Pemberitahuan akhir dukungan: Pada 31 Oktober 2025, AWS akan menghentikan dukungan untuk Amazon Lookout for Vision. Setelah 31 Oktober 2025, Anda tidak akan lagi dapat mengakses konsol Lookout for Vision atau sumber daya Lookout for Vision. Untuk informasi lebih lanjut, kunjungi posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memahami Amazon Lookout for Vision
Anda dapat menggunakan Amazon Lookout for Vision untuk menemukan cacat visual pada produk industri, secara akurat dan sesuai skala, untuk tugas-tugas seperti:
-
Mendeteksi bagian yang rusak - Mendeteksi kerusakan pada kualitas permukaan, warna, dan bentuk produk selama proses fabrikasi dan perakitan.
-
Mengidentifikasi komponen yang hilang — Menentukan komponen yang hilang berdasarkan ketidakhadiran, keberadaan, atau penempatan objek. Misalnya, kapasitor yang hilang pada papan sirkuit tercetak.
-
Mengungkap masalah proses — Mendeteksi cacat dengan pola berulang, seperti goresan berulang di tempat yang sama pada wafer silikon.
Dengan Lookout for Vision Anda membuat model visi komputer yang memprediksi adanya anomali dalam gambar. Anda memberikan gambar yang digunakan Amazon Lookout for Vision untuk melatih dan menguji model Anda. Amazon Lookout for Vision menyediakan metrik yang dapat Anda gunakan untuk mengevaluasi dan meningkatkan model terlatih Anda. Anda dapat meng-host model terlatih di AWS cloud atau Anda dapat menerapkan model ke perangkat edge. APIOperasi sederhana mengembalikan prediksi yang dibuat model Anda.
Alur kerja umum untuk membuat, mengevaluasi, dan menggunakan model adalah sebagai berikut:
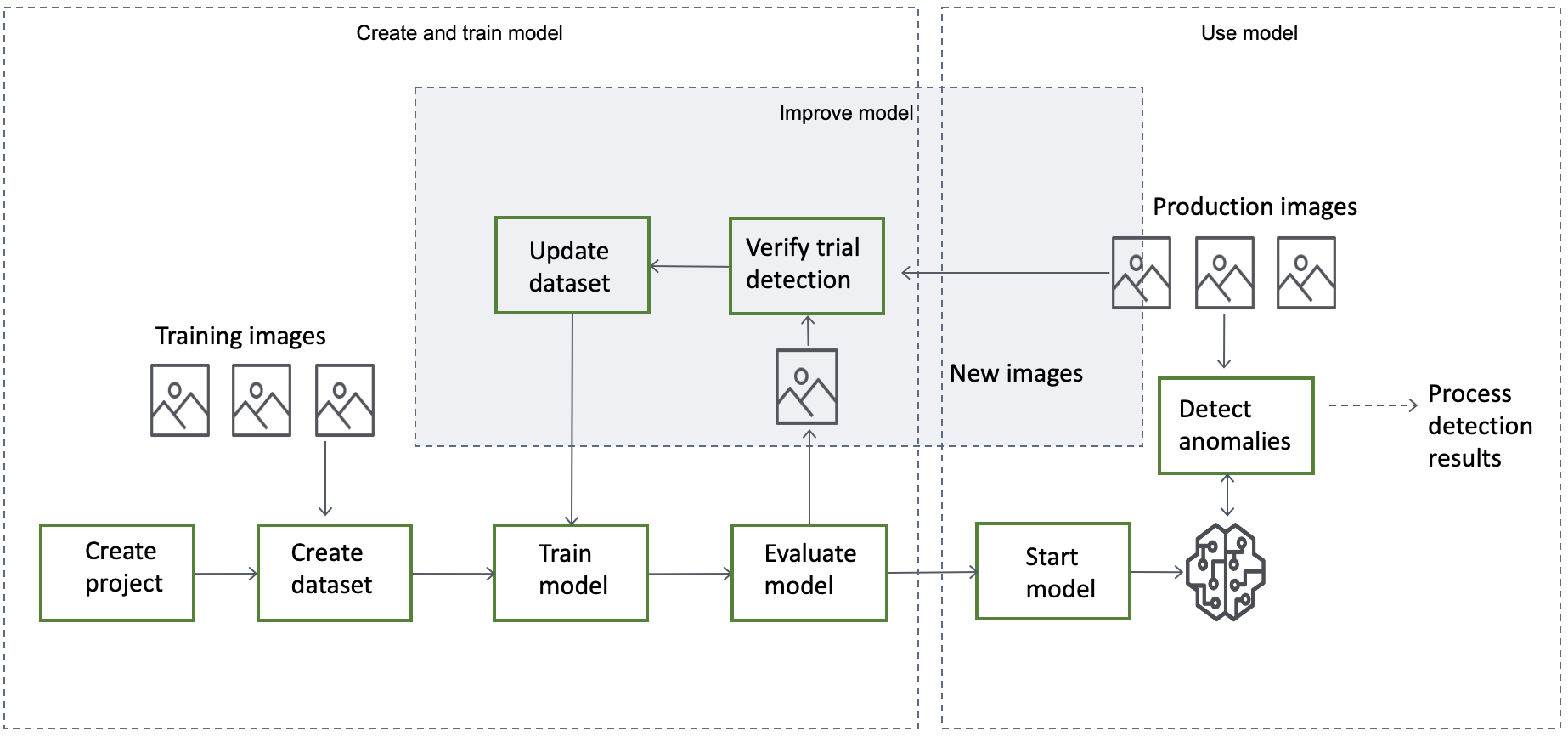
Topik
Pilih jenis model Anda
Sebelum Anda dapat membuat model, Anda harus memutuskan jenis model yang Anda inginkan. Anda dapat membuat dua jenis model, klasifikasi gambar dan segmentasi gambar. Anda memutuskan jenis model yang akan dibuat berdasarkan kasus penggunaan Anda.
Model klasifikasi gambar
Jika Anda hanya perlu tahu apakah suatu gambar mengandung anomali, tetapi tidak perlu mengetahui lokasinya, buat model klasifikasi gambar. Model klasifikasi gambar membuat prediksi apakah suatu gambar mengandung anomali. Prediksi tersebut mencakup kepercayaan model pada keakuratan prediksi. Model tidak memberikan informasi apa pun tentang lokasi anomali yang ditemukan pada gambar.
