サポート終了通知: 2026 年 10 月 7 日、AWSはサポートを終了しますAWS IoT Greengrass Version 1。2026 年 10 月 7 日以降、AWS IoT Greengrass V1リソースにアクセスできなくなります。詳細については、「 からの移行AWS IoT Greengrass Version 1」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
機械学習の推論を実行する
この機能は AWS IoT Greengrass Core v1.6 以降で使用できます。
を使用すると AWS IoT Greengrass、クラウドでトレーニングされたモデルを使用して、ローカルに生成されたデータのエッジで機械学習 (ML) 推論を実行できます。ローカル推論の実行により低レイテンシーとコスト節約のメリットを得ながら、モデルのトレーニングと複雑な処理にクラウドコンピューティングの処理能力を活用できます。
ローカル推論の実行を開始するには、「を使用して機械学習推論を設定する方法 AWS マネジメントコンソール」を参照してください。
ML AWS IoT Greengrass 推論の仕組み
推論モデルは、任意の場所でトレーニングし、Greengrass グループに機械学習リソースとしてローカルにデプロイした後、Greengrass Lambda 関数からアクセスできるようになります。たとえば、SageMaker AI
次の図は、ML AWS IoT Greengrass 推論ワークフローを示しています。
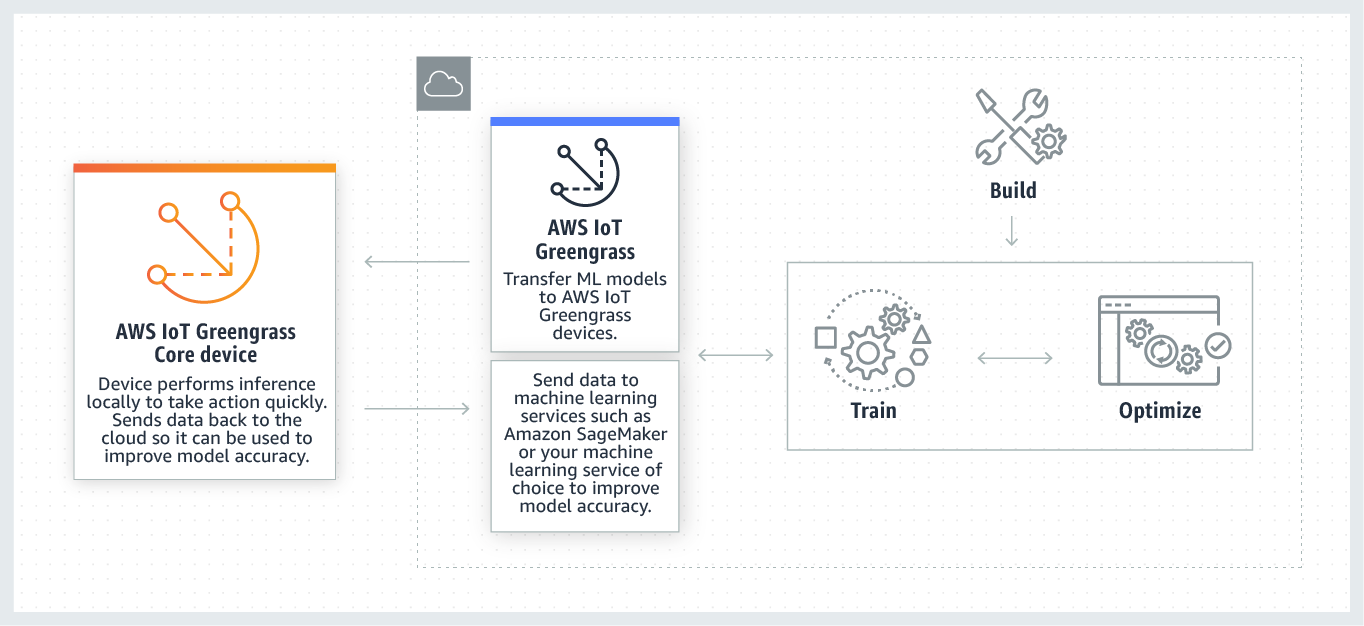
AWS IoT Greengrass ML 推論は、以下を含む ML ワークフローの各ステップを簡素化します。
-
ML フレームワークのプロトタイプを構築し、デプロイする。
-
クラウドトレーニング済みモデルにアクセスし、それらのモデルを Greengrass コアデバイスにデプロイする。
-
ローカルリソースであるハードウェアアクセラレーター (GPU や FPGA など) にアクセスできる推論アプリケーションを作成する。
機械学習リソース
機械学習リソースは、 AWS IoT Greengrass コアにデプロイされるクラウドトレーニングされた推論モデルを表します。機械学習リソースをデプロイするには、まず Greengrass グループに追加し、グループ内の Lambda 関数がそれらのリソースにアクセスできる方法を定義します。グループのデプロイ中、 はクラウドからソースモデルパッケージ AWS IoT Greengrass を取得し、Lambda ランタイム名前空間内のディレクトリに抽出します。その後、Greengrass Lambda 関数によって、ローカルにデプロイしたモデルを使用して推論が実行されるようになります。
ローカルにデプロイしたモデルを更新するには、まず機械学習リソースに対応するソースモデル (クラウド内) を更新してから、そのグループをデプロイします。デプロイ中、 AWS IoT Greengrass によってソースの変更が確認されます。変更が検出されると、 はローカルモデル AWS IoT Greengrass を更新します。
サポートされているモデルソース
AWS IoT Greengrass は、機械学習リソースの SageMaker AI および Amazon S3 モデルソースをサポートしています。
モデルソースには、以下の要件が適用されます。
-
SageMaker AI および Amazon S3 モデルソースを保存する S3 バケットは、SSE-C を使用して暗号化しないでください。 Amazon S3 サーバー側の暗号化を使用するバケットの場合、 AWS IoT Greengrass ML 推論は現在 SSE-S3 または SSE-KMS 暗号化オプションのみをサポートしています。サーバー側の暗号化の詳細については、「Amazon Simple Storage Service ユーザーガイド」の「サーバー側の暗号化を使用したデータ保護」を参照してください。
-
SageMaker AI および Amazon S3 モデルソースを保存する S3 バケットの名前にピリオド () を含めることはできません
