Bantu tingkatkan halaman ini
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Untuk berkontribusi pada panduan pengguna ini, pilih Edit halaman ini pada GitHub tautan yang terletak di panel kanan setiap halaman.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pelajari tentang pergeseran zona Amazon Application Recovery Controller (ARC) di Amazon EKS
Kubernetes memiliki fitur asli yang memungkinkan Anda membuat aplikasi Anda lebih tahan terhadap peristiwa seperti penurunan kesehatan atau gangguan Availability Zone (AZ). Saat menjalankan beban kerja di klaster Amazon EKS, Anda dapat lebih meningkatkan toleransi kesalahan lingkungan aplikasi dan pemulihan aplikasi dengan menggunakan pergeseran zona Amazon Application Recovery Controller (ARC) atau pergeseran otomatis zona. Pergeseran zona ARC dirancang untuk menjadi tindakan sementara yang memungkinkan Anda memindahkan lalu lintas untuk sumber daya dari AZ yang rusak hingga pergeseran zona berakhir atau Anda membatalkannya. Anda dapat memperpanjang pergeseran zona, jika perlu.
Anda dapat memulai pergeseran zona untuk kluster EKS, atau Anda dapat mengizinkan AWS untuk menggeser lalu lintas untuk Anda dengan mengaktifkan pergeseran otomatis zona. Pergeseran ini memperbarui aliran lalu lintas jaringan timur-ke-barat di klaster Anda untuk hanya mempertimbangkan titik akhir jaringan untuk Pod yang berjalan pada node pekerja di AZ yang sehat. Selain itu, ALB atau NLB apa pun yang menangani lalu lintas masuk untuk aplikasi di kluster EKS Anda akan secara otomatis merutekan lalu lintas ke target di AZ yang sehat. Bagi pelanggan yang mencari tujuan ketersediaan tertinggi, jika AZ menjadi terganggu, penting untuk dapat mengarahkan semua lalu lintas dari AZ yang rusak hingga pulih. Untuk ini, Anda juga dapat mengaktifkan ALB atau NLB dengan ARC zonal shift.
Memahami arus lalu lintas jaringan timur-barat antar Pod
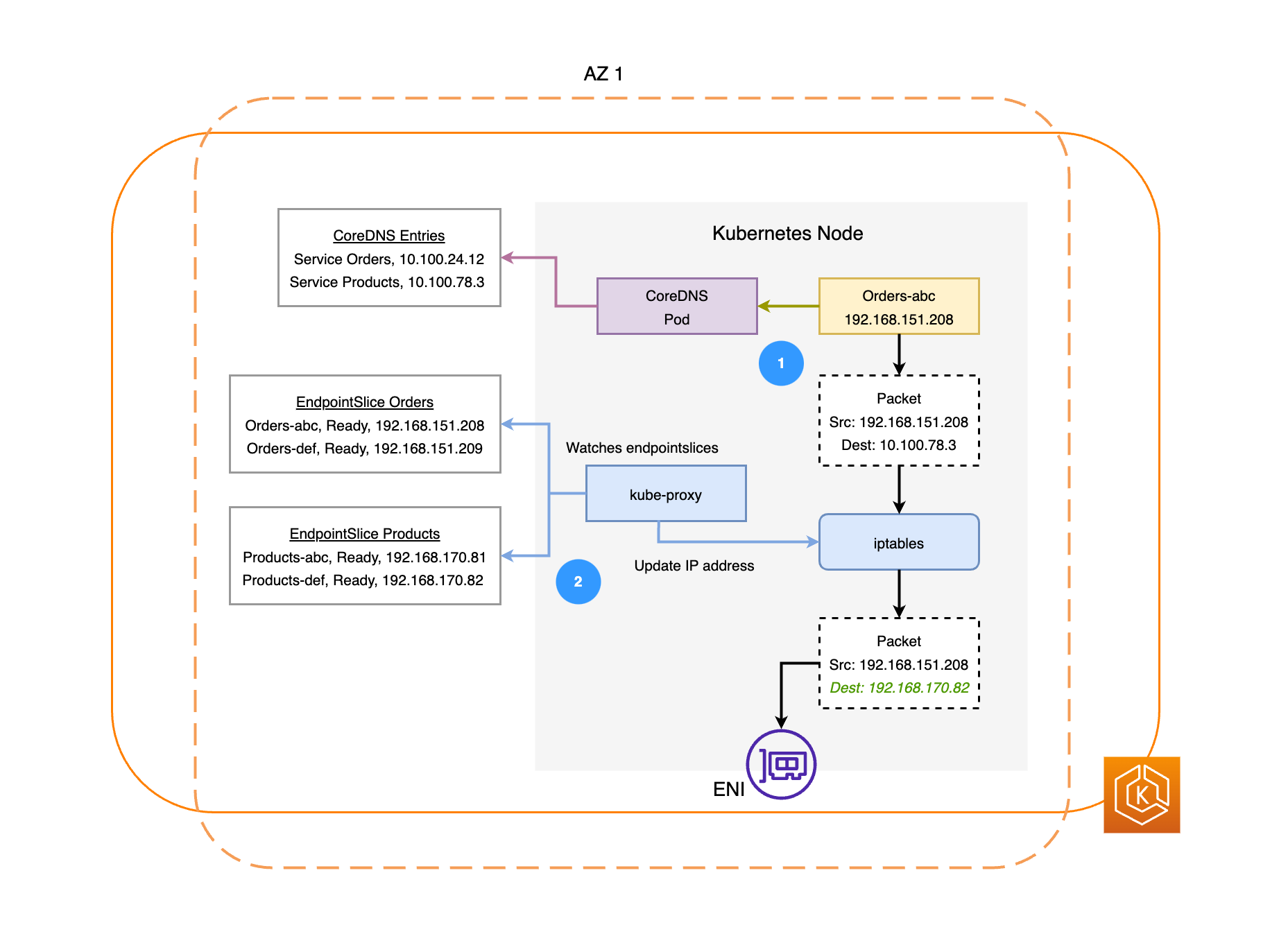
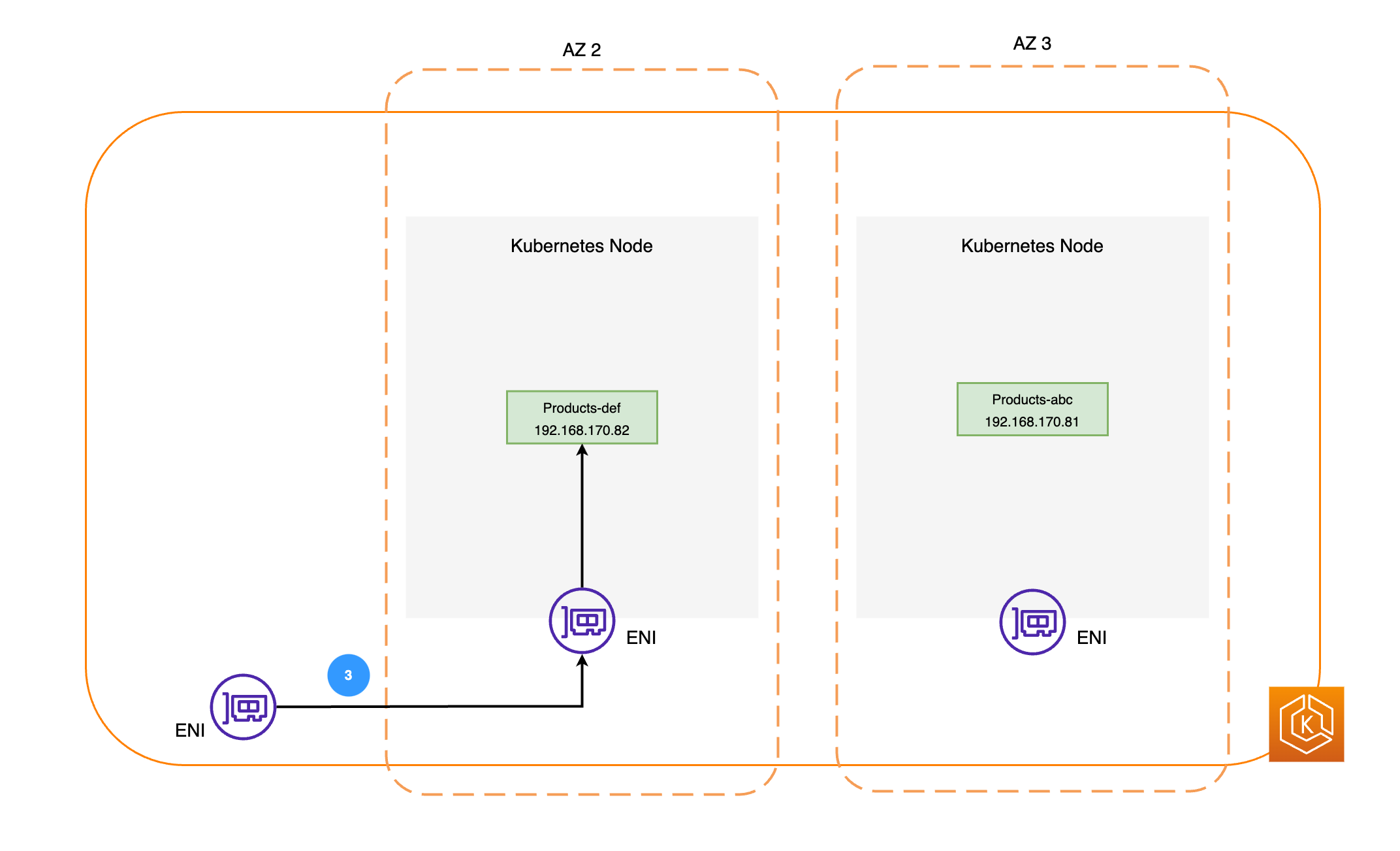
Diagram berikut menggambarkan dua contoh beban kerja, Pesanan, dan Produk. Tujuan dari contoh ini adalah untuk menunjukkan bagaimana beban kerja dan Pod dalam AZ yang berbeda berkomunikasi.
