翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS DeepRacer での強化学習
強化学習では、エージェント物理または仮想の AWS DeepRacer 車両など、意図したといった、意思をもって目標を達成するためのという目的を持つことは、環境エージェントは、環境と通信してエージェントの総報酬を最大化します。エージェントは、一定の環境 状態 において ポリシー と呼ばれる 戦略が導いたアクション を行い、新しい状態に達します。あらゆるアクションに対して、報酬が即座に関連付けられます。報酬は、アクションの優先度を決定するメジャーです。この即時報酬は、環境により返されるとみなされます。
AWS DeepRacer の強化学習の目的は、所定の環境における最適なポリシーを学習することです。学習とは、試行錯誤を繰り返すプロセスです。エージェントは初期アクションをランダムに実行して、新しい状態に到達します。その後、エージェントは新しい状態からその次の状態に、ステップを繰り返します。そのうち、エージェントは最大の長期報酬につながるアクションを発見します。初期状態から最終状態までのエージェントのやりとりは、エピソードと呼ばれます。
次のスケッチはこの学習プロセスを示しています。
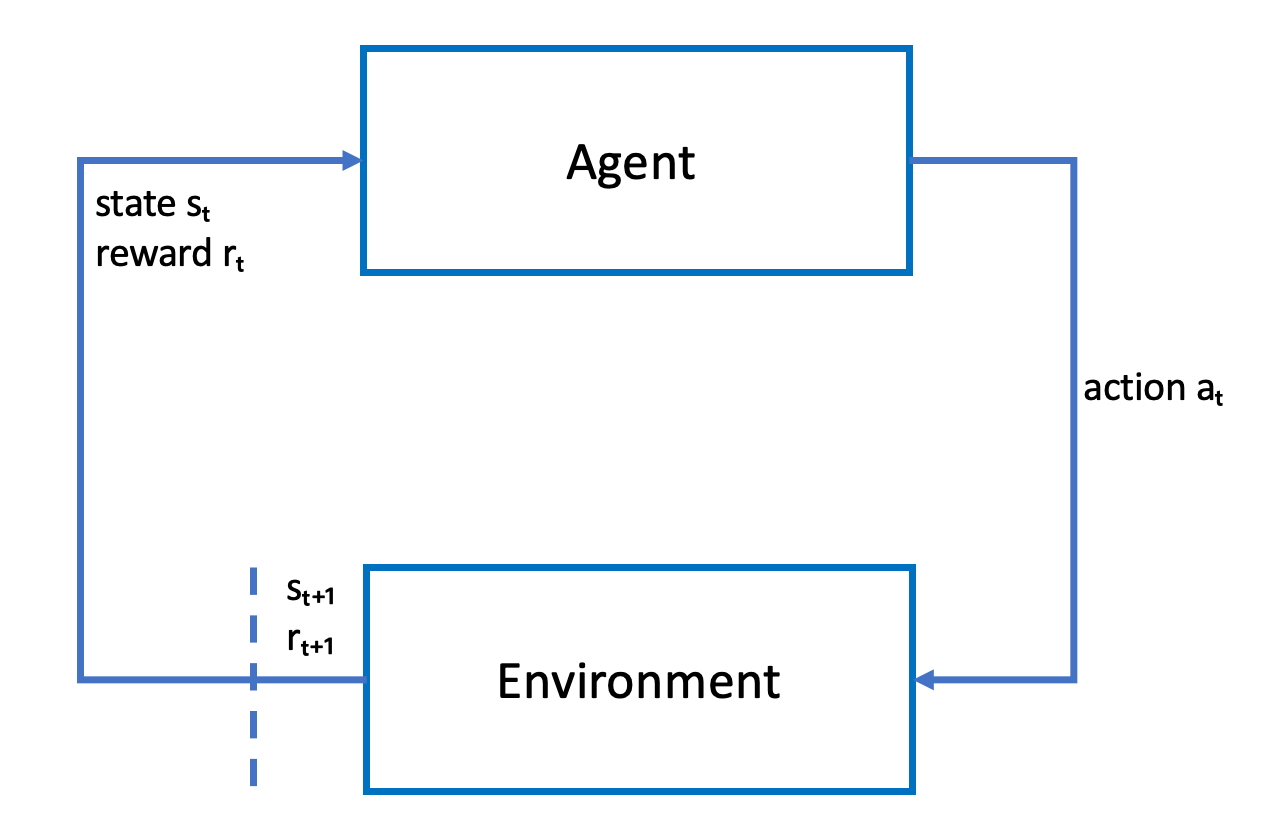
エージェントは、エージェントのポリシーを概算する関数を表すニューラルネットワークを具体化します。車両に搭載されたフロントカメラからの映像は環境の状態で、エージェントのアクションはエージェントの速度とステアリング角度で定義されます。
エージェントがトラック上を走行したままレースを終えると、エージェントは正の報酬を受け取り、トラックを外れると負の報酬を受け取ります。エピソードは、レーストラックのどこかでエージェントとともに開始し、エージェントが脱線するかラップを完走すると、終了します。
注記
厳密に言うと、環境の状態は問題に関係するすべてを指します。たとえば、トラック上の車両の位置とトラックの形状などです。車両のフロントに搭載されたカメラから供給さる画像では、環境状態のすべてはキャプチャされません。このため、環境は部分的に観察されているとみなされ、エージェントへのインプットは状態ではなく観測と呼ばれます。分かりやすいように、このドキュメントでは、状態と観測を同じ意味として使用します。
シミュレーションされた環境でエージェントをトレーニングすることには、次の利点があります。
-
シミュレーションにより、エージェントがどの程度進歩を遂げたかを推定し、トラックから外れたタイミングを特定して、報酬を計算できます。
-
シミュレーションにより、トレーナーは、物理環境のようにトラックから外れるたびに車両をリセットする、面倒な雑用から解放されます。
-
シミュレーションはトレーニングを高速化できます。
-
シミュレーションにより、たとえば、異なるトラック、背景、車両条件を選択するなど、環境の条件をより詳細に管理できます。
強化学習の代替は教師あり学習です。これは模倣学習とも呼ばれます。所定の環境から収集された ([image, action] タプルの) 既知のデータセットがあり、エージェントのトレーニングに使用されます。模倣学習を通して訓練されたモデルは、自動運転に適用することができます。カメラからの画像がトレーニングデータセットの画像と似ている場合にのみ効果があります。堅牢な走行には、トレーニングデータセットが包括的である必要があります。対照的に、強化学習はこのような大規模なラベリング作業を必要とせず、完全にシミュレーションで訓練することができます。強化学習はランダムなアクションで始まるため、エージェントは幅広い環境とトラック条件を学習します。このため、トレーニングしたモデルが堅牢になります。
