翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
このセクションでは、Python スクリプトを使用してハイブリッドジョブを作成する方法について説明します。または、任意の統合開発環境 (IDE) や Braket ノートブックなどのローカル Python コードからハイブリッドジョブを作成するには、「」を参照してくださいローカルコードをハイブリッドジョブとして実行する。
このセクションの内容:
アクセス許可の設定
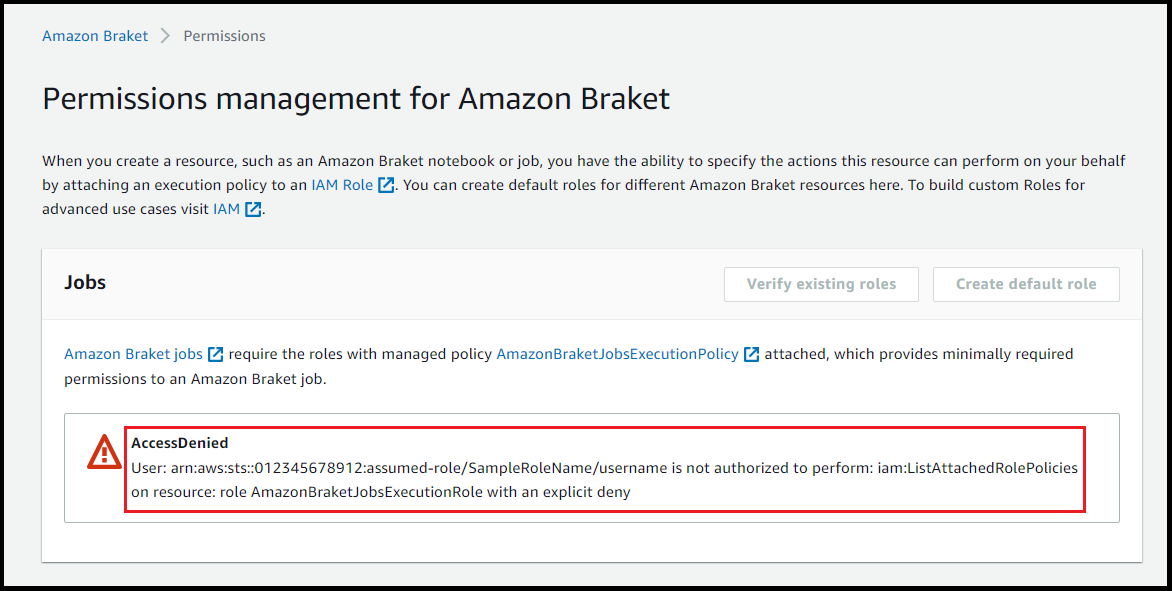
