As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Crie um plano de migração para migrar do Apache Cassandra para o Amazon Keyspaces
Para uma migração bem-sucedida do Apache Cassandra para o Amazon Keyspaces, recomendamos uma análise dos conceitos e das melhores práticas de migração aplicáveis, bem como uma comparação das opções disponíveis.
Este tópico descreve como o processo de migração funciona, apresentando vários conceitos-chave e as ferramentas e técnicas disponíveis para você. É possível avaliar as diferentes estratégias de migração para selecionar a mais adequada às suas necessidades.
Tópicos
Compatibilidade funcional
Considere cuidadosamente as diferenças funcionais entre o Apache Cassandra e o Amazon Keyspaces antes da migração. O Amazon Keyspaces oferece suporte a todas as operações de plano de dados do Cassandra comumente usadas, como criar espaços de chaves e tabelas, ler dados e gravar dados.
No entanto, existem algumas APIs do Cassandra que o Amazon Keyspaces não suporta. Para obter mais informações sobre as APIs compatíveis, consulte APIs, operações, funções e tipos de dados compatíveis do Cassandra. Para obter uma visão geral de todas as diferenças funcionais entre o Amazon Keyspaces e o Apache Cassandra, consulte Diferenças funcionais: Amazon Keyspaces versus Apache Cassandra.
Para comparar as APIs e o esquema do Cassandra que você está usando com a funcionalidade compatível no Amazon Keyspaces, você pode executar um script de compatibilidade disponível no kit de ferramentas do Amazon Keyspaces em. GitHub
Como usar o script de compatibilidade
Baixe o script de compatibilidade do Python GitHub
e mova-o para um local que tenha acesso ao seu cluster Apache Cassandra existente. O script de compatibilidade usa parâmetros semelhantes a
CQLSH. Para--hoste--portinsira o endereço IP e a porta que você usa para se conectar e executar consultas em um dos nós do Cassandra em seu cluster.Se seu cluster Cassandra usa autenticação, você também precisa fornecer
-usernamee-password. Para usar o script de compatibilidade, você pode executar o seguinte comando.python toolkit-compat-tool.py --hosthostname or IP-u "username" -p "password" --portnative transport port
Custos estimados do Amazon Keyspaces
Esta seção fornece uma visão geral das informações que você precisa coletar das tabelas do Apache Cassandra para calcular o custo estimado do Amazon Keyspaces. Cada uma de suas tabelas exige tipos de dados diferentes, precisa oferecer suporte a diferentes consultas CQL e manter um tráfego distinto read/write .
Pensar em seus requisitos com base em tabelas se alinha aos modos de capacidade de transferência e isolamento read/write de recursos em nível de tabela do Amazon Keyspaces. Com o Amazon Keyspaces, você pode definir políticas de read/write capacidade e escalabilidade automática para tabelas de forma independente.
Compreender os requisitos das tabelas ajuda você a priorizar tabelas para migração com base na funcionalidade, no custo e no esforço de migração.
Colete as seguintes métricas da tabela do Cassandra antes de uma migração. Essas informações ajudam a estimar o custo da sua workload no Amazon Keyspaces.
Nome da tabela: o nome do espaço de chaves totalmente qualificado e o nome da tabela.
Descrição: uma descrição da tabela, por exemplo, como ela é usada ou que tipo de dados são armazenados nela.
Média de leituras por segundo: o número médio de leituras em nível de coordenadas na tabela em um grande intervalo de tempo.
Média de gravações por segundo: o número médio de gravações em nível de coordenadas na tabela em um grande intervalo de tempo.
Tamanho médio da linha em bytes: o tamanho médio da linha em bytes.
Tamanho do armazenamento em GBs: o tamanho bruto do armazenamento de uma tabela.
Detalhamento da consistência de leitura: a porcentagem de leituras que usam consistência eventual (
LOCAL_ONEouONE) versus consistência forte (LOCAL_QUORUM).