-
Agar Pesanan dapat berkomunikasi dengan Produk, Pesanan harus terlebih dahulu menyelesaikan nama DNS dari layanan tujuan. Pesanan berkomunikasi dengan CoreDNS untuk mengambil alamat IP virtual (Cluster IP) untuk layanan itu. Setelah Pesanan menyelesaikan nama layanan Produk, ia mengirimkan lalu lintas ke alamat IP target tersebut.
-
Kube-proxy berjalan pada setiap node di cluster dan terus mengawasi EndpointSlices
layanan. Ketika layanan dibuat, sebuah EndpointSlice dibuat dan dikelola di latar belakang oleh EndpointSlice controller. Masing-masing EndpointSlice memiliki daftar atau tabel titik akhir yang berisi subset alamat Pod, bersama dengan node yang mereka jalankan. Kube-proxy mengatur aturan routing untuk masing-masing titik akhir Pod yang digunakan pada node. iptablesKube-proxy juga bertanggung jawab untuk bentuk dasar load balancing, mengarahkan lalu lintas yang ditujukan ke alamat IP Cluster layanan untuk dikirim ke alamat IP Pod secara langsung. Kube-proxy melakukan ini dengan menulis ulang alamat IP tujuan pada koneksi keluar. -
Paket jaringan kemudian dikirim ke Products Pod di AZ 2 dengan menggunakan ENI pada node masing-masing, seperti yang ditunjukkan pada diagram sebelumnya.
Memahami pergeseran zona ARC di Amazon EKS
Jika ada gangguan AZ di lingkungan Anda, Anda dapat memulai pergeseran zona untuk lingkungan cluster EKS Anda. Atau, Anda dapat mengizinkan AWS untuk mengelola lalu lintas yang bergeser untuk Anda dengan zonal autoshift. Dengan pergeseran otomatis zona, AWS memantau kesehatan AZ secara keseluruhan dan merespons potensi gangguan AZ dengan secara otomatis mengalihkan lalu lintas dari AZ yang terganggu di lingkungan klaster Anda.
Setelah klaster Amazon EKS Anda mengaktifkan pergeseran zona dengan ARC, Anda dapat memulai pergeseran zona atau mengaktifkan pergeseran otomatis zona dengan menggunakan Konsol ARC, AWS CLI, atau pergeseran zona dan API pergeseran otomatis zona. Selama pergeseran zona EKS, berikut ini dilakukan secara otomatis:
-
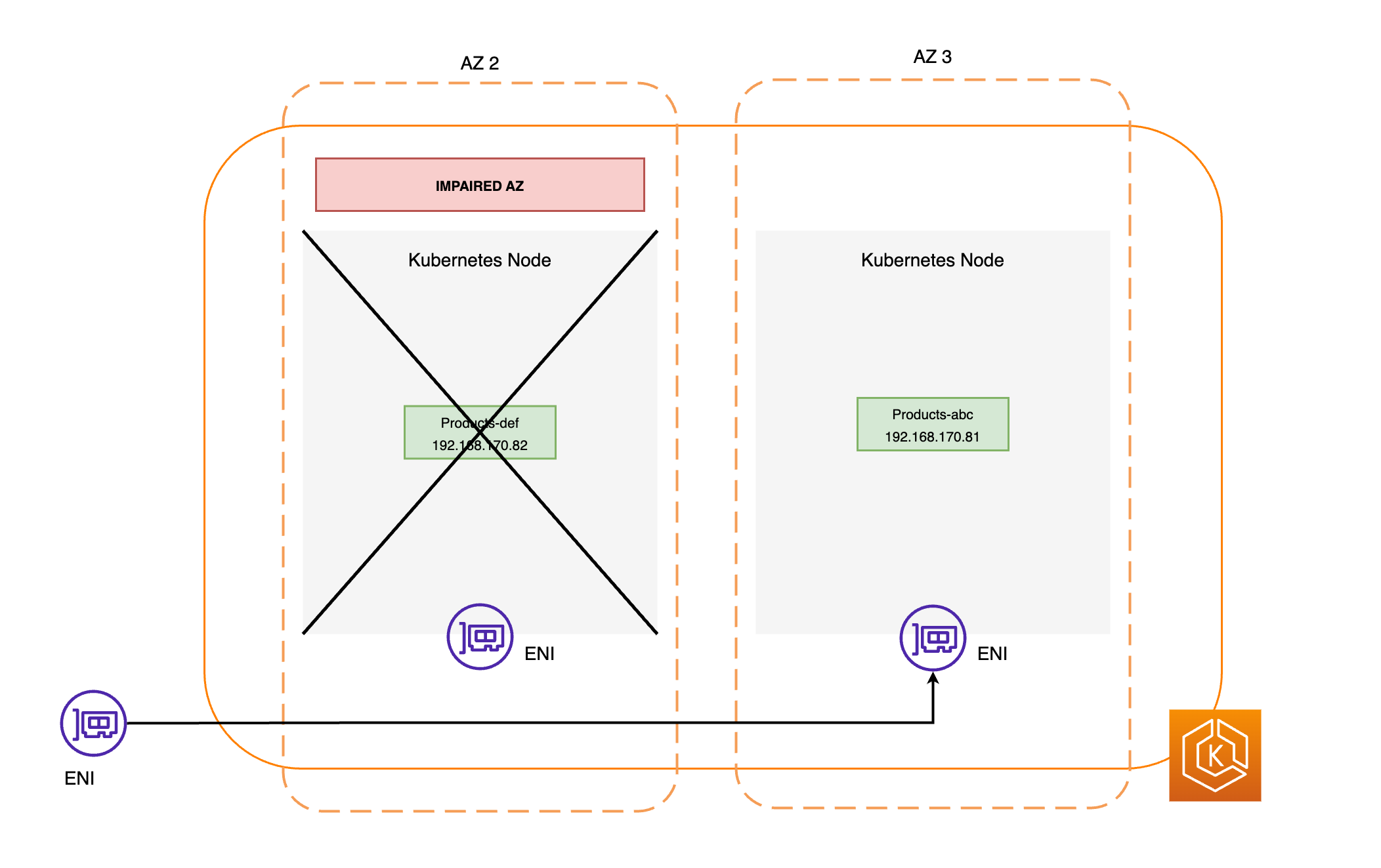
Semua node di AZ yang terkena dampak ditutup. Hal ini mencegah Kubernetes Scheduler menjadwalkan Pod baru ke node di AZ yang tidak sehat.
-