最初のハイブリッドジョブを実行する前に、このタスクを続行するのに十分なアクセス許可があることを確認する必要があります。適切なアクセス許可があることを確認するには、Braket コンソールの左側にあるメニューから[Permissions] (アクセス許可) を選択します。Amazon Braket のアクセス許可管理ページでは、既存のロールの 1 つにハイブリッドジョブを実行するのに十分なアクセス許可があるかどうかを検証するか、そのようなロールがない場合はハイブリッドジョブを実行するために使用できるデフォルトロールの作成をガイドします。
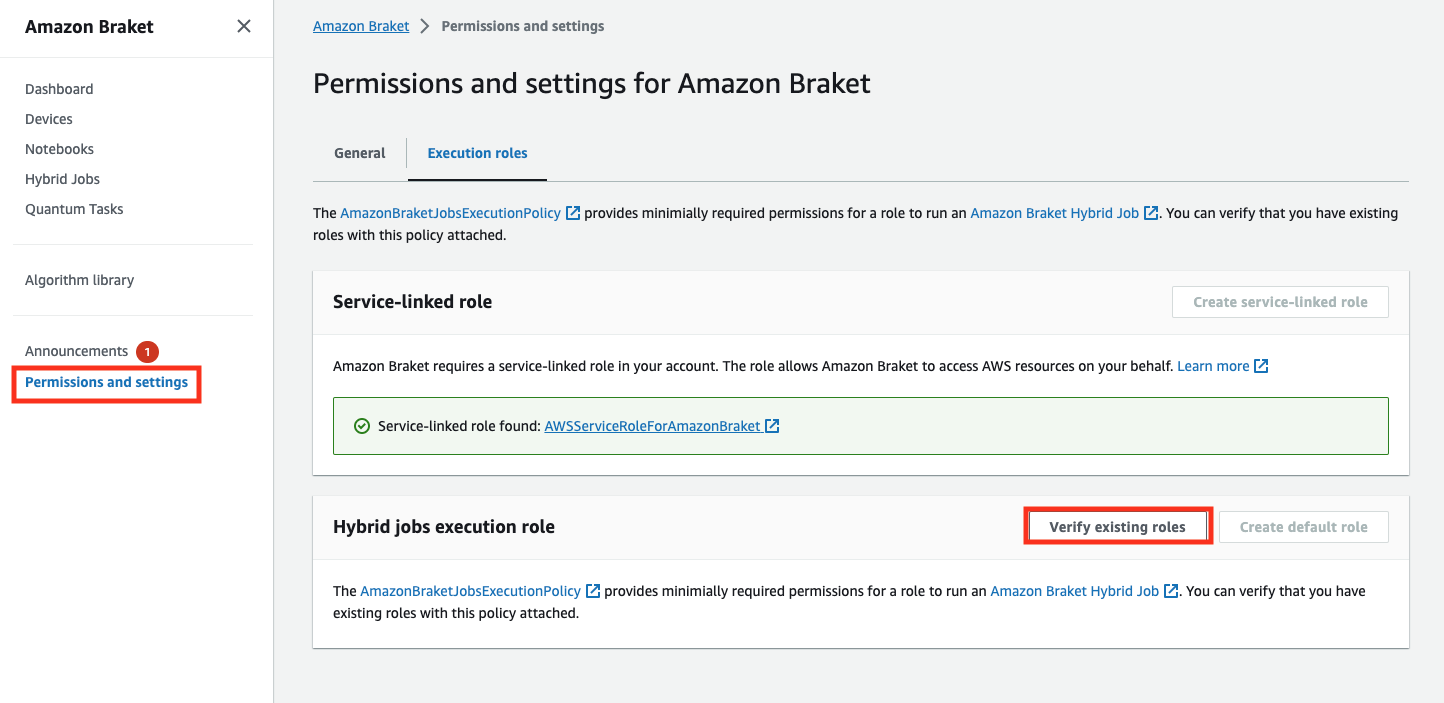
