecto que contiene los archivos
lambda_function.pyyrequirements.txtque creó o descargó de GitHub anteriormente y cree un nuevo directorio denominadopackage. -
Instale las dependencias especificadas en el archivo
requirements.txtdel directoriopackageejecutando el siguiente comando:pip install -r requirements.txt --target ./package/ -
Cree un archivo .zip que contenga el código de la aplicación y todas sus dependencias. En Linux o macOS, ejecute los siguientes comandos desde la interfaz de la línea de comandos.
cd package zip -r ../lambda_function.zip . cd .. zip lambda_function.zip lambda_function.pyEn Windows, utilice la herramienta de compresión que prefiera para crear el archivo
lambda_function.zip. Asegúrese de que el archivolambda_function.pyy las carpetas que contienen las dependencias estén en la raíz del archivo .zip.
También puede crear su paquete de implementación mediante un entorno virtual de Python. Consulte Uso de archivos .zip para funciones de Lambda en Python
Crear la función de Lambda
Ahora use el paquete de implementación que creó en el paso anterior para implementar la función de Lambda.
Configuración de un desencadenador de Amazon S3 para invocar una función
Para que la función de Lambda se ejecute cuando carga un archivo al bucket de origen, debe configurar un desencadenador para la función. Puede configurar el desencadenador de Amazon S3 mediante la consola o la AWS CLI.
importante
Este procedimiento configura el bucket de S3 para invocar su función cada vez que se crea un objeto en el bucket. Asegúrese de configurar esto solo en el bucket de origen. Si la función de Lambda crea objetos en el mismo bucket que la invoca, la función se puede invocar de forma continua en un bucle
Antes de empezar, asegúrese de que Docker
-
En el directorio del proyecto, copie y pegue el siguiente código en un nuevo archivo denominado
template.yaml. Sustituya los nombres de los buckets del marcador de posición:-
Para el bucket de origen, sustituya
amzn-s3-demo-bucketpor cualquier nombre que cumpla con las reglas de nomenclatura del bucket de S3. -
Para el bucket de destino, reemplace
amzn-s3-demo-bucket-encryptedpor<source-bucket-name>-encryptedcuando<source-bucket>sea el nombre que escogió para el bucket de origen.
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Resources: EncryptPDFFunction: Type: AWS::Serverless::Function Properties: FunctionName: EncryptPDF Architectures: [x86_64] CodeUri: ./ Handler: lambda_function.lambda_handler Runtime: python3.12 Timeout: 15 MemorySize: 256 LoggingConfig: LogFormat: JSON Policies: - AmazonS3FullAccess Events: S3Event: Type: S3 Properties: Bucket: !Ref PDFSourceBucket Events: s3:ObjectCreated:* PDFSourceBucket: Type: AWS::S3::Bucket Properties: BucketName:amzn-s3-demo-bucketEncryptedPDFBucket: Type: AWS::S3::Bucket Properties: BucketName:amzn-s3-demo-bucket-encryptedLa plantilla AWS SAM define los recursos que crea para la aplicación. En este ejemplo, la plantilla define una función de Lambda con el tipo
AWS::Serverless::Functiony dos buckets de S3 con el tipoAWS::S3::Bucket. Los nombres de los buckets especificados en la plantilla son marcadores de posición. Antes de implementar la aplicación mediante AWS SAM, debe editar la plantilla para cambiar el nombre de los buckets por nombres únicos a nivel mundial que cumplan con las reglas de nomenclatura para los buckets de S3. Este paso se explica con más detalle en Implementación de los recursos mediante AWS SAM.La definición del recurso de la función de Lambda configura un desencadenador para la función mediante la propiedad del evento
S3Event. Este desencadenador hace que se invoque la función cada vez que se crea un objeto en el bucket de origen.La definición de la función también especifica una política de AWS Identity and Access Management (IAM) que se adjuntará al rol de ejecución de la función. La política administrada de AWS
AmazonS3FullAccessproporciona a su función los permisos que necesita para leer y escribir objetos en Amazon S3. -
-
Ejecute el comando a continuación en el directorio en el que guardó los archivos
template.yaml,lambda_function.pyyrequirements.txt.sam build --use-containerEste comando recopila los artefactos de compilación de la aplicación y los coloca en el formato y la ubicación adecuados para implementarlos. Con la opción
--use-container, la función se crea dentro de un contenedor de Docker tipo Lambda. Lo usamos aquí para que no necesite tener Python 3.12 instalado en su máquina local para que la compilación funcione.Durante el proceso de compilación, AWS SAM busca el código de la función de Lambda en la ubicación que especificó con la propiedad
CodeUrien la plantilla. En este caso, especificamos el directorio actual como la ubicación (./).Si hay un archivo
requirements.txt, AWS SAM lo usa para recopilar las dependencias especificadas. De forma predeterminada, AWS SAM crea un paquete de implementación .zip con el código y las dependencias de la función. También puede optar por implementar la función como una imagen de contenedor mediante la propiedad PackageType. -
Para implementar la aplicación y crear los recursos de Lambda y Amazon S3 especificados en la plantilla de AWS SAM, ejecute el siguiente comando:
sam deploy --guidedEl uso de la marca
--guidedsignifica que AWS SAM le mostrará instrucciones para guiarlo a lo largo del proceso de implementación. Para esta implementación, acepte las opciones predeterminadas pulsando Intro.
Durante el proceso de implementación, AWS SAM crea los siguientes recursos en su Cuenta de AWS:
-
Una pila de CloudFormation llamada
sam-app -
Una función de Lambda con el nombre
EncryptPDF -
Dos buckets de S3 con los nombres que eligió cuando editó el archivo de plantilla
template.yamlde AWS SAM -
Un rol de ejecución de IAM para la función con el formato de nombre
sam-app-EncryptPDFFunctionRole-2qGaapHFWOQ8
Cuando AWS SAM termine de crear los recursos, debería ver el siguiente mensaje:
Successfully created/updated stack - sam-app in us-east-2Probar la aplicación
Para probar la aplicación, cargue un archivo PDF en el bucket de origen y confirme que Lambda crea una versión cifrada del archivo en el bucket de destino. En este ejemplo, puede probarlo de forma manual mediante la consola o la AWS CLI o usando el script de prueba proporcionado.
Para las aplicaciones de producción, puede utilizar métodos y técnicas de prueba tradicionales, como las pruebas unitarias, para confirmar el correcto funcionamiento del código de la función de Lambda. La mejor práctica también es implementar pruebas como las del script de prueba proporcionado, que llevan a cabo pruebas de integración con recursos reales basados en la nube. Las pruebas de integración en la nube confirman que la infraestructura se desplegó correctamente y que los eventos fluyen entre los distintos servicios según lo esperado. Para obtener más información, consulte Cómo realizar pruebas de funciones y aplicaciones sin servidor.
Para probar la función de forma manual, agregue un archivo PDF a su bucket de origen de Amazon S3. Cuando agrega el archivo al bucket de origen, la función de Lambda se debe invocar de forma automática y debe almacenar una versión cifrada del archivo en el bucket de destino.
Cree los siguientes archivos en el directorio del proyecto:
-
test_pdf_encrypt.py: es un script de prueba que puede usar para probar la aplicación de forma automática -
pytest.ini: es un archivo de configuración para el script de prueba
Expanda las siguientes secciones para ver el código y obtener más información sobre la función de cada archivo.
