Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utiliser des étapes de traitement de fichiers personnalisées
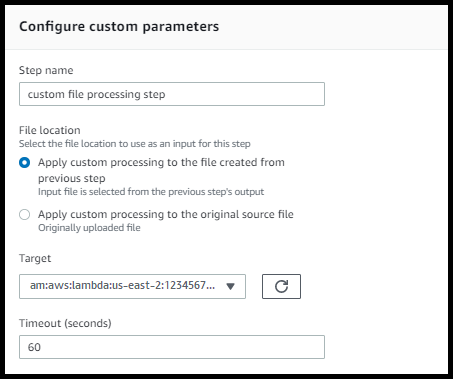
En utilisant une étape de traitement de fichiers personnalisée, vous pouvez apporter votre propre logique de traitement de fichiers en utilisant. AWS LambdaÀ l'arrivée du fichier, un serveur Transfer Family invoque une fonction Lambda qui contient une logique de traitement de fichiers personnalisée, telle que le chiffrement de fichiers, la recherche de logiciels malveillants ou la recherche de types de fichiers incorrects. Dans l'exemple suivant, la AWS Lambda fonction cible est utilisée pour traiter le fichier de sortie de l'étape précédente.
Note
Pour obtenir un exemple de fonction Lambda, consultez Exemple de fonction Lambda pour une étape de flux de travail personnalisée. Pour des exemples d'événements (y compris l'emplacement des fichiers transmis au Lambda), voir. Exemples d'événements envoyés à une adresse AWS Lambda lors du chargement d'un fichier
Avec une étape de flux de travail personnalisée, vous devez configurer la fonction Lambda pour appeler l'opération d'SendWorkflowStepStateAPI. SendWorkflowStepStateindique à l'exécution du flux de travail que l'étape s'est terminée avec un statut de réussite ou d'échec. L'état de l'opération d'SendWorkflowStepStateAPI appelle une étape du gestionnaire d'exceptions ou une étape nominale dans la séquence linéaire, en fonction du résultat de la fonction Lambda.
Si la fonction Lambda échoue ou expire, l'étape échoue et cela apparaît StepErrored dans vos CloudWatch journaux. Si la fonction Lambda fait partie de l'étape nominale et que la fonction répond SendWorkflowStepState avec Status="FAILURE" ou expire, le flux continue avec les étapes du gestionnaire d'exceptions. Dans ce cas, le flux de travail ne continue pas à exécuter les étapes nominales restantes (le cas échéant). Pour en savoir plus, consultez Gestion des exceptions pour un flux de travail.
Lorsque vous appelez l'opération SendWorkflowStepState API, vous devez envoyer les paramètres suivants :
{ "ExecutionId": "string", "Status": "string", "Token": "string", "WorkflowId": "string" }
Vous pouvez extraire le ExecutionIdToken, et WorkflowId de l'événement d'entrée transmis lors de l'exécution de la fonction Lambda (des exemples sont présentés dans les sections suivantes). La Status valeur peut être SUCCESS soitFAILURE.
Pour pouvoir appeler l'opération d'SendWorkflowStepStateAPI depuis votre fonction Lambda, vous devez utiliser une version du AWS SDK publiée après l'introduction de Managed Workflows.
Utilisation consécutive de plusieurs fonctions Lambda
Lorsque vous utilisez plusieurs étapes personnalisées l'une après l'autre, l'option Emplacement du fichier fonctionne différemment que si vous n'utilisez qu'une seule étape personnalisée. Transfer Family ne prend pas en charge le Lambda-processed renvoi du fichier pour l'utiliser comme entrée de l'étape suivante. Ainsi, si plusieurs étapes personnalisées sont toutes configurées pour utiliser l'previous.fileoption, elles utilisent toutes le même emplacement de fichier (l'emplacement du fichier d'entrée pour la première étape personnalisée).
Note
Le previous.file paramètre fonctionne également différemment si vous avez une étape prédéfinie (marquer, copier, déchiffrer ou supprimer) après une étape personnalisée. Si l'étape prédéfinie est configurée pour utiliser le previous.file paramètre, elle utilise le même fichier d'entrée que celui utilisé par l'étape personnalisée. Le fichier traité à partir de l'étape personnalisée n'est pas transmis à l'étape prédéfinie.
