As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Migração de dados de bancos de dados PostgreSQL com migrações de dados homogêneas em AWS DMS
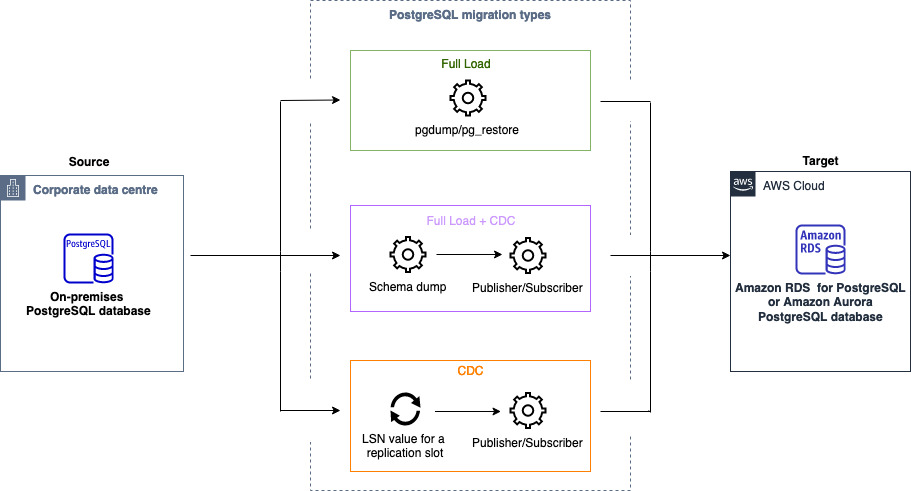
É possível utilizar Migração de dados homogênea para migrar um banco de dados PostgreSQL autogerenciado para o RDS para PostgreSQL ou o Aurora PostgreSQL. O AWS DMS cria um ambiente com tecnologia sem servidor para a migração de dados. Para diferentes tipos de migração de dados, o AWS DMS utiliza diferentes ferramentas nativas do banco de dados do PostgreSQL.
Para migrações de dados homogêneas do tipo Full load, AWS DMS usa pg_dump para ler dados do banco de dados de origem e armazená-los no disco conectado ao ambiente sem servidor. Depois de AWS DMS ler todos os dados de origem, ele usa pg_restore no banco de dados de destino para restaurar seus dados.
Para migrações de dados homogêneas do tipo Full load and Change Data Capture (CDC), AWS DMS usa pg_dump para ler objetos de esquema sem dados de tabela do banco de dados de origem e armazená-los no disco conectado ao ambiente sem servidor. Em seguida, utiliza pg_restore no banco de dados de destino para restaurar os objetos do esquema. Depois de AWS DMS concluir o pg_restore processo, ele muda automaticamente para um modelo de editor e assinante para replicação lógica com a Initial Data Synchronization opção de copiar os dados iniciais da tabela diretamente do banco de dados de origem para o banco de dados de destino e, em seguida, inicia a replicação contínua. Nesse modelo, um ou mais assinantes assinam uma ou mais publicações em um nó do publicador.
Para migrações de dados homogêneas do tipo Change data capture (CDC), é AWS DMS necessário o ponto de partida nativo para iniciar a replicação. Se você fornecer o ponto inicial nativo, AWS DMS capturará as alterações desse ponto. Como alternativa, escolha Imediatamente nas configurações da migração de dados para capturar automaticamente o ponto de início da replicação quando a migração de dados real for iniciada.
nota
Para que uma CDC-only migração funcione adequadamente, todos os esquemas e objetos do banco de dados de origem já devem estar presentes no banco de dados de destino. No entanto, o destino pode ter objetos que não estão presentes na origem.
É possível utilizar o exemplo de código a seguir para obter o ponto de início nativo no banco de dados do PostgreSQL.
select confirmed_flush_lsn from pg_replication_slots where slot_name=‘migrate_to_target';
Essa consulta utiliza a visualização pg_replication_slots no banco de dados do PostgreSQL para capturar o valor do número de sequência de log (LSN).
Depois de AWS DMS definir o status da migração homogênea de dados do PostgreSQL como Parada, Falha ou Excluída, o editor e a replicação não serão removidos. Se você não quiser retomar a migração, exclua o slot de replicação e o publicador utilizando o comando a seguir.
SELECT pg_drop_replication_slot('migration_subscriber_{ARN}'); DROP PUBLICATION publication_{ARN};
O diagrama a seguir mostra o processo de uso de migrações de dados homogêneas para migrar um banco de dados PostgreSQL AWS DMS para o RDS for PostgreSQL ou Aurora PostgreSQL.
Práticas recomendadas para utilizar um banco de dados PostgreSQL como origem para migrações de dados homogêneas
Para acelerar a sincronização de dados inicial no lado do assinante para a tarefa FLCDC, você deve ajustar
max_logical_replication_workersemax_sync_workers_per_subscription. Aumentar esses valores aumenta a velocidade de sincronização da tabela.max_logical_replication_workers: especifica o número máximo de operadores de replicação lógica. Isso inclui os operadores de aplicação no lado do assinante e os operadores de sincronização de tabelas.
max_sync_workers_per_subscription: o aumento de
max_sync_workers_per_subscriptionafeta somente o número de tabelas sincronizadas em paralelo, não o número de operadores por tabela.
nota
max_logical_replication_workersnão deve excedermax_worker_processes, emax_sync_workers_per_subscriptiondeve ser menor ou igual amax_logical_replication_workers.Para migrar tabelas grandes, considere dividi-las em tarefas separadas usando regras de seleção. Por exemplo, você pode dividir tabelas grandes em tarefas individuais separadas e tabelas pequenas em outra tarefa única.
Monitore a utilização do disco e da CPU no lado do assinante para manter o máximo desempenho.
