La instrucción EXPLAIN muestra el plan de ejecución lógico o distribuido de una instrucción SQL especificada, o valida la instrucción SQL. Puede generar los resultados en formato de texto o en formato de datos para representarlos en un gráfico.
nota
Puede ver representaciones gráficas de planes lógicos y distribuidos para sus consultas en la consola de Athena sin usar la sintaxis EXPLAIN. Para obtener más información, consulte Visualización de planes de ejecución para consultas SQL.
La instrucción EXPLAIN ANALYZE muestra el plan de ejecución distribuido de una instrucción SQL especificada y el costo computacional de cada operación en una consulta SQL. Puede generar los resultados en formato de texto o JSON.
Consideraciones y limitaciones
Las instrucciones EXPLAIN y EXPLAIN ANALYZE de Athena tienen las siguientes limitaciones.
-
Dado que las consultas
EXPLAINno escanean ningún dato, Athena no cobra por ellas. Sin embargo, como las consultasEXPLAINrealizan llamadas a AWS Glue para recuperar metadatos de la tabla, puede incurrir en cargos de Glue si las llamadas superan el límite de nivel gratuito de Glue. -
Como se ejecutan las consultas
EXPLAIN ANALYZE, analizan datos, de modo que Athena cobra en función de los datos escaneados. -
La información de filtrado de filas o celdas definida en Lake Formation y la información de estadísticas de consultas no se muestran en la salida de
EXPLAINyEXPLAIN ANALYZE.
Sintaxis de EXPLAIN
EXPLAIN [ (option[, ...]) ]statement
La opción puede ser una de las siguientes:
FORMAT { TEXT | GRAPHVIZ | JSON }
TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }Si no se especifica la opción FORMAT, la salida predeterminada es en formato TEXT. El tipo IO proporciona información sobre las tablas y esquemas que la consulta lee.
Sintaxis de EXPLAIN ANALYZE
Además de la salida incluida en EXPLAIN, la salida EXPLAIN
ANALYZE también incluye estadísticas de tiempo de ejecución de la consulta especificada, como el uso de CPU, el número de filas de entrada y el número de filas de salida.
EXPLAIN ANALYZE [ (option[, ...]) ]statement
La opción puede ser una de las siguientes:
FORMAT { TEXT | JSON }Si no se especifica la opción FORMAT, la salida predeterminada es en formato TEXT. Como todas las consultas para EXPLAIN ANALYZE son DISTRIBUTED, la opción TYPE no está disponible para EXPLAIN ANALYZE.
La instrucción puede ser una de las siguientes:
SELECT CREATE TABLE AS SELECT INSERT UNLOAD
Ejemplos de EXPLAIN
Los siguientes ejemplos de EXPLAIN avanzan de los más sencillos a los más complejos.
En el siguiente ejemplo, EXPLAIN muestra el plan de ejecución de una consulta SELECT en registros de Elastic Load Balancing. El formato se establece de forma predeterminada en la salida de texto.
EXPLAIN
SELECT
request_timestamp,
elb_name,
request_ip
FROM sampledb.elb_logs;Resultados
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULARPuede utilizar la consola de Athena para representar de manera gráfica un plan de consultas. Ingrese una instrucción SELECT como la siguiente en el editor de consultas de Athena y, a continuación, elija EXPLICAR.
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey Se abrirá la página Explain (Explicar) del editor de consultas de Athena y se mostrára un plan distribuido y un plan lógico para la consulta. En el siguiente gráfico se muestra el plan lógico para el ejemplo.