Jika Anda menggunakan Mode Otomatis EKS, Mode Otomatis EKS secara otomatis berhenti menyediakan node baru di AZ yang rusak. Tindakan gangguan sukarela seperti konsolidasi dan penyimpangan yang akan mempengaruhi AZ yang terganggu juga ditangguhkan. Pod dengan persyaratan penjadwalan ketat yang menargetkan AZ yang mengalami gangguan (seperti binding volume persisten, afinitas node, atau batasan penyebaran topologi yang ketat) tidak menghasilkan upaya peluncuran node baru ke AZ tersebut.
-
Jika Anda menggunakan Grup Node Terkelola, penyeimbangan ulang Availability Zone ditangguhkan, dan grup Auto Scaling Anda diperbarui untuk memastikan bahwa node pesawat data EKS baru hanya diluncurkan di AZ yang sehat.
-
Node di AZ yang tidak sehat tidak dihentikan, dan Pod tidak diusir dari node. Ini memastikan bahwa ketika pergeseran zona berakhir atau dibatalkan, lalu lintas Anda dapat dikembalikan dengan aman ke AZ untuk kapasitas penuh.
-
EndpointSlice Pengontrol menemukan semua titik akhir Pod di AZ yang rusak, dan menghapusnya dari yang relevan EndpointSlices. Ini memastikan bahwa hanya titik akhir Pod di AZ sehat yang ditargetkan untuk menerima lalu lintas jaringan. Ketika pergeseran zona dibatalkan atau kedaluwarsa, EndpointSlice pengontrol memperbarui EndpointSlices untuk menyertakan titik akhir di AZ yang dipulihkan.
Diagram berikut memberikan gambaran tingkat tinggi tentang bagaimana pergeseran zona EKS memastikan bahwa hanya titik akhir Pod yang sehat yang ditargetkan di lingkungan klaster Anda.

Persyaratan pergeseran zona EKS
penting
Pergeseran zona menggeser semua lalu lintas dalam cluster menjauh dari Availability Zone. Jika beban kerja Anda tidak tersebar di beberapa AZ dengan replika yang cukup, memulai pergeseran zona itu sendiri dapat menyebabkan dampak ketersediaan pada aplikasi Anda karena tidak ada titik akhir yang sehat untuk menerima lalu lintas. Anda harus memvalidasi bahwa lingkungan cluster Anda dapat beroperasi dengan satu AZ lebih sedikit sebelum mengaktifkan pergeseran otomatis zona atau memulai pergeseran zona manual.
Agar pergeseran zona berhasil bekerja dengan EKS, Anda harus mengatur lingkungan cluster Anda sebelumnya agar tahan terhadap gangguan AZ. Berikut ini adalah daftar opsi konfigurasi yang membantu memastikan ketahanan.
