Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Fehlerbehebung bei Stacks AWS OpsWorks
Wichtig
Der AWS OpsWorks Stacks Service hat am 26. Mai 2024 das Ende seiner Lebensdauer erreicht und wurde sowohl für neue als auch für bestehende Kunden deaktiviert. Wir empfehlen Kunden dringend, ihre Workloads so bald wie möglich auf andere Lösungen zu migrieren. Wenn Sie Fragen zur Migration haben, wenden Sie sich an das AWS -Support Team auf AWS re:POST
Dieser Abschnitt enthält einige häufig auftretende AWS OpsWorks Stacks-Probleme und deren Lösungen.
Themen
Die Instances eines Layers bestehen alle bei einem Elastic Load Balancing Health Check nicht
Es kann nicht mit einem Elastic Load Balancing Load Balancer kommuniziert werden
AWS OpsWorks Stacks-Sicherheitsgruppen können nicht gelöscht werden
Versehentlich wurde eine Stacks-Sicherheitsgruppe AWS OpsWorks gelöscht
Instances können nicht verwaltet werden
Problem: Eine Instance, die bisher verwaltbar war, lässt sich nicht mehr verwalten. In einigen Fällen können Protokolle eine Fehlermeldung wie die folgende anzeigen.
Aws::CharlieInstanceService::Errors::UnrecognizedClientException - The security token included in the request is invalid.
Ursache: Dies kann auftreten, wenn eine Ressource, von der die Instance abhängig ist, außerhalb von AWS OpsWorks bearbeitet oder gelöscht wurde. Nachfolgend finden Sie Beispiele für Ressourcenänderungen, die zu einem Kommunikationsabbruch mit der Instance führen.
-
Ein der Instance zugeordneter IAM-Benutzer oder eine IAM-Rolle wurde versehentlich außerhalb von AWS OpsWorks Stacks gelöscht. Dies führt zu einem Kommunikationsfehler zwischen dem AWS OpsWorks Agenten, der auf der Instance installiert ist, und dem AWS OpsWorks Stacks-Dienst. Der -Benutzer, der einer Instance zugeordnet ist, muss während der gesamten Instance-Lebensdauer vorhanden sein.
-
Das Bearbeiten von Volume- oder Speicherkonfigurationen, während eine Instance offline ist, kann dazu führen, dass die Instance nicht mehr verwaltbar ist.
-
Manuelles Hinzufügen von EC2 Instanzen zu einem ELB. AWS OpsWorks konfiguriert einen zugewiesenen Elastic Load Balancing Load Balancer jedes Mal neu, wenn eine Instance den Online-Status erreicht oder verlässt. AWS OpsWorks betrachtet nur Instances, von denen sie weiß, als gültige Mitglieder. Instances AWS OpsWorks, die außerhalb oder durch einen anderen Prozess hinzugefügt wurden, werden entfernt. Jede andere Instance wird ebenfalls entfernt.
Lösung: Löschen Sie keine IAM-Benutzer oder -Rollen, von denen Ihre Instanzen abhängen. Bearbeiten Sie (wenn möglich) die Volume- oder Speicherkonfigurationen nur, während die abhängigen Instances ausgeführt werden. Wird verwendet AWS OpsWorks , um die Load Balancer- oder EIP-Mitgliedschaften von Instances zu verwalten. AWS OpsWorks Um Probleme bei der Verwaltung registrierter Instances zu vermeiden, falls der Benutzer versehentlich gelöscht wird, fügen Sie bei der Registrierung einer Instance den --use-instance-profile Parameter zu Ihrem register Befehl hinzu, um stattdessen das integrierte Instanzprofil der Instanz zu verwenden.
Nach einer Chef-Ausführung starten die Instances nicht
Problem: Wenn in Chef 11.10 (oder einer älteren Version) Stacks für die Verwendung von benutzerdefinierten Rezeptbüchern konfiguriert sind, starten die Instances nach einer Chef-Ausführung mit Community-Rezeptbüchern nicht mehr. Die Protokollnachrichten besagen, dass die Rezepte nicht kompiliert ("Recipe Compile Error") oder geladen werden können (weil eine Abhängigkeit nicht gefunden wird).
Ursache: Vermutlich wird die vom Stack verwendete Chef-Version von den benutzerdefinierten oder Community-Rezeptbüchern nicht unterstützt. Bei einigen beliebten Community-Rezeptbüchern wie apt und build-essential sind Kompatibilitätsprobleme mit Chef 11.10 bekannt.
