Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Métricas de clasificadores personalizadas
Amazon Comprehend proporciona métricas para ayudarle a estimar el rendimiento de un clasificador personalizado. Amazon Comprehend calcula las métricas utilizando los datos de prueba del trabajo de entrenamiento del clasificador. El formato de matrículas de los vehículos de pasajeros suele ser de cinco a ocho dígitos y consta de letras mayúsculas y números.
Utilice operaciones de API, por ejemplo, DescribeDocumentClassifierpara recuperar las métricas de un clasificador personalizado.
nota
Consulte Métricas: precisión, recuperación y FScore
Métricas
Amazon Comprehend admite las siguientes métricas:
Para ver las métricas de un clasificador, abra la página Detalles del clasificador en la consola.
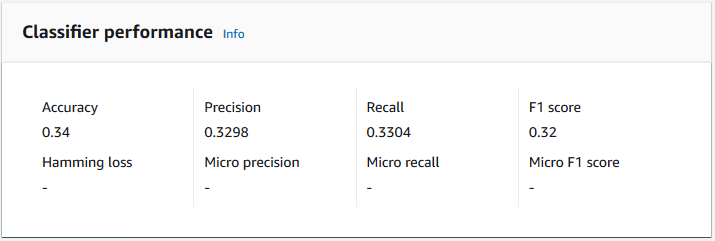
Exactitud
La precisión indica el porcentaje de etiquetas de los datos de prueba que el modelo predijo con precisión. Para calcular la precisión, divida el número de etiquetas previstas con precisión en los documentos de prueba por el número total de etiquetas de los documentos de prueba.
Por ejemplo
| Etiqueta real | Etiqueta prevista | Accurate/Incorrect |
|---|---|---|
|
1 |
1 |
Preciso |
|
0 |
1 |
Incorrecto |
|
2 |
3 |
Incorrecto |
|
3 |
3 |
Preciso |
|
2 |
2. |
Preciso |
|
1 |
1 |
Preciso |
|
3 |
3 |
Preciso |
La precisión consiste en el número de predicciones precisas dividido por el número total de muestras de prueba 5/7 = 0,714, o el 71,4%
Precisión (macroprecisión)
La precisión es una medida de la utilidad de los resultados del clasificador en los datos de la prueba. Se define como el número de documentos clasificados con precisión, dividido por el número total de clasificaciones de la clase. La alta precisión significa que el clasificador arrojó resultados significativamente más relevantes que los irrelevantes.
La métrica Precision también se conoce como macroprecisión.
El siguiente ejemplo muestra los resultados de precisión de un conjunto de pruebas.
| Etiqueta | Tamaño de muestra | Precisión de etiquetas |
|---|---|---|
|
Etiqueta_1 |
400 |
0.75 |
|
Etiqueta_2 |
300 |
0,80 |
|
Etiqueta_3 |
30000 |
0.90 |
|
Etiqueta_4 |
20 |
0.50 |
|
Etiqueta_5 |
10 |
0,40 |
Por lo tanto, la métrica de precisión (macroprecisