기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon DynamoDB 데이터베이스를의 대상으로 사용 AWS Database Migration Service
AWS DMS 를 사용하여 데이터를 Amazon DynamoDB 테이블로 마이그레이션할 수 있습니다. Amazon DynamoDB는 원활한 확장성과 함께 빠르고 예측 가능한 성능을 제공하는 완전 관리형 NoSQL 데이터베이스 서비스입니다.는 관계형 데이터베이스 또는 MongoDB를 소스로 사용할 수 있도록 AWS DMS 지원합니다.
DynamoDB에서 테이블, 항목 및 속성은 작업 시 사용하는 핵심 구성 요소입니다. 테이블은 항목의 컬렉션이고 각 항목은 속성의 컬렉션입니다. DynamoDB는 파티션 키라는 프라이머리 키를 사용하여 테이블의 각 항목을 고유하게 식별합니다. 또한 키와 보조 인덱스를 사용할 수 있어 쿼리 유연성이 향상됩니다.
객체 매핑을 사용하여 소스 데이터베이스에서 대상 DynamoDB 테이블로 데이터를 마이그레이션할 수 있습니다. 객체 매핑을 통해 소스 데이터가 대상에 배치되는 위치를 결정할 수 있습니다.
가 DynamoDB 대상 엔드포인트에 테이블을 AWS DMS 생성할 때 소스 데이터베이스 엔드포인트에 있는 만큼 테이블을 생성합니다. AWS DMS 또한는 여러 DynamoDB 파라미터 값을 설정합니다. 테이블 생성 비용은 마이그레이션할 테이블 수와 데이터 양에 따라 달라집니다.
참고
AWS DMS 콘솔 또는 API의 SSL 모드 옵션은 Kinesis 및 DynamoDB와 같은 일부 데이터 스트리밍 및 NoSQL 서비스에는 적용되지 않습니다. 기본적으로 안전하므로 SSL 모드 설정이 없음(SSL 모드=없음)과 같음을 AWS DMS 보여줍니다. 엔드포인트에서 SSL을 사용하기 위한 추가 구성을 제공할 필요는 없습니다. 예를 들어 DynamoDB를 대상 엔드포인트로 사용하는 경우 기본적으로 안전합니다. DynamoDB에 대한 모든 API 호출은 SSL을 사용하므로 AWS DMS 엔드포인트에 추가 SSL 옵션이 필요하지 않습니다. DynamoDB 데이터베이스에 연결할 때 기본적으로 AWS DMS 가 사용하는 HTTPS 프로토콜을 사용하여 SSL 엔드포인트를 통해 안전하게 데이터를 넣고 검색할 수 있습니다.
전송 속도를 높이기 위해는 DynamoDB 대상 인스턴스에 대한 멀티스레드 전체 로드를 AWS DMS 지원합니다. DMS는 다음과 같은 작업 설정을 통해 이 멀티스레딩을 지원합니다.
-
MaxFullLoadSubTasks– 병렬로 로드할 최대 소스 테이블 수를 표시하려면 이 옵션을 사용합니다. DMS는 전용 하위 작업을 사용하여 각 테이블을 해당 DynamoDB 대상 테이블에 로드합니다. 기본값은 8입니다. 최대값은 49입니다. -
ParallelLoadThreads-이 옵션을 사용하여가 각 테이블을 DynamoDB 대상 테이블에 로드하는 데 AWS DMS 사용하는 스레드 수를 지정합니다. 기본값은 0입니다(단일 스레드). 최대값은 200입니다. 이 최대 한도를 증가시키도록 요청할 수 있습니다.참고
DNMS는 로딩을 위해 테이블의 각 세그먼트를 고유의 스레드에 할당합니다. 따라서
ParallelLoadThreads를 소스의 테이블에 지정하는 최대 세그먼트 수로 설정합니다. -
ParallelLoadBufferSize– 병렬 로드 스레드에서 데이터를 DynamoDB 대상에 로드하기 위해 사용하는 버퍼에 저장할 최대 레코드 수를 지정합니다. 기본값은 50입니다. 최대값은 1,000입니다. 이 설정은ParallelLoadThreads와 함께 사용하세요.ParallelLoadBufferSize는 둘 이상의 스레드가 있는 경우에만 유효합니다. -
개별 테이블에 대한 테이블 매핑 설정 –
table-settings규칙을 사용하여 소스에서 병렬로 로드할 개별 테이블을 식별합니다. 또한 멀티스레드 로딩을 위해 각 테이블의 행을 세그먼트화하는 방법도 이 규칙을 사용하여 지정합니다. 자세한 내용은 테이블 및 컬렉션 설정 규칙과 작업 단원을 참조하십시오.