Esta tabela mostra um exemplo das informações sobre suas tabelas que você precisa reunir ao planejar uma migração.
| Nome da tabela | Description | Média de leitura por segundo | Média de gravação por segundo | Tamanho médio da linha em bytes | Tamanho de armazenamento em GB | Detalhamento de consistência de leitura |
|---|---|---|---|---|---|---|
|
mykeyspace.mytable |
Usado para armazenar o histórico do carrinho de compras |
10.000 |
5.000 |
2.200 |
2.000 |
100% |
mykeyspace.mytable2 |
Usado para armazenar as informações mais recentes do perfil |
20.000 |
1.000 |
850 |
1.000 |
25% |
Como coletar métricas de tabela
Esta seção fornece instruções passo a passo sobre como coletar as métricas de tabela necessárias do seu cluster Cassandra existente. Essas métricas incluem tamanho da linha, tamanho da tabela e read/write solicitações por segundo (RPS). Eles permitem que você avalie os requisitos de capacidade de throughput de uma tabela do Amazon Keyspaces e estime os preços.
Como coletar métricas de tabela na tabela de origem do Cassandra
Determinar o tamanho da linha
O tamanho da linha é importante para determinar a capacidade de leitura e a utilização da capacidade de gravação no Amazon Keyspaces. O diagrama a seguir mostra a distribuição de dados típica em um intervalo de tokens do Cassandra.
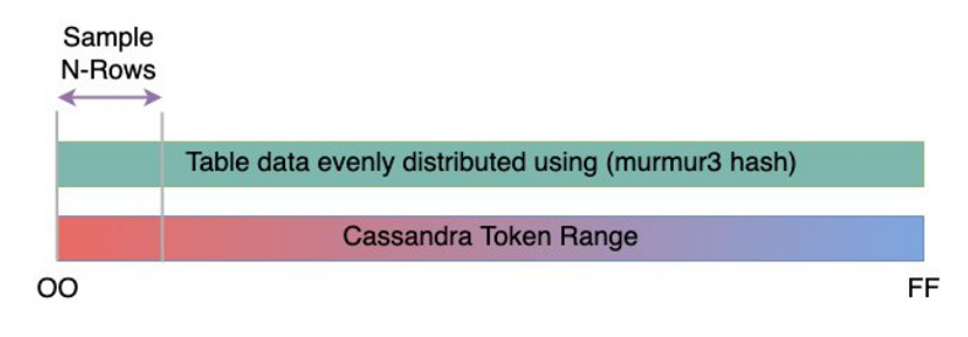
Você pode usar um script de amostragem de tamanho de linha disponível GitHub
para coletar métricas de tamanho de linha para cada tabela em seu cluster do Cassandra. O script exporta dados da tabela do Apache Cassandra usando
cqlsheawkpara calcular o mínimo, o máximo, a média e o desvio padrão do tamanho da linha em um conjunto de amostra configurável de dados da tabela. O amostrador de tamanho de linha passa os argumentos paracqlsh, portanto, os mesmos parâmetros podem ser usados para se conectar e ler do seu cluster do Cassandra.A instrução a seguir é um exemplo disso.
./row-size-sampler.sh10.22.33.449142 \\ -u "username" -p "password" --sslPara saber mais sobre como o tamanho da linha é calculado no Amazon Keyspaces, consulte Estimar o tamanho da linha no Amazon Keyspaces.
Determinar o tamanho da tabela
Com o Amazon Keyspaces, você não precisa provisionar o armazenamento com antecedência. O Amazon Keyspaces monitora continuamente o tamanho faturável de suas tabelas para determinar suas cobranças de armazenamento. O armazenamento é cobrado por. GB-month O tamanho da tabela do Amazon Keyspaces é baseado no tamanho bruto (não compactado) de uma única réplica.
Para monitorar o tamanho da tabela no Amazon Keyspaces, você pode usar a métrica
BillableTableSizeInBytes, que é exibida para cada tabela em Console de gerenciamento da AWS.Para estimar o tamanho faturável da sua tabela do Amazon Keyspaces, você pode usar um desses dois métodos:
Use o tamanho médio da linha e multiplique pelo número ou linhas.
Você pode estimar o tamanho da tabela Amazon Keyspaces multiplicando o tamanho médio da linha pelo número de linhas da tabela de origem do Cassandra. Use o script de amostra de tamanho de linha da seção anterior para capturar o tamanho médio da linha. Para capturar a contagem de linhas, você pode usar ferramentas como
dsbulk countdeterminar o número total de linhas na tabela de origem.Use o
nodetoolpara coletar os metadados da tabela.Nodetoolé uma ferramenta administrativa fornecida na distribuição do Apache Cassandra que fornece uma visão sobre o estado do processo do Cassandra e retorna os metadados da tabela. Você pode usarnodetoolpara amostrar metadados sobre o tamanho da tabela e, com isso, extrapolar o tamanho da tabela no Amazon Keyspaces.O comando a ser usado é
nodetool tablestats. Tablestats retorna o tamanho e a taxa de compactação da tabela. O tamanho da tabela é armazenado comotablelivespaceda tabela e você pode dividi-lo porcompression ratio. Em seguida, multiplique esse valor de tamanho pelo número de nós. Por fim, divida pelo fator de replicação (normalmente três).Essa é a fórmula completa do cálculo que você pode usar para avaliar o tamanho da tabela.