Model segmentasi gambar
Jika Anda perlu mengetahui lokasi anomali, seperti lokasi goresan, buat model segmentasi gambar. Model Amazon Lookout for Vision menggunakan segmentasi semantik untuk mengidentifikasi piksel pada gambar di mana jenis anomali (seperti goresan atau bagian yang hilang) ada.
catatan
Model segmentasi semantik menempatkan berbagai jenis anomali. Itu tidak memberikan informasi contoh untuk anomali individu. Misalnya, jika gambar berisi dua penyok, Lookout for Vision mengembalikan informasi tentang kedua penyok dalam satu entitas yang mewakili jenis anomali penyok.
Model segmentasi Amazon Lookout for Vision memprediksi hal berikut:
Klasifikasi
Model mengembalikan klasifikasi untuk gambar yang dianalisis (normal/anomali), yang mencakup kepercayaan model dalam prediksi. Informasi klasifikasi dihitung secara terpisah dari informasi segmentasi dan Anda tidak boleh menganggap hubungan di antara mereka.
Segmentasi
Model mengembalikan topeng gambar yang menandai piksel tempat anomali terjadi pada gambar. Berbagai jenis anomali diberi kode warna sesuai dengan warna yang ditetapkan ke label anomali dalam kumpulan data. Label anomali mewakili jenis anomali. Misalnya, topeng biru pada gambar berikut menandai lokasi jenis anomali goresan yang ditemukan pada mobil.

Model mengembalikan kode warna untuk setiap label anomali di topeng. Model ini juga mengembalikan persentase penutup gambar yang dimiliki label anomali.
Dengan model segmentasi Lookout for Vision, Anda dapat menggunakan berbagai kriteria untuk menganalisis hasil analisis dari model. Sebagai contoh:
-
Lokasi anomali — Jika Anda perlu mengetahui lokasi anomali, gunakan informasi segmentasi untuk melihat topeng yang menutupi anomali.
-
Jenis anomali — Gunakan informasi segmentasi untuk memutuskan apakah suatu gambar mengandung lebih dari jumlah jenis anomali yang dapat diterima.
-
Area cakupan — Gunakan informasi segmentasi untuk memutuskan apakah jenis anomali mencakup lebih dari area gambar yang dapat diterima.
-
Klasifikasi gambar — Jika Anda tidak perlu mengetahui lokasi anomali, gunakan informasi klasifikasi untuk menentukan apakah suatu gambar mengandung anomali.
Untuk kode sampel, lihat Mendeteksi anomali dalam gambar.
