AWS Lake Formationsuporta a criação de tabelas Apache Iceberg que usam o formato de dados Apache Parquet no AWS Glue Data Catalog com dados residentes no Amazon S3. Uma tabela no catálogo de dados é a definição de metadados que representa os dados em um armazenamento de dados. Por padrão, o Lake Formation cria tabelas do Iceberg v2. Para saber a diferença entre as tabelas da v1 e v2, consulte Alterações de versão do formato
Apache Iceberg
Você pode usar o console do Lake Formation ou a operação CreateTable na API do AWS Glue para criar uma tabela Iceberg no catálogo de dados. Para obter mais informações, consulte a ação CreateTable (Python: create_table).
Ao criar uma tabela do Iceberg no catálogo de dados, você deve especificar o formato da tabela e o caminho do arquivo de metadados no Amazon S3 para poder realizar leituras e gravações.
Você pode usar o Lake Formation para proteger sua tabela do Iceberg usando permissões de controle de acesso refinadas ao registrar a localização de dados do Amazon S3 com o AWS Lake Formation. Para dados de origem no Amazon S3 e metadados que não estão registrados no Lake Formation, o acesso é determinado pelas políticas de permissões do IAM para ações do Amazon S3 e do AWS Glue. Para ter mais informações, consulte Gerenciando permissões do Lake Formation.
nota
O catálogo de dados não oferece suporte à criação de partições e à adição de propriedades da tabela do Iceberg.
Pré-requisitos
Para criar tabelas Iceberg no catálogo de dados e configurar as permissões de acesso aos dados do Lake Formation, você precisa preencher os seguintes requisitos:
-
Permissões necessárias para criar tabelas do Iceberg sem os dados registrados no Lake Formation.
Além das permissões necessárias para criar uma tabela no catálogo de dados, o criador da tabela precisa as seguintes permissões:
s3:PutObjectno recurso arn:aws:s3:::{bucketName}-
s3:GetObjectno recurso arn:aws:s3:::{bucketName} -
s3:DeleteObjectno recurso arn:aws:s3:::{bucketName}
-
Permissões necessárias para criar tabelas do Iceberg com dados registrados no Lake Formation:
Para usar o Lake Formation para gerenciar e proteger os dados em seu data lake, registre sua localização no Amazon S3 que tenha os dados para tabelas com o Lake Formation. Isso é para que a Lake Formation possa fornecer credenciais para serviços analíticos AWS como Athena, Redshift Spectrum e Amazon EMR para acessar dados. Para obter mais informações sobre como registrar um local do Amazon S3, consulte Adicionar uma localização do Amazon S3 ao seu data lake.
Uma entidade principal que lê e grava os dados subjacentes registrados no Lake Formation exige as seguintes permissões:
-
lakeformation:GetDataAccess -
DATA_LOCATION_ACCESSUma entidade principal que tem permissões de localização de dados em um local também tem permissões de localização em todos os locais secundários.
Para obter mais informações sobre permissões de localização de dados, consulte Controle de acesso a dados subjacente.
-
Para permitir a compactação, o serviço precisa assumir um perfil do IAM que tenha permissões para atualizar tabelas no catálogo de dados. Para obter detalhes, consulte Table optimization prerequisites.
Criar uma tabela no Iceberg
Você pode criar tabelas do Iceberg v1 e v2 usando o console Lake Formation ou AWS Command Line Interface conforme documentado nesta página. Você também pode criar tabelas Iceberg usando o console do AWS Glue ou o Crawler do AWS Glue. Para obter mais informações, consulte Catálogo de dados e crawlers no Guia do desenvolvedor do AWS Glue.
Para criar uma tabela no Iceberg
Faça login no AWS Management Console e abra o console do Lake Formation em https://console.aws.amazon.com/lakeformation/
. Em catálogo de dados, escolha Tabelas e use o botão Criar tabela para especificar os seguintes atributos:
-
Nome da tabela: insira um nome para a tabela. Se você estiver usando o Athena para acessar tabelas, use essas dicas de nomenclatura no Guia do usuário do Amazon Athena.
-
Banco de dados: escolha um banco de dados existente ou crie um novo.
-
Descrição: descrição da tabela. Você pode escrever uma descrição para ajudá-lo a entender o conteúdo da tabela.
-
Formato da tabela: para Formato da tabela, escolha Apache Iceberg.
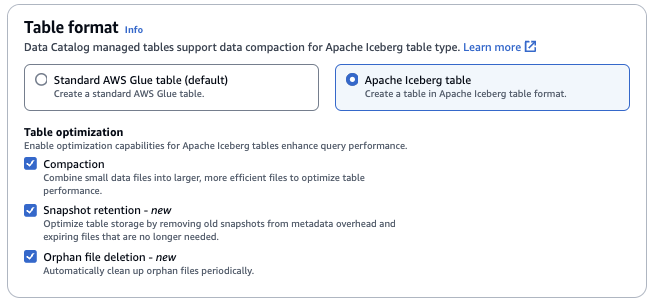
Otimização de tabelas
-
Compactação: os arquivos de dados são mesclados e regravados para remover dados obsoletos e consolidar dados fragmentados em arquivos maiores e mais eficientes.
Retenção de snapshots: os snapshots são versões com carimbo de data e hora de uma tabela do Iceberg. As configurações de retenção de snapshots permitem que os clientes determinem por quanto tempo reter e quantos snapshots devem ser retidos. A configuração de um otimizador de retenção de snapshots pode ajudar a gerenciar a sobrecarga de armazenamento removendo snapshots antigos e desnecessários e seus arquivos subjacentes.
Exclusão de arquivos órfãos: arquivos órfãos são arquivos que não são mais referidos pelos metadados da tabela Iceberg. Esses arquivos podem se acumular ao longo do tempo, especialmente após operações como exclusões de tabelas ou trabalhos de ETL com falha. Habilitar a exclusão de arquivos órfãos permite que o AWS Glue identifique e remova periodicamente esses arquivos desnecessários, liberando espaço de armazenamento.
Para obter mais informações, consulte Como otimizar tabelas do Iceberg.
-
-
Perfil do IAM: para executar a compactação, o serviço assume um perfil do IAM em seu nome. Você pode escolher um perfil do IAM usando o menu suspenso. Certifique-se de que a função tenha as permissões necessárias para habilitar a compactação.
Para saber mais sobre as permissões necessárias, consulte Table optimization prerequisites.
-
Localização: especifique o caminho para a pasta no Amazon S3 que armazena a tabela de metadados. O Iceberg precisa de um arquivo de metadados e de um local no catálogo de dados para poder realizar leituras e gravações.
-
Esquema: escolha Adicionar colunas para adicionar colunas e tipos de dados das colunas. Você tem a opção de criar uma tabela vazia e atualizar o esquema posteriormente. O catálogo de dados oferece suporte aos tipos de dados do Hive. Para obter mais informações, consulte Tipos de dados do Hive
. O Iceberg permite que você evolua o esquema e a partição depois de criar a tabela. Você pode usar as consultas do Athena para atualizar o esquema da tabela e as consultas do Spark
para atualizar as partições.
-