((tablelivespace / compression ratio) * (total number of nodes))/ (replication factor)Vamos supor que seu cluster do Cassandra tenha 12 nós. A execução do
nodetool tablestatscomando retorna umtablelivespacede 200 GB e umcompression ratiode 0,5. O espaço de chave tem um fator de replicação de três.É assim que o cálculo desse exemplo se parece.
(200 GB / 0.5) * (12 nodes)/ (replication factor of 3) = 4,800 GB / 3 = 1,600 GB is the table size estimate for Amazon Keyspaces
Capture o número de leituras e gravações
Para determinar os requisitos de capacidade e ajuste de escala para suas tabelas do Amazon Keyspaces, capture a taxa de solicitação de leitura e gravação de suas tabelas do Cassandra antes da migração.
O Amazon Keyspaces não tem servidor e você paga apenas pelo que usa. Em geral, o preço da read/write taxa de transferência no Amazon Keyspaces é baseado no número e no tamanho das solicitações.
Há dois modos de capacidade no Amazon Keyspaces:
On-demand— Essa é uma opção de cobrança flexível capaz de atender a milhares de solicitações por segundo sem a necessidade de planejamento de capacidade. Esta opção oferece preços de pagamento por solicitação para solicitações de leitura e gravação, para que você pague apenas pelo que usar.
Provisionada: se você selecionar o modo de capacidade de throughput provisionada, especifique o número de leituras e gravações por segundo necessárias para seu aplicativo. Isso ajuda você a gerenciar o uso do Amazon Keyspaces para permanecer em ou abaixo de uma taxa de solicitação definida para manter a previsibilidade.
O modo provisionado oferece ajuste de escala automático para ajustar automaticamente sua taxa provisionada para aumentar ou reduzir a escala verticalmente para melhorar a eficiência operacional. Para obter mais informações sobre o gerenciamento de recursos com tecnologia sem servidor, consulte Como gerenciar os recursos de tecnologia sem servidor no Amazon Keyspaces (para Apache Cassandra).
Como você provisiona a capacidade de throughput de leitura e gravação no Amazon Keyspaces separadamente, você precisa medir a taxa de solicitações para leituras e gravações em suas tabelas existentes de forma independente.
Para reunir as métricas de utilização mais precisas do seu cluster Cassandra existente, capture a média de solicitações por segundo (RPS) para operações de leitura e gravação em nível de coordenador durante um longo período de tempo para uma tabela agregada em todos os nós em um único data center.
Capturar o RPS médio em um período de pelo menos várias semanas captura picos e baixos em seus padrões de tráfego, conforme mostrado no diagrama a seguir.
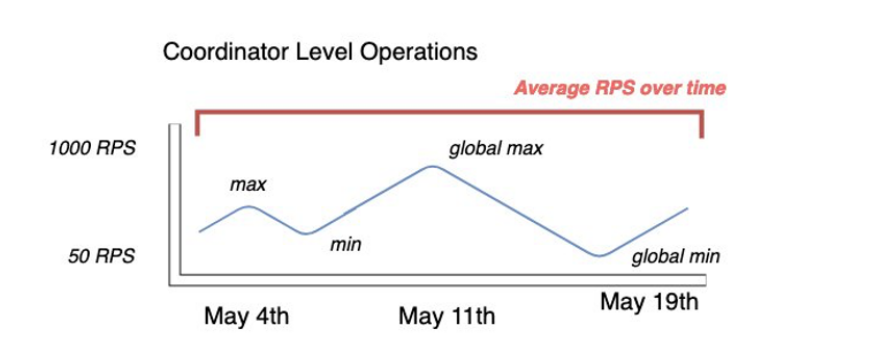
Você tem duas opções para determinar a taxa de solicitações de leitura e gravação da sua tabela do Cassandra.