Lösung: Bei AWS OpsWorks Stacks-Stacks, bei denen die Einstellung Benutzerdefinierte Chef-Kochbücher verwenden aktiviert ist, müssen benutzerdefinierte Kochbücher oder Community-Kochbücher immer die Version von Chef unterstützen, die Ihr Stack verwendet. Legen Sie für die Community-Rezeptbücher eine Version fest (das heißt, Sie legen die Rezeptbuch-Versionsnummer auf eine bestimmte Version fest), die mit der Chef-Version kompatibel ist, die Sie in Ihren Stack-Einstellungen konfiguriert haben. Um eine unterstützte Version für Community-Rezeptbücher zu ermitteln, suchen Sie im Änderungsprotokoll nach einem Rezeptbuch, das nicht kompiliert werden konnte, und verwenden Sie nur die neueste Version des Rezeptbuchs, die von Ihrem Stack unterstützt wird. Um eine Rezeptbuchversion festzulegen, geben Sie im Repository des benutzerdefinierten Rezeptbuchs in der Berksfile-Datei die exakte Versionsnummer an. Beispiel, cookbook 'build-essential', '= 3.2.0'.
Die Instances eines Layers bestehen alle bei einem Elastic Load Balancing Health Check nicht
Problem: Sie fügen einen Elastic Load Balancing Load Balancer an eine App-Serverebene an, aber alle Instances bestehen die Integritätsprüfung nicht.
Ursache: Wenn Sie einen Elastic Load Balancing Load Balancer erstellen, müssen Sie den Ping-Pfad angeben, den der Load Balancer aufruft, um festzustellen, ob die Instance fehlerfrei ist. Stellen Sie sicher, dass der Ping-Pfad für die Anwendung geeignet ist. Der Standardwert lautet "/index.html". Falls die Anwendung den Wert index.html nicht enthält, müssen Sie einen entsprechenden Pfad angeben. Andernfalls schlägt die Zustandsprüfung fehl. Beispielsweise verwendet die in verwendete PHPApp Simple-Anwendung Erste Schritte mit Chef 11 Linux-Stacks nicht index.html; der entsprechende Ping-Pfad für diese Server ist /.
Lösung: Ändern Sie den Ping-Pfad für den Load Balancer. Weitere Informationen finden Sie unter Elastic Load Balancing
Es kann nicht mit einem Elastic Load Balancing Load Balancer kommuniziert werden
Problem: Sie erstellen einen Elastic Load Balancing Load Balancer und hängen ihn an eine App-Serverebene an. Wenn Sie jedoch auf den DNS-Namen oder die IP-Adresse des Load Balancers klicken, um die Anwendung auszuführen, erhalten Sie die folgende Fehlermeldung: „Der Remote-Server reagiert nicht“.
Ursache: Wenn Ihr Stack in einer Standard-VPC ausgeführt wird, müssen Sie beim Erstellen eines Elastic Load Balancing-Load Balancers in der Region eine Sicherheitsgruppe angeben. Die für den Dateneingang festgelegten Regeln der Sicherheitsgruppe müssen eingehenden Datenverkehr von Ihrer IP-Adresse zulassen. Wenn Sie default VPC security group (standardmäßige VPC-Sicherheitsgruppe) angeben, akzeptiert die Standardregel keinen eingehenden Datenverkehr.
Lösung: Ändern Sie die Dateneingangsregeln für die Sicherheitsgruppe, damit eingehender Datenverkehr von den entsprechenden IP-Adressen akzeptiert wird.
-
Klicken Sie im Navigationsbereich der EC2 Amazon-Konsole
auf Sicherheitsgruppen. -
Wählen Sie die Sicherheitsgruppe für den Load Balancer aus.
-
Klicken Sie auf Edit (Bearbeiten) auf der Registerkarte Inbound (Eingehend).
-
Fügen Sie eine Dateneingangsregel hinzu und legen Sie Source (Quelle) auf einen geeigneten CIDR-Wert fest.
Wenn Sie beispielsweise Anywhere (Beliebig) angeben, wird der CIDR-Wert auf 0.0.0.0/0 festgelegt, sodass der Load Balancer eingehenden Datenverkehr von einer beliebigen IP-Adresse akzeptiert.
