支援終止通知:在 2025 年 10 月 31 日, AWS 將停止對 Amazon Lookout for Vision 的支援。2025 年 10 月 31 日之後,您將無法再存取 Lookout for Vision 主控台或 Lookout for Vision 資源。如需詳細資訊,請造訪此部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
了解 Amazon Lookout for Vision
您可以使用 Amazon Lookout for Vision 來準確且大規模地尋找工業產品中的視覺瑕疵,例如:
-
偵測受損的零件 – 在製造和組裝過程中,發現產品的表面品質、顏色和形狀受損。
-
識別缺少的元件 – 根據物件的不存在、存在或放置,判斷缺少的元件。例如,在印刷電路板上缺少的電容。
-
發現程序問題 – 偵測具有重複模式的瑕疵,例如在矽晶片上的相同位置重複劃痕。
使用 Lookout for Vision,您可以建立電腦視覺模型,預測影像中是否存在異常。您提供 Amazon Lookout for Vision 用來訓練和測試模型的影像。Amazon Lookout for Vision 提供指標,您可以用來評估和改善訓練過的模型。您可以在 AWS 雲端託管訓練模型,也可以將模型部署到邊緣裝置。簡單API操作會傳回模型所做的預測。
建立、評估和使用模型的一般工作流程如下:
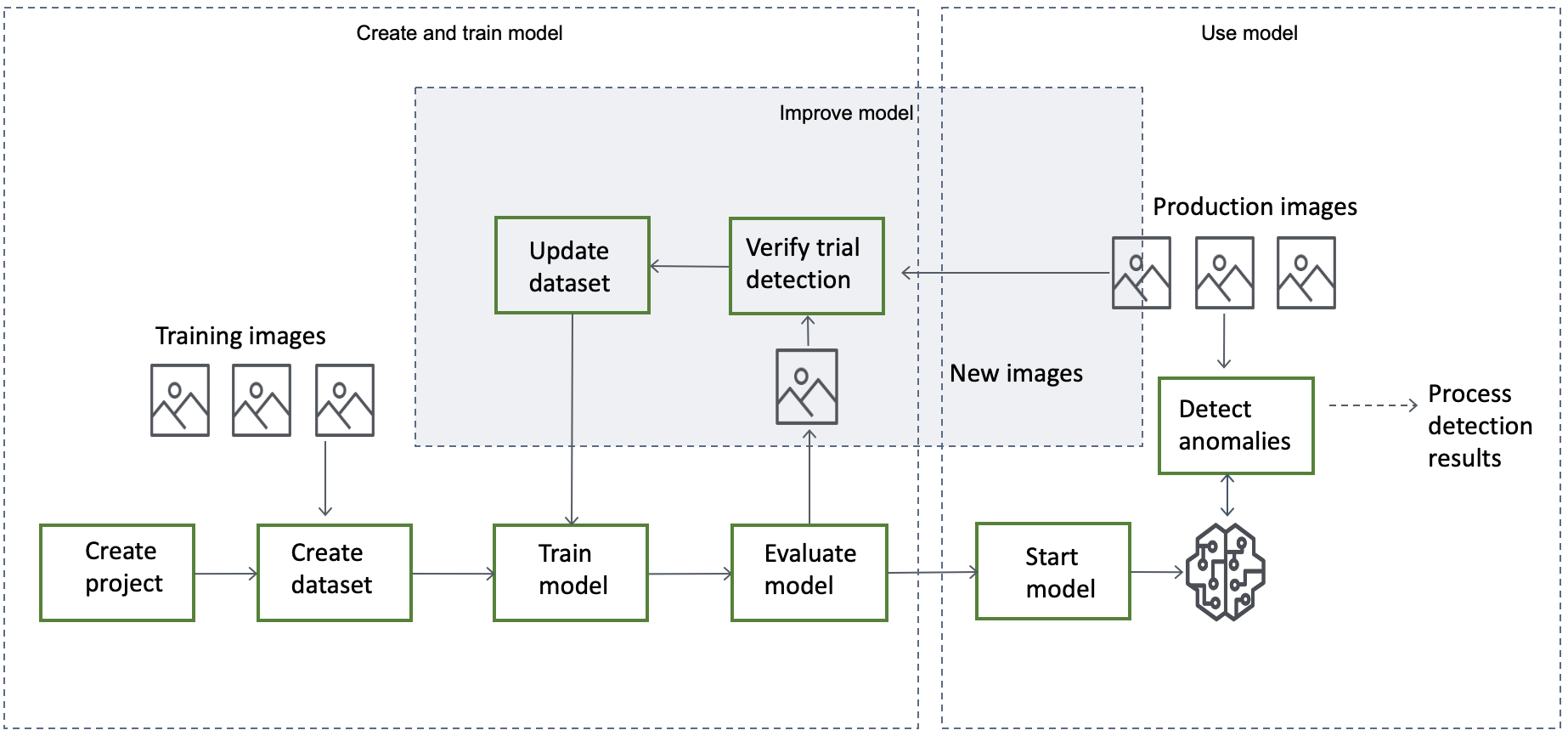
選擇您的模型類型
在建立模型之前,您必須決定您想要的模型類型。您可以建立兩種類型的模型:影像分類和影像分割。您可以根據您的使用案例決定要建立的模型類型。
影像分類模型
如果您只需要知道影像是否包含異常,但不需要知道其位置,請建立影像分類模型。影像分類模型會預測影像是否包含異常。預測包括模型對預測準確性的可信度。此模型不會提供有關影像上任何異常位置的任何資訊。
影像分割模型
如果您需要知道異常的位置,例如劃痕的位置,請建立影像分割模型。Amazon Lookout for Vision 模型使用語意分割來識別影像上存在異常類型 (例如刮痕或缺少部分) 的像素。
注意
語意分割模型會找出不同類型的異常。它不提供個別異常的執行個體資訊。例如,如果影像包含兩個凹痕, Lookout for Vision 會傳回代表凹痕異常類型的單一實體中兩個凹痕的相關資訊。
Amazon Lookout for Vision 分割模型預測下列項目:
分類
模型會傳回已分析影像的分類 (正常/異常),其中包括模型對預測的可信度。分類資訊是與分割資訊分開計算的,您不應在它們之間建立關係。
區隔
模型會傳回影像遮罩,標記影像上發生異常的像素。不同類型的異常會根據指派給資料集中異常標籤的顏色進行顏色編碼。異常標籤代表異常的類型。例如,下圖中的藍色遮罩會標記汽車上發現的劃痕異常類型的位置。

模型會傳回遮罩中每個異常標籤的顏色碼。此模型也會傳回異常標籤所具有影像的百分比涵蓋範圍。
使用 Lookout for Vision 分割模型,您可以使用各種條件來分析模型的分析結果。例如:
-