ハイブリッドジョブを実行するのに十分なアクセス許可を持つロールがあることを確認するには、既存のロールの検証ボタンを選択します。使用すると、ロールが見つかったというメッセージが表示されます。ロールの名前とそのロール ARN を表示するには、[Show roles] (ロールを表示する) ボタンを選択します。
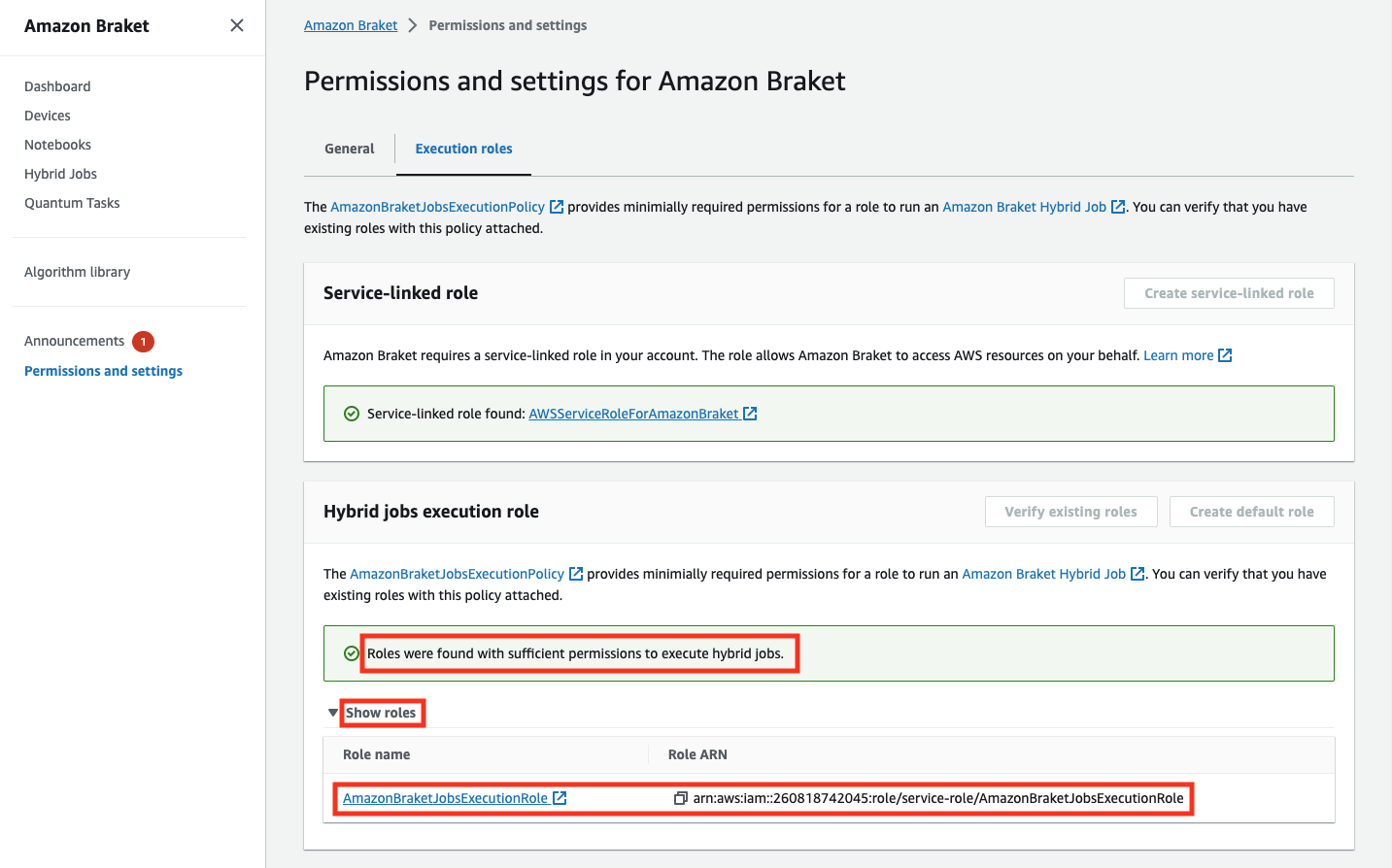
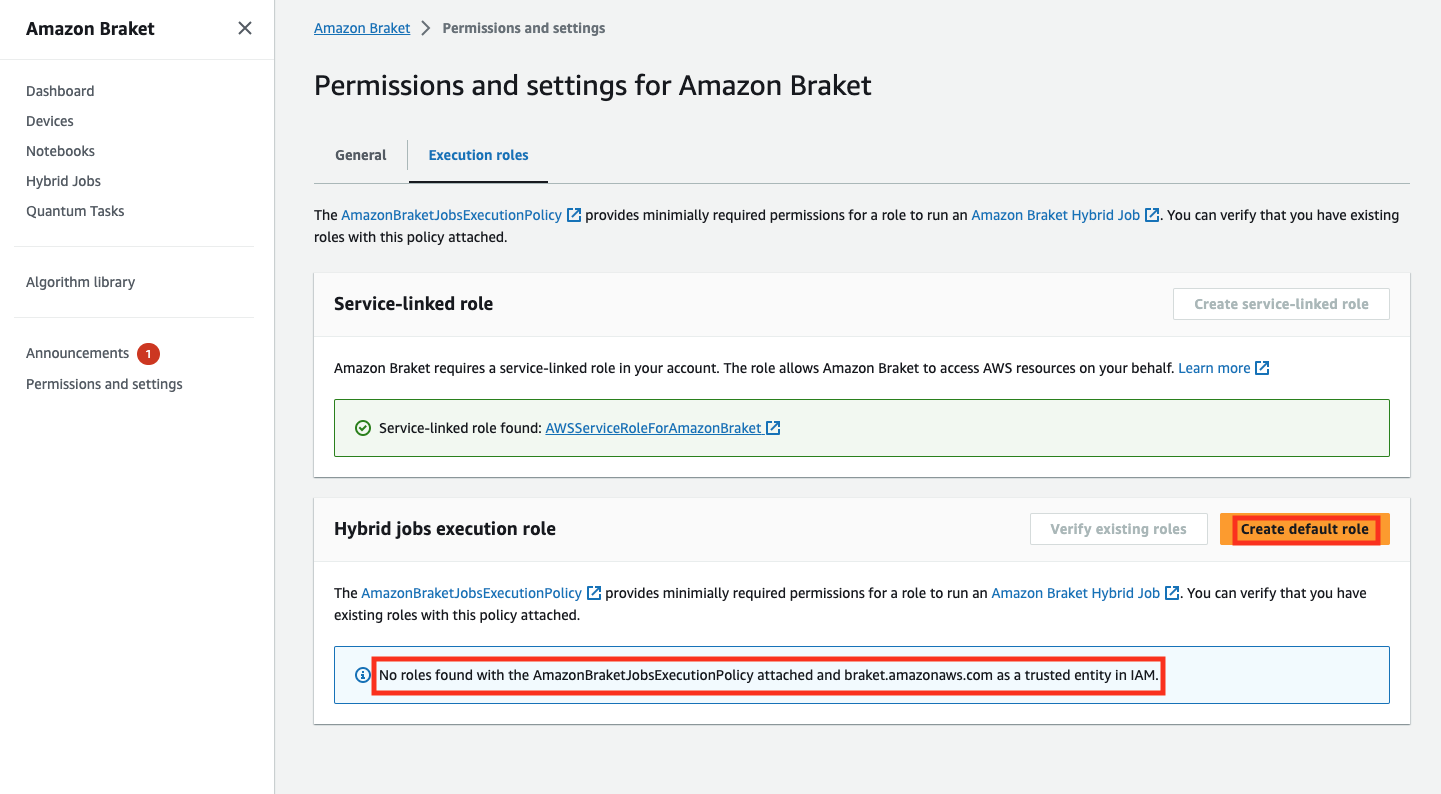
ハイブリッドジョブを実行するのに十分なアクセス許可を持つロールがない場合は、そのようなロールが見つからなかったというメッセージが表示されます。[Create default role] (デフォルトのロールの作成) ボタンを選択して、十分な権限を持つロールを取得します。
