本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
设计您的 GraphQL 架构GraphQL 架构是任何 GraphQL 服务器实施的基础。每个 GraphQL API 由单个架构定义,其中包含描述如何填充请求中的数据的类型和字段。必须根据架构验证流经 API 的数据和执行的操作。
一般来说,GraphQL 类型系统描述 GraphQL 服务器的功能,并用于确定查询是否有效。服务器的类型系统通常称为该服务器的架构,可以由不同的对象类型、标量类型、输入类型等组成。GraphQL 既是声明性的,又是强类型的,这意味着将在运行时明确定义类型,并且仅返回指定的内容。
AWS AppSync 允许您定义和配置 GraphQL 架构。以下部分介绍如何使用 AWS AppSync的服务从头开始创建 GraphQL 架构。
构建 GraphQL 架构
GraphQL 是一种实施 API 服务的强大工具。根据 GraphQL 网站,GraphQL 定义如下:
“GraphQL 是一种查询语言,也是使用现有数据完成这些查询的运行时。 APIs GraphQL 为你的 API 中的数据提供了完整且易于理解的描述,使客户能够准确地询问他们需要什么,仅此而已,使其更容易随着 APIs 时间的推移而发展,并支持强大的开发者工具。 “
本节介绍了 GraphQL 实施的第一部分,即架构。根据上面的引述,架构扮演“为 API 中的数据提供完整且易于理解的描述”角色。换句话说,GraphQL 架构是您的服务的数据、操作以及它们之间的关系的文本表示形式。架构被视为 GraphQL 服务实施的主要入口点。毫不奇怪,它通常是您在项目中首先实施的内容之一。我们建议在继续之前查看架构一节。
引用架构一节的内容,GraphQL 架构是使用架构定义语言 (SDL) 编写的。SDL 由具有既定结构的类型和字段组成:
-
类型:类型是 GraphQL 定义数据形状和行为的方式。GraphQL 支持多种类型,本节后面将介绍这些类型。架构中定义的每种类型将包含自己的范围。在该范围内具有一个或多个字段,这些字段可以包含在 GraphQL 服务中使用的值或逻辑。类型扮演很多不同的角色,最常见的角色是对象或标量(基元值类型)。
-
字段:字段位于类型范围内,并保存从 GraphQL 服务中请求的值。它们与其他编程语言中的变量非常相似。您在字段中定义的数据形状将决定 request/response 操作中数据的结构方式。这样,开发人员就可以在不知道服务后端实施方式的情况下预测返回的内容。
最简单的架构包含三种不同的数据类别:
-
架构根:根定义架构的入口点。它指向对数据执行某种操作(例如添加、删除或修改某些内容)的字段。
-
类型:这些是用于表示数据形状的基本类型。您几乎可以将它们视为具有定义的特征的事物的对象或抽象表示形式。例如,您可以创建 Person 对象以表示数据库中的某个人。每个人的特征将在 Person 中定义为字段。它们可能是这个人的姓名、年龄、工作、地址等任何内容。
-
特殊对象类型:这些是在架构中定义操作行为的类型。每种特殊对象类型在每个架构中定义一次。它们先放置在架构根中,然后在架构正文中进行定义。特殊对象类型中的每个字段定义解析器实施的单个操作。
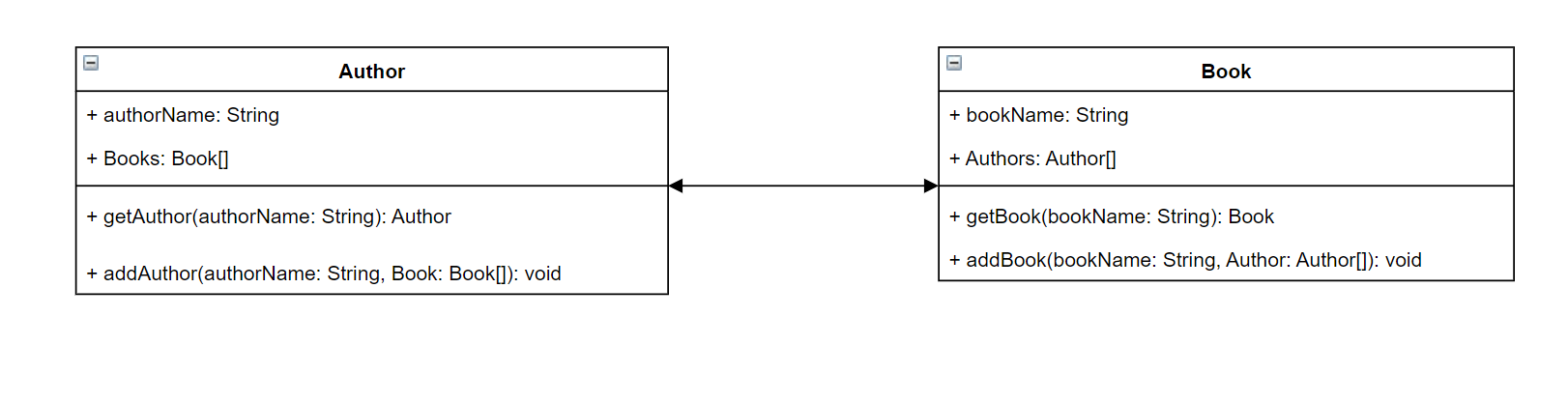
为了便于理解,假设您正在创建一个服务以存储作者及其所写的书籍。每个作者具有姓名和他们撰写的一系列书籍。每本书具有名称和相关的作者列表。我们还希望能够添加或检索书籍和作者。这种关系的简单 UML 表示形式可能如下所示:
在 GraphQL 中,Author 和 Book 实体表示架构中的两种不同的对象类型:
type Author {
}
type Book {
}
Author 包含 authorName 和 Books,而 Book 包含 bookName 和 Authors。这些可以表示为类型范围内的字段:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
正如您看到的一样,类型表示形式与图表非常接近。不过,这些方法可能会变得有些复杂。它们将作为字段放置在几种特殊对象类型之一中。它们的特殊对象分类取决于它们的行为。GraphQL 包含三种基本的特殊对象类型:查询、变更和订阅。有关更多信息,请参阅特殊对象。