참고
가 마이그레이션 작업에 DynamoDB 파라미터 값을 AWS DMS 설정하면 기본 읽기 용량 단위(RCU) 파라미터 값이 200으로 설정됩니다.
쓰기 용량 단위(WCU) 파라미터 값도 설정되지만 이 파라미터의 값은 다른 여러 설정에 따라 달라집니다.
-
WCU 파라미터의 기본값은 200입니다.
-
ParallelLoadThreads작업 설정이 1(기본값은 0)보다 크게 설정되면 WCU 파라미터는ParallelLoadThreads값의 200배로 설정됩니다. 사용하는 리소스에는 표준 AWS DMS 사용 요금이 적용됩니다.
관계형 데이터베이스에서 DynamoDB 테이블로 마이그레이션
AWS DMS 는 DynamoDB 스칼라 데이터 형식으로 데이터 마이그레이션을 지원합니다. Oracle 또는 MySQL 같은 관계형 데이터베이스에서 DynamoDB로 마이그레이션할 때에는 이 데이터를 저장하는 방법을 다시 구성하는 것이 좋습니다.
현재 AWS DMS 는 DynamoDB 스칼라 유형 속성으로 단일 테이블 재구성을 지원합니다. 관계형 데이터베이스 테이블에서 데이터를 DynamoDB로 마이그레이션하려는 경우, 테이블에서 데이터를 가져와서 DynamoDB 스칼라 데이터 형식 속성으로 재지정합니다. 이 속성은 여러 열에서 데이터를 수락하여 열을 속성에 직접 매핑할 수 있습니다.
AWS DMS 는 다음과 같은 DynamoDB 스칼라 데이터 형식을 지원합니다.
-
문자열
-
숫자
-
부울
참고
소스의 NULL 데이터는 대상에서 무시됩니다.
DynamoDB를의 대상으로 사용하기 위한 사전 조건 AWS Database Migration Service
DynamoDB 데이터베이스를 대상으로 사용하기 전에 IAM 역할을 생성해야 AWS DMS합니다. 이 IAM 역할은 AWS DMS 가 마이그레이션 중인 DynamoDB 테이블에 대한 액세스 권한을 수임하고 부여할 수 있도록 허용해야 합니다. 최소 액세스 권한 집합이 다음 IAM 정책에 나와 있습니다.
DynamoDB로의 마이그레이션에 사용하는 역할에는 다음 권한이 있어야 합니다.
DynamoDB를의 대상으로 사용할 때의 제한 사항 AWS Database Migration Service
DynamoDB를 대상으로 사용할 때에는 다음 제한 사항이 적용됩니다.
-
DynamoDB는 숫자 데이터 형식의 정밀도를 38자리로 제한합니다. 정밀도가 더 높은 모든 데이터 형식은 문자열로 저장합니다. 객체 매핑 기능을 사용하여 이것을 명시적으로 지정해야 합니다.
-
DynamoDB에는 날짜 데이터 형식이 없기 때문에 날짜 데이터 형식을 사용한 데이터는 문자열로 변환됩니다.
-
DynamoDB에서는 프라이머리 키 속성 업데이트를 허용하지 않습니다. 대상에 원치 않는 데이터가 발생할 수 있으므로 변경 데이터 캡처(CDC)와 함께 지속적인 복제 사용 시 이 제한이 중요합니다. 객체 매핑 형태에 따라 프라이머리 키를 업데이트하는 CDC 작업은 두 가지 중 하나를 수행할 수 있습니다. 즉, 실패하거나 업데이트된 키와 불완전한 데이터로 새 항목을 삽입할 수 있습니다.
-
AWS DMS 는 비복합 기본 키가 있는 테이블의 복제만 지원합니다. 예외는 사용자 지정 파티션 키나 정렬 키 또는 두 키를 모두 사용하여 대상 테이블의 객체 매핑을 지정하는 경우입니다.