.。 SageMaker 詳細については、「Amazon Simple Storage Service ユーザーガイド」のバケット命名規則で、SSL で仮想ホスト型バケットの使用に関するルールを参照してください。 -
サービスレベルの AWS リージョン サポートは、 AWS IoT Greengrassと SageMaker AI の両方で利用できる必要があります。現在、 AWS IoT Greengrass は次のリージョンで SageMaker AI モデルをサポートしています。
-
米国東部(オハイオ)
-
米国東部 (バージニア北部)
-
米国西部 (オレゴン)
-
アジアパシフィック (ムンバイ)
-
アジアパシフィック (ソウル)
-
アジアパシフィック (シンガポール)
-
アジアパシフィック (シドニー)
-
アジアパシフィック (東京)
-
欧州 (フランクフルト)
-
欧州 (アイルランド)
-
欧州 (ロンドン)
-
-
AWS IoT Greengrass 次のセクションで説明するように、 にはモデルソースに対する
readアクセス許可が必要です。
- SageMaker AI
-
AWS IoT Greengrass は、SageMaker AI トレーニングジョブとして保存されるモデルをサポートします。SageMaker AI は、組み込みアルゴリズムまたはカスタムアルゴリズムを使用してモデルを構築およびトレーニングするために使用できるフルマネージド ML サービスです。詳細については、SageMaker AI とは」を参照してください。 SageMaker AI デベロッパーガイド」の「」を参照してください。
という名前のバケットを作成して SageMaker AI 環境を設定した場合
sagemaker、 AWS IoT Greengrass には SageMaker AI トレーニングジョブにアクセスするための十分なアクセス許可があります。AWSGreengrassResourceAccessRolePolicy管理ポリシーは、名前に文字列sagemakerが含まれるバケットへのアクセスを許可します。このポリシーは Greengrass サービスのロールにアタッチされます。それ以外の場合は、トレーニングジョブが保存されているバケットにアクセス許可を付与 AWS IoT Greengrass
readする必要があります。そのためには、サービスロールに以下のインラインポリシーを埋め込みます。複数のバケット ARN を含めることができます。 - Amazon S3
-
AWS IoT Greengrass は、Amazon S3 に
tar.gzまたは.zipファイルとして保存されているモデルをサポートします。AWS IoT Greengrass が Amazon S3 バケットに保存されているモデルにアクセスできるようにするには、次のいずれかを実行してバケットにアクセスするためのアクセス AWS IoT Greengrass
read許可を付与する必要があります。-
名前に
greengrassが含まれるバケットにモデルを保存します。AWSGreengrassResourceAccessRolePolicy管理ポリシーは、名前に文字列greengrassが含まれるバケットへのアクセスを許可します。このポリシーは Greengrass サービスのロールにアタッチされます。 -
Greengrass サービスロールにインラインポリシーを埋め込みます。
バケット名に
greengrassが含まれない場合は、サービスロールに以下のインラインポリシーを追加します。複数のバケット ARN を含めることができます。詳細については、「IAM ユーザーガイド」の「インラインポリシーの埋め込み」を参照してください。
-
要件
機械学習リソースの作成と使用には、以下の要件が適用されます。
-
AWS IoT Greengrass Core v1.6 以降を使用している必要があります。
-
ユーザー定義 Lambda 関数は、リソースに対して
readまたはread and writeオペレーションを実行できます。他のオペレーションに対するアクセス許可はありません。関連する Lambda 関数のコンテナ化モードによって、アクセス権限の設定方法が決まります。詳細については、「Lambda 関数から機械学習リソースにアクセスする」を参照してください。 -
