Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Si ejecuta Amazon EMR HBase en la versión 5.2.0 o posterior, puede habilitarlo en Amazon HBase S3, lo que ofrece las siguientes ventajas:
El directorio HBase raíz se almacena en Amazon S3, incluidos los archivos de la HBase tienda y los metadatos de las tablas. Estos datos son persistentes fuera del clúster, están disponibles en todas las zonas de EC2 disponibilidad de Amazon y no es necesario recuperarlos mediante instantáneas u otros métodos.
Con los archivos de almacén en Amazon S3, puede dimensionar el clúster de Amazon EMR en función de sus requisitos informáticos en lugar de sus requisitos de datos, con una replicación 3x en HDFS.
Mediante la versión 5.7.0 de Amazon EMR o posteriores, puede configurar un clúster de réplicas de lectura, lo que le permite mantener copias de solo lectura de los datos en Amazon S3. Puede acceder a los datos desde el clúster de réplicas de lectura para realizar operaciones de lectura de forma simultánea y en caso de que el clúster principal deje de estar disponible.
En las versiones 6.2.0 a 7.3.0 de Amazon EMR, el HFile seguimiento persistente utiliza una tabla HBase del sistema llamada
hbase:storefilepara rastrear directamente las HFile rutas utilizadas para las operaciones de lectura. Esta característica está habilitada de forma predeterminada y no requiere ninguna migración manual. En las versiones posteriores a la 7.3.0, las HFile rutas se rastrean mediante un rastreador de archivos, que almacena las HFile rutas directamente en un metaarchivo, dentro del directorio de la tienda.
nota
Los usuarios que utilizan una versión de Amazon EMR anterior a la 7.4.0 y van a migrar a EMR-7.4.0 y versiones posteriores, consulte Migración desde HBase versiones anteriores y siga la documentación de actualización disponible para garantizar una transición fluida.
La siguiente ilustración muestra los HBase componentes relevantes para HBase Amazon S3.
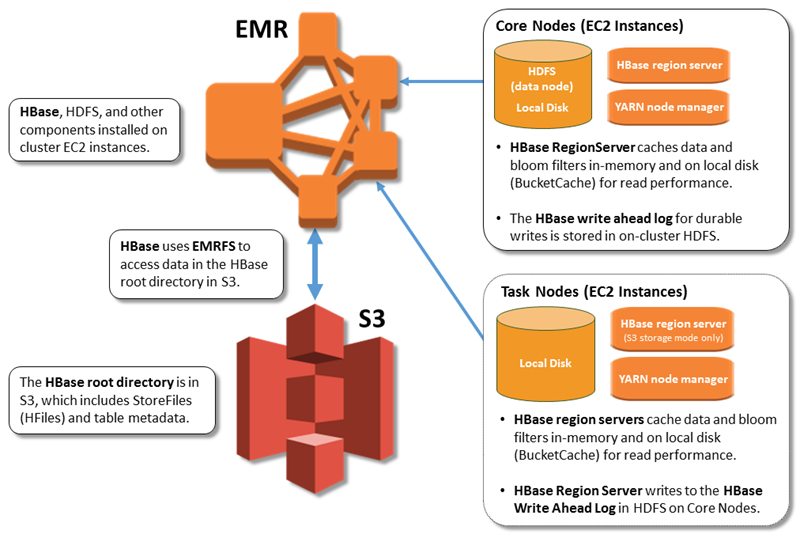
Habilitación HBase en Amazon S3
Puede activarlo HBase en Amazon S3 mediante la consola de Amazon EMR AWS CLI, la o la API de Amazon EMR. La configuración es una opción durante la creación del clúster. Al utilizar la consola, elija la configuración mediante las Advanced options (Opciones avanzadas). Al utilizar la AWS CLI, utilice la opción --configurations para proporcionar un objeto de configuración JSON. Las propiedades del objeto de configuración especifican el modo de almacenamiento y la ubicación del directorio raíz en Amazon S3. La ubicación de Amazon S3 que especifique debe estar en la misma región que el clúster de Amazon EMR. Solo un clúster activo a la vez puede utilizar el mismo directorio HBase raíz en Amazon S3. Para ver los pasos de la consola y un ejemplo detallado de creación de clústeres utilizando el AWS CLI, consulte. Crear un clúster con HBase Un objeto de configuración de ejemplo se muestra en el siguiente fragmento de JSON.