Accès à un fichier après un traitement personnalisé
Si vous utilisez Amazon S3 comme espace de stockage, et si votre flux de travail inclut une étape personnalisée qui exécute des actions sur le fichier initialement chargé, les étapes suivantes ne peuvent pas accéder à ce fichier traité. En d'autres termes, aucune étape postérieure à l'étape personnalisée ne peut faire référence au fichier mis à jour à partir de la sortie de l'étape personnalisée.
Supposons, par exemple, que votre flux de travail comporte les trois étapes suivantes.
-
Étape 1 — Téléchargez un fichier nommé
example-file.txt. -
Étape 2 — Invoquez une fonction Lambda qui change d'une manière ou d'une
example-file.txtautre. -
Étape 3 — Essayez d'effectuer un traitement supplémentaire sur la version mise à jour de
example-file.txt.
Si vous configurez l'sourceFileLocationétape 3${original.file}, l'étape 3 utilise l'emplacement du fichier d'origine à partir du moment où le serveur a chargé le fichier vers le stockage à l'étape 1. Si vous utilisez ${previous.file} pour l'étape 3, l'étape 3 réutilise l'emplacement du fichier que l'étape 2 a utilisé comme entrée.
Par conséquent, l'étape 3 provoque une erreur. Par exemple, si l'étape 3 tente de copier la mise à jourexample-file.txt, le message d'erreur suivant s'affiche :
{ "type": "StepErrored", "details": { "errorType": "NOT_FOUND", "errorMessage": "ETag constraint not met (Service: null; Status Code: 412; Error Code: null; Request ID: null; S3 Extended Request ID: null; Proxy: null)", "stepType": "COPY", "stepName": "CopyFile" },
Cette erreur se produit car l'étape personnalisée modifie la balise d'entité (ETag) pour example-file.txt qu'elle ne corresponde pas au fichier d'origine.
Note
Ce comportement ne se produit pas si vous utilisez Amazon EFS, car Amazon EFS n'utilise pas de balises d'entité pour identifier les fichiers.
Exemples d'événements envoyés à une adresse AWS Lambda lors du chargement d'un fichier
Les exemples suivants montrent les événements qui sont envoyés AWS Lambda lorsque le téléchargement d'un fichier est terminé. Un exemple utilise un serveur Transfer Family où le domaine est configuré avec Amazon S3. L'autre exemple utilise un serveur Transfer Family où le domaine utilise Amazon EFS.
Exemple de fonction Lambda pour une étape de flux de travail personnalisée
La fonction Lambda suivante extrait les informations concernant l'état d'exécution, puis appelle l'opération d'SendWorkflowStepStateAPI pour renvoyer le statut au flux de travail de l'étapeSUCCESS, soit. FAILURE Avant que votre fonction n'appelle l'opération SendWorkflowStepState API, vous pouvez configurer Lambda pour qu'il exécute une action en fonction de votre logique de flux de travail.
import json import boto3 transfer = boto3.client('transfer') def lambda_handler(event, context): print(json.dumps(event)) # call the SendWorkflowStepState API to notify the workflow about the step's SUCCESS or FAILURE status response = transfer.send_workflow_step_state( WorkflowId=event['serviceMetadata']['executionDetails']['workflowId'], ExecutionId=event['serviceMetadata']['executionDetails']['executionId'], Token=event['token'], Status='SUCCESS|FAILURE' ) print(json.dumps(response)) return { 'statusCode': 200, 'body': json.dumps(response) }
Autorisations IAM pour une étape personnalisée
Pour permettre à une étape qui appelle un Lambda de réussir, assurez-vous que le rôle d'exécution de votre flux de travail contient les autorisations suivantes.
{ "Sid": "Custom", "Effect": "Allow", "Action": [ "lambda:InvokeFunction" ], "Resource": [ "arn:aws:lambda:region:account-id:function:function-name" ] }