Für eine importierte lokale Instance kann die Volume-Einrichtung nach einem Neustart nicht abgeschlossen werden
Problem: Sie starten eine EC2 Instance neu, die Sie in AWS OpsWorks Stacks importiert haben, und in der AWS OpsWorks Stacks-Konsole wird als Instance-Status „Fehlgeschlagen“ angezeigt. Dies kann bei Chef 11- oder Chef 12-Instances auftreten.
Ursache: AWS OpsWorks Stacks kann vermutlich im Rahmen der Einrichtung kein Volume für die Instance hinzufügen. Ein möglicher Grund ist, dass AWS OpsWorks
Stacks bei Ausführung des Befehls setup die Volume-Konfiguration der Instance überschreibt.
Lösung: Öffnen Sie die Seite Details für die Instance und überprüfen Sie die Volume-Konfiguration im Bereich Volumes. Beachten Sie, dass Sie die Volume-Konfiguration nur ändern können, wenn die Instance den Status stopped (angehalten) aufweist. Stellen Sie sicher, dass jedes Volume über einen definierten Mounting-Punkt und Namen verfügt. Vergewissern Sie sich, dass Sie in Ihrer Konfiguration in AWS OpsWorks Stacks den richtigen Mountpunkt angegeben haben, bevor Sie die Instance neu starten.
EBS-Volume wird nach einem Neustart nicht wieder zugeordnet
Problem: Sie verwenden die EC2 Amazon-Konsole, um ein Amazon EBS-Volume an eine Instance anzuhängen, aber wenn Sie die Instance neu starten, ist das Volume nicht mehr angehängt.
Ursache: AWS OpsWorks Stacks können nur die Amazon EBS-Volumes wieder anhängen, die ihm bekannt sind. Diese sind auf Folgendes beschränkt:
-
Volumes, die von Stacks erstellt wurden. AWS OpsWorks
-
Die Volumes von Ihrem Konto wurden explizit über die Seite Resources (Ressourcen) für einen Stack registriert.
Lösung: Verwalten Sie Ihre Amazon EBS-Volumes nur mithilfe der AWS OpsWorks Stacks-Konsole, API oder CLI. Wenn Sie eines der Amazon EBS-Volumes Ihres Kontos mit einem Stack verwenden möchten, verwenden Sie die Ressourcenseite des Stacks, um das Volume zu registrieren und es an eine Instance anzuhängen. Weitere Informationen finden Sie unter Ressourcenmanagement.
AWS OpsWorks
Stacks-Sicherheitsgruppen können nicht gelöscht werden
Problem: Nachdem Sie einen Stack gelöscht haben, bleiben eine Reihe von AWS OpsWorks Stacks-Sicherheitsgruppen übrig, die nicht gelöscht werden können.
Ursache: Die Sicherheitsgruppen müssen in einer bestimmten Reihenfolge gelöscht werden.
Lösung: Stellen Sie zunächst sicher, dass die Sicherheitsgruppen von keiner Instance verwendet werden. Anschließend löschen Sie die folgenden Sicherheitsgruppen, sofern vorhanden, in der folgenden Reihenfolge:
-
AWS OpsWorks - Blank-Server
-
OpsWorksAWS-Monitoring-Master-Server
-
OpsWorksAWS-DB-Master-Server
-
OpsWorksAWS-Memcached-Server
-
OpsWorksAWS-Benutzerdefinierter Server
-
OpsWorksAWS-NodeJS-App-Server
-
OpsWorksAWS-PHP-App-Server
-
OpsWorksAWS-Rails-App-Server
-
OpsWorksAWS-Webserver
-
AWS- OpsWorks -Standardserver
-
OpsWorksAWS-LB-Server
Versehentlich wurde eine Stacks-Sicherheitsgruppe AWS OpsWorks gelöscht
Problem: Sie haben eine der AWS OpsWorks Stacks-Sicherheitsgruppen gelöscht und müssen sie neu erstellen.
Ursache: Diese Sicherheitsgruppen werden meist aus Versehen gelöscht.
Lösung: Die neu erstellte Gruppe muss eine exakte Kopie des Originals einschließlich derselben Groß-/Kleinschreibung des Gruppennamens sein. Anstatt die Gruppe manuell neu zu erstellen, wird empfohlen, diese Schritte von AWS OpsWorks Stacks ausführen zu lassen. Erstellen Sie einfach einen neuen Stack in derselben AWS-Region — und VPC, falls vorhanden — und AWS OpsWorks Stacks erstellt automatisch alle integrierten Sicherheitsgruppen neu, einschließlich der gelöschten. Anschließend können Sie den Stack löschen, wenn Sie keine weitere Verwendung dafür haben. Die Sicherheitsgruppen bleiben erhalten.