-
AWS DMS 는 CLOB가 아닌 한 LOB 데이터를 지원하지 않습니다.는 데이터를 마이그레이션할 때 CLOB 데이터를 DynamoDB 문자열로 AWS DMS 변환합니다.
-
DynamoDB를 대상으로 사용하는 경우 예외 적용 제어 테이블(
dmslogs.awsdms_apply_exceptions)만 지원됩니다. 제어 테이블에 대한 자세한 내용은 제어 테이블 작업 설정 섹션을 참조하세요. AWS DMS 는 DynamoDB에
TargetTablePrepMode=TRUNCATE_BEFORE_LOAD대한 작업 설정을 대상으로 지원하지 않습니다.AWS DMS 는 DynamoDB에
TaskRecoveryTableEnabled대한 작업 설정을 대상으로 지원하지 않습니다.BatchApply는 DynamoDB 엔드포인트에는 지원되지 않습니다.-
AWS DMS 는 이름이 DynamoDB의 예약어와 일치하는 속성을 마이그레이션할 수 없습니다. 자세한 내용은 Amazon DynamoDB 개발자 안내서의 DynamoDB의 예약어를 참조하세요.
객체 매핑을 사용하여 데이터를 DynamoDB로 마이그레이션
AWS DMS 는 테이블 매핑 규칙을 사용하여 소스의 데이터를 대상 DynamoDB 테이블로 매핑합니다. 데이터를 DynamoDB 대상에 매핑하려면 객체 매핑이라는 테이블 매핑 규칙 유형을 사용합니다. 객체 매핑을 통해 마이그레이션할 속성 이름과 데이터를 정의할 수 있습니다. 객체 매핑을 사용할 때는 선택 규칙이 있어야 합니다.
DynamoDB에는 파티션 키와 정렬 키(선택 사항) 외에 사전 설정 구조가 없습니다. 비복합 기본 키가 있는 경우에서 이를 AWS DMS 사용합니다. 복합 프라이머리 키가 있거나 정렬 키를 사용하려는 경우, 대상 DynamoDB 테이블에서 이러한 키와 기타 속성을 정의하세요.
객체 매핑 규칙을 만들려면 rule-type을 object-mapping으로 지정합니다. 이 규칙은 사용할 객체 매핑의 유형을 지정합니다.
이 규칙의 구조는 다음과 같습니다.
{ "rules": [ { "rule-type": "object-mapping", "rule-id": "<id>", "rule-name": "<name>", "rule-action": "<valid object-mapping rule action>", "object-locator": { "schema-name": "<case-sensitive schema name>", "table-name": "" }, "target-table-name": "<table_name>" } ] }
AWS DMS 는 현재 rule-action 파라미터map-record-to-document에 유효한 유일한 값으로 map-record-to-record 및를 지원합니다. 이러한 값은 exclude-columns 속성 목록의 일부로 제외되지 않는 레코드에 대해 기본적으로 AWS DMS 가 수행하는 작업을 지정합니다. 이러한 값은 어떤 식으로든 속성 매핑에 영향을 미치지 않습니다.
-
관계형 데이터베이스에서 DynamoDB로 마이그레이션할 때
map-record-to-record를 사용할 수 있습니다. 이것은 DynamoDB에서 파티션 키로서 관계형 데이터베이스의 프라이머리 키를 사용하고 소스 데이터베이스의 각 열마다 속성을 생성합니다. 를 사용할 때exclude-columns속성 목록에 나열되지 않은 소스 테이블의 모든 열에map-record-to-record대해는 대상 DynamoDB 인스턴스에 해당 속성을 AWS DMS 생성합니다. 이 속성은 소스 열이 속성 매핑에 사용되는지 여부와 상관없이 생성됩니다. -
속성 이름 '_doc'를 사용하여 대상에 있는 단일한 플랫 DynamoDB 맵에 소스 열을 배치하려면
map-record-to-document를 사용합니다. 를 사용하는 경우map-record-to-document는 데이터를 소스의 단일 플랫 DynamoDB 맵 속성에 AWS DMS 배치합니다. 이 속성을 '_doc'라고 합니다. 이 배치는exclude-columns속성 목록에 나열되지 않은 소스 테이블의 모든 열에 적용됩니다.
rule-action 파라미터 map-record-to-record와 map-record-to-document의 차이를 이해하는 한 가지 방법은 두 파라미터를 실행하는 것입니다. 이 예에서는 다음 구조와 데이터를 사용하여 관계형 데이터베이스 테이블 행에서 시작한다고 가정합니다.