-
Menyediakan node pekerja klaster Anda di beberapa AZ
-
Menyediakan kapasitas komputasi yang cukup untuk mengakomodasi penghapusan AZ tunggal
-
Pre-scale Pod Anda, termasuk CoreDNS, di setiap AZ
-
Sebarkan beberapa replika Pod di semua AZ, untuk membantu memastikan bahwa ketika Anda beralih dari satu AZ, Anda masih akan memiliki kapasitas yang cukup
-
Kolokasi Pod yang saling bergantung atau terkait di AZ yang sama
-
Uji apakah lingkungan cluster Anda berfungsi seperti yang diharapkan tanpa satu AZ dengan memulai pergeseran zona secara manual dari AZ. Atau, Anda dapat mengaktifkan pergeseran otomatis zona dan mengandalkan latihan autoshift. Pengujian dengan pergeseran zona manual atau praktik tidak diperlukan agar pergeseran zona bekerja di EKS tetapi sangat disarankan.
Menyediakan node pekerja EKS Anda di beberapa Availability Zone
AWS Wilayah memiliki beberapa lokasi terpisah dengan pusat data fisik, yang dikenal sebagai Availability Zones (AZ). AZ dirancang untuk diisolasi secara fisik satu sama lain untuk menghindari dampak simultan yang dapat mempengaruhi seluruh Wilayah. Saat Anda menyediakan kluster EKS, sebaiknya Anda menerapkan node pekerja di beberapa AZ di Region. Ini membantu membuat lingkungan klaster Anda lebih tahan terhadap kerusakan satu AZ, dan memungkinkan Anda mempertahankan ketersediaan tinggi untuk aplikasi Anda yang berjalan di AZ lain. Saat Anda memulai pergeseran zona dari AZ yang terkena dampak, jaringan in-cluster lingkungan EKS Anda secara otomatis diperbarui untuk hanya menggunakan AZ yang sehat, untuk membantu menjaga ketersediaan tinggi untuk klaster Anda.
Memastikan bahwa Anda memiliki pengaturan Multi-AZ untuk lingkungan EKS Anda meningkatkan keandalan keseluruhan sistem Anda. Namun, lingkungan multi-AZ memengaruhi cara data aplikasi ditransfer dan diproses, yang pada gilirannya berdampak pada biaya jaringan lingkungan Anda. Secara khusus, lalu lintas lintas zona keluar yang sering (lalu lintas yang didistribusikan antar AZ) dapat berdampak besar pada biaya terkait jaringan Anda. Anda dapat menerapkan berbagai strategi untuk mengontrol jumlah lalu lintas lintas zona antar Pod di klaster EKS Anda dan menurunkan biaya terkait. Untuk informasi selengkapnya tentang cara mengoptimalkan biaya jaringan saat menjalankan lingkungan EKS yang sangat tersedia, lihat praktik terbaik ini
Diagram berikut menggambarkan lingkungan EKS yang sangat tersedia dengan tiga AZ sehat.

Diagram berikut menggambarkan bagaimana lingkungan EKS dengan tiga AZ tahan terhadap gangguan AZ dan tetap sangat tersedia karena ada dua AZ sehat yang tersisa.

Menyediakan kapasitas komputasi yang cukup untuk menahan penghapusan satu Availability Zone
Untuk mengoptimalkan pemanfaatan sumber daya dan biaya untuk infrastruktur komputasi Anda di bidang data EKS, ini adalah praktik terbaik untuk menyelaraskan kapasitas komputasi dengan persyaratan beban kerja Anda. Namun, jika semua node pekerja Anda berada pada kapasitas penuh, Anda bergantung pada node pekerja baru yang ditambahkan ke bidang data EKS sebelum Pod baru dapat dijadwalkan. Saat Anda menjalankan beban kerja kritis, umumnya merupakan praktik yang baik untuk dijalankan dengan kapasitas berlebihan secara online untuk menangani skenario seperti peningkatan beban dan masalah kesehatan node secara tiba-tiba. Jika Anda berencana untuk menggunakan pergeseran zona, Anda berencana untuk menghapus seluruh AZ kapasitas ketika ada gangguan. Ini berarti Anda harus menyesuaikan kapasitas komputasi redundan sehingga cukup untuk menangani beban bahkan dengan salah satu AZ offline.
Saat Anda menskalakan sumber daya komputasi Anda, proses menambahkan node baru ke bidang data EKS membutuhkan waktu. Ini dapat berimplikasi pada kinerja real-time dan ketersediaan aplikasi Anda, terutama jika terjadi gangguan zona. Lingkungan EKS Anda harus dapat menyerap beban kehilangan satu AZ tanpa menghasilkan pengalaman yang terdegradasi bagi pengguna akhir atau klien Anda. Ini berarti meminimalkan atau menghilangkan jeda antara waktu ketika Pod baru dibutuhkan dan kapan sebenarnya dijadwalkan pada node pekerja.