由于 getAuthor 和 getBook 都请求数据,因此,它们将放置在 Query 特殊对象类型中:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
这些操作链接到查询,而查询本身链接到架构。添加架构根会将特殊对象类型(该示例中的 Query)定义为入口点之一。可以使用 schema 关键字完成该操作:
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
看一下最后两个方法(addAuthor 和 addBook),它们在数据库中添加数据,因此,它们是在 Mutation 特殊对象类型中定义的。不过,从类型页面中,我们还知道不允许直接引用对象的输入,因为它们严格来说是输出类型。在这种情况下,我们不能使用 Author 或 Book,因此,我们需要创建一种具有相同字段的输入类型。在该示例中,我们添加了 AuthorInput 和 BookInput,它们接受相应类型的相同字段。然后,我们将输入作为参数以创建变更:
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
让我们回顾一下我们刚刚执行的操作:
-
我们创建了一个具有 Book 和 Author 类型的架构以表示我们的实体。
-
我们添加了包含实体特性的字段。
-
我们添加了一个查询,以从数据库中检索该信息。
-
我们添加了一个变更以处理数据库中的数据。
-
我们添加了输入类型以在变更中替换对象参数,从而符合 GraphQL 的规则。
-
我们将查询和变更添加到根架构中,以使 GraphQL 实施了解根类型位置。
正如您看到的一样,创建架构的过程通常采用数据建模(尤其是数据库建模)中的一些概念。您可以将架构视为适合源数据的形状。它还充当解析器实施的模型。在以下各节中,您将学习如何使用各种 AWS支持的工具和服务来创建架构。
以下几节中的示例并不表示在实际应用程序中运行。它们仅用于说明这些命令,以使您可以构建自己的应用程序。
创建架构
您的架构将位于名为的文件中schema.graphql。 AWS AppSync 允许用户使用各种方法为其 G APIs raphQL 创建新的架构。在该示例中,我们将创建一个空白 API 以及空白架构。
- Console
-
-
登录 AWS 管理控制台 并打开AppSync控制台。
-
在控制面板中,选择创建 API。
-
在 API 选项下,选择 GraphQL APIs、从头开始设计,然后选择 “下一步”。
-
对于 API 名称,将预填充的名称更改为您的应用程序所需的名称。
-
对于联系信息,您可以输入联系人以指定 API 的管理员。此为可选字段。
-
在私有 API 配置下面,您可以启用私有 API 功能。只能从配置的 VPC 终端节点 (VPCE) 中访问私有 API。有关更多信息,请参阅私有 APIs。
对于该示例,我们不建议启用该功能。在检查您的输入后,选择下一步。
-
在创建 GraphQL 类型下面,您可以选择创建 DynamoDB 表以用作数据来源,或者跳过该步骤并稍后执行。
对于该示例,请选择稍后创建 GraphQL 资源。我们将在单独的章节中创建资源。
-
检查您的输入,然后选择创建 API。
-
将进入您的特定 API 的控制面板。由于该 API 的名称位于控制面板顶部,因此,您可以看出这一点。如果不是这样,你可以在侧栏APIs中选择,然后在APIs 控制面板中选择你的 API。
-
在侧边栏中,在您的 API 名称下面选择架构。
-
在架构编辑器中,您可以配置您的 schema.graphql 文件。它可能是空的,也可能填充了通过模型生成的类型。右侧是解析器部分,用于将解析器附加到您的架构字段。我们不会在本节中介绍解析器内容。
- CLI
-
在使用 CLI 时,请确保您具有正确权限以在该服务中访问和创建资源。您可能希望为需要访问该服务的非管理员用户设置最低权限策略。有关 AWS AppSync 策略的更多信息,请参阅的身份和访问管理 AWS AppSync。
此外,如果您还没有查看控制台版本,我们建议您先查看该版本。
-
如果您尚未安装 AWS
CLI 并添加您的配置,请执行该操作。
-
运行 create-graphql-api 命令以创建 GraphQL API 对象。
您需要为该特定命令键入两个参数:
-
您的 API 的 name。
-
authentication-type 或用于访问该 API 的凭证类型(IAM、OIDC 等)。
必须配置其他参数(例如 Region),但这些参数通常默认为您的 CLI 配置值。
示例命令可能如下所示:
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
将在 CLI 中返回输出。示例如下:
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
这是一个可选命令,它采用现有的架构并使用 Base64 Blob 将其上传到 AWS AppSync 服务中。对于该示例,我们不会使用该命令。
运行 start-schema-creation 命令。
您需要为该特定命令键入两个参数:
-
上一步中的 api-id。
-
架构 definition 是一个 Base64 编码的二进制 Blob。
示例命令可能如下所示:
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
将返回输出:
{
"status": "PROCESSING"
}
该命令不会在处理后返回最终输出。您必须使用单独的命令 (get-schema-creation-status) 查看结果。请注意,这两个命令是异步的,因此,即使仍在创建架构,您也可以检查输出状态。
- CDK
-
在使用 CDK 之前,我们建议您查看 CDK 的官方文档以及 CD K 参考资料。 AWS AppSync
下面列出的步骤仅显示用于添加特定资源的一般代码片段示例。这并不意味着,它是您的生产代码中的有效解决方案。我们还假设您已具有正常工作的应用程序。
-
CDK 的起点有所不同。理想情况下,应该已创建了您的 schema.graphql 文件。您只需创建一个具有 .graphql 文件扩展名的新文件。它可以是空文件。
-
一般来说,您可能需要将 import 指令添加到您使用的服务中。例如,它可能采用以下形式:
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
要添加 GraphQL API,您的堆栈文件需要导入 AWS AppSync 服务:
import * as appsync from 'aws-cdk-lib/aws-appsync';
这意味着我们使用 appsync 关键字导入整个服务。要在您的应用程序中使用它,您的 AWS AppSync 构造将使用以下格式appsync.construct_name。例如,如果我们要创建 GraphQL API,我们将使用 new appsync.GraphqlApi(args_go_here)。以下步骤介绍了这一点。
-
最基本的 GraphQL API 将包括 API 的 name 和 schema 路径。
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
让我们回顾一下该代码片段执行的操作。在 api 范围内,我们调用 appsync.GraphqlApi(scope: Construct, id:
string, props: GraphqlApiProps) 以创建一个新的 GraphQL API。范围是 this,它指的是当前对象。ID 是API_ID,这将是你的 GraphQL API 在创建 CloudFormation 时使用的资源名称。GraphqlApiProps 包含 GraphQL API 的 name 和 schema。schema将通过在绝对路径 (SchemaFile.fromAsset) 中搜索.graphql文件 (__dirname) 来生成架构 (schema_name.graphql)。在实际场景中,您的架构文件可能位于 CDK 应用程序内。
要使用对 GraphQL API 所做的更改,您必须重新部署该应用程序。
在架构中添加类型
现已添加了架构,您可以开始添加输入和输出类型。请注意,不应在实际代码中使用此处的类型;它们只是帮助您理解该过程的示例。
首先,我们创建一个对象类型。在实际代码中,您不必从这些类型开始。只要遵循 GraphQL 的规则和语法,您可以随时创建所需的任何类型。
接下来的几节将使用架构编辑器,因此,请将其保持打开状态。
- Console
-
-
您可以使用 type 关键字和类型名称以创建对象类型:
type Type_Name_Goes_Here {}
