Avis de fin de support : le 31 mai 2026, AWS le support de AWS Panorama. Après le 31 mai 2026, vous ne pourrez plus accéder à la AWS Panorama console ni aux AWS Panorama ressources. Pour plus d'informations, voir AWS Panorama fin du support.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Modèles de vision par ordinateur
Un modèle de vision par ordinateur est un logiciel formé pour détecter des objets dans des images. Un modèle apprend à reconnaître un ensemble d'objets en analysant d'abord des images de ces objets par entraînement. Un modèle de vision par ordinateur prend une image en entrée et produit des informations sur les objets qu'il détecte, tels que le type d'objet et son emplacement. AWS Panorama prend en charge les modèles de vision par ordinateur PyTorch créés avec MXNet, Apache et TensorFlow.
Note
Pour obtenir la liste des modèles prédéfinis qui ont été testés avec AWS Panorama, consultez la section Compatibilité des modèles
Sections
Utilisation de modèles dans le code
Un modèle renvoie un ou plusieurs résultats, qui peuvent inclure des probabilités pour les classes détectées, des informations de localisation et d'autres données.L'exemple suivant montre comment exécuter une inférence sur une image à partir d'un flux vidéo et envoyer le résultat du modèle à une fonction de traitement.
Exemple application.py
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
L'exemple suivant montre une fonction qui traite les résultats d'un modèle de classification de base. Le modèle d'échantillon renvoie un tableau de probabilités, qui est la première et unique valeur du tableau de résultats.
Exemple application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
Le code de l'application trouve les valeurs présentant les probabilités les plus élevées et les associe aux étiquettes d'un fichier de ressources chargé lors de l'initialisation.
Création d'un modèle personnalisé
Vous pouvez utiliser les modèles que vous créez dans PyTorch Apache MXNet et TensorFlow dans les applications AWS Panorama. Comme alternative à la création et à la formation de modèles dans l' SageMaker IA, vous pouvez utiliser un modèle entraîné ou créer et entraîner votre propre modèle avec un framework pris en charge et l'exporter dans un environnement local ou sur Amazon EC2.
Note
Pour en savoir plus sur les versions de framework et les formats de fichiers pris en charge par SageMaker AI Neo, consultez la section Frameworks pris en charge dans le manuel Amazon SageMaker AI Developer Guide.
Le référentiel de ce guide fournit un exemple d'application qui illustre ce flux de travail pour un modèle Keras au TensorFlow SavedModel format. Il utilise TensorFlow 2 et peut être exécuté localement dans un environnement virtuel ou dans un conteneur Docker. L'exemple d'application inclut également des modèles et des scripts pour créer le modèle sur une EC2 instance Amazon.
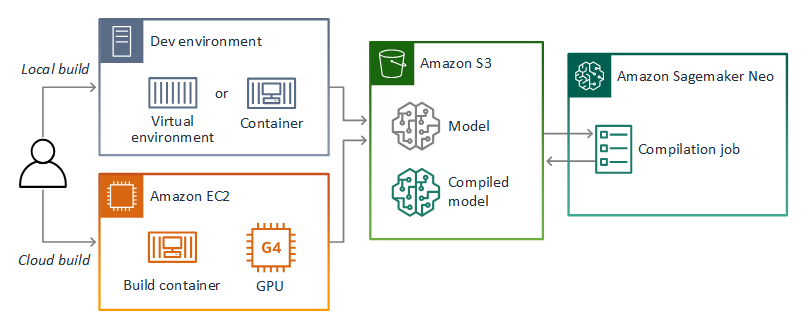
AWS Panorama utilise SageMaker AI Neo pour compiler des modèles destinés à être utilisés sur l'appliance AWS Panorama. Pour chaque framework, utilisez le format pris en charge par SageMaker AI Neo et empaquetez le modèle dans une .tar.gz archive.
Pour plus d'informations, consultez Compiler et déployer des modèles avec Neo dans le manuel Amazon SageMaker AI Developer Guide.
Emballage d'un modèle
Un package modèle comprend un descripteur, une configuration de package et une archive de modèle. Comme dans le cas d'un package d'image d'application, la configuration du package indique au service AWS Panorama où le modèle et le descripteur sont stockés dans Amazon S3.
Exemple Paquets/123456789012-squeezenet_pytorch-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
Note
Spécifiez uniquement les versions majeure et mineure de la version du framework. Pour obtenir la liste des versions prises en charge PyTorch, d'Apache MXNet et des TensorFlow versions, voir Frameworks pris en charge.
Pour importer un modèle, utilisez la import-raw-model commande CLI de l'application AWS Panorama. Si vous apportez des modifications au modèle ou à son descripteur, vous devez réexécuter cette commande pour mettre à jour les actifs de l'application. Pour de plus amples informations, veuillez consulter Modification du modèle de vision par ordinateur.
Pour le schéma JSON du fichier descripteur, consultez AssetDescriptor.schema.json
Entraînement de modèles
Lorsque vous entraînez un modèle, utilisez des images provenant de l'environnement cible ou d'un environnement de test qui ressemble beaucoup à l'environnement cible. Tenez compte des facteurs suivants qui peuvent affecter les performances du modèle :
-
Éclairage : la quantité de lumière réfléchie par un sujet détermine le niveau de détail que le modèle doit analyser. Un modèle entraîné avec des images de sujets bien éclairés peut ne pas fonctionner correctement dans un environnement peu éclairé ou rétroéclairé.
-
Résolution — La taille d'entrée d'un modèle est généralement fixée à une résolution comprise entre 224 et 512 pixels de large dans un format carré. Avant de transférer une image vidéo au modèle, vous pouvez la réduire ou la recadrer pour l'adapter à la taille requise.
-
Distorsion de l'image : la distance focale et la forme de l'objectif d'un appareil photo peuvent entraîner une distorsion des images par rapport au centre du cadre. La position d'une caméra détermine également les caractéristiques visibles d'un sujet. Par exemple, un rétroviseur équipé d'un objectif grand angle affiche le dessus d'un sujet lorsqu'il se trouve au centre du cadre, et une vue biaisée du côté du sujet lorsqu'il s'éloigne du centre.
Pour résoudre ces problèmes, vous pouvez prétraiter les images avant de les envoyer au modèle et entraîner le modèle sur une plus grande variété d'images qui reflètent les variations dans les environnements réels. Si un modèle doit fonctionner dans des situations d'éclairage et avec une variété de caméras, vous avez besoin de plus de données pour la formation. En plus de collecter davantage d'images, vous pouvez obtenir davantage de données d'entraînement en créant des variations de vos images existantes qui sont biaisées ou ont un éclairage différent.