Chef-Protokoll wird plötzlich beendet
Problem: Ein Chef-Protokoll wird plötzlich beendet und aus dem Ende des Protokolls geht nicht hervor, ob es sich um eine erfolgreiche Ausführung handelt. Es wird auch keine Ausnahme bzw. kein Stacktrace angezeigt.
Ursache: Dieses Verhalten wird in der Regel durch zu wenig Speicher verursacht.
Lösung: Erstellen Sie eine größere Instance und verwenden Sie den Agent-CLI-Befehl run_command, um die Rezepte erneut auszuführen. Weitere Informationen finden Sie unter Ausführen von Rezepten.
Rezeptbuch wird nicht aktualisiert
Problem: Sie haben Ihre Rezeptbücher aktualisiert, aber auf den Instances des Stacks werden immer noch die alten Rezepte ausgeführt.
Ursache: AWS OpsWorks Stacks speichert Kochbücher auf jeder Instanz im Cache und führt Rezepte aus dem Cache aus, nicht aus dem Repository. Wenn Sie eine neue Instanz starten, lädt AWS OpsWorks Stacks Ihre Kochbücher aus dem Repository in den Cache der Instanz herunter. Wenn Sie aber Ihre benutzerdefinierten Rezeptbücher häufig ändern, werden die Online-Instance-Caches von AWS OpsWorks Stacks nicht automatisch aktualisiert.
Lösung: Führen Sie den Befehl Update Cookbooks stack aus, um AWS OpsWorks Stacks explizit anzuweisen, die Kochbuch-Caches Ihrer Online-Instanzen zu aktualisieren.
Instances bleiben im Startstatus hängen
Problem: Wenn Sie eine Instance starten oder diese von der automatischen Reparatur automatisch neu gestartet wird, bleibt der Startvorgang im Status booting stehen.
Ursache: Ein möglicher Grund für dieses Problem ist die VPC-Konfiguration, einschließlich einer Standard-VPC. Instances müssen immer in der Lage sein, mit dem AWS OpsWorks Stacks-Service, Amazon S3 und den Paket-, Kochbuch- und App-Repositorys zu kommunizieren. Wenn Sie beispielsweise ein Standard-Gateway aus einer Standard-VPC entfernen, verlieren die Instances ihre Verbindung zum AWS OpsWorks Stacks-Service. Da AWS OpsWorks Stacks nicht mehr mit dem Instanzagenten kommunizieren kann, behandelt es die Instance als ausgefallen und repariert sie auto. Ohne eine Verbindung kann AWS OpsWorks Stacks jedoch keinen Instanzagenten auf der geheilten Instanz installieren. Ohne einen Agenten kann AWS OpsWorks Stacks die Setup-Rezepte auf der Instanz nicht ausführen, sodass der Startvorgang nicht über den Status „Booting“ hinaus fortgesetzt werden kann.
Lösung: Ändern Sie die VPC-Konfiguration so, dass Instances über die erforderliche Konnektivität verfügen.
Instances starten unerwartet neu
Problem: Eine gestoppte Instance startet unerwartet neu.
Ursache 1: Wenn Sie die auto Heilung für Ihre Instances aktiviert haben, führt AWS OpsWorks Stacks regelmäßig eine Zustandsprüfung der zugehörigen EC2 Amazon-Instances durch und startet alle fehlerhaften neu. Wenn Sie eine von AWS OpsWorks Stacks verwaltete Instance mithilfe der EC2 Amazon-Konsole, API oder CLI stoppen oder beenden, wird AWS OpsWorks Stacks nicht benachrichtigt. Stattdessen wird die gestoppte Instance als fehlerhaft erkannt und automatisch neu gestartet.
Lösung: Verwalten Sie Ihre Instances nur über die Konsole, die API oder die CLI von AWS OpsWorks Stacks. Wenn Sie AWS OpsWorks Stacks verwenden, um eine Instance zu stoppen oder zu löschen, wird sie nicht neu gestartet. Weitere Informationen erhalten Sie unter Manuelles Starten, Beenden und Neustarten von 24/7-Instances und AWS OpsWorks Stacks-Instances löschen.