在类型的范围内,您可以添加表示对象特性的字段:
type Type_Name_Goes_Here {
# Add fields here
}
示例如下:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
在该骤中,我们添加了一个通用对象类型,将 id 必填字段存储为 ID,将 title 字段存储为 String,并将 date 字段存储为 AWSDateTime。要查看类型和字段列表及其用途,请参阅架构。要查看标量列表及其用途,请参阅类型参考。
- CLI
-
如果您还没有查看控制台版本,我们建议您先查看该版本。
-
您可以运行 create-type 命令以创建对象类型。
您需要为该特定命令输入一些参数:
-
您的 API 的 api-id。
-
definition 或您的类型内容。在控制台示例中,这是:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
您的输入的 format。在该示例中,我们使用 SDL。
示例命令可能如下所示:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
将在 CLI 中返回输出。示例如下:
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
在该骤中,我们添加了一个通用对象类型,将 id 必填字段存储为 ID,将 title 字段存储为 String,并将 date 字段存储为 AWSDateTime。要查看类型和字段列表及其用途,请参阅架构。要查看标量列表及其用途,请参阅类型参考。
此外,您可能已意识到,直接输入定义适用于较小的类型,但对于添加较大类型或多个类型是不可行的。您可以选择将所有内容添加到 .graphql 文件中,然后将其作为输入传递。
- CDK
-
在使用 CDK 之前,我们建议您查看 CDK 的官方文档以及 CD K 参考资料。 AWS AppSync
下面列出的步骤仅显示用于添加特定资源的一般代码片段示例。这并不意味着,它是您的生产代码中的有效解决方案。我们还假设您已具有正常工作的应用程序。
要添加类型,您需要将其添加到您的 .graphql 文件中。例如,控制台示例是:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
您可以像任何其他文件一样将类型直接添加到架构中。
要使用对 GraphQL API 所做的更改,您必须重新部署该应用程序。
对象类型具有标量类型的字段,例如字符串和整数。 AWS AppSync 除基本的 GraphQL 标量外,还允许您使用增强的标量类型。AWSDateTime此外,任何以感叹号结尾的字段都是必填字段。
特别是,ID 标量类型是唯一标识符,可以是 String 或 Int。您可以在解析器代码中控制这些内容以自动进行分配。
特殊对象类型(如 Query)和“常规”对象类型(如上面的示例)之间存在相似之处,因为它们都使用 type 关键字并被视为对象。不过,对于特殊对象类型(Query、Mutation 和 Subscription),它们的行为有很大不同,因为它们是作为 API 的入口点公开的。它们更多地涉及设置形状操作而不是数据。有关更多信息,请参阅查询和变更类型。
对于特殊对象类型主题,下一步可能是添加一个或多个对象类型以对设置形状的数据执行操作。在实际场景中,每个 GraphQL 架构必须至少具有一个根查询类型以请求数据。您可以将查询视为 GraphQL 服务器的入口点(或终端节点)之一。让我们添加一个查询以作为示例。
- Console
-
-
要创建查询,您只需将其添加到架构文件中,就像任何其他类型一样。查询需要具有 Query 类型并在根中具有一个条目,如下所示:
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
请注意,Name_of_Query在生产环境中,大多数Query情况下只会被调用。我们建议保留该值。在查询类型中,您可以添加字段。每个字段都会在请求中执行一个操作。因此,大多数(即使不是全部)字段将附加到一个解析器。不过,我们在本节中并不关注这个问题。对于字段操作格式,它可能如下所示:
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