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
nota
Si utiliza un bucket de Amazon S3 como rootdir formulario HBase, debe añadir una barra al final del URI de Amazon S3. Por ejemplo, debe utilizar "hbase.rootdir: s3://amzn-s3-demo-bucket/", en lugar de "hbase.rootdir: s3://amzn-s3-demo-bucket", para evitar problemas.
Uso de un clúster de réplicas de lectura
Después de configurar un clúster principal con HBase Amazon S3, puede crear y configurar un clúster de réplica y lectura que proporcione acceso de solo lectura a los mismos datos que el clúster principal. Esto resulta útil cuando se necesita acceso simultáneo a datos de consulta o acceso ininterrumpido si el clúster principal deja de estar disponible. La característica de réplica de lectura está disponible en la versión 5.7.0 de Amazon EMR y posteriores.
El clúster principal y el clúster de réplicas de lectura se configuran de la misma forma con una importante diferencia. Ambos apuntan a la misma ubicación hbase.rootdir. Sin embargo, la clasificación hbase del clúster de réplicas de lectura incluye la propiedad "hbase.emr.readreplica.enabled":"true".
El clúster de réplica y lectura está diseñado para operaciones de solo lectura y no se debe realizar ninguna acción manual de compactación o escritura en él. Para las versiones de Amazon EMR anteriores a la 7.4.0, se recomienda deshabilitar la compactación en el clúster de lectura-réplica al habilitar la función de lectura-réplica. Esta precaución es necesaria porque, con la función de HFile seguimiento persistente habilitada en el clúster principal, es posible que el clúster de lectura-réplica compacte las tablas del sistema, lo que podría provocar una en el clúster principal. FileNotFoundException Al deshabilitar la compactación en el clúster de lectura-réplica, se evitan las incoherencias de datos entre el clúster principal y el clúster de réplica de lectura.
Por ejemplo, dada la clasificación JSON del clúster principal, tal como se muestra anteriormente en el tema, la configuración de un clúster de lectura-réplica para las versiones de EMR anteriores a la 7.4.0 es la siguiente:
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir", "hbase.regionserver.compaction.enabled": "false" } }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
Para las versiones de Amazon EMR posteriores a la 7.3.0, ahora utilizamos la Seguimiento de archivos de la tienda función, por lo que no es necesario deshabilitar las compactaciones.
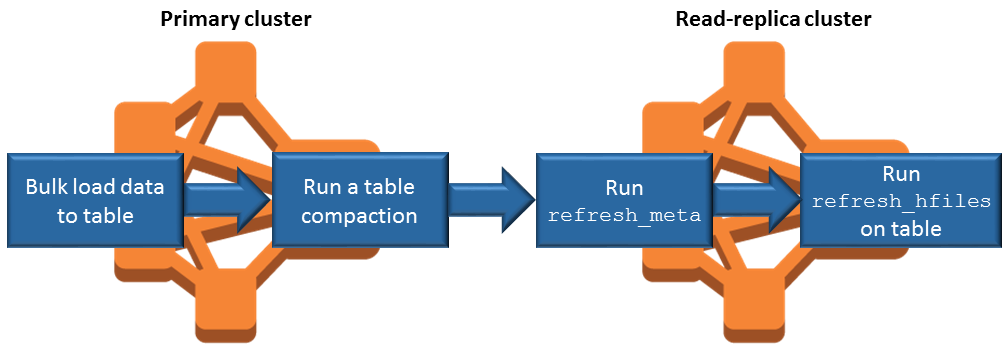
Sincronización de la réplica de lectura al agregar datos
Como la réplica de lectura utiliza HBase StoreFiles los metadatos que el clúster principal escribe en Amazon S3, la réplica de lectura solo es tan actualizada como el almacén de datos de Amazon S3. Las siguientes directrices pueden ayudarle a minimizar el retardo entre el clúster principal y la réplica de lectura al escribir datos.