Ursache 2: Instances können aus verschiedenen Gründen fehlerhaft sein. Wenn Sie Auto Healing aktiviert haben, startet AWS OpsWorks Stacks ausgefallene Instances automatisch neu.
Lösung: Dies ist ein normaler Vorgang. Sie müssen nichts tun, es sei denn, Sie möchten nicht, dass AWS OpsWorks Stacks ausgefallene Instances neu startet. In diesem Fall sollten Sie die automatische Reparatur deaktivieren.
opsworks-agent-Prozesse werden auf Instances ausgeführt
Problem: Auf den Instances werden mehrere opsworks-agent-Prozesse ausgeführt. Zum Beispiel:
aws 24543 0.0 1.3 172360 53332 ? S Feb24 0:29 opsworks-agent: master 24543
aws 24545 0.1 2.0 208932 79224 ? S Feb24 22:02 opsworks-agent: keep_alive of master 24543
aws 24557 0.0 2.0 209012 79412 ? S Feb24 8:04 opsworks-agent: statistics of master 24543
aws 24559 0.0 2.2 216604 86992 ? S Feb24 4:14 opsworks-agent: process_command of master 24Ursache: Dies sind reguläre Prozesse, die für eine normale Agent-Ausführung erforderlich sind. Sie führen Aufgaben wie das Verarbeiten von Bereitstellungen und das Senden von Keepalive-Nachrichten an den Service aus.
Lösung: Das ist ein normales Verhalten. Beenden Sie diese Prozesse nicht, denn das beeinträchtigt die Agent-Ausführung.
Unerwartete "execute_recipes"-Befehle
Problem: Der Bereich Logs (Protokolle) auf der Instance-Detailseite enthält unerwartete execute_recipes-Befehle. Unerwartete execute_recipes-Befehle können auch auf den Seiten Stack und Deployments (Bereitstellungen) angezeigt werden.
Ursache: Dieses Problem wird meist von geänderten Berechtigungen verursacht. Wenn Sie die SSH- oder Sudo-Berechtigungen eines Benutzers oder einer Gruppe ändern, wird AWS OpsWorks Stacks ausgeführt, um die Instanzen des Stacks execute_recipes zu aktualisieren, und löst außerdem ein Configure-Ereignis aus. Die execute_recipes-Befehle können außerdem auch dadurch verursacht werden, dass AWS OpsWorks
Stacks den Instance-Agent aktualisiert.
Lösung: Hierbei handelt es sich um einen normalen Vorgang, es sind keine Schritte erforderlich.
Um die von einem execute_recipes-Befehl ausgeführten Aktionen anzuzeigen, klicken Sie auf der Seite Deployments (Bereitstellungen) auf den Zeitstempel des Befehls. Dann wird die Detailseite des Befehls mit den wichtigsten ausgeführten Rezepten angezeigt. Beispielsweise ist die folgende Detailseite für einen execute_recipes-Befehl, der ssh_users zur Aktualisierung der SSH-Berechtigungen ausgeführt hat.
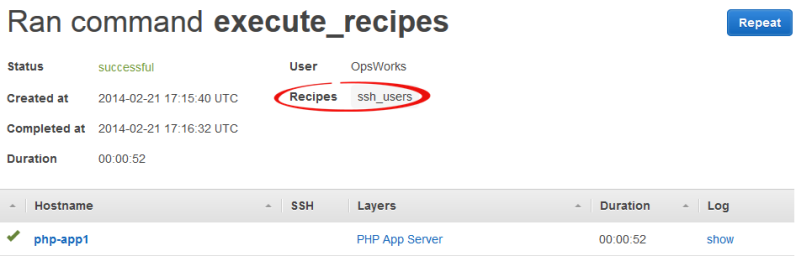
Zum Anzeigen aller Details klicken Sie auf show (Anzeigen) in der Spalte Log (Protokoll) des Befehls. Damit zeigen Sie das zugehörige Chef-Protokoll an. Suchen Sie im Protokoll nach. Run List AWS OpsWorks Rezepte für die Wartung von Stacks finden Sie unterOpsWorks Custom Run List. Beispielsweise sieht die Ausführungsliste für den im vorigen Screenshot abgebildeten execute_recipes-Befehl, die alle Rezepte anzeigt, die diesem Befehl zugeordnet sind, wie folgt aus.
[2014-02-21T17:16:30+00:00] INFO: OpsWorks Custom Run List: ["opsworks_stack_state_sync",
"ssh_users", "test_suite", "opsworks_cleanup"]