Selain itu, ketika ada gangguan zona, Anda harus bertujuan untuk mengurangi risiko mengalami kendala kapasitas komputasi yang akan mencegah node yang baru diperlukan ditambahkan ke bidang data EKS Anda di AZ yang sehat.
Untuk mengurangi risiko potensi dampak negatif ini, kami menyarankan Anda untuk menyediakan kapasitas komputasi yang berlebihan di beberapa node pekerja di setiap AZ. Dengan melakukan ini, Kubernetes Scheduler memiliki kapasitas yang sudah ada sebelumnya yang tersedia untuk penempatan Pod baru, yang sangat penting ketika Anda kehilangan salah satu AZ di lingkungan Anda.
Jalankan dan sebarkan beberapa replika Pod di seluruh Availability Zone
Kubernetes memungkinkan Anda untuk melakukan pra-skala beban kerja Anda dengan menjalankan beberapa instance (replika Pod) dari satu aplikasi. Menjalankan beberapa replika Pod untuk sebuah aplikasi menghilangkan satu titik kegagalan dan meningkatkan kinerja secara keseluruhan dengan mengurangi ketegangan sumber daya pada satu replika. Namun, untuk memiliki ketersediaan tinggi dan toleransi kesalahan yang lebih baik untuk aplikasi Anda, kami sarankan Anda menjalankan beberapa replika aplikasi Anda dan menyebarkan replika di berbagai domain kegagalan, juga disebut sebagai domain topologi. Domain kegagalan dalam skenario ini adalah Availability Zones. Dengan menggunakan kendala penyebaran topologi
Diagram berikut menggambarkan lingkungan EKS yang memiliki arus lalu lintas timur-ke-barat ketika semua AZ sehat.

Diagram berikut menggambarkan lingkungan EKS yang memiliki arus lalu lintas timur-ke-barat di mana satu AZ gagal dan Anda telah memulai pergeseran zona.

Cuplikan kode berikut adalah contoh cara mengatur beban kerja Anda dengan beberapa replika di Kubernetes.
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
Yang paling penting, Anda harus menjalankan beberapa replika perangkat lunak server DNS Anda (CoreDNS/kube-dns) dan menerapkan batasan penyebaran topologi serupa, jika tidak dikonfigurasi secara default. Ini membantu memastikan bahwa, jika ada satu gangguan AZ, Anda memiliki cukup Pod DNS di AZ yang sehat untuk terus menangani permintaan penemuan layanan untuk Pod lain yang berkomunikasi di klaster. Add-on CoreDNS EKS memiliki pengaturan default untuk Pod CoreDNS yang memastikan bahwa, jika ada node di beberapa AZ yang tersedia, mereka tersebar di Availability Zone klaster Anda. Jika mau, Anda dapat mengganti pengaturan default ini dengan konfigurasi kustom Anda sendiri.
Saat Anda menginstal CoreDNS denganreplicaCount file in values.yamltopologySpreadConstraints properti dalam file yang samavalues.yaml. Cuplikan kode berikut menggambarkan bagaimana Anda dapat mengonfigurasi CoreDNS untuk melakukan ini.
CoreDNS Helm nilai.yaml
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
Jika ada gangguan AZ, Anda dapat menyerap peningkatan beban pada Pod CoreDNS dengan menggunakan sistem penskalaan otomatis untuk CoreDNS. Jumlah instans DNS yang Anda perlukan bergantung pada jumlah beban kerja yang berjalan di klaster Anda. CoreDNS adalah CPU bound, yang memungkinkannya untuk skala berdasarkan CPU dengan menggunakan Horizontal Pod Autoscaler
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
Atau, EKS dapat mengelola penskalaan otomatis penerapan CoreDNS di CoreDNS versi add-on EKS. Autoscaler CoreDNS ini terus memantau status cluster, termasuk jumlah node dan core CPU. Berdasarkan informasi tersebut, pengontrol secara dinamis menyesuaikan jumlah replika penerapan CoreDNS di cluster EKS.
Untuk mengaktifkan konfigurasi penskalaan otomatis di add-on CoreDNS EKS, gunakan pengaturan konfigurasi berikut:
{ "autoScaling": { "enabled": true } }
Anda juga dapat menggunakan NodeLocal DNS
Kolokasi Pod yang saling bergantung di Availability Zone yang sama
Biasanya, aplikasi memiliki beban kerja yang berbeda yang perlu berkomunikasi satu sama lain untuk berhasil menyelesaikan proses end-to-end. Jika aplikasi berbeda ini tersebar di AZ yang berbeda dan tidak ditempatkan di AZ yang sama, maka satu gangguan AZ dapat memengaruhi proses ujung ke ujung. Misalnya, jika Aplikasi A memiliki beberapa replika di AZ 1 dan AZ 2, tetapi Aplikasi B memiliki semua replika di AZ 3, maka hilangnya AZ 3 akan memengaruhi proses ujung ke ujung antara dua beban kerja, Aplikasi A dan Aplikasi B. Jika Anda menggabungkan batasan penyebaran topologi dengan afinitas pod, Anda dapat meningkatkan ketahanan aplikasi Anda dengan menyebarkan Pod ke semua AZ. Selain itu, ini mengonfigurasi hubungan antara Pod tertentu untuk memastikan bahwa mereka terkolokasi.
