翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
コネクタを理解する
コネクタは、ストリーミングデータをデータソースから Apache Kafka クラスターに継続的にコピーするか、クラスターからデータシンクにデータを継続的にコピーすることにより、外部システムと Amazon サービスを Apache Kafka と統合します。コネクタは、データを宛先に配信する前に、変換、フォーマット変換、データのフィルタリングなどの軽量ロジックを実行することもできます。ソースコネクタはデータソースからデータをプルしてこのデータをクラスターにプッシュし、シンクコネクタはクラスターからデータをプルしてこのデータをデータシンクにプッシュします。
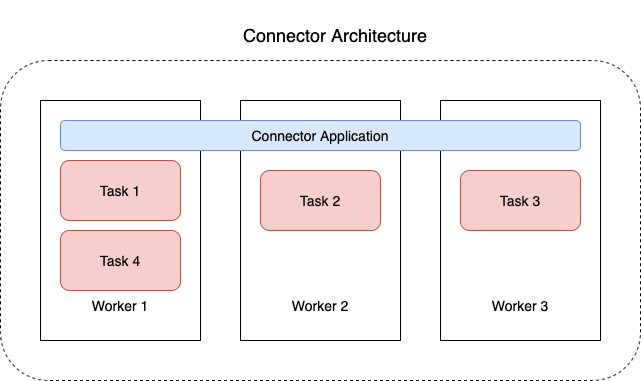
次の図表は、コネクタのアーキテクチャを示しています。ワーカーは、コネクタロジックを実行する Java 仮想マシン (JVM) プロセスです。各ワーカーは、並列スレッドで実行され、データをコピーする作業を行う一連のタスクを作成します。タスクは状態を保存しないため、復元力のあるスケーラブルな Data Pipeline を提供するために、いつでも開始、停止、または再開できます。