示例如下:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
在该步骤中,我们添加了一个 Query 类型,并在 schema 根中定义该类型。我们的 Query 类型定义了一个 getObj 字段,该字段返回 Obj_Type_1 对象列表。请注意,Obj_Type_1 是上一步中的对象。在生产代码中,您的字段操作通常处理由 Obj_Type_1 等对象设置形状的数据。此外,getObj 等字段通常具有一个解析器以执行业务逻辑。将在另一节中介绍该内容。
另外,在导出过程中 AWS AppSync 会自动添加架构根,因此从技术上讲,您不必将其直接添加到架构中。我们的服务自动处理重复的架构。我们在此处添加架构根以作为最佳实践。
- CLI
-
如果您还没有查看控制台版本,我们建议您先查看该版本。
-
运行 create-type 命令以创建一个具有 query 定义的 schema 根。
您需要为该特定命令输入一些参数:
-
您的 API 的 api-id。
-
definition 或您的类型内容。在控制台示例中,这是:
schema {
query: Query
}
-
您的输入的 format。在该示例中,我们使用 SDL。
示例命令可能如下所示:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
将在 CLI 中返回输出。示例如下:
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
请注意,如果您在 create-type 命令中未正确输入某些内容,您可以运行 update-type 命令以更新您的架构根(或架构中的任何类型)。在该示例中,我们暂时更改架构根以包含 subscription 定义。
您需要为该特定命令输入一些参数:
-
您的 API 的 api-id。
-
您的类型的 type-name。在控制台示例中,这是 schema。
-
definition 或您的类型内容。在控制台示例中,这是:
schema {
query: Query
}
添加 subscription 后的架构如下所示:
schema {
query: Query
subscription: Subscription
}
-
您的输入的 format。在该示例中,我们使用 SDL。
示例命令可能如下所示:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
将在 CLI 中返回输出。示例如下:
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
在该示例中,添加预设置格式的文件仍然有效。
-
运行 create-type 命令以创建一个 Query 类型。
您需要为该特定命令输入一些参数:
-
您的 API 的 api-id。
-
definition 或您的类型内容。在控制台示例中,这是:
type Query {
getObj: [Obj_Type_1]
}
-
您的输入的 format。在该示例中,我们使用 SDL。
示例命令可能如下所示:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
将在 CLI 中返回输出。示例如下:
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
在该步骤中,我们添加了一个 Query 类型,并在 schema 根中定义该类型。我们的 Query 类型定义了一个 getObj 字段,该字段返回 Obj_Type_1 对象列表。
在 schema 根代码 query: Query 中,query: 部分指示在您的架构中定义了一个查询,而 Query 部分指示实际的特殊对象名称。
- CDK
-
在使用 CDK 之前,我们建议您查看 CDK 的官方文档以及 CD K 参考资料。 AWS AppSync
下面列出的步骤仅显示用于添加特定资源的一般代码片段示例。这并不意味着,它是您的生产代码中的有效解决方案。我们还假设您已具有正常工作的应用程序。
您需要将查询和架构根添加到 .graphql 文件中。我们的示例与以下示例类似,但您希望将其替换为实际的架构代码:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