コアデバイスのオペレーティングシステム上のリソースの完全パスを指定することが必要です。
-
リソース名または ID の最大長は 128 文字で、パターン
[a-zA-Z0-9:_-]+を使用する必要があります。
ML 推論用のランタイムとライブラリ
では、次の ML ランタイムとライブラリを使用できます AWS IoT Greengrass。
-
Apache MXNet
-
TensorFlow
これらのランタイムとライブラリは、NVIDIA Jetson TX2、Intel Atom、および Raspberry Pi プラットフォームにインストールできます。ダウンロード情報については、「サポートされている機械学習ランタイムおよびライブラリ」を参照してください。コアデバイスに直接インストールできます。
互換性と制限については、必ず以下の情報を参照してください。
SageMaker AI Neo 深層学習ランタイム
SageMaker AI Neo 深層学習ランタイムを使用して、 AWS IoT Greengrass デバイスで最適化された機械学習モデルで推論を実行できます。これらのモデルは、機械学習推論の予測速度を向上させるために SageMaker AI Neo 深層学習コンパイラを使用して最適化されています。SageMaker AI でのモデル最適化の詳細については、SageMaker AI Neo ドキュメントを参照してください。
注記
現在、特定のアマゾン ウェブ サービスリージョンでのみ Neo 深層学習コンパイラを使用して機械学習モデルを最適化できます。ただし、 AWS リージョン AWS IoT Greengrass コアがサポートされている各 で最適化されたモデルで Neo 深層学習ランタイムを使用できます。詳細については、「最適化された機械学習推論を設定する方法」を参照してください。
MXNet のバージョニング
Apache MXNet は現在、下位互換性を保証していないため、フレームワークの新しいバージョンを使用してトレーニングするモデルは、フレームワークの以前のバージョンでは正しく動作しないことがあります。モデルトレーニング段階とモデル提供段階との間で競合を回避し、一貫したエンドツーエンドエクスペリエンスを実現するには、両方の段階で同じバージョンの MXNet フレームワークを使用します。
Raspberry Pi の MXNet
ローカル MXNet モデルにアクセスする Greengrass Lambda 関数では、以下の環境変数が設定される必要があります。
MXNET_ENGINE_TYPE=NativeEngine
関数コードで環境変数を設定することも、関数のグループ固有設定に追加することもできます。構成設定として環境変数を追加する例については、このステップを参照してください。
注記
サードパーティのコード例を実行するなどの MXNet フレームワークの一般使用に対しては、環境変数を Raspberry Pi で設定する必要があります。
Raspberry Pi での TensorFlow モデルの制限
推論結果を向上させるための推奨事項は、Raspberry Pi プラットフォームで TensorFlow 32-bit Arm ライブラリを使用したテストに基づいています。これらの推奨事項は、上級ユーザーのみを対象としており、いかなる種類の保証もありません。
-
チェックポイント
形式を使用してトレーニングされたモデルは、提供する前にプロトコルバッファ形式で "圧縮" する必要があります。例については、「TensorFlow-Slim イメージ分類モデルライブラリ 」を参照してください。 -
TF-Estimator および TF-Slim ライブラリはトレーニングコードまたは推論コードで使用しないでください。代わりに、以下の例に示している
.pbファイルモデルロードパターンを使用してください。graph = tf.Graph() graph_def = tf.GraphDef() graph_def.ParseFromString(pb_file.read()) with graph.as_default(): tf.import_graph_def(graph_def)
注記
TensorFlow でサポートされているプラットフォームの詳細については、TensorFlow のドキュメントの「TensorFlow のインストール