이 정보를 DynamoDB로 마이그레이션하려면 데이터를 DynamoDB 테이블 항목으로 매핑하는 규칙을 생성해야 합니다. exclude-columns 파라미터에 대해 나열된 열을 기록합니다. 이러한 열은 대상에 직접 매핑되지 않습니다. 그 대신 속성 매핑을 사용하여 데이터를 새 항목으로 결합합니다. 예를 들어 FirstName과 LastName이 함께 그룹화되어 DynamoDB 대상에서 CustomerName이 됩니다. NickName과 income은 제외되지 않습니다.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
rule-action 파라미터 map-record-to-record를 사용하여 NickName 및 income의 데이터가 DynamoDB 대상에 있는 동일한 이름의 항목에 매핑됩니다.
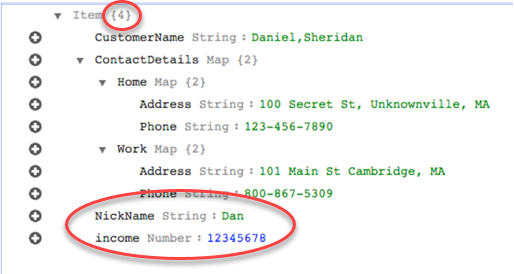
단, 동일한 규칙을 사용하되 rule-action 파라미터를 map-record-to-document로 변경한다고 가정합니다. 이 경우, exclude-columns 파라미터에 나열되어 있지 않은 열인 NickName 및 income은 _doc 항목으로 매핑됩니다.
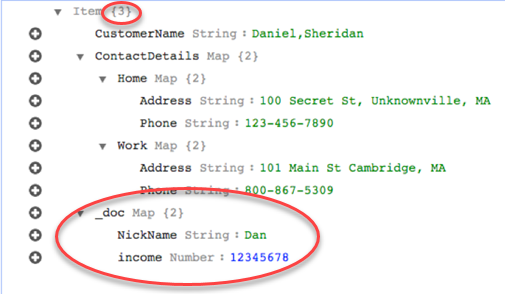
객체 매핑과 함께 사용자 지정 조건식 사용
조건식이라는 DynamoDB의 기능을 사용하여 DynamoDB 테이블에 작성되고 있는 데이터를 조작할 수 있습니다. DynamoDB의 조건식에 대한 자세한 내용은 조건식 섹션을 참조하세요.
조건식 멤버의 구성 요소는 다음과 같습니다.
-
표현식(필수)
-
표현식 속성 값(필수). 속성 값의 DynamoDB json 구조를 지정합니다. 이는 속성을 런타임까지 모를 수 있는 DynamoDB의 값과 비교하는 데 유용합니다. 표현식 속성 값을 실제 값에 대한 자리 표시자로 정의할 수 있습니다.
-
표현식 속성 이름(필수). 이렇게 하면 DynamoDB 예약어, 특수 문자가 포함된 속성 이름 등과의 잠재적 충돌을 방지할 수 있습니다.
-
조건식을 사용할 때 수반되는 옵션(선택 사항). 기본값은 apply-during-cdc = false와 apply-during-full-load = true입니다.
이 규칙의 구조는 다음과 같습니다.
"target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "condition-expression": { "expression":"<conditional expression>", "expression-attribute-values": [ { "name":"<attribute name>", "value":<attribute value> } ], "apply-during-cdc":<optional Boolean value>, "apply-during-full-load": <optional Boolean value> }
다음 샘플은 조건식에 사용되는 섹션을 강조한 것입니다.

객체 매핑과 함께 속성 매핑 사용
속성 매핑을 통해 소스 열 이름을 사용한 템플릿 문자열을 지정하여 대상에서 데이터를 재구성할 수 있습니다. 사용자가 템플릿에서 지정한 항목 외에 완료한 서식 변경이 없습니다.
다음 예는 소스 데이터베이스의 구조와 필요한 DynamoDB 대상 구조를 보여 줍니다. 첫 번째는 소스(이 경우, Oracle 데이터베이스)의 구조를, 그 다음은 필요한 DynamoDB 데이터 구조를 나타냅니다. 이 예는 필요한 대상 구조를 생성하는 데 사용되는 JSON으로 끝납니다.