Copie y pegue el siguiente código en un archivo denominado test_pdf_encrypt.py. Asegúrese de reemplazar los nombres de los buckets del marcador de posición:
-
En la función
test_source_bucket_available, reemplaceamzn-s3-demo-bucketpor el nombre de su bucket de origen. -
En la función
test_encrypted_file_in_bucket, reemplaceamzn-s3-demo-bucket-encryptedporsource-bucket-encrypted, cuandosource-bucket>sea el nombre del bucket de origen. -
En la función
cleanup, sustituyaamzn-s3-demo-bucketpor el nombre del bucket de origen y reemplaceamzn-s3-demo-bucket-encryptedpor el nombre del bucket de destino.
import boto3 import json import pytest import time import os @pytest.fixture def lambda_client(): return boto3.client('lambda') @pytest.fixture def s3_client(): return boto3.client('s3') @pytest.fixture def logs_client(): return boto3.client('logs') @pytest.fixture(scope='session') def cleanup(): # Create a new S3 client for cleanup s3_client = boto3.client('s3') yield # Cleanup code will be executed after all tests have finished # Delete test.pdf from the source bucket source_bucket = 'amzn-s3-demo-bucket' source_file_key = 'test.pdf' s3_client.delete_object(Bucket=source_bucket, Key=source_file_key) print(f"\nDeleted {source_file_key} from {source_bucket}") # Delete test_encrypted.pdf from the destination bucket destination_bucket = 'amzn-s3-demo-bucket-encrypted' destination_file_key = 'test_encrypted.pdf' s3_client.delete_object(Bucket=destination_bucket, Key=destination_file_key) print(f"Deleted {destination_file_key} from {destination_bucket}") @pytest.mark.order(1) def test_source_bucket_available(s3_client): s3_bucket_name = 'amzn-s3-demo-bucket' file_name = 'test.pdf' file_path = os.path.join(os.path.dirname(__file__), file_name) file_uploaded = False try: s3_client.upload_file(file_path, s3_bucket_name, file_name) file_uploaded = True except: print("Error: couldn't upload file") assert file_uploaded, "Could not upload file to S3 bucket" @pytest.mark.order(2) def test_lambda_invoked(logs_client): # Wait for a few seconds to make sure the logs are available time.sleep(5) # Get the latest log stream for the specified log group log_streams = logs_client.describe_log_streams( logGroupName='/aws/lambda/EncryptPDF', orderBy='LastEventTime', descending=True, limit=1 ) latest_log_stream_name = log_streams['logStreams'][0]['logStreamName'] # Retrieve the log events from the latest log stream log_events = logs_client.get_log_events( logGroupName='/aws/lambda/EncryptPDF', logStreamName=latest_log_stream_name ) success_found = False for event in log_events['events']: message = json.loads(event['message']) status = message.get('record', {}).get('status') if status == 'success': success_found = True break assert success_found, "Lambda function execution did not report 'success' status in logs." @pytest.mark.order(3) def test_encrypted_file_in_bucket(s3_client): # Specify the destination S3 bucket and the expected converted file key destination_bucket = 'amzn-s3-demo-bucket-encrypted' converted_file_key = 'test_encrypted.pdf' try: # Attempt to retrieve the metadata of the converted file from the destination S3 bucket s3_client.head_object(Bucket=destination_bucket, Key=converted_file_key) except s3_client.exceptions.ClientError as e: # If the file is not found, the test will fail pytest.fail(f"Converted file '{converted_file_key}' not found in the destination bucket: {str(e)}") def test_cleanup(cleanup): # This test uses the cleanup fixture and will be executed last pass
El script de prueba automatizado ejecuta tres funciones de prueba para confirmar el correcto funcionamiento de la aplicación:
-
La prueba
test_source_bucket_availableconfirma que el bucket de origen se creó correctamente mediante la carga de un archivo PDF de prueba en el bucket. -
La prueba
test_lambda_invokedconsulta el último flujo de registro de los registros de CloudWatch de la función para confirmar que la función de Lambda se ejecutó correctamente cuando cargó el archivo de prueba. -
La prueba
test_encrypted_file_in_bucketconfirma que el bucket de destino contiene el archivo cifradotest_encrypted.pdf.
Una vez ejecutadas todas estas pruebas, el script ejecuta un paso de limpieza adicional para eliminar los archivos test.pdf y test_encrypted.pdf de los buckets de origen y destino.
