지원 종료 알림: 2026년 5월 31일에에 대한 지원이 AWS 종료됩니다 AWS Panorama. 2026년 5월 31일 이후에는 AWS Panorama 콘솔 또는 AWS Panorama 리소스에 더 이상 액세스할 수 없습니다. 자세한 내용은 AWS Panorama 지원 종료를 참조하세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
컴퓨터 비전 모델
컴퓨터 비전 모델은 이미지에서 개체를 감지하도록 학습된 소프트웨어 프로그램입니다. 모델은 먼저 학습을 통해 해당 개체의 이미지를 분석하여 일련의 물체를 인식하는 방법을 학습합니다. 컴퓨터 비전 모델은 이미지를 입력으로 받아 감지한 개체에 대한 정보(예: 개체 유형 및 위치)를 출력합니다. AWS Panorama는 PyTorch, Apache MXNet, TensorFlow로 구축된 컴퓨터 비전 모델을 지원합니다.
참고
AWS Panorama로 테스트한 사전 빌드 모델 목록은 모델 호환성
코드에서 모델 사용
모델은 감지된 클래스의 확률, 위치 정보 및 기타 데이터를 포함할 수 있는 하나 이상의 결과를 반환합니다. 다음 예시는 비디오 스트림의 이미지에 대한 추론을 실행하고 모델의 출력을 처리 함수로 보내는 방법을 보여줍니다.
예 application.py
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
다음 예시에서는 기본 분류 모델의 결과를 처리하는 함수를 보여줍니다. 샘플 모델은 결과 배열의 첫 번째이자 유일한 값인 확률 배열을 반환합니다.
예 application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
애플리케이션 코드는 확률이 가장 높은 값을 찾아 초기화 중에 로드되는 리소스 파일의 레이블에 매핑합니다.
사용자 지정 모델 빌드
PyTorch, Apache MXnet 및 TensorFlow에서 빌드한 모델을 AWS Panorama 애플리케이션에서 사용할 수 있습니다. SageMaker AI에서 모델을 빌드하고 훈련하는 대신 훈련된 모델을 사용하거나 지원되는 프레임워크로 자체 모델을 빌드하고 훈련하여 로컬 환경 또는 Amazon EC2에서 내보낼 수 있습니다.
참고
SageMaker AI Neo에서 지원하는 프레임워크 버전 및 파일 형식에 대한 자세한 내용은 Amazon SageMaker AI 개발자 안내서의 지원되는 프레임워크를 참조하세요.
이 설명서의 리포지토리는 TensorFlow SavedModel 형식의 Keras 모델에 대한 이 워크플로를 보여주는 샘플 애플리케이션을 제공합니다. TensorFlow 2를 사용하며 가상 환경 또는 도크 컨테이너에서 로컬로 실행할 수 있습니다. 샘플 앱에는 Amazon EC2 인스턴스에서 모델을 빌드하기 위한 템플릿과 스크립트도 포함되어 있습니다.
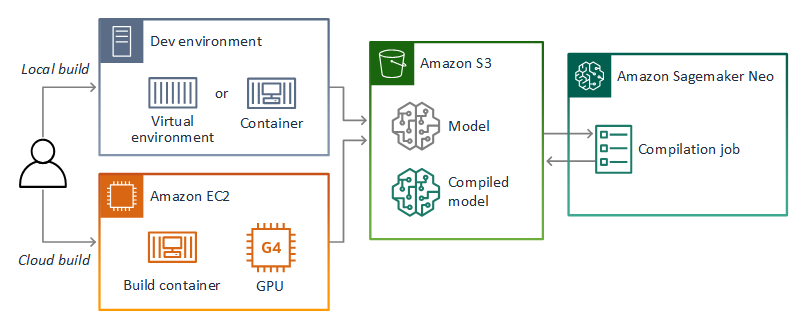
AWS Panorama는 SageMaker AI Neo를 사용하여 AWS Panorama 어플라이언스에서 사용할 모델을 컴파일합니다. 각 프레임워크에 대해 SageMaker AI Neo에서 지원하는 형식을 사용하고 모델을 .tar.gz 아카이브에 패키징합니다.
자세한 내용은 Amazon SageMaker AI 개발자 안내서의 Neo로 모델 컴파일 및 배포를 참조하세요.
모델 패키징
모델 패키지는 설명자, 패키지 구성, 모델 아카이브로 구성됩니다. 애플리케이션 이미지 패키지에서와 마찬가지로 패키지 구성은 AWS Panorama 서비스에 Amazon S3의 모델 및 설명자가 저장된 위치를 알려줍니다.
예 packages/123456789012-SQUEEZENET_PYTORCH-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
참고
프레임워크 버전의 메이저 버전과 마이너 버전만 지정하십시오. 지원되는 PyTorch, Apache MXNet, TensorFlow 버전 목록은 지원되는 프레임워크를 참조하십시오.
모델을 가져오려면 AWS Panorama 애플리케이션 CLI import-raw-model 명령을 사용하십시오. 모델 또는 설명자를 변경하는 경우 이 명령을 다시 실행하여 애플리케이션 자산을 업데이트해야 합니다. 자세한 내용은 컴퓨터 비전 모델 변경 단원을 참조하십시오.
설명자 파일의 JSON 스키마는 assetDescriptor.schema.json
모델 학습
모델을 학습시킬 때는 대상 환경이나 대상 환경과 매우 유사한 테스트 환경의 이미지를 사용하십시오. 모델 성능에 영향을 줄 수 있는 다음 요인을 고려하십시오.
-
조명 – 피사체에 반사되는 빛의 양에 따라 모델이 분석해야 하는 세부 정보의 양이 결정됩니다. 조명이 밝은 피사체의 이미지로 학습된 모델은 저조도 또는 역광 환경에서는 잘 작동하지 않을 수 있습니다.
-
해상도 – 모델의 입력 크기는 일반적으로 정사각형 종횡비에서 폭 224~512픽셀 사이의 해상도로 고정됩니다. 비디오 프레임을 모델로 전달하기 전에 필요한 크기에 맞게 축소하거나 자를 수 있습니다.
-
이미지 왜곡 – 카메라의 초점 거리와 렌즈 모양으로 인해 프레임 중앙에서 멀어지면 이미지가 왜곡될 수 있습니다. 카메라의 위치에 따라 피사체의 어떤 특징이 보이는지도 결정됩니다. 예를 들어 광각 렌즈가 장착된 오버헤드 카메라는 피사체가 프레임 중앙에 있을 때는 피사체의 위쪽을, 중심에서 멀어지면 피사체의 측면을 비뚤어진 모습으로 보여줍니다.
이러한 문제를 해결하려면 이미지를 모델로 보내기 전에 전처리하고 실제 환경의 변화를 반영하는 더 다양한 이미지에 대해 모델을 학습시킬 수 있습니다. 조명 상황에서 다양한 카메라로 모델을 작동시켜야 하는 경우 학습에 더 많은 데이터가 필요합니다. 더 많은 이미지를 수집하는 것 외에도 왜곡되거나 조명이 다른 기존 이미지의 변형을 만들어 더 많은 학습 데이터를 얻을 수 있습니다.