Setelah Anda memutuskan jenis model yang Anda inginkan, Anda membuat proyek dan kumpulan data untuk mengelola model Anda. Menggunakan Label, Anda dapat mengklasifikasikan gambar sebagai normal atau anomali. Label juga mengidentifikasi informasi segmentasi seperti topeng dan jenis anomali. Cara Anda memberi label pada gambar dalam kumpulan data menentukan jenis model yang dibuat Lookout for Vision untuk Anda.
Pelabelan model segmentasi gambar lebih kompleks daripada memberi label model klasifikasi gambar. Untuk melatih model segmentasi, Anda harus mengklasifikasikan gambar pelatihan sebagai normal atau anomali. Anda juga harus menentukan topeng anomali dan jenis anomali untuk setiap gambar anomali. Model klasifikasi hanya mengharuskan Anda mengidentifikasi gambar pelatihan sebagai normal atau anomali.
Buat model Anda
Langkah-langkah untuk membuat model adalah membuat proyek, membuat dataset, dan melatih model adalah sebagai berikut:
Membuat proyek
Buat proyek untuk mengelola kumpulan data dan model yang Anda buat. Sebuah proyek harus digunakan untuk kasus penggunaan tunggal, seperti mendeteksi anomali dalam satu jenis bagian mesin.
Anda dapat menggunakan dasbor untuk mendapatkan ikhtisar proyek Anda. Untuk informasi selengkapnya, lihat Menggunakan dasbor Amazon Lookout for Vision.
Informasi lebih lanjut: Buat proyek Anda.
Buat kumpulan data
Untuk melatih model Amazon Lookout for Vision membutuhkan gambar objek normal dan anomali untuk kasus penggunaan Anda. Anda menyediakan gambar-gambar ini dalam kumpulan data.
Dataset adalah sekumpulan gambar dan label yang menggambarkan gambar-gambar tersebut. Gambar harus mewakili satu jenis objek di mana anomali dapat terjadi. Untuk informasi selengkapnya, lihat Mempersiapkan gambar untuk dataset.
Dengan Amazon Lookout for Vision, Anda dapat memiliki proyek yang menggunakan satu kumpulan data, atau proyek yang memiliki kumpulan data pelatihan dan pengujian terpisah. Sebaiknya gunakan satu proyek kumpulan data kecuali Anda menginginkan kontrol yang lebih baik atas pelatihan, pengujian, dan penyetelan kinerja.
Anda membuat kumpulan data dengan mengimpor gambar. Tergantung pada bagaimana Anda mengimpor gambar, gambar mungkin juga diberi label. Jika tidak, Anda menggunakan konsol untuk memberi label pada gambar.
Mengimpor gambar
Jika Anda membuat kumpulan data dengan konsol Lookout for Vision, Anda dapat mengimpor gambar dengan salah satu cara berikut:
-
Impor gambar dari komputer lokal Anda. Gambar tidak diberi label.
-
Impor gambar dari ember S3. Amazon Lookout for Vision dapat mengklasifikasikan gambar menggunakan nama folder yang berisi gambar. Gunakan
normaluntuk gambar normal. Gunakananomalyuntuk gambar anomali. Anda tidak dapat secara otomatis menetapkan label segmentasi. -
Impor file manifes Amazon SageMaker AI Ground Truth. Gambar dalam file manifes diberi label. Anda dapat membuat dan mengimpor file manifes Anda sendiri. Jika Anda memiliki banyak gambar, pertimbangkan untuk menggunakan layanan pelabelan SageMaker AI Ground Truth. Anda kemudian mengimpor file manifes keluaran dari pekerjaan Amazon SageMaker AI Ground Truth.
Pelabelan gambar
Label menggambarkan gambar dalam kumpulan data. Label menentukan apakah gambar normal atau anomali (klasifikasi). Label juga menggambarkan lokasi anomali pada gambar (segmentasi).
Jika gambar Anda tidak diberi label, Anda dapat menggunakan konsol untuk memberi label.
Label yang Anda tetapkan ke gambar dalam kumpulan data menentukan jenis model yang dibuat Lookout for Vision:
Klasifikasi gambar
Untuk membuat model klasifikasi gambar, gunakan konsol Lookout for Vision untuk mengklasifikasikan gambar dalam kumpulan data sebagai normal atau anomali.
Anda juga dapat menggunakan CreateDataset operasi untuk membuat kumpulan data dari file manifes yang menyertakan informasi klasifikasi.