Oracle 데이터의 구조는 다음과 같습니다.
| FirstName | LastName | StoreId | HomeAddress | HomePhone | WorkAddress | WorkPhone | DateOfBirth |
|---|---|---|---|---|---|---|---|
| 프라이머리 키 | 해당 사항 없음 | ||||||
| Randy | Marsh | 5 | 221B Baker Street | 1234567890 | 31 Spooner Street, Quahog | 9876543210 | 1988/02/29 |
DynamoDB 데이터의 구조는 다음과 같습니다.
| CustomerName | StoreId | ContactDetails | DateOfBirth |
|---|---|---|---|
| 파티션 키 | 정렬 키 | 해당 사항 없음 | |
|
|
|
|
다음 JSON은 DynamoDB 구조를 달성하는 데 사용되는 객체 매핑과 열 매핑을 보여 줍니다.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "{\"Name\":\"${FirstName}\",\"Home\":{\"Address\":\"${HomeAddress}\",\"Phone\":\"${HomePhone}\"}, \"Work\":{\"Address\":\"${WorkAddress}\",\"Phone\":\"${WorkPhone}\"}}" } ] } } ] }
열 매핑을 사용하는 또 다른 방법은 DynamoDB 형식을 문서 형식으로 사용하는 것입니다. 다음 코드 예제에서는 dynamodb-map을 속성 매핑을 위한 attribute-sub-type으로 사용합니다.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Name": { "S": "${FirstName}" }, "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
dynamodb-map 대신 다음 예제와 같이 속성 매핑을 위한 속성-하위 유형으로 dynamodb-list를 사용할 수 있습니다.
{ "target-attribute-name": "ContactDetailsList", "attribute-type": "document", "attribute-sub-type": "dynamodb-list", "value": { "L": [ { "N": "${FirstName}" }, { "N": "${HomeAddress}" }, { "N": "${HomePhone}" }, { "N": "${WorkAddress}" }, { "N": "${WorkPhone}" } ] } }
예제 1: 객체 매핑과 함께 속성 매핑 사용
다음 예제는 두 MySQL 데이터베이스 테이블인 nfl_data 및 sport_team에서 NFLTeams와 SportTeam이라는 두 개의 DynamoDB 테이블로 데이터를 마이그레이션합니다. 이 테이블의 구조와 MySQL 데이터베이스 테이블의 데이터를 DynamoDB 테이블로 매핑하는 데 사용된 JSON은 다음과 같습니다.
MySQL 데이터베이스 테이블 nfl_data의 구조는 다음과 같습니다.
mysql> desc nfl_data; +---------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+-------+ | Position | varchar(5) | YES | | NULL | | | player_number | smallint(6) | YES | | NULL | | | Name | varchar(40) | YES | | NULL | | | status | varchar(10) | YES | | NULL | | | stat1 | varchar(10) | YES | | NULL | | | stat1_val | varchar(10) | YES | | NULL | | | stat2 | varchar(10) | YES | | NULL | | | stat2_val | varchar(10) | YES | | NULL | | | stat3 | varchar(10) | YES | | NULL | | | stat3_val | varchar(10) | YES | | NULL | | | stat4 | varchar(10) | YES | | NULL | | | stat4_val | varchar(10) | YES | | NULL | | | team | varchar(10) | YES | | NULL | | +---------------+-------------+------+-----+---------+-------+
MySQL 데이터베이스 테이블 sport_team의 구조는 다음과 같습니다.
mysql> desc sport_team; +---------------------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------------------+--------------+------+-----+---------+----------------+ | id | mediumint(9) | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | NULL | | | abbreviated_name | varchar(10) | YES | | NULL | | | home_field_id | smallint(6) | YES | MUL | NULL | | | sport_type_name | varchar(15) | NO | MUL | NULL | | | sport_league_short_name | varchar(10) | NO | | NULL | | | sport_division_short_name | varchar(10) | YES | | NULL | |
테이블 2개를 DynamoDB 테이블 2개에 매핑하는 데 사용된 테이블 매핑 규칙은 다음과 같습니다.