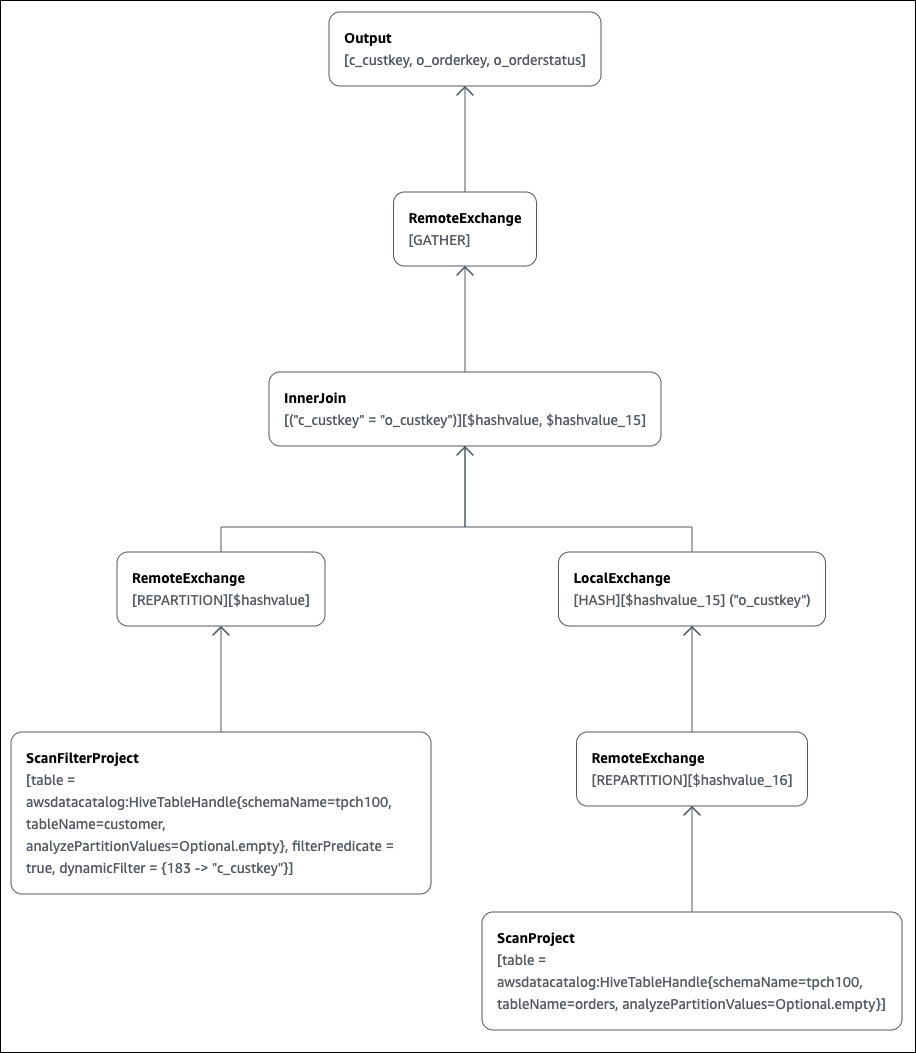
importante
Actualmente, es posible que algunos filtros de partición no estén visibles en el gráfico de árbol de operadores anidado, aunque Athena los aplique a la consulta. Para comprobar el efecto de dichos filtros, ejecute EXPLAIN o EXPLAIN
ANALYZE en la consulta y observe los resultados.
Para obtener más información sobre cómo usar las características de representación gráfica de planes de consulta en la consola de Athena, consulte Visualización de planes de ejecución para consultas SQL.
Puede utilizar la consola de Athena para representar de manera gráfica un plan de consultas. Ingrese una instrucción SELECT como la siguiente en el editor de consultas de Athena y, a continuación, elija EXPLICAR.
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey Se abrirá la página Explain (Explicar) del editor de consultas de Athena y se mostrára un plan distribuido y un plan lógico para la consulta. En el siguiente gráfico se muestra el plan lógico para el ejemplo.
importante
Actualmente, es posible que algunos filtros de partición no estén visibles en el gráfico de árbol de operadores anidado, aunque Athena los aplique a la consulta. Para comprobar el efecto de dichos filtros, ejecute EXPLAIN o EXPLAIN
ANALYZE en la consulta y observe los resultados.
Para obtener más información sobre cómo usar las características de representación gráfica de planes de consulta en la consola de Athena, consulte Visualización de planes de ejecución para consultas SQL.
Cuando se utiliza un predicado de filtrado en una clave particionada para consultar una tabla particionada, el motor de consultas aplica el predicado a la clave particionada para reducir la cantidad de datos leídos.
En el siguiente ejemplo se utiliza una consulta EXPLAIN para verificar la poda de partición para una consulta SELECT en una tabla particionada. Primero, una instrucción CREATE TABLE crea la tabla tpch100.orders_partitioned. La tabla está particionada en la columna o_orderdate.
CREATE TABLE `tpch100.orders_partitioned`(
`o_orderkey` int,
`o_custkey` int,
`o_orderstatus` string,
`o_totalprice` double,
`o_orderpriority` string,
`o_clerk` string,
`o_shippriority` int,
`o_comment` string)
PARTITIONED BY (
`o_orderdate` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amzn-s3-demo-bucket/<your_directory_path>/'La tabla tpch100.orders_partitioned tiene varias particiones en o_orderdate, como se muestra en el comando SHOW PARTITIONS.