Dengan aturan afinitas pod
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Diagram berikut menunjukkan beberapa pod yang telah dikolokasi pada node yang sama dengan menggunakan aturan afinitas pod.

Uji apakah lingkungan cluster Anda dapat menangani hilangnya AZ
Setelah Anda menyelesaikan persyaratan yang dijelaskan di bagian sebelumnya, langkah selanjutnya adalah menguji apakah Anda memiliki kapasitas komputasi dan beban kerja yang cukup untuk menangani hilangnya AZ. Anda dapat melakukan ini dengan memulai pergeseran zona secara manual di EKS. Atau, Anda dapat mengaktifkan zonal autoshift dan mengkonfigurasi praktik berjalan, yang juga menguji apakah aplikasi Anda berfungsi seperti yang diharapkan dengan satu AZ yang lebih sedikit di lingkungan cluster Anda.
Pertanyaan umum
Mengapa saya harus menggunakan fitur ini?
Dengan menggunakan ARC zonal shift atau zonal autoshift di kluster EKS Anda, Anda dapat mempertahankan ketersediaan aplikasi Kubernetes dengan lebih baik dengan mengotomatiskan proses pemulihan cepat untuk mengalihkan lalu lintas jaringan in-cluster dari AZ yang rusak. Dengan ARC, Anda dapat menghindari langkah-langkah panjang dan rumit yang dapat menyebabkan periode pemulihan yang diperpanjang selama peristiwa AZ yang terganggu.
Bagaimana cara kerja fitur ini dengan AWS layanan lain?
EKS terintegrasi dengan ARC, yang menyediakan antarmuka utama bagi Anda untuk menyelesaikan operasi pemulihan di. AWS Untuk memastikan bahwa lalu lintas in-cluster dialihkan dengan tepat dari AZ yang rusak, EKS membuat modifikasi pada daftar titik akhir jaringan untuk Pod yang berjalan di bidang data Kubernetes. Jika Anda menggunakan Elastic Load Balancing untuk merutekan lalu lintas eksternal ke cluster, Anda dapat mendaftarkan penyeimbang beban Anda dengan ARC dan memulai pergeseran zona untuk mencegah lalu lintas mengalir ke AZ yang terdegradasi. Jika Anda menggunakan Mode Otomatis EKS, Mode Otomatis EKS secara otomatis membatasi penyediaan node ke AZ yang sehat. Zonal shift juga berfungsi dengan grup Amazon EC2 Auto Scaling yang dibuat oleh grup node terkelola EKS. Untuk mencegah AZ yang rusak digunakan untuk Pod Kubernetes atau peluncuran node baru, EKS menghapus AZ yang rusak dari grup Auto Scaling.
Apa perbedaan fitur ini dengan perlindungan Kubernetes default?
Fitur ini bekerja bersama-sama dengan beberapa perlindungan bawaan Kubernetes yang membantu ketahanan aplikasi pelanggan. Anda dapat mengonfigurasi probe kesiapan dan keaktifan Pod yang menentukan kapan Pod harus mengambil lalu lintas. Ketika probe ini gagal, Kubernetes menghapus Pod ini sebagai target untuk layanan, dan lalu lintas tidak lagi dikirim ke Pod. Meskipun ini berguna, tidak mudah bagi pelanggan untuk mengonfigurasi pemeriksaan kesehatan ini sehingga dijamin gagal ketika AZ terdegradasi. Fitur ARC zonal shift menyediakan jaring pengaman tambahan yang membantu Anda mengisolasi AZ yang terdegradasi sepenuhnya ketika perlindungan asli Kubernetes tidak cukup. Pergeseran zona juga memberi Anda cara mudah untuk menguji kesiapan operasional dan ketahanan arsitektur Anda.
Bisakah AWS memulai pergeseran zona atas nama saya?
Ya, jika Anda menginginkan cara yang sepenuhnya otomatis menggunakan pergeseran zona ARC, Anda dapat mengaktifkan pergeseran otomatis zona ARC. Dengan pergeseran otomatis zona, Anda dapat mengandalkan AWS untuk memantau kesehatan AZ untuk cluster EKS Anda, dan untuk secara otomatis memulai pergeseran zona ketika gangguan AZ terdeteksi.
