As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Usando um banco de dados do Amazon DynamoDB como destino para AWS Database Migration Service
Você pode usar AWS DMS para migrar dados para uma tabela do Amazon DynamoDB. O Amazon DynamoDB é um serviço de banco de dados NoSQL totalmente gerenciado que fornece desempenho rápido e previsível com escalabilidade perfeita. AWS DMS suporta o uso de um banco de dados relacional ou MongoDB como fonte.
No DynamoDB, tabelas, itens e atributos são os componentes principais com que você trabalha. Uma tabela é uma coleção de itens, e cada item é uma coleção de atributos. O DynamoDB utiliza chaves primárias, chamadas chaves de partição, para identificar de modo exclusivo cada item em uma tabela. Também é possível utilizar chaves e índices secundários para fornecer mais flexibilidade de consulta.
O mapeamento de objeto é utilizado para migrar os dados de um banco de dados de origem para uma tabela de destino do DynamoDB. O mapeamento de objetos permite que você determine onde os dados de origem estão localizados no destino.
Ao AWS DMS criar tabelas em um endpoint de destino do DynamoDB, ele cria tantas tabelas quanto no endpoint do banco de dados de origem. AWS DMS também define vários valores de parâmetros do DynamoDB. O custo de criação da tabela depende da quantidade de dados e do número de tabelas a serem migradas.
nota
A opção Modo SSL no AWS DMS console ou na API não se aplica a alguns serviços de streaming de dados e NoSQL, como Kinesis e DynamoDB. Eles são seguros por padrão, então AWS DMS mostra que a configuração do modo SSL é igual a nenhuma (Modo SSL = Nenhuma). Não é necessário fornecer nenhuma configuração adicional para que o endpoint utilize o SSL. Por exemplo, ao utilizar o DynamoDB como um endpoint de destino, ele é seguro por padrão. Todas as chamadas de API para o DynamoDB usam SSL, portanto, não há necessidade de uma opção adicional de SSL no endpoint. AWS DMS É possível inserir e recuperar dados com segurança por meio de endpoints SSL utilizando o protocolo HTTPS, que o AWS DMS utiliza por padrão ao se conectar a um banco de dados DynamoDB.
Para ajudar a aumentar a velocidade da transferência, AWS DMS oferece suporte a uma carga completa multiencadeada em uma instância de destino do DynamoDB. O DMS oferece suporte a esse multithreading com configurações de tarefa que incluem o seguinte:
-
MaxFullLoadSubTasks: utilize esta opção para indicar o número máximo de tabelas de origem a serem carregadas em paralelo. O DMS carrega cada tabela na tabela de destino do DynamoDB correspondente utilizando uma subtarefa dedicada. O valor padrão é 8. O valor máximo é 49. -
ParallelLoadThreads— Use essa opção para especificar o número de threads AWS DMS usados para carregar cada tabela em sua tabela de destino do DynamoDB. O valor padrão é 0 (segmento único). O valor máximo é 200. Você pode solicitar o aumento desse limite máximo.nota
O DMS atribui cada segmento de uma tabela ao seu próprio thread para carregar. Portanto, defina
ParallelLoadThreadscomo o número máximo de segmentos que você especifica para uma tabela na origem. -
ParallelLoadBufferSize: utilize essa opção para especificar o número máximo de registros a serem armazenados em buffer utilizado pelos threads paralelos para carregar dados no destino do DynamoDB. O valor padrão é 50. Valor máximo de 1.000. Use essa configuração comParallelLoadThreads;ParallelLoadBufferSizeé válido somente quando há mais de um thread. -
Table-mapping configurações para tabelas individuais — Use
table-settingsregras para identificar tabelas individuais da fonte que você deseja carregar paralelamente. Além disso, utilize essas regras para especificar como segmentar as linhas de cada tabela para carregamento multithread. Para obter mais informações, consulte Regras e operações de configurações de tabelas e coleções.
nota
Quando AWS DMS define os valores dos parâmetros do DynamoDB para uma tarefa de migração, o valor padrão do parâmetro Read Capacity Units (RCU) é definido como 200.
O valor do parâmetro das Unidades de capacidade de gravação (WCU) também é definido, mas o valor depende de várias outras configurações:
-
O valor padrão do parâmetro WCU é 200.
-
Se a configuração de tarefa
ParallelLoadThreadsfor definida com um valor maior que 1 (o padrão é 0), o parâmetro WCU será definido como 200 vezes o valor deParallelLoadThreads. As taxas AWS DMS de uso padrão se aplicam aos recursos que você usa.
