本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
本节提供了使用 Amazon Rekognition Image 和 Amazon Rekognition Video 检测图像和视频中的标签的信息。
标签是基于其内容在图像或视频中找到的对象或概念(包括场景和动作)。例如,热带海滩上的人物照片可能包含棕榈树(对象)、海滩(场景)、奔跑(动作)以及户外(概念)等标签。
Rekognition 标签检测操作支持的标签
注意
Amazon Rekognition 根据特定图像中一个人的外表进行性别二进制预测(男性、女性、女孩等)。这种预测不是为了对一个人的性别认同进行分类而设计的,您不应该使用 Amazon Rekognition 来做出这样的决定。例如,戴着长发假发和耳环扮演角色的男演员可能被预测为女性。
使用 Amazon Rekognition 进行性别二进制预测最适合需要在不识别特定用户的情况下分析汇总性别分布统计数据的使用案例。例如,社交媒体平台用户中女性与男性的比例。
我们不建议使用性别二进制预测来做出会影响个人权利、隐私或服务访问权限的决策。
Amazon Rekognition 返回英文标签。您可以使用 Amazon Translate
下图显示了调用操作的顺序,具体取决于您使用 Amazon Rekognition Image 或 Amazon Rekognition Video 操作的目标:
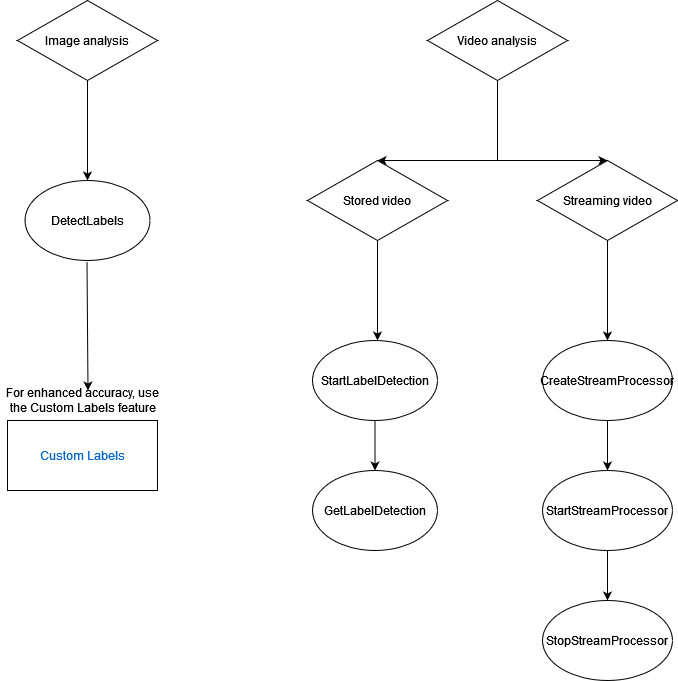
为响应对象添加标签
边界框
Amazon Rekognition Image 和 Amazon Rekognition Video 可以为常见对象标签(例如车辆、家具、服装或宠物)返回边界框。对于不常见的对象标签,将不会返回边界框信息。您可以使用边界框找到对象在图像中的确切位置,对检测到的对象实例计数或者使用边界框尺寸衡量对象的大小。
例如,在下图中,Amazon Rekognition Image 能够检测是否存在人员、滑板、停放的车辆和其他信息。Amazon Rekognition Image 还会返回检测到的人员以及其他检测到的对象(例如汽车和车轮)的边界框。

置信度得分
Amazon Rekognition Video 和 Amazon Rekognition Image 提供了百分比分数,用于表示 Amazon Rekognition 对每个检测到的标签的准确性中具有的置信度。
父级
Amazon Rekognition Image 和 Amazon Rekognition Video 使用原级标签的分层分类对标签进行分类。例如,一个正在穿过马路的人可能会检测为行人。行人 的父标签为人。在响应中会返回这两个标签。所有原级标签将返回,给定的标签包含其父级和其他原级标签的列表。例如,祖父和曾祖父标签(如果存在)。您可以使用父标签生成一组相关标签,以允许在一个或多个图像中查询类似的标签。例如,查询所有交通工具 可能会返回一张图像中的汽车,以及另一张图像中的摩托车。
类别
Amazon Rekognition Image 和 Amazon Rekognition Video 返回标签类别的相关信息。标签是根据常见功能和上下文将各个标签组合在一起的类别的一部分,例如“车辆和汽车”和“食品和饮料”。标签类别可以是父类别的子类别。