Cargue los datos de forma masiva en el clúster principal siempre que sea posible. Para obtener más información, consulte la documentación sobre la carga masiva
en Apache. HBase Debe llevarse a cabo un vaciado que escriba archivos de almacén en Amazon S3 tan pronto como sea posible después de agregar los datos. Realice el vaciado manualmente o bien ajuste la configuración de vaciado para minimizar el retardo.
Si las compactaciones se pudieran ejecutar automáticamente, ejecute una compactación manual para evitar incoherencias cuando se activen las compactaciones.
En el clúster de lectura-réplica, ejecute el comando cuando se modifique algún metadato (por ejemplo, cuando se dividan o compacten HBase regiones, o cuando se agreguen o eliminen tablas).
refresh_metaEn el clúster de réplicas de lectura, ejecute el comando
refresh_hfilescuando se añadan registros o se cambien en una tabla.
Seguimiento persistente HFile
HFile El seguimiento persistente utiliza una tabla HBase del sistema llamada hbase:storefile para rastrear directamente las HFile rutas utilizadas para las operaciones de lectura. Las nuevas HFile rutas se añaden a la tabla a medida que se añaden datos adicionales HBase. Esto elimina las operaciones de cambio de nombre como mecanismo de confirmación en HBase las rutas de escritura críticas y mejora el tiempo de recuperación al abrir una HBase región al leer la tabla del hbase:storefile sistema en lugar de la lista de directorios del sistema de archivos. Esta función está habilitada de forma predeterminada en las versiones 6.2.0 a 7.3.0 de Amazon EMR y no requiere ningún paso de migración manual.
nota
El HFile seguimiento persistente mediante la tabla del HBase sistema de archivos de almacenamiento no admite la HBase función de replicación regional. Para obtener más información sobre HBase la replicación regional, consulte Lecturas de alta disponibilidad coherentes con el cronograma
Desactivar el seguimiento persistente HFile
El HFile seguimiento persistente está activado de forma predeterminada a partir de la versión 6.2.0 de Amazon EMR. Para deshabilitar el HFile seguimiento persistente, especifique la siguiente anulación de configuración al lanzar un clúster:
{
"Classification": "hbase-site",
"Properties": {
"hbase.storefile.tracking.persist.enabled":"false",
"hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine"
}
}nota
Al volver a configurar el clúster de Amazon EMR, se deben actualizar todos los grupos de instancias.
Sincronización manual de la tabla de archivos de almacenamiento
La tabla de archivos de almacenamiento se mantiene actualizada a medida que se crean nuevas HFile instancias. Sin embargo, si la tabla de archivos de almacenamiento no está sincronizada con los archivos de datos por algún motivo, se pueden usar los siguientes comandos para sincronizar los datos manualmente:
Sincronice la tabla de archivos de almacenamiento en una región en línea:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
Sincronice la tabla de archivos de almacenamiento en una región sin conexión:
Elimine la tabla de archivos de almacenamiento znode.
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]Asigne la región (ejecute en el intérprete de comandos de HBase).
hbase cli> assign '<region name>'Si se produce un error en la asignación.
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
Escalar la tabla de archivos de almacenamiento
La tabla de archivos de almacenamiento se divide en cuatro regiones de forma predeterminada. Si la tabla de archivos de almacenamiento aún tiene una gran carga de escritura, se puede dividir aún más manualmente.
Para dividir una región activa específica, utilice el siguiente comando (ejecute en el intérprete de comandos de HBase).
hbase cli> split '<region name>'Para dividir la tabla, utilice el siguiente comando (ejecute en el intérprete de comandos de HBase).