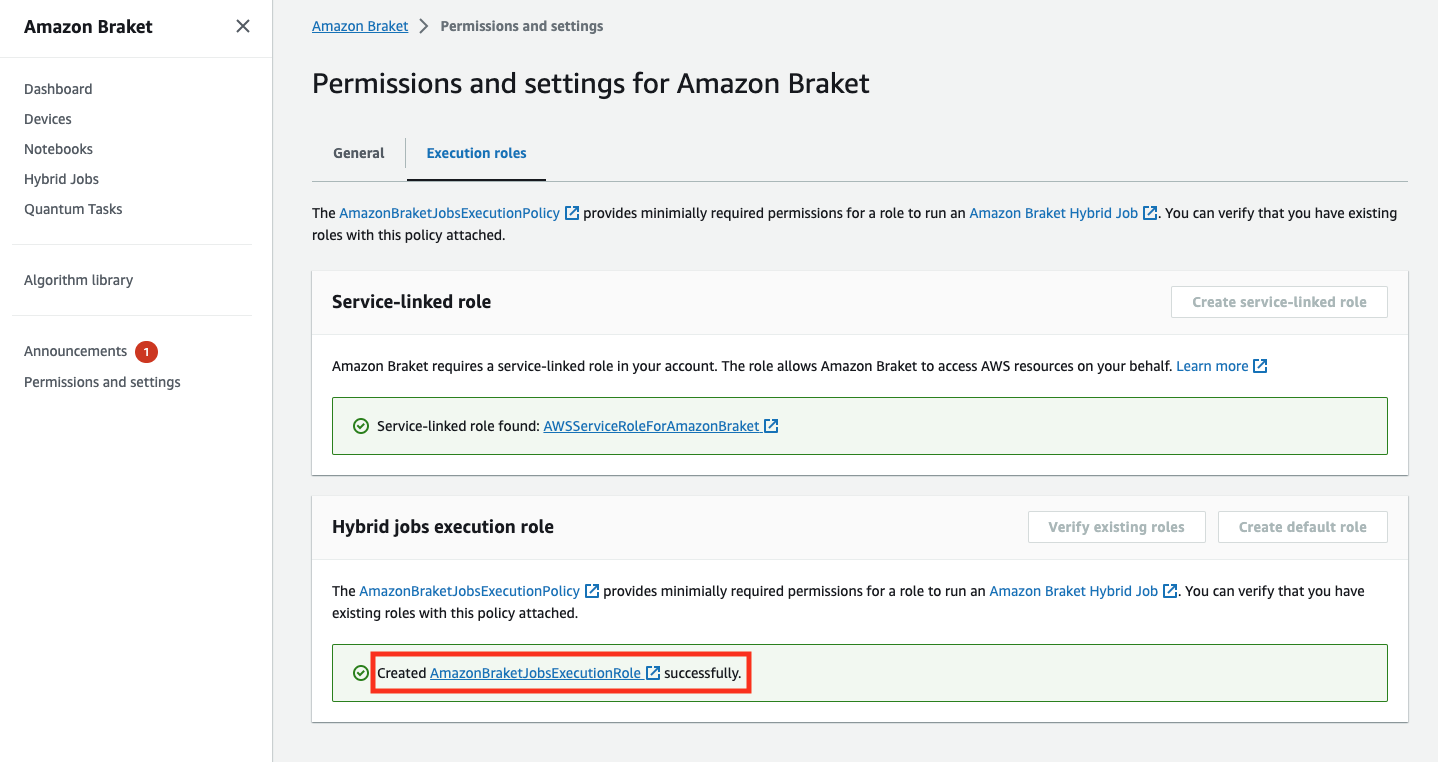
ロールが正常に作成された場合は、これを確認するメッセージが表示されます。
この問い合わせを行う権限がない場合、アクセスは拒否されます。この場合、内部 AWS 管理者に連絡してください。
作成と実行
ハイブリッドジョブを実行するアクセス許可を持つロールを取得したら、続行する準備が整います。最初の Braket ハイブリッドジョブのキー部分はアルゴリズムスクリプトです。実行するアルゴリズムを定義し、アルゴリズムの一部である古典的な論理と量子タスクが含まれています。アルゴリズムスクリプトに加えて、他の依存関係ファイルを指定することもできます。