您可以像任何其他文件一样将类型直接添加到架构中。
更新架构根是可选的。我们在该示例中添加架构根以作为最佳实践。
要使用对 GraphQL API 所做的更改,您必须重新部署该应用程序。
您现已看到创建对象和特殊对象(查询)的示例。您还了解了这些对象如何相互关联以描述数据和操作。您可以具有仅包含数据描述以及一个或多个查询的架构。不过,我们希望添加另一个操作以将数据添加到数据来源中。我们将添加另一个名为 Mutation 的特殊对象类型以修改数据。
- Console
-
-
一个变更命名为 Mutation。与 Query 一样,Mutation 中的字段操作描述一个操作并附加到一个解析器。另请注意,我们需要在 schema 根中定义该变更,因为它是一个特殊对象类型。下面是一个变更示例:
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
像查询一样,将在根中列出典型的变更。变异是使用type关键字和名称定义的。 Name_of_Mutation通常会被调用Mutation,所以我们建议保持这种状态。每个字段还会执行一个操作。对于字段操作格式,它可能如下所示:
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
示例如下:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
在该步骤中,我们添加了一个具有 addObj 字段的 Mutation 类型。让我们简要说明一下该字段的用途:
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
addObj 使用 Obj_Type_1 对象以执行操作。由于这些字段,这是显而易见的,但语法在 : Obj_Type_1 返回类型中证实了这一点。在 addObj 中,它接受 Obj_Type_1 对象中的 id、title 和 date 字段以作为参数。正如您看到的一样,它看起来很像方法声明。不过,我们还没有介绍我们的方法的行为。正如前面所述,架构仅用于定义数据和操作是什么,而不定义它们的工作方式。在我们稍后创建第一个解析器时,将实施实际的业务逻辑。
在完成架构后,可以选择将其导出为 schema.graphql 文件。在架构编辑器中,您可以选择导出架构以使用支持的格式下载该文件。
另外,在导出过程中 AWS AppSync 会自动添加架构根,因此从技术上讲,您不必将其直接添加到架构中。我们的服务自动处理重复的架构。我们在此处添加架构根以作为最佳实践。
- CLI
-
如果您还没有查看控制台版本,我们建议您先查看该版本。
-
运行 update-type 命令以更新您的根架构。
您需要为该特定命令输入一些参数:
-
您的 API 的 api-id。
-
您的类型的 type-name。在控制台示例中,这是 schema。
-
definition 或您的类型内容。在控制台示例中,这是:
schema {
query: Query
mutation: Mutation
}
-
您的输入的 format。在该示例中,我们使用 SDL。
示例命令可能如下所示:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
将在 CLI 中返回输出。示例如下:
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
运行 create-type 命令以创建一个 Mutation 类型。
您需要为该特定命令输入一些参数:
-
您的 API 的 api-id。
-
definition 或您的类型内容。在控制台示例中,这是:
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
您的输入的 format。在该示例中,我们使用 SDL。
示例命令可能如下所示:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
将在 CLI 中返回输出。示例如下:
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
在使用 CDK 之前,我们建议您查看 CDK 的官方文档以及 CD K 参考资料。 AWS AppSync