Migração de um banco de dados relacional para uma tabela do DynamoDB
AWS DMS suporta a migração de dados para tipos de dados escalares do DynamoDB. Para migrar de um banco de dados relacional, como o Oracle ou o MySQL, para o DynamoDB, reestruture a forma como você armazena esses dados.
Atualmente, AWS DMS oferece suporte à reestruturação de tabela única para tabela única para atributos do tipo escalar do DynamoDB. Se você estivesse migrando dados para o DynamoDB a partir de uma tabela de banco de dados relacional, pegaria dados de uma tabela e os reformataria como atributos de tipo de dados escalares. Esses atributos podem aceitar dados de várias colunas, e é possível mapear uma coluna diretamente para um atributo.
AWS DMS é compatível com os seguintes tipos de dados escalares do DynamoDB:
-
String
-
Número
-
Booleano
nota
Os dados NULL da origem são ignorados no destino.
Pré-requisitos para usar o DynamoDB como destino para AWS Database Migration Service
Antes de começar a trabalhar com um banco de dados do DynamoDB como destino, certifique-se AWS DMS de criar uma função do IAM. Essa função do IAM deve AWS DMS permitir assumir e conceder acesso às tabelas do DynamoDB para as quais estão sendo migradas. O conjunto mínimo de permissões de acesso é mostrado na seguinte política do IAM.
O perfil utilizado para a migração para o DynamoDB deve ter as seguintes permissões:
Limitações ao usar o DynamoDB como destino para AWS Database Migration Service
Aplicam-se as seguintes limitações ao utilizar o DynamoDB como destino:
-
O DynamoDB limita a precisão do tipo de dados Número a 38 locais. Armazene todos os tipos de dados com mais precisão como uma string. É necessário especificar isso explicitamente utilizando o recurso de mapeamento de objetos.
-
Como o DynamoDB não tem um tipo de dados Date, os dados que utilizam esse tipo Date são convertidos em strings.
-
O DynamoDB não permite atualizações nos atributos da chave primária. Essa restrição é importante quando se usa a replicação contínua com captura de dados de alterações (CDC), pois ela pode gerar dados indesejados no destino. Dependendo de como é o seu mapeamento de objetos, uma operação de CDC que atualiza a chave primária pode fazer uma de duas coisas. Pode falhar ou inserir um novo item com a chave primária atualizada e dados incompletos.
-
AWS DMS suporta somente a replicação de tabelas com chaves primárias não compostas. A exceção é se você especificar um mapeamento de objetos para a tabela de destino com uma chave de partição personalizada ou chave de classificação, ou ambas.
-
AWS DMS não suporta dados LOB, a menos que seja um CLOB. AWS DMS converte dados CLOB em uma string do DynamoDB ao migrar os dados.
-
Ao utilizar o DynamoDB como destino, somente a tabela de controle Aplicar exceções (
dmslogs.awsdms_apply_exceptions) será compatível. Para obter mais informações sobre tabelas de controle, consulte Configurações de tarefa de tabela de controle. AWS DMS não suporta a configuração
TargetTablePrepMode=TRUNCATE_BEFORE_LOADde tarefas do DynamoDB como destino.AWS DMS não suporta a configuração
TaskRecoveryTableEnabledde tarefas do DynamoDB como destino.O
BatchApplynão é compatível com um endpoint do DynamoDB.-
AWS DMS não é possível migrar atributos cujos nomes correspondam às palavras reservadas no DynamoDB. Para ter mais informações, consulte Palavras reservadas no DynamoDB no Guia do desenvolvedor Amazon DynamoDB.
Utilizar o mapeamento de objetos para migrar dados para o DynamoDB
AWS DMS usa regras de mapeamento de tabelas para mapear dados da tabela de origem para a tabela do DynamoDB de destino. Para mapear dados para um destino do DynamoDB, utilize um tipo de regra de mapeamento de tabela chamada object-mapping. O mapeamento de objetos permite definir os nomes de atributos e os dados a serem migrados para eles. Você deve ter regras de seleção ao utilizar o mapeamento de objetos.
O DynamoDB não tem uma estrutura predefinida além de ter uma chave de partição e uma chave de classificação opcional. Se você tiver uma chave primária não composta, use-a AWS DMS . Se você tiver uma chave primária composta ou quiser utilizar uma chave de classificação, defina as chaves e os outros atributos na tabela de destino do DynamoDB.
Para criar uma regra de mapeamento de objetos, especifique rule-type como object-mapping. Essa regra especifica o tipo de mapeamento de objeto que você deseja usar.