アルゴリズムスクリプトとその依存関係は、ソースモジュールと呼ばれます。エントリポイントは、ハイブリッドジョブの開始時にソースモジュールで実行する最初のファイルまたは関数を定義します。
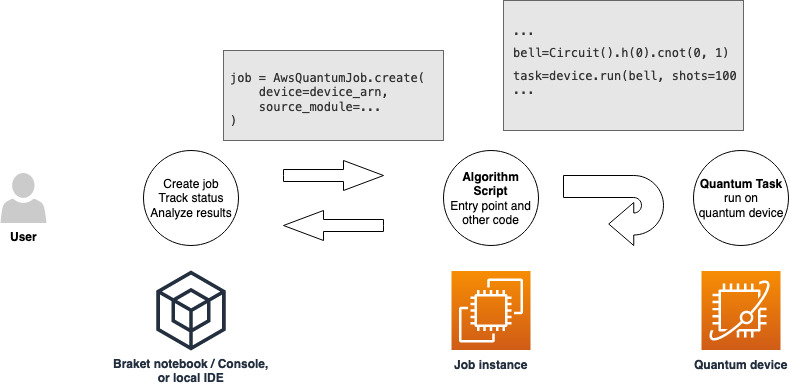
まず、5 つのベル状態を作成し、対応する測定結果を出力するアルゴリズムスクリプトの基本的な例を考えてみましょう。
import os
from braket.aws import AwsDevice
from braket.circuits import Circuit
def start_here():
print("Test job started!")