Segmentasi gambar
Untuk membuat model segmentasi gambar, gunakan konsol Lookout for Vision untuk mengklasifikasikan gambar dalam kumpulan data sebagai normal atau anomali. Anda juga menentukan topeng piksel untuk area anomali pada gambar (jika ada) serta label anomali untuk masing-masing topeng anomali.
Anda juga dapat menggunakan CreateDataset operasi untuk membuat kumpulan data dari file manifes yang mencakup informasi segmentasi dan klasifikasi.
Jika proyek Anda memiliki kumpulan data pelatihan dan pengujian terpisah, Lookout for Vision menggunakan kumpulan data pelatihan untuk mempelajari dan menentukan jenis model. Anda harus memberi label pada gambar dalam kumpulan data pengujian Anda dengan cara yang sama.
Informasi lebih lanjut: Membuat kumpulan data Anda.
Latih model Anda
Pelatihan menciptakan model dan melatihnya untuk memprediksi keberadaan anomali dalam gambar. Versi baru model Anda dibuat setiap kali Anda berlatih.
Pada awal pelatihan, Amazon Lookout for Vision memilih algoritma yang paling cocok untuk melatih model Anda. Model dilatih dan kemudian diuji. DiMemulai dengan Amazon Lookout for Vision, Anda melatih satu proyek kumpulan data, kumpulan data dibagi secara internal untuk membuat kumpulan data pelatihan dan kumpulan data pengujian. Anda juga dapat membuat proyek yang memiliki kumpulan data pelatihan dan pengujian terpisah. Dalam konfigurasi ini, Amazon Lookout for Vision melatih model Anda dengan kumpulan data pelatihan dan menguji model dengan kumpulan data pengujian.
penting
Anda dikenakan biaya untuk jumlah waktu yang diperlukan untuk berhasil melatih model Anda.
Informasi lebih lanjut: Latih model Anda.
Evaluasi model Anda
Evaluasi kinerja model Anda dengan menggunakan metrik kinerja yang dibuat selama pengujian.
Dengan menggunakan metrik kinerja, Anda dapat lebih memahami kinerja model terlatih Anda, dan memutuskan apakah Anda siap menggunakannya dalam produksi.
Informasi lebih lanjut: Meningkatkan model Anda.
Jika metrik kinerja menunjukkan bahwa peningkatan diperlukan, Anda dapat menambahkan lebih banyak data pelatihan dengan menjalankan tugas deteksi uji coba dengan gambar baru. Setelah tugas selesai, Anda dapat memverifikasi hasil dan menambahkan gambar terverifikasi ke kumpulan data pelatihan Anda. Atau, Anda dapat menambahkan gambar pelatihan baru langsung ke kumpulan data. Selanjutnya, Anda melatih kembali model Anda dan memeriksa kembali metrik kinerja.
Informasi lebih lanjut: Memverifikasi model Anda dengan tugas deteksi uji coba.
Gunakan model Anda
Sebelum Anda dapat menggunakan model Anda di AWS cloud, Anda memulai model dengan StartModeloperasi. Anda bisa mendapatkan StartModel CLI perintah untuk model Anda dari konsol.
Informasi lebih lanjut: Mulai model Anda.
Model Amazon Lookout for Vision yang terlatih memprediksi apakah gambar input berisi konten normal atau anomali. Jika model Anda adalah model segmentasi, prediksi mencakup topeng anomali yang menandai piksel tempat anomali ditemukan.
Untuk membuat prediksi dengan model Anda, panggil DetectAnomaliesoperasi dan berikan gambar input dari komputer lokal Anda. Anda bisa mendapatkan CLI perintah yang memanggil DetectAnomalies dari konsol.
Informasi lebih lanjut: Mendeteksi anomali dalam gambar.
penting
Anda dikenakan biaya untuk waktu model Anda berjalan.
Jika Anda tidak lagi menggunakan model Anda, gunakan StopModeloperasi untuk menghentikan model. Anda bisa mendapatkan CLI perintah dari konsol.
Informasi lebih lanjut: Hentikan model Anda.
Gunakan model Anda di perangkat tepi
Anda dapat menggunakan model Lookout for Vision pada AWS IoT Greengrass Version 2 perangkat inti.
Informasi lebih lanjut: Menggunakan model Amazon Lookout for Vision pada perangkat edge.
Gunakan dasbor Anda
Anda dapat menggunakan dasbor untuk mendapatkan gambaran umum dari semua proyek Anda dan informasi ikhtisar untuk masing-masing proyek.
Informasi lebih lanjut: Gunakan dasbor Anda.