{ "rules":[ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "dms_sample", "table-name": "nfl_data" }, "rule-action": "include" }, { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "dms_sample", "table-name": "sport_team" }, "rule-action": "include" }, { "rule-type":"object-mapping", "rule-id":"3", "rule-name":"MapNFLData", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"nfl_data" }, "target-table-name":"NFLTeams", "mapping-parameters":{ "partition-key-name":"Team", "sort-key-name":"PlayerName", "exclude-columns": [ "player_number", "team", "name" ], "attribute-mappings":[ { "target-attribute-name":"Team", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${team}" }, { "target-attribute-name":"PlayerName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"PlayerInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"Number\": \"${player_number}\",\"Position\": \"${Position}\",\"Status\": \"${status}\",\"Stats\": {\"Stat1\": \"${stat1}:${stat1_val}\",\"Stat2\": \"${stat2}:${stat2_val}\",\"Stat3\": \"${stat3}:${ stat3_val}\",\"Stat4\": \"${stat4}:${stat4_val}\"}" } ] } }, { "rule-type":"object-mapping", "rule-id":"4", "rule-name":"MapSportTeam", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"sport_team" }, "target-table-name":"SportTeams", "mapping-parameters":{ "partition-key-name":"TeamName", "exclude-columns": [ "name", "id" ], "attribute-mappings":[ { "target-attribute-name":"TeamName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"TeamInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"League\": \"${sport_league_short_name}\",\"Division\": \"${sport_division_short_name}\"}" } ] } } ] }
NFLTeams DynamoDB 테이블의 샘플 출력은 다음과 같습니다.
"PlayerInfo": "{\"Number\": \"6\",\"Position\": \"P\",\"Status\": \"ACT\",\"Stats\": {\"Stat1\": \"PUNTS:73\",\"Stat2\": \"AVG:46\",\"Stat3\": \"LNG:67\",\"Stat4\": \"IN 20:31\"}", "PlayerName": "Allen, Ryan", "Position": "P", "stat1": "PUNTS", "stat1_val": "73", "stat2": "AVG", "stat2_val": "46", "stat3": "LNG", "stat3_val": "67", "stat4": "IN 20", "stat4_val": "31", "status": "ACT", "Team": "NE" }
SportsTeams DynamoDB 테이블의 샘플 출력은 다음과 같습니다.
{ "abbreviated_name": "IND", "home_field_id": 53, "sport_division_short_name": "AFC South", "sport_league_short_name": "NFL", "sport_type_name": "football", "TeamInfo": "{\"League\": \"NFL\",\"Division\": \"AFC South\"}", "TeamName": "Indianapolis Colts" }
DynamoDB에 대한 대상 데이터 형식
용 DynamoDB 엔드포인트는 대부분의 DynamoDB 데이터 형식을 AWS DMS 지원합니다. 다음 표에는를 사용할 때 지원되는 Amazon AWS DMS 대상 데이터 형식 AWS DMS 과 AWS DMS 데이터 형식의 기본 매핑이 나와 있습니다.
AWS DMS 데이터 형식에 대한 자세한 내용은 섹션을 참조하세요AWS Database Migration Service에서 사용되는 데이터 형식.
가 이기종 데이터베이스에서 데이터를 AWS DMS 마이그레이션할 때 소스 데이터베이스의 데이터 유형을 AWS DMS 데이터 유형이라고 하는 중간 데이터 유형으로 매핑합니다. 그런 다음, 중간 데이터 형식을 대상 데이터 형식에 매핑합니다. 다음 표에는 DynamoDB의 각 AWS DMS 데이터 유형과 매핑되는 데이터 유형이 나와 있습니다.
| AWS DMS 데이터 유형 | DynamoDB 데이터 형식 |
|---|---|
|
문자열 |
문자열 |
|
WString |
문자열 |
|
부울 |
부울 |
|
날짜 |
문자열 |
|
DateTime |
문자열 |
|
INT1 |
숫자 |
|
INT2 |
숫자 |
|
INT4 |
숫자 |
|
INT8 |
숫자 |
|
Numeric |
숫자 |
|
Real4 |
숫자 |
|
Real8 |
숫자 |
|
UINT1 |
숫자 |
|
UINT2 |
숫자 |
|
UINT4 |
숫자 |
| UINT8 | 숫자 |
| CLOB | 문자열 |