# Use the device declared in the job script
device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"])
bell = Circuit().h(0).cnot(0, 1)
for count in range(5):
task = device.run(bell, shots=100)
print(task.result().measurement_counts)
print("Test job completed!")このファイルをalgorithm_script.py という名前で、Braket ノートブックまたはローカル環境の現在の作業ディレクトリに保存します。algorithm_script.py ファイルには計画されたエントリーポイントとして start_here() が含まれます。
次に、algorithm_script.py ファイルと同じディレクトリに Python ファイルまたは Python ノートブックを作成します。このスクリプトはハイブリッドジョブを開始し、関心のあるステータスや主要な結果の印刷などの非同期処理を処理します。少なくとも、このスクリプトはハイブリッドジョブスクリプトとプライマリデバイスを指定する必要があります。
注記
Braket ノートブックを作成する方法、または algorithm_script.py ファイルなどのファイルをノートブックと同じディレクトリにアップロードする方法の詳細については、Amazon Braket Python SDK を使用して最初の回路を実行する」を参照してください。
この基本的な最初のケースでは、シミュレーターをターゲットにします。ターゲットとする量子デバイス、シミュレーター、または実際の量子処理ユニット (QPU) のタイプにかかわらず、次のスクリプトdeviceで で指定したデバイスはハイブリッドジョブのスケジュールに使用され、アルゴリズムスクリプトで環境変数 として使用できますAMZN_BRAKET_DEVICE_ARN。
注記
ハイブリッドジョブ AWS リージョン の で使用可能なデバイスのみを使用できます。Amazon Braket SDK がこれを自動的に選択します AWS リージョン。例えば、us-east-1 のハイブリッドジョブでは、IonQ、SV1、DM1、および デバイスを使用できますがTN1、 Rigetti デバイスは使用できません。
シミュレーターの代わりに量子コンピュータを選択した場合、Braket はハイブリッドジョブがすべての量子タスクを優先アクセスで実行するようにスケジュールします。
from braket.aws import AwsQuantumJob
from braket.devices import Devices
job = AwsQuantumJob.create(
Devices.Amazon.SV1,
source_module="algorithm_script.py",
entry_point="algorithm_script:start_here",
wait_until_complete=True
)パラメータ wait_until_complete=True は、冗長モードを設定して、ジョブが実行中に実際のジョブからの出力を出力するようにします。次の例のような出力が表示されます。
job = AwsQuantumJob.create(
Devices.Amazon.SV1,
source_module="algorithm_script.py",
entry_point="algorithm_script:start_here",
wait_until_complete=True,
)
Initializing Braket Job: arn:aws:braket:us-west-2:<accountid>:job/<UUID>
.........................................
.
.
.
Completed 36.1 KiB/36.1 KiB (692.1 KiB/s) with 1 file(s) remaining#015download: s3://braket-external-assets-preview-us-west-2/HybridJobsAccess/models/braket-2019-09-01.normal.json to ../../braket/additional_lib/original/braket-2019-09-01.normal.json
Running Code As Process
Test job started!!!!!
Counter({'00': 55, '11': 45})
Counter({'11': 59, '00': 41})
Counter({'00': 55, '11': 45})
Counter({'00': 58, '11': 42})
Counter({'00': 55, '11': 45})
Test job completed!!!!!