Use o monitoramento existente do Cassandra
É possível usar as métricas mostradas na tabela a seguir para observar solicitações de leituras e gravações. Observe que os nomes das métricas podem mudar com base na ferramenta de monitoramento que você está usando.
Dimensão Métrica do Cassandra JMX Gravações
org.apache.cassandra.metrics:type=ClientRequest, scope=Write,name=Latency#CountLeituras
org.apache.cassandra.metrics:type=ClientRequest, scope=Read,name=Latency#CountUsar a
nodetoolUse
nodetool tablestatsenodetool infopara capturar a média de operações de leitura e gravação da tabela.tablestatsretorna a contagem total de leituras e gravações a partir do momento em que o nó foi iniciado.nodetool infofornece o tempo de atividade de um nó em segundos.Para receber a média de leituras e gravações por segundo, divida a contagem de leitura e gravação pelo tempo de atividade do nó em segundos. Em seguida, para leituras, você divide pelo nível de consistência e, para gravações, divide pelo fator de replicação. Esses cálculos são expressos nas fórmulas a seguir.
Fórmula para leituras médias por segundo:
((number of reads * number of nodes in cluster) / read consistency quorum (2)) / uptimeFórmula para a média de gravações por segundo:
((number of writes * number of nodes in cluster) / replication factor of 3) / uptimeVamos supor que temos um cluster de 12 nós que está ativo há 4 semanas.
nodetool inforetorna 2.419.200 segundos de tempo de atividade enodetool tablestatsretorna 1 bilhão de gravações e 2 bilhões de leituras. Esse exemplo resultaria no cálculo a seguir.((2 billion reads * 12 in cluster) / read consistency quorum (2)) / 2,419,200 seconds = 12 billion reads / 2,419,200 seconds = 4,960 read request per second ((1 billion writes * 12 in cluster) / replication factor of 3) / 2,419,200 seconds = 4 billion writes / 2,419,200 seconds = 1,653 write request per second
Determine a utilização da capacidade da tabela
Para estimar a utilização média da capacidade, comece com as taxas médias de solicitação e o tamanho médio da linha da tabela de origem do Cassandra.
O Amazon Keyspaces usa unidades de capacidade de leitura (RCUs) e unidades de capacidade de gravação (WCUs) para medir a capacidade de throughput provisionada para leituras e gravações em tabelas. Para essa estimativa, usamos essas unidades para calcular as necessidades de capacidade de leitura e gravação da nova tabela do Amazon Keyspaces após a migração.
Posteriormente neste tópico, discutiremos como a escolha entre o modo de capacidade provisionada e sob demanda afeta o faturamento. Mas para a estimativa da utilização da capacidade neste exemplo, presumimos que a tabela esteja no modo provisionado.
Leituras: um RCU representa uma solicitação de leitura
LOCAL_QUORUMou duas solicitações de leituraLOCAL_ONEpara uma linha com até 4 KB de tamanho. Se você precisar ler uma linha maior que 4 KB, a operação de leitura usará RCUs adicionais. O número total de RCUs necessários varia de acordo com o tamanho da linha e se você deseja usar consistência de leituraLOCAL_QUORUMouLOCAL_ONE.Por exemplo, a leitura de uma linha de 8 KB exige 2 RCUs usando consistência de leitura
LOCAL_QUORUMe 1 RCU se você selecionar consistência de leituraLOCAL_ONE.Gravação: um WCU representa uma gravação para uma linha com até 1 KB de tamanho. Todas as gravações estão usando consistência
LOCAL_QUORUMe não há cobrança adicional pelo uso de transações leves (LWTs).O número total de WCUs necessárias depende do tamanho da linha. Se você precisar gravar uma linha maior que 1 KB, a operação de gravação usará WCUs adicionais. Por exemplo, se o tamanho da sua linha for 2 KB, você precisa de 2 WCUs para realizar uma solicitação de gravação.
A fórmula a seguir pode ser usada para estimar as RCUs e WCUs necessárias.
A capacidade de leitura em RCUs pode ser determinada multiplicando as leituras por segundo pelo número de linhas lidas por leitura multiplicado pelo tamanho médio da linha dividido por 4 KB e arredondado para o número inteiro mais próximo.
A capacidade de gravação nas WCUs pode ser determinada multiplicando o número de solicitações pelo tamanho médio da linha dividido por 1 KB e arredondado para o número inteiro mais próximo.
Isso é expresso nas fórmulas a seguir.
Read requests per second * ROUNDUP((Average Row Size)/4096 per unit) = RCUs per second Write requests per second * ROUNDUP(Average Row Size/1024 per unit) = WCUs per secondPor exemplo, se você estiver realizando 4.960 solicitações de leitura com um tamanho de linha de 2,5 KB em sua tabela do Cassandra, precisará de 4.960 RCUs no Amazon Keyspaces. Se você está realizando atualmente 1.653 solicitações de gravação por segundo com um tamanho de linha de 2,5 KB em sua tabela do Cassandra, você precisa de 4.959 WCUs por segundo no Amazon Keyspaces.
Esse exemplo é expresso nas fórmulas a seguir.
4,960 read requests per second * ROUNDUP( 2.5KB /4KB bytes per unit) = 4,960 read requests per second * 1 RCU = 4,960 RCUs 1,653 write requests per second * ROUNDUP(2.5KB/1KB per unit) = 1,653 requests per second * 3 WCUs = 4,959 WCUsO uso de
eventual consistencypermite que você economize até metade da capacidade de throughput em cada solicitação de leitura. Cada leitura final consistente pode consumir até 8 KB. Você pode calcular eventuais leituras consistentes multiplicando o cálculo anterior por 0,5, conforme mostrado na fórmula a seguir.4,960 read requests per second * ROUNDUP( 2.5KB /4KB per unit) * .5 = 2,480 read request per second * 1 RCU = 2,480 RCUs-
Calcule a estimativa de preço mensal para o Amazon Keyspaces
Para estimar o faturamento mensal da tabela com base na taxa de transferência da read/write capacidade, você pode calcular os preços para o modo sob demanda e para o modo provisionado usando fórmulas diferentes e comparar as opções da sua tabela.
Modo provisionado: o consumo de capacidade de leitura e gravação é cobrado em uma taxa horária com base nas unidades de capacidade por segundo. Primeiro, divida essa taxa por 0,7 para representar a meta de utilização padrão de ajuste de escala automático de 70%. Em seguida, multiplique por 30 dias corridos, 24 horas por dia e preços tarifários regionais.
Esse cálculo está resumido nas fórmulas a seguir.
(read capacity per second / .7) * 24 hours * 30 days * regional rate (write capacity per second / .7) * 24 hours * 30 days * regional rateOn-demand modo — a capacidade de leitura e gravação é cobrada de acordo com uma taxa por solicitação. Primeiro, multiplique a taxa de solicitações por 30 dias corridos e 24 horas por dia. Em seguida, divida por um milhão de unidades de solicitação. Por fim, multiplique pela taxa regional.
Esse cálculo está resumido nas fórmulas a seguir.
((read capacity per second * 30 * 24 * 60 * 60) / 1 Million read request units) * regional rate ((write capacity per second * 30 * 24 * 60 * 60) / 1 Million write request units) * regional rate
Escolher uma estratégia de migração
Você pode escolher entre as seguintes estratégias de migração ao migrar do Apache Cassandra para o Amazon Keyspaces:
On-line: essa é uma migração ao vivo usando gravações duplas para começar a gravar novos dados no Amazon Keyspaces e no cluster Cassandra simultaneamente. Esse tipo de migração é recomendado para aplicativos que exigem zero tempo de inatividade durante a migração e consistência de leitura após gravação.
Para saber mais sobre como planejar e implementar uma estratégia de migração on-line, consulte Migração on-line para o Amazon Keyspaces: estratégias e melhores práticas.
Off-line: essa técnica de migração envolve a cópia de um conjunto de dados do Cassandra para o Amazon Keyspaces durante uma janela de tempo de inatividade. A migração off-line pode simplificar o processo de migração, pois não exige alterações em seu aplicativo ou resolução de conflitos entre dados históricos e novas gravações.
Para saber mais sobre como planejar uma migração off-line, consulte Processo de migração off-line: Apache Cassandra para Amazon Keyspaces.
Híbrida: essa técnica de migração permite que as alterações sejam replicadas para o Amazon Keyspaces quase em tempo real, mas sem consistência de leitura após gravação.
Para saber mais sobre como planejar uma migração híbrida, consulte Usando uma solução de migração híbrida: Apache Cassandra para Amazon Keyspaces.
Depois de analisar as técnicas de migração e as melhores práticas discutidas neste tópico, você pode colocar as opções disponíveis em uma árvore decisória para criar uma estratégia de migração com base em seus requisitos e recursos disponíveis.