hbase cli> split 'hbase:storefile'Seguimiento de archivos de la tienda
De forma predeterminada, utilizamos la FileBasedStoreFileTrackerimplementación. Esta implementación crea nuevos archivos directamente en el directorio de la tienda, lo que evita la necesidad de realizar operaciones de cambio de nombre. Mantiene una lista de las instancias de hfile confirmadas en la memoria, respaldada por los metaarchivos de cada directorio de la tienda. Cada vez que se confirma un nuevo archivo hfile, se actualiza la lista de archivos rastreados en el almacén en cuestión y se escribe un nuevo metaarchivo con el contenido de la lista y descartando el metarchivo anterior, que contiene una lista obsoleta. Puede encontrar más información sobre el seguimiento de archivos de almacén en la guía de HBase referencia de Apache en el apartado Seguimiento de archivos de almacén
La implementación del FileBasedStoreFile rastreador está habilitada de forma predeterminada, a partir de la versión 7.4.0 de Amazon EMR:
{
"Classification": "hbase-site",
"Properties": {
hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.FileBasedStoreFileTracker"
}Para deshabilitar la FileBasedStoreFileTracker implementación, especifique la siguiente anulación de configuración al lanzar un clúster:
{
"Classification": "hbase-site",
"Properties": {
hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.DefaultStoreFileTracker"
}nota
Al volver a configurar el clúster de Amazon EMR, se deben actualizar todos los grupos de instancias.
Consideraciones operativas
HBase los servidores de región se utilizan BlockCache para almacenar las lecturas de datos en la memoria y BucketCache para almacenar las lecturas de datos en el disco local. Además, los servidores de región suelen almacenar MemStore las escrituras de datos en la memoria y utilizan los registros de escritura anticipada para almacenar las escrituras de datos en HDFS antes de que los datos se escriban en Amazon HBase StoreFiles S3. El rendimiento de lectura del clúster se refiere a la frecuencia con la que un registro puede recuperarse en memoria o en las cachés de disco. Si se pierde la memoria caché, el registro se lee desde Amazon S3, que tiene una latencia y una desviación estándar significativamente más altas que la lectura desde HDFS. StoreFile Además, las velocidades de solicitud máximas en Amazon S3 son más bajas que las que se pueden conseguir en la caché local, por lo que el almacenamiento de datos en caché podría ser importante para cargas de trabajo con lectura intensiva. Para obtener más información, consulte Optimizar el rendimiento de Amazon S3 en la Guía del usuario de Amazon Simple Storage Service.
Para mejorar el rendimiento, le recomendamos que almacene en caché la mayor cantidad posible de su conjunto de datos en el almacenamiento de EC2 instancias. Como BucketCache utiliza el almacenamiento de EC2 instancias del servidor de la región, puede elegir un tipo de EC2 instancia con un almacén de instancias suficiente y añadir el almacenamiento de Amazon EBS para acomodar el tamaño de caché requerido. También puede aumentar el BucketCache tamaño de los almacenes de instancias adjuntos y los volúmenes de EBS mediante la hbase.bucketcache.size propiedad. La configuración predeterminada es 8 192 MB.
En el caso de las escrituras, la MemStore frecuencia de las descargas y el número de descargas StoreFiles presentes durante las compactaciones menores y mayores pueden contribuir considerablemente a aumentar los tiempos de respuesta de los servidores regionales. Para obtener un rendimiento óptimo, considere la posibilidad de aumentar el tamaño del multiplicador de HRegion bloques y de MemStore descarga, lo que aumentará el tiempo transcurrido entre las compactaciones principales, pero también aumentará el retraso en la coherencia si utiliza una réplica de lectura. En algunos casos, es posible obtener un mejor rendimiento mediante tamaños de bloque de archivo más grandes (pero inferiores a 5 GB) para activar la funcionalidad de carga multiparte de Amazon S3 en EMRFS. El tamaño de bloque predeterminado de Amazon EMR es de 128 MB. Para obtener más información, consulte Configuración de HDFS. No son frecuentes los clientes que superen un tamaño de bloque de 1 GB al realizar un análisis comparativo del rendimiento con vaciados y compactaciones. Además, HBase las compactaciones y los servidores regionales funcionan de forma óptima cuando es necesario compactar menos. StoreFiles
Las tablas pueden tardar mucho en eliminarse en Amazon S3, ya que es necesario cambiar de nombre directorios grandes. Considere la posibilidad de deshabilitar las tablas en lugar de eliminarlas.