Los nombres de los buckets especificados en este archivo son marcadores de posición, al igual que en la plantilla AWS SAM. Antes de ejecutar la prueba, debe editar este archivo con los nombres reales de los buckets de la aplicación. Este paso se explica con más detalle en Prueba de la aplicación con el script automatizado
Copie y pegue el siguiente código en un archivo denominado pytest.ini.
[pytest] markers = order: specify test execution order
Esto es necesario para especificar el orden en el que se ejecutan las pruebas del script test_pdf_encrypt.py.
Para ejecutar las pruebas, haga lo siguiente:
-
Asegúrese de que el módulo
pytestesté instalado en el entorno local. Puede instalarpytestejecutando el siguiente comando:pip install pytest -
Guarde un archivo PDF con el nombre
test.pdfen el directorio que contiene los archivostest_pdf_encrypt.pyypytest.ini. -
Abra un programa de terminal o intérprete de comandos y ejecute el siguiente comando desde el directorio que contiene los archivos de prueba:
pytest -s -vCuando concluya la prueba, la salida debe tener el siguiente aspecto:
============================================================== test session starts ========================================================= platform linux -- Python 3.12.2, pytest-7.2.2, pluggy-1.0.0 -- /usr/bin/python3 cachedir: .pytest_cache hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/home/pdf_encrypt_app/.hypothesis/examples') Test order randomisation NOT enabled. Enable with --random-order or --random-order-bucket=<bucket_type> rootdir: /home/pdf_encrypt_app, configfile: pytest.ini plugins: anyio-3.7.1, hypothesis-6.70.0, localserver-0.7.1, random-order-1.1.0 collected 4 items test_pdf_encrypt.py::test_source_bucket_available PASSED test_pdf_encrypt.py::test_lambda_invoked PASSED test_pdf_encrypt.py::test_encrypted_file_in_bucket PASSED test_pdf_encrypt.py::test_cleanup PASSED Deleted test.pdf from amzn-s3-demo-bucket Deleted test_encrypted.pdf from amzn-s3-demo-bucket-encrypted =============================================================== 4 passed in 7.32s ==========================================================
Siguientes pasos
Ahora que creó esta aplicación de ejemplo, puede usar el código proporcionado como base para crear otros tipos de aplicaciones de procesamiento de archivos. Modifique el código del archivo lambda_function.py para implementar la lógica de procesamiento de archivos para su caso de uso.
Muchos casos de uso típicos del procesamiento de archivos implican el procesamiento de imágenes. Cuando se usa Python, las bibliotecas de procesamiento de imágenes más populares, como pillow
Cuando implemente los recursos con AWS SAM, debe tomar algunas medidas adicionales para incluir la distribución de origen correcta en el paquete de implementación. Como AWS SAM no instalará dependencias para una plataforma diferente a la de la máquina de compilación, especificar la distribución de origen (archivo .whl) correcta en su archivo requirements.txt no funcionará si la máquina de compilación usa un sistema operativo o una arquitectura diferente del entorno de ejecución de Lambda. En su lugar, lleve a cabo una de las siguientes acciones:
-
Use la opción
--use-containercuando ejecutesam build. Cuando especifica esta opción, AWS SAM descarga una imagen base de contenedor compatible con el entorno de ejecución de Lambda y compila el paquete de implementación de la función en un contenedor de Docker con esa imagen. Para obtener más información, consulte Creación de una función de Lambda dentro de un contenedor proporcionado. -
Cree usted mismo el paquete de implementación .zip de la función con la distribución binaria de origen correcta y guarde el archivo .zip en el directorio que especifique como
CodeUrien la plantilla AWS SAM. Para obtener más información sobre la compilación de paquetes de implementación .zip para Python mediante distribuciones binarias, consulte Creación de un paquete de despliegue .zip con dependencias y Creación de paquetes de despliegue .zip con bibliotecas nativas.