别名
除返回标签外,Amazon Rekognition Image 和 Amazon Rekognition Video 还会返回与标签相关的所有别名。别名是具有相同含义的标签,或在视觉上可与返回的主标签互换的标签。例如,“Cell Phone”是“Mobile Phone”的别名。
在之前的版本中,Amazon Rekognition Image 在包含“Cell Phone”的主标签名称列表中返回了诸如“Mobile Phone”之类的别名。Amazon Rekognition Image 现在在名为“别名”的字段中返回“Cell Phone”,在主要标签名称列表中返回“Mobile Phone”。如果您的应用程序依赖于先前版本的 Rekognition 返回的结构,则可能需要将图像或视频标签检测操作返回的当前响应转换为之前的响应结构,其中所有标签和别名都作为主标签返回。
如果您需要将来自 DetectLabels API 的当前响应(用于图像中的标签检测)转换为之前的响应结构,请参阅中的代码示例转变 DetectLabels应对措施。
如果您需要将来自 GetLabelDetection API 的当前响应(用于存储视频中的标签检测)转换为之前的响应结构,请参阅中的代码示例转变回 GetLabelDetection 应。
图像属性
Amazon Rekognition Image 返回有关整张图片的图像质量(锐度、亮度和对比度)的信息。还会返回图像前景和背景的锐度和亮度。图像属性还可用于检测整个图像、前景、背景和带有边界框的对象的主色。

以下是正在 ImageProperties 处理的图像的 DetectLabels 操作响应中包含的数据示例:
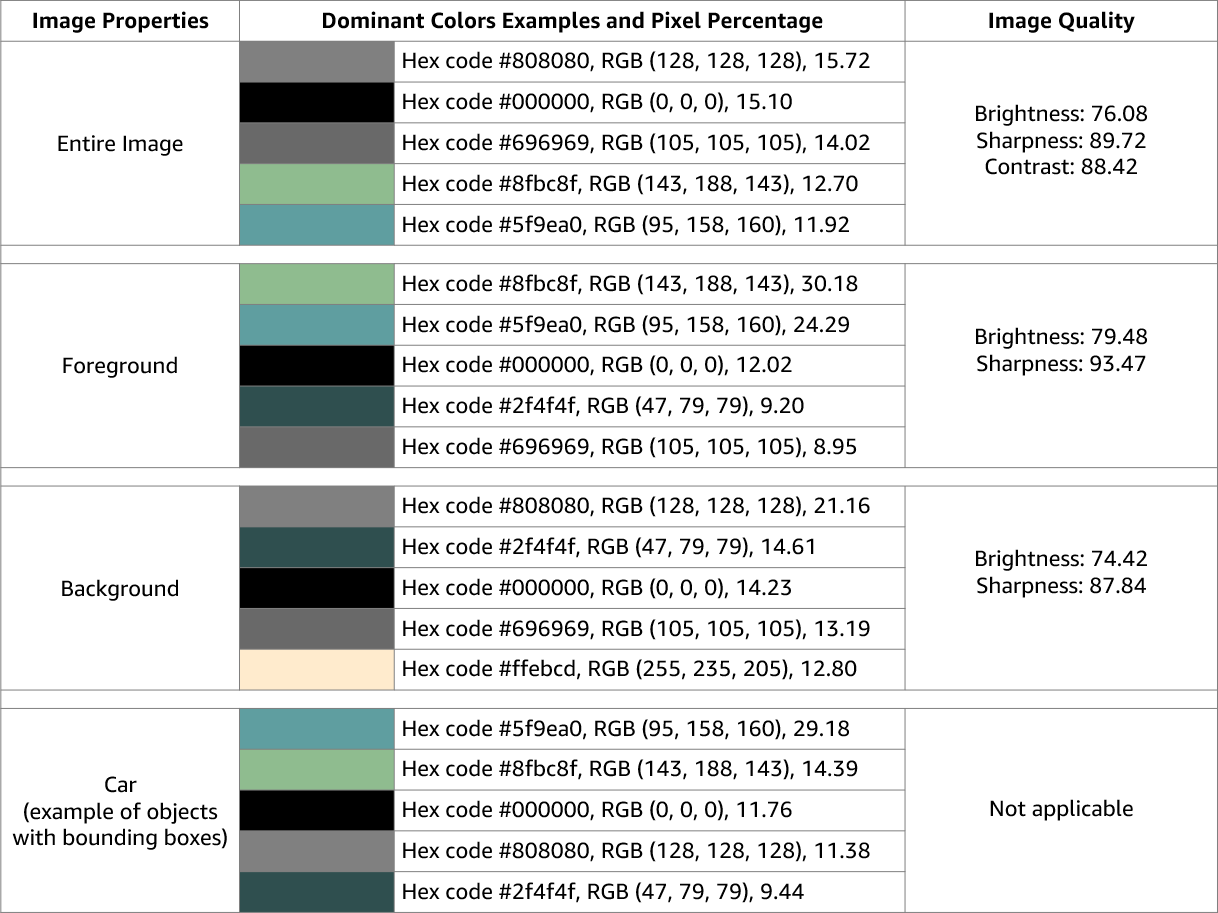
图片属性不适用于 Amazon Rekognition Video。
模型版本
Amazon Rekognition Image 和 Amazon Rekognition Video 返回用于检测图像或存储视频中的标签的标签检测模型版本。
纳入和排除筛选器
您可以筛选 Amazon Rekognition Image 和 Amazon Rekognition Video 标签检测操作返回的结果。通过提供标签和类别的筛选标准来筛选结果。标签筛选器可以执行纳入或排除操作。
有关使用 DetectLabels 筛选获得的结果的更多信息,请参阅检测图像中的标签。
有关使用 GetLabelDetection 筛选获得的结果的更多信息,请参阅检测视频中的标签。
对结果进行排序和汇总
从某些 Amazon Rekognition Video 操作中获得的结果可以根据时间戳和视频片段进行排序和汇总。分别使用 GetLabelDetection 或 GetContentModeration 检索标签检测或内容审核作业的结果时,您可以使用 SortBy 和 AggregateBy 参数来指定希望如何返回结果。您可以SortBy与TIMESTAMP或NAME(标签名称)一起使用,也可以将TIMESTAMPS或SEGMENTS与 AggregateBy参数一起使用。