SHOW PARTITIONS tpch100.orders_partitioned;
o_orderdate=1994
o_orderdate=2015
o_orderdate=1998
o_orderdate=1995
o_orderdate=1993
o_orderdate=1997
o_orderdate=1992
o_orderdate=1996La siguiente consulta EXPLAIN comprueba la poda de partición en la instrucción SELECT especificada.
EXPLAIN
SELECT
o_orderkey,
o_custkey,
o_orderdate
FROM tpch100.orders_partitioned
WHERE o_orderdate = '1995'Resultados
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAREl texto en negrita del resultado muestra que se aplicó el predicado o_orderdate =
'1995' en PARTITION_KEY.
La siguiente consulta EXPLAIN verifica el orden y el tipo de unión de la instrucción SELECT. Utilice una consulta como esta para examinar el uso de la memoria de consulta de modo que pueda reducir las posibilidades de obtener un error EXCEEDED_LOCAL_MEMORY_LIMIT.
EXPLAIN (TYPE DISTRIBUTED)
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey
WHERE c.c_custkey = 123Resultados
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARLa consulta de ejemplo se optimizó en una combinación cruzada para obtener un mejor rendimiento. Los resultados muestran que tpch100.orders se distribuirá como el tipo de distribución BROADCAST. Esto implica que la tabla tpch100.orders se distribuirá a todos los nodos que realizan la operación de unión. El tipo de distribución BROADCAST requerirá que todos los resultados filtrados de la tabla tpch100.orders se ajusten en la memoria de cada nodo que realiza la operación de unión.
Sin embargo, la tabla tpch100.customer es más pequeña que tpch100.orders. Dado que tpch100.customer requiere menos memoria, puede reescribir la consulta en BROADCAST
tpch100.customer en lugar de tpch100.orders. Esto reduce la posibilidad de que la consulta reciba el error EXCEEDED_LOCAL_MEMORY_LIMIT. Esta estrategia supone los siguientes puntos:
-
La
tpch100.customer.c_custkeyes única en la tablatpch100.customer. -
Existe una relación de asignación de uno a muchos entre
tpch100.customerytpch100.orders.
En el siguiente ejemplo, se muestra la consulta reescrita.
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.orders o
JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes.
ON c.c_custkey = o.o_custkey
WHERE c.c_custkey = 123Puede utilizar una consulta EXPLAIN para verificar la eficacia de los predicados de filtrado. Puede utilizar los resultados para eliminar predicados que no tengan ningún efecto, como en el ejemplo a continuación.
EXPLAIN
SELECT
c.c_name
FROM tpch100.customer c
WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT)
AND c.c_custkey BETWEEN 1000 AND 2000
AND c.c_custkey = 1500Resultados
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULAREl filterPredicate en los resultados muestra que el optimizador fusionó los tres predicados originales en dos predicados y cambió su orden de aplicación.
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
Como los resultados muestran que el predicado AND c.c_custkey BETWEEN
1000 AND 2000 no tiene ningún efecto, puede eliminar este predicado sin cambiar los resultados de la consulta.
Para obtener información sobre los términos utilizados en los resultados de las consultas EXPLAIN, consulte Descripción de los resultados de la instrucción EXPLAIN de Athena.
Ejemplos de EXPLAIN ANALYZE
En los siguientes ejemplos, se muestran consultas y salidas EXPLAIN ANALYZE.
En el siguiente ejemplo, EXPLAIN ANALYZE muestra el plan de ejecución y los costos computacionales de una consulta SELECT en los registros de CloudFront. El formato se establece de forma predeterminada en la salida de texto.
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10Resultados
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULAREn el siguiente ejemplo, se muestra el plan de ejecución y los costos computacionales de una consulta SELECT en los registros de CloudFront. En el ejemplo se especifica JSON como formato de salida.
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10Resultados
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}Recursos adicionales
Para obtener información adicional, consulte los siguientes recursos.
-
Descripción de los resultados de la instrucción EXPLAIN de Athena
-
Visualización de estadísticas y detalles de ejecución de consultas completadas
-
Documentación de Trino sobre
EXPLAIN -
Documentación de Trino sobre
EXPLAIN ANALYZE -
Optimice el rendimiento de las consultas federadas con EXPLAIN y EXPLAIN ANALYZE en Amazon Athena
en el Blog de macrodatos de AWS.