下面列出的步骤仅显示用于添加特定资源的一般代码片段示例。这并不意味着,它是您的生产代码中的有效解决方案。我们还假设您已具有正常工作的应用程序。
您需要将查询和架构根添加到 .graphql 文件中。我们的示例与以下示例类似,但您希望将其替换为实际的架构代码:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
更新架构根是可选的。我们在该示例中添加架构根以作为最佳实践。
要使用对 GraphQL API 所做的更改,您必须重新部署该应用程序。
可选注意事项 - 将枚举作为状态
至此,您知道如何创建基本架构了。不过,您可以添加很多内容以增加架构的功能。在应用程序中,一种常见情况是将枚举作为状态。您可以使用枚举在调用时强制从一组值中选择一个特定的值。对于您知道在很长一段时间内不会发生显著变化的内容,这是非常有用的。假设来说,我们可以添加一个枚举以在响应中返回状态代码或字符串。
例如,假设我们创建一个社交媒体应用程序,该应用程序在后端存储用户的文章数据。我们的架构包含一个 Post 类型,它表示一篇文章的数据:
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
我们的 Post 将包含唯一的 id、文章 title、发布 date 以及名为 PostStatus 的枚举,它表示应用程序处理时的文章状态。对于我们的操作,我们使用一个查询以返回所有文章数据:
type Query {
getPosts: [Post]
}
我们还使用一个变更以将文章添加到数据来源中:
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
看一下我们的架构,PostStatus 枚举可能具有多种状态。我们可能需要三种基本状态,分别命名为 success(已成功处理文章)、pending(正在处理文章)和 error(无法处理文章)。要添加枚举,我们可以编写以下代码:
enum PostStatus {
success
pending
error
}
完整架构可能如下所示:
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
如果用户在应用程序中添加 Post,将调用 addPost 操作以处理该数据。在附加到 addPost 的解析器处理数据时,它不断使用操作状态更新 poststatus。在查询时,Post 将包含数据的最终状态。请记住,我们只是介绍我们希望如何在架构中处理数据。我们对解析器实施进行了很多假设,这些解析器实施处理数据以完成请求的实际业务逻辑。
可选注意事项 - 订阅
中的订阅 AWS AppSync 是作为对突变的响应而调用的。您可使用架构中的Subscription 类型和 @aws_subscribe() 指令进行配置,以指定哪些变更会调用一个或多个订阅。有关配置订阅的更多信息,请参阅实时数据。
可选的注意事项 - 关系和分页
假设您在 DynamoDB 表中存储了一百万个 Posts,并且您希望返回其中的一些数据。不过,上面给出的示例查询仅返回所有文章。您不希望每次发出请求时获取所有这些文章。相反,您可能希望对它们进行分页。请对您的架构进行以下改动:
-
在 getPosts 字段中,添加两个输入参数:nextToken(迭代器)和 limit(迭代限制)。
-
添加一个新的 PostIterator 类型,其中包含 Posts(检索 Post 对象列表)和 nextToken(迭代器)字段。
-
更改 getPosts 以使其返回 PostIterator,而不是 Post 对象列表。
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
PostIterator 类型允许您返回 Post 对象列表的一部分,以及用于获取下一部分的 nextToken。在 PostIterator 中,具有一个 Post 项目 ([Post]) 列表,该列表与分页标记 (nextToken) 一起返回。在中 AWS AppSync,它将通过解析器连接到 Amazon DynamoDB,并自动生成为加密令牌。它会将 limit 参数的值转换为 maxResults 参数;并将 nextToken 参数转换为 exclusiveStartKey 参数。有关 AWS AppSync 控制台中的示例和内置模板示例,请参阅 Resolver 参考 (JavaScript)。