異常位置 – 如果您需要知道異常位置,請使用分割資訊查看涵蓋異常的遮罩。
-
異常類型 – 使用分割資訊來判斷影像是否包含超過可接受數量的異常類型。
-
涵蓋區域 – 使用分割資訊來判斷異常類型是否涵蓋超過影像可接受的區域。
-
影像分類 – 如果您不需要知道異常的位置,請使用分類資訊來判斷影像是否包含異常。
如需範例程式碼,請參閱 偵測映像中的異常。
在您決定您想要的模型類型後,您可以建立專案和資料集來管理模型。使用標籤,您可以將影像分類為正常或異常。標籤也會識別分割資訊,例如遮罩和異常類型。如何標記資料集中的影像,決定 Lookout for Vision 為您建立的模型類型。
標記影像分割模型比標記影像分類模型更複雜。若要訓練分割模型,您必須將訓練影像分類為正常或異常。您也必須為每個異常影像定義異常遮罩和異常類型。分類模型只需要您將訓練影像識別為正常或異常。
建立模型
建立模型的步驟是建立專案、建立資料集,以及訓練模型,如下所示:
建立專案
建立專案以管理資料集和您建立的模型。專案應該用於單一使用案例,例如偵測單一類型機器組件中的異常。
您可以使用儀表板來取得專案的概觀。如需詳細資訊,請參閱使用 Amazon LoLookout for Vision 儀表板。
更多資訊:建立您的專案。
建立資料集
若要訓練模型,Amazon Lookout for Vision 需要正常和異常物件的影像,以滿足您的使用案例。您可以在資料集中提供這些影像。
資料集是描述這些影像的一組影像和標籤。影像應代表可能發生異常的單一類型物件。如需詳細資訊,請參閱準備資料集的影像。
使用 Amazon Lookout for Vision,您可以擁有使用單一資料集的專案,或具有個別訓練和測試資料集的專案。建議您使用單一資料集專案,除非您想要更精確地控制訓練、測試和效能調校。
您可以透過匯入映像來建立資料集。視您匯入影像的方式而定,也可能標記影像。如果沒有,您可以使用 主控台來標記影像。
匯入映像
如果您使用 Lookout for Vision 主控台建立資料集,您可以使用下列其中一種方式匯入映像:
-
從本機電腦匯入映像。影像不會加上標籤。
-
從 S3 儲存貯體匯入映像。Amazon Lookout for Vision 可以使用包含影像的資料夾名稱來分類影像。將
normal用於一般影像。anomaly用於異常映像。您無法自動指派分割標籤。 -
匯入 Amazon SageMaker AI Ground Truth 資訊清單檔案。資訊清單檔案中的影像會加上標籤。您可以建立和匯入自己的資訊清單檔案。如果您有許多影像,請考慮使用 SageMaker AI Ground Truth 標籤服務。然後,從 Amazon SageMaker AI Ground Truth 任務匯入輸出資訊清單檔案。
標記檔案
標籤描述資料集中的映像。標籤會指定影像是正常還是異常 (分類)。標籤也會描述影像上異常的位置 (區段)。
如果您的影像未標記,您可以使用 主控台來標記。
您指派給資料集中影像的標籤決定 Lookout for Vision 建立的模型類型:
Image classification
若要建立影像分類模型,請使用 Lookout for Vision 主控台,將資料集中的影像分類為正常或異常。
您也可以使用 CreateDataset操作,從包含分類資訊的資訊清單檔案建立資料集。
影像分割
若要建立影像分割模型,請使用 Lookout for Vision 主控台將資料集中的影像分類為正常或異常。您也可以為影像上的異常區域 (如果存在) 指定像素遮罩,以及為個別異常遮罩指定異常標籤。
您也可以使用 CreateDataset操作,從包含分段和分類資訊的資訊清單檔案建立資料集。
如果您的專案有單獨的訓練和測試資料集, Lookout for Vision 會使用訓練資料集來學習和判斷模型類型。您應該以相同的方式標記測試資料集中的映像。
更多資訊:建立資料集。
培訓模型
訓練會建立模型並訓練模型,以預測影像中是否存在異常。每次訓練都會建立新的模型版本。
在訓練開始時,Amazon Lookout for Vision 會選擇最適合用來訓練模型的演算法。模型會經過訓練,然後進行測試。在 中Amazon Lookout for Vision,您會訓練單一資料集專案,資料集會在內部分割,以建立訓練資料集和測試資料集。您也可以建立具有個別訓練和測試資料集的專案。在此組態中,Amazon Lookout for Vision 會使用訓練資料集訓練模型,並使用測試資料集測試模型。
重要
您需要支付成功訓練模型所需的時間。
詳細資訊:訓練您的模型。
評估模型
使用在測試期間建立的效能指標來評估模型的效能。
使用效能指標,您可以更了解訓練模型的效能,並決定您是否已準備好在生產中使用它。
更多資訊:改善您的模型。
如果效能指標指出需要改進,您可以透過使用新映像執行試驗偵測任務來新增更多訓練資料。任務完成後,您可以驗證結果,並將已驗證的影像新增至訓練資料集。或者,您可以將新的訓練影像直接新增至資料集。接下來,您將重新訓練模型,並重新檢查效能指標。
詳細資訊:使用試驗偵測任務 驗證您的模型。
使用您的模型
在 AWS 雲端中使用模型之前,請先使用 StartModel操作啟動模型。您可以從主控台取得模型的 StartModelCLI命令。
詳細資訊:啟動您的模型。
經過訓練的 Amazon Lookout for Vision 模型可預測輸入映像是否包含正常或異常內容。如果您的模型是分段模型,則預測包含異常遮罩,用於標記找到異常的像素。
若要使用模型進行預測,請呼叫 DetectAnomalies操作,並從本機電腦傳遞輸入映像。您可以從主控台取得呼叫 DetectAnomalies 的CLI命令。
更多資訊:偵測映像中的異常。
重要
您需要根據模型的執行時間付費。
如果您不再使用模型,請使用 StopModel操作來停止模型。您可以從主控台取得 CLI命令。
更多資訊:停止您的模型。
在邊緣裝置上使用您的模型
您可以在 AWS IoT Greengrass Version 2 核心裝置上使用 Lookout for Vision 模型。
詳細資訊:在邊緣裝置上使用您的 Amazon Lookout for Vision 模型。
使用您的儀表板
您可以使用儀表板來取得所有專案的概觀,以及個別專案的概觀資訊。
詳細資訊:使用您的儀表板。