A estrutura da regra é a seguinte:
{ "rules": [ { "rule-type": "object-mapping", "rule-id": "<id>", "rule-name": "<name>", "rule-action": "<valid object-mapping rule action>", "object-locator": { "schema-name": "<case-sensitive schema name>", "table-name": "" }, "target-table-name": "<table_name>" } ] }
AWS DMS atualmente suporta map-record-to-record e map-record-to-document como os únicos valores válidos para o rule-action parâmetro. Esses valores especificam o que AWS DMS acontece por padrão com registros que não são excluídos como parte da lista de exclude-columns atributos. Esses valores não afetam os mapeamentos de atributos de forma alguma.
-
É possível utilizar
map-record-to-recordao migrar de um banco de dados relacional para o DynamoDB. Ele utiliza a chave primária do banco de dados relacional como a chave de partição no DynamoDB e cria um atributo para cada coluna no banco de dados de origem. Ao usarmap-record-to-record, para qualquer coluna na tabela de origem não listada na lista de atributos, AWS DMS cria umexclude-columnsatributo correspondente na instância do DynamoDB de destino. Isso é feito, independentemente de a coluna de origem ser utilizada ou não em um mapeamento de atributos. -
Você utiliza
map-record-to-documentpara colocar colunas de origem em um único mapa sem formatação do DynamoDB no destino, utilizando o nome de atributo "_doc". Ao usarmap-record-to-document, AWS DMS coloca os dados em um único atributo de mapa plano do DynamoDB na fonte. Esse atributo é chamado "_doc". Esse posicionamento se aplica a qualquer coluna na tabela de origem que não aparece na lista de atributosexclude-columns.
Uma maneira de compreender a diferença entre os parâmetros de rule-action, map-record-to-record e map-record-to-document, é ver os dois parâmetros em ação. Para este exemplo, suponha que você está começando com uma linha de tabela de banco de dados relacional com a seguinte estrutura e dados:

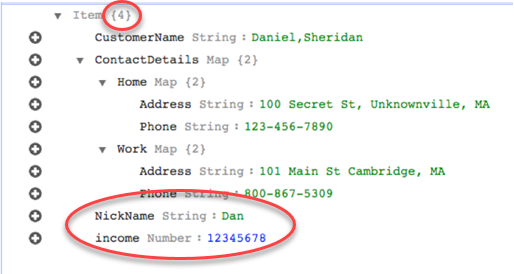
Para migrar essas informações para o DynamoDB, você criaria regras para mapear os dados para um item de tabela do DynamoDB. Observe as colunas listadas para o parâmetro exclude-columns. Essas colunas não são mapeadas diretamente para o destino. Em vez disso, o mapeamento de atributos é usado para combinar os dados em novos itens, como onde FirstNamee LastNamesão agrupados para se tornarem CustomerNameno destino do DynamoDB. NickNamee a renda não está excluída.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
Ao usar o rule-action parâmetro map-record-to-record, os dados NickNamee a receita são mapeados para itens com o mesmo nome no destino do DynamoDB.
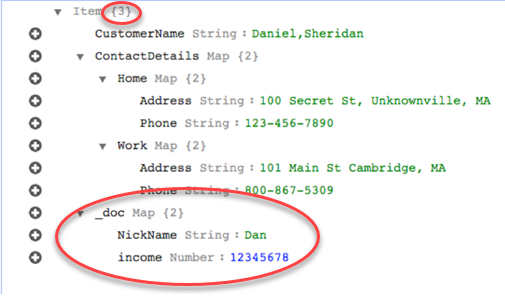
No entanto, suponhamos que você utilize as mesmas regras, mas altere o parâmetro rule-action para map-record-to-document. Nesse caso, as colunas não listadas no exclude-columns parâmetro NickNamee renda são mapeadas para um item _doc.
Utilizar expressões de condição personalizadas com o mapeamento de objetos
É possível utilizar um recurso do DynamoDB chamado de expressões condicionais para manipular dados que estão sendo gravados em uma tabela do DynamoDB. Para obter mais informações sobre expressões condicionais no DynamoDB, consulte Expressões de condição.
Um membro de expressão condicional consiste em:
-
uma expressão (obrigatória);
-
valores de atributos de expressão (obrigatório). Especificam uma estrutura json do DynamoDB do valor de atributo. Isso é útil para comparar um atributo com um valor no DynamoDB que você talvez só conhecerá no runtime. Você pode definir um atributo de expressão como um espaço reservado para um valor real.
-
nomes de atributos de expressão (obrigatório). Isso ajuda a evitar possíveis conflitos com quaisquer palavras reservadas do DynamoDB, nomes de atributo que contêm caracteres especiais e similares.
-
opções para quando utilizar a expressão condicional (opcional). O padrão é apply-during-cdc = falso e apply-during-full-load = verdadeiro
A estrutura da regra é a seguinte:
"target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "condition-expression": { "expression":"<conditional expression>", "expression-attribute-values": [ { "name":"<attribute name>", "value":<attribute value> } ], "apply-during-cdc":<optional Boolean value>, "apply-during-full-load": <optional Boolean value> }
O exemplo a seguir destaca as seções utilizadas para expressão condicional.

Usar o mapeamento de atributo com mapeamento de objeto
O mapeamento de atributo permite especificar uma string de modelo utilizando nomes de colunas de origem para reestruturar dados no destino. Não há formatação feita além do que o usuário especifica no modelo.
O exemplo a seguir mostra a estrutura do banco de dados de origem e a estrutura desejada do destino do DynamoDB. Primeiramente, é mostrada a estrutura da origem: nesse caso um banco de dados Oracle, e, depois, a estrutura desejada dos dados no DynamoDB. O exemplo termina com o JSON utilizado para criar a estrutura de destino desejada.
A estrutura dos dados do Oracle é a seguinte:
| FirstName | LastName | StoreId | HomeAddress | HomePhone | WorkAddress | WorkPhone | DateOfBirth |
|---|---|---|---|---|---|---|---|
| Chave primária | N/A | ||||||
| Randy | Marsh | 5 | 221B Baker Street | 1234567890 | 31 Spooner Street, Quahog | 9876543210 | 02/29/1988 |
A estrutura dos dados do DynamoDB é a seguinte:
| CustomerName | StoreId | ContactDetails | DateOfBirth |
|---|---|---|---|
| Chave de partição | Chave de classificação | N/A | |
|
|
|
|
O JSON a seguir mostra o mapeamento de objetos e o mapeamento de colunas utilizados para alcançar a estrutura do DynamoDB:
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "{\"Name\":\"${FirstName}\",\"Home\":{\"Address\":\"${HomeAddress}\",\"Phone\":\"${HomePhone}\"}, \"Work\":{\"Address\":\"${WorkAddress}\",\"Phone\":\"${WorkPhone}\"}}" } ] } } ] }
Outra maneira de utilizar o mapeamento de colunas é utilizar o formato do DynamoDB como o tipo de documento. O código a seguir utiliza dynamodb-map como attribute-sub-type para o mapeamento de atributo.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Name": { "S": "${FirstName}" }, "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
Como alternativa a dynamodb-map, é possível utilizar dynamodb-list como o subtipo de atributo para mapeamento de atributos, conforme mostrado no exemplo a seguir.
{ "target-attribute-name": "ContactDetailsList", "attribute-type": "document", "attribute-sub-type": "dynamodb-list", "value": { "L": [ { "N": "${FirstName}" }, { "N": "${HomeAddress}" }, { "N": "${HomePhone}" }, { "N": "${WorkAddress}" }, { "N": "${WorkPhone}" } ] } }
Exemplo 1: Usar o mapeamento de atributo com mapeamento de objeto
O exemplo a seguir migra dados de duas tabelas do banco de dados MySQL, nfl_data e sport_team, para duas tabelas do DynamoDB chamadas NFLTeams e. SportTeams A estrutura das tabelas e do JSON utilizados para mapear os dados das tabelas do banco de dados MySQL para as tabelas do DynamoDB é mostrada a seguir.