Code Run Finished
2021-09-17 21:48:05,544 sagemaker-training-toolkit INFO Reporting training SUCCESS注記
また、AwsQuantumJob.create
結果をモニタリングする
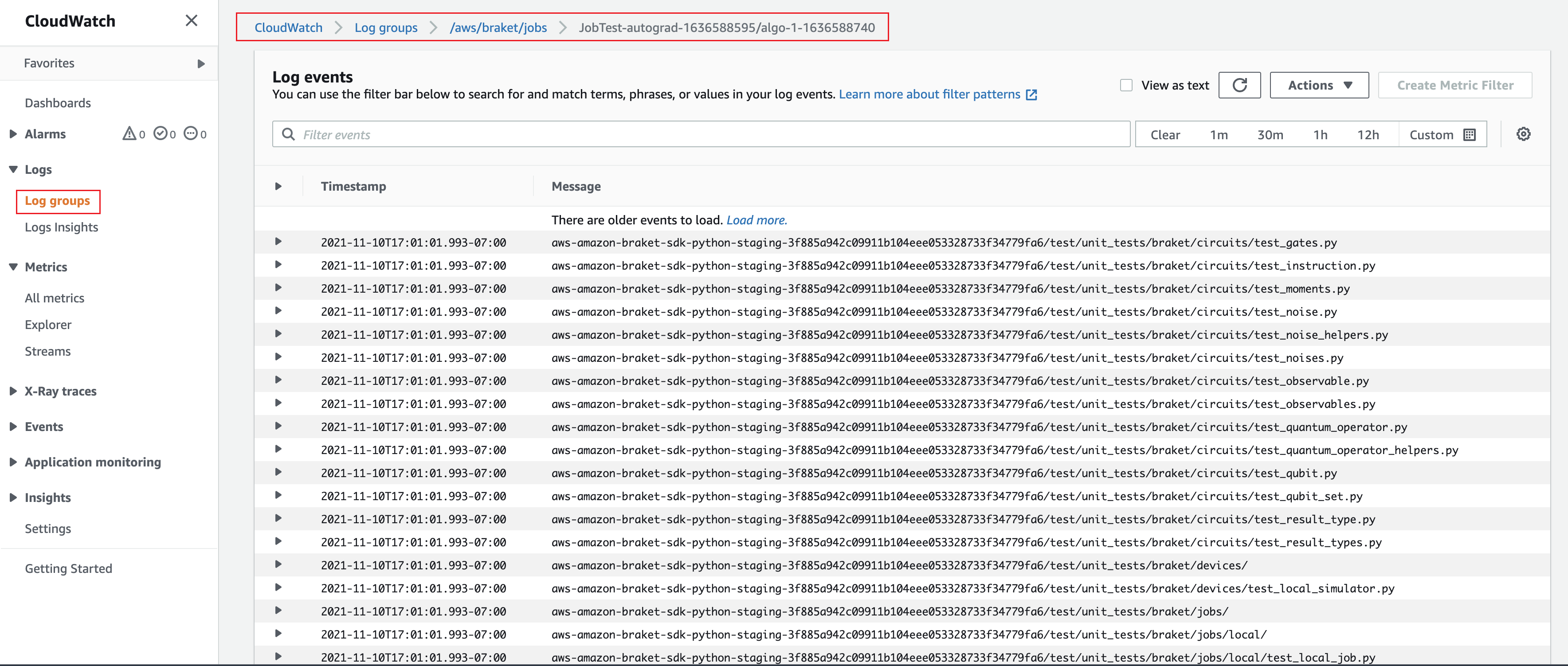
または、Amazon CloudWatch からのログ出力にアクセスすることもできます。これを行うには、ジョブの詳細ページの左側のメニューにあるロググループタブに移動し、ロググループ を選択しaws/braket/jobs、ジョブ名を含むログストリームを選択します。上記の例で、これは braket-job-default-1631915042705/algo-1-1631915190 です。
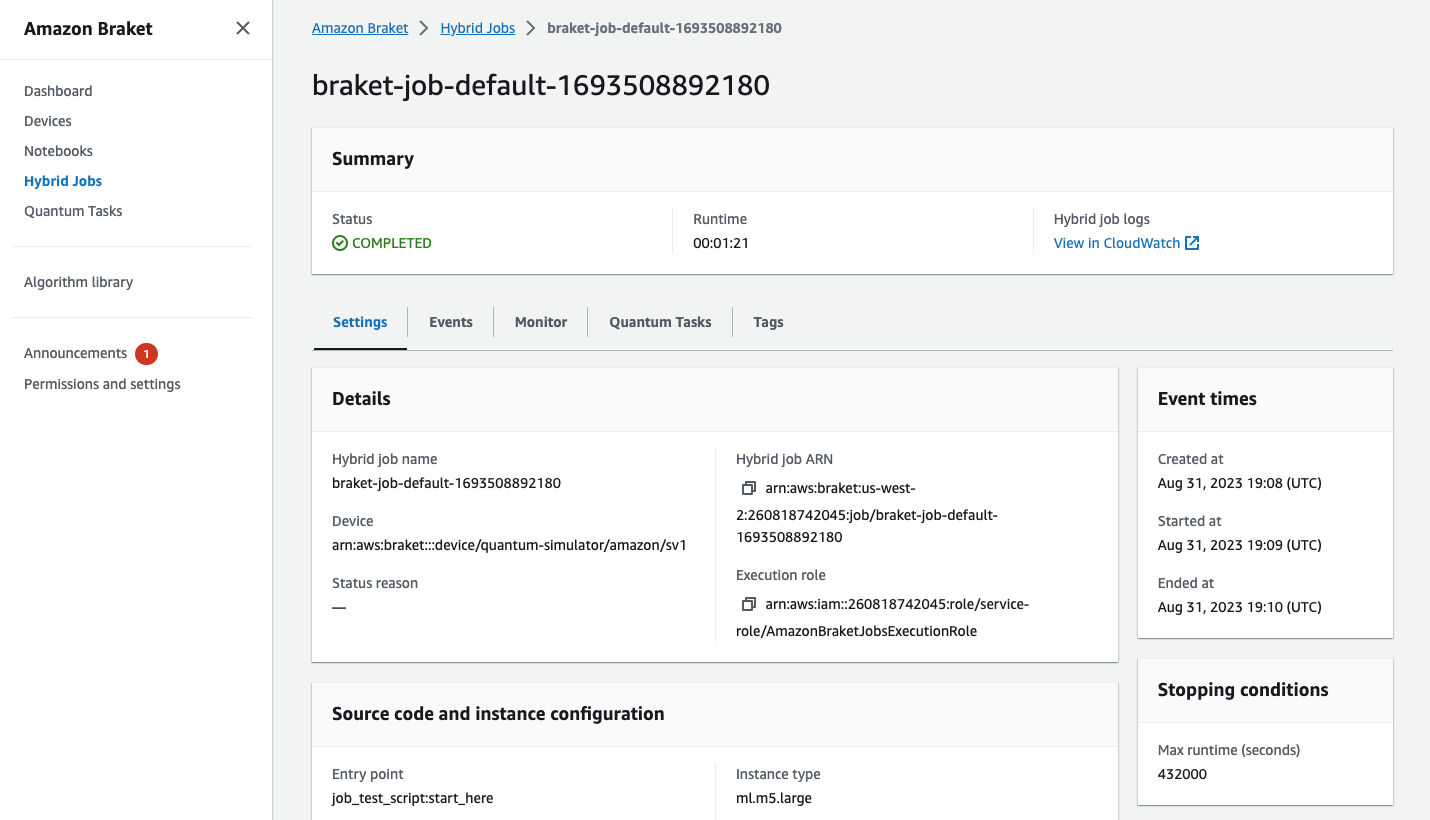
ハイブリッドジョブページを選択し、設定を選択して、コンソールでハイブリッドジョブのステータスを表示することもできます。
ハイブリッドジョブは、実行中に Amazon S3 でいくつかのアーティファクトを生成します。デフォルトの S3 バケット名は amazon-braket-<region>-<accountid> で、コンテンツはjobs/<jobname>/<timestamp> ディレクトリにあります。Braket Python SDK でハイブリッドジョブを作成するcode_locationときに別の を指定することで、これらのアーティファクトが保存される S3 の場所を設定できます。
注記
この S3 バケットは、ジョブスクリプト AWS リージョン と同じ にある必要があります。
jobs/<jobname>/<timestamp> ディレクトリには、model.tar.gzファイル内のエントリポイントスクリプトからの出力を含むサブフォルダが含まれています。また、 というディレクトリもあります。scriptこのディレクトリには、アルゴリズムスクリプトのアーティファクトがsource.tar.gzファイルに含まれています。実際の量子タスクの結果は、jobs/<jobname>/tasks という名前のディレクトリにあります。