Apa yang terjadi jika saya menggunakan fitur ini dan node pekerja serta beban kerja saya tidak diskalakan sebelumnya?
Jika Anda tidak melakukan pra-skala dan mengandalkan penyediaan node atau Pod tambahan selama pergeseran zona, Anda berisiko mengalami pemulihan yang tertunda. Proses penambahan node baru ke bidang data Kubernetes membutuhkan waktu lama, yang dapat memengaruhi kinerja dan ketersediaan aplikasi Anda secara real-time, terutama ketika ada gangguan zona. Selain itu, jika terjadi gangguan zona, Anda mungkin menghadapi kendala kapasitas komputasi potensial yang dapat mencegah node yang baru diperlukan ditambahkan ke AZ yang sehat.
Jika Anda menggunakan Mode Otomatis EKS, Mode Otomatis EKS secara otomatis menyediakan node baru dalam AZ yang sehat untuk memenuhi permintaan Pod yang tidak dapat dijadwalkan. Namun, node baru masih membutuhkan waktu untuk diluncurkan dan siap. Untuk pemulihan tercepat, kami sarankan pra-penskalaan beban kerja Anda di beberapa AZ.
Jika beban kerja Anda tidak diskalakan sebelumnya dan tersebar di semua AZ di klaster Anda, gangguan zona dapat memengaruhi ketersediaan aplikasi yang hanya berjalan pada node pekerja di AZ yang terkena dampak. Untuk mengurangi risiko pemadaman ketersediaan lengkap untuk aplikasi Anda, EKS memiliki keamanan yang gagal untuk lalu lintas yang dikirim ke titik akhir Pod di zona yang terganggu jika beban kerja tersebut memiliki semua titik akhir di AZ yang tidak sehat. Namun, kami sangat menyarankan Anda melakukan pra-skala dan menyebarkan aplikasi Anda ke semua AZ untuk menjaga ketersediaan jika terjadi masalah zona.
Bagaimana cara kerjanya jika saya menjalankan aplikasi stateful?
Jika Anda menjalankan aplikasi stateful, Anda harus menilai toleransi kesalahannya, berdasarkan kasus penggunaan dan arsitektur Anda. Jika Anda memiliki active/standby arsitektur atau pola, mungkin ada contoh di mana aktif berada di AZ yang rusak. Pada tingkat aplikasi, jika siaga tidak diaktifkan, Anda mungkin mengalami masalah dengan aplikasi Anda. Anda mungkin juga mengalami masalah ketika Pod Kubernetes baru diluncurkan dalam AZ yang sehat, karena mereka tidak akan dapat melampirkan ke volume persisten yang dibatasi ke AZ yang rusak.
Apakah fitur ini berfungsi dengan Mode Otomatis EKS?
Ya. Saat Anda mengaktifkan pergeseran zona pada kluster Mode Otomatis EKS, Mode Otomatis EKS secara otomatis merespons peristiwa pergeseran zona. Selama pergeseran zona, Mode Otomatis EKS berhenti menyediakan node baru di AZ yang mengalami gangguan, menangguhkan tindakan gangguan sukarela (seperti konsolidasi dan penyimpangan) yang akan memengaruhi AZ yang mengalami gangguan, dan menghindari kapasitas peluncuran untuk Pod dengan persyaratan penjadwalan ketat yang menargetkan AZ yang mengalami gangguan. Anda tidak memerlukan konfigurasi tambahan selain mengaktifkan pergeseran zona pada cluster.
Apakah fitur ini berfungsi dengan Karpenter yang dikelola sendiri?
Self-managed Dukungan Karpenter tersedia dengan ARC zonal shift dan zonal autoshift di EKS dengan Karpenter
Apakah fitur ini berfungsi dengan EKS Fargate?
Fitur ini tidak berfungsi dengan EKS Fargate. Secara default, ketika EKS Fargate mengenali peristiwa kesehatan zona, Pod akan lebih memilih untuk berjalan di AZ lain.
Apakah pesawat kontrol Kubernetes yang dikelola EKS akan terkena dampak?
Tidak, secara default Amazon EKS menjalankan dan menskalakan bidang kontrol Kubernetes di beberapa AZ untuk memastikan ketersediaan yang tinggi. ARC zonal shift dan zonal autoshift hanya bekerja pada bidang data Kubernetes.
Apakah ada biaya yang terkait dengan fitur baru ini?
Anda dapat menggunakan ARC zonal shift dan zonal autoshift di kluster EKS Anda tanpa biaya tambahan. Namun, Anda akan terus membayar instans yang telah disediakan dan kami sangat menyarankan agar Anda melakukan pra-skala pesawat data Kubernetes sebelum menggunakan fitur ini. Anda harus mempertimbangkan keseimbangan antara biaya dan ketersediaan aplikasi.
Sumber daya tambahan