Existe un proceso HBase más limpio que limpia los archivos WAL antiguos y almacena los archivos. En la versión 5.17.0 de Amazon EMR y posteriores, el limpiador está habilitado de forma global y se pueden utilizar las siguientes propiedades de configuración para controlar su comportamiento.
| Propiedad de configuración | Valor predeterminado | Descripción |
|---|---|---|
|
|
1 |
El número de subprocesos asignados a la limpieza ha caducado mucho. HFiles |
|
|
1 |
El número de subprocesos asignados a la limpieza expirado es pequeño HFiles. |
|
|
Se establece en la cuarta parte de los núcleos disponibles. |
El número de subprocesos para escanear los WALs directorios antiguos. |
|
|
2 |
El número de subprocesos que se van a limpiar WALs en el WALs directorio antiguo. |
En Amazon EMR 5.17.0 y versiones anteriores, el funcionamiento del limpiador puede afectar al rendimiento de las consultas cuando se ejecutan cargas de trabajo pesadas, por lo que le recomendamos que únicamente habilite el limpiador fuera de las horas punta. El limpiador tiene los siguientes comandos de HBase shell:
cleaner_chore_enabledconsulta si el limpiador está habilitado.cleaner_chore_runejecuta manualmente el limpiador para eliminar archivos.cleaner_chore_switchhabilita o deshabilita el limpiador y devuelve el estado anterior del limpiador. Por ejemplo,cleaner_chore_switch truehabilita el limpiador.
Propiedades para ajustar HBase el rendimiento en Amazon S3
Los siguientes parámetros se pueden ajustar para ajustar el rendimiento de la carga de trabajo cuando se utiliza HBase en Amazon S3.
| Propiedad de configuración | Valor predeterminado | Descripción |
|---|---|---|
|
|
8 192 |
La cantidad de espacio en disco, en MB, reservado en el servidor regional, los almacenes de EC2 instancias de Amazon y los volúmenes de EBS para el BucketCache almacenamiento. La configuración se aplica a todas las instancias de servidor de región. BucketCache Los tamaños más grandes suelen corresponder a un rendimiento mejorado |
|
|
134217728 |
El límite de datos, en bytes, a partir del cual el vaciado de memstore en Amazon S3 se activa. |
|
|
4 |
Multiplicador que determina el límite MemStore superior en el que se bloquean las actualizaciones. Si |
|
|
10 |
La cantidad máxima StoreFiles que puede haber en una tienda antes de que se bloqueen las actualizaciones. |
|
|
10737418240 |
El tamaño máximo de una región antes de que la región se divida. |
Cierre y restauración de un clúster sin pérdida de datos
Para cerrar un clúster de Amazon EMR sin perder datos que no se hayan escrito en Amazon S3, debe vaciar la MemStore memoria caché en Amazon S3 para escribir nuevos archivos de almacenamiento. En primer lugar, tendrá que deshabilitar todas las tablas. La siguiente configuración de paso puede utilizarse al añadir un paso al clúster. Para obtener más información, consulte Uso de pasos con la AWS CLI y la consola en la Guía de administración de Amazon EMR.
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"] De forma alternativa, puede ejecutar el siguiente comando bash directamente.
bash /usr/lib/hbase/bin/disable_all_tables.shTras deshabilitar todas las tablas, vacíe la hbase:meta tabla con el HBase shell y el siguiente comando.
flush 'hbase:meta'A continuación, puede ejecutar un script de shell incluido en el clúster de Amazon EMR para vaciar la caché. MemStore Puede agregarlo como un paso o ejecutarlo directamente a través de la AWS CLI en el clúster. El script deshabilita todas HBase las tablas, lo que provoca que MemStore el servidor de cada región pase a Amazon S3. Si el script se completa de forma satisfactoria, los datos persisten en Amazon S3 y el clúster puede terminarse.
Para reiniciar un clúster con los mismos HBase datos, especifique la misma ubicación de Amazon S3 que el clúster anterior, ya sea en la propiedad de hbase.rootdir configuración AWS Management Console o mediante ella.