A estrutura da tabela do banco de dados MySQL nfl_data é mostrada abaixo:
mysql> desc nfl_data; +---------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+-------+ | Position | varchar(5) | YES | | NULL | | | player_number | smallint(6) | YES | | NULL | | | Name | varchar(40) | YES | | NULL | | | status | varchar(10) | YES | | NULL | | | stat1 | varchar(10) | YES | | NULL | | | stat1_val | varchar(10) | YES | | NULL | | | stat2 | varchar(10) | YES | | NULL | | | stat2_val | varchar(10) | YES | | NULL | | | stat3 | varchar(10) | YES | | NULL | | | stat3_val | varchar(10) | YES | | NULL | | | stat4 | varchar(10) | YES | | NULL | | | stat4_val | varchar(10) | YES | | NULL | | | team | varchar(10) | YES | | NULL | | +---------------+-------------+------+-----+---------+-------+
A estrutura do banco de dados MySQL sport_team é mostrada abaixo:
mysql> desc sport_team; +---------------------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------------------+--------------+------+-----+---------+----------------+ | id | mediumint(9) | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | NULL | | | abbreviated_name | varchar(10) | YES | | NULL | | | home_field_id | smallint(6) | YES | MUL | NULL | | | sport_type_name | varchar(15) | NO | MUL | NULL | | | sport_league_short_name | varchar(10) | NO | | NULL | | | sport_division_short_name | varchar(10) | YES | | NULL | |
As regras de mapeamento de tabela utilizadas para mapear as duas tabelas para as duas tabelas do DynamoDB são mostradas abaixo:
{ "rules":[ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "dms_sample", "table-name": "nfl_data" }, "rule-action": "include" }, { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "dms_sample", "table-name": "sport_team" }, "rule-action": "include" }, { "rule-type":"object-mapping", "rule-id":"3", "rule-name":"MapNFLData", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"nfl_data" }, "target-table-name":"NFLTeams", "mapping-parameters":{ "partition-key-name":"Team", "sort-key-name":"PlayerName", "exclude-columns": [ "player_number", "team", "name" ], "attribute-mappings":[ { "target-attribute-name":"Team", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${team}" }, { "target-attribute-name":"PlayerName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"PlayerInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"Number\": \"${player_number}\",\"Position\": \"${Position}\",\"Status\": \"${status}\",\"Stats\": {\"Stat1\": \"${stat1}:${stat1_val}\",\"Stat2\": \"${stat2}:${stat2_val}\",\"Stat3\": \"${stat3}:${ stat3_val}\",\"Stat4\": \"${stat4}:${stat4_val}\"}" } ] } }, { "rule-type":"object-mapping", "rule-id":"4", "rule-name":"MapSportTeam", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"sport_team" }, "target-table-name":"SportTeams", "mapping-parameters":{ "partition-key-name":"TeamName", "exclude-columns": [ "name", "id" ], "attribute-mappings":[ { "target-attribute-name":"TeamName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"TeamInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"League\": \"${sport_league_short_name}\",\"Division\": \"${sport_division_short_name}\"}" } ] } } ] }
A amostra de saída da tabela NFLTeams do DynamoDB é mostrada abaixo:
"PlayerInfo": "{\"Number\": \"6\",\"Position\": \"P\",\"Status\": \"ACT\",\"Stats\": {\"Stat1\": \"PUNTS:73\",\"Stat2\": \"AVG:46\",\"Stat3\": \"LNG:67\",\"Stat4\": \"IN 20:31\"}", "PlayerName": "Allen, Ryan", "Position": "P", "stat1": "PUNTS", "stat1_val": "73", "stat2": "AVG", "stat2_val": "46", "stat3": "LNG", "stat3_val": "67", "stat4": "IN 20", "stat4_val": "31", "status": "ACT", "Team": "NE" }
O exemplo de saída da tabela do SportsTeams DynamoDB é mostrado abaixo:
{ "abbreviated_name": "IND", "home_field_id": 53, "sport_division_short_name": "AFC South", "sport_league_short_name": "NFL", "sport_type_name": "football", "TeamInfo": "{\"League\": \"NFL\",\"Division\": \"AFC South\"}", "TeamName": "Indianapolis Colts" }
Tipos de dados de destino do DynamoDB
O endpoint do DynamoDB for é AWS DMS compatível com a maioria dos tipos de dados do DynamoDB. A tabela a seguir mostra os tipos de dados de AWS DMS destino da Amazon que são compatíveis com o uso AWS DMS e o mapeamento padrão dos tipos de AWS DMS dados.
Para obter informações adicionais sobre AWS DMS os tipos de dados, consulteTipos de dados do AWS Database Migration Service.
Ao AWS DMS migrar dados de bancos de dados heterogêneos, mapeamos tipos de dados do banco de dados de origem para tipos de dados intermediários chamados AWS DMS tipos de dados. Em seguida, mapeamos os tipos de dados intermediários para os tipos de dados de destino. A tabela a seguir mostra cada tipo de AWS DMS dados e o tipo de dados para o qual ele é mapeado no DynamoDB:
| AWS DMS tipo de dados | Tipo de dados do DynamoDB |
|---|---|
|
String |
String |
|
WString |
String |
|
Booleano |
Booleano |
|
Data |
String |
|
DateTime |
String |
|
INT1 |
Número |
|
INT2 |
Número |
|
INT4 |
Número |
|
INT8 |
Número |
|
Numérico |
Número |
|
Real4 |
Número |
|
Real8 |
Número |
|
UINT1 |
Número |
|
UINT2 |
Número |
|
UINT4 |
Número |
| UINT8 | Número |
| CLOB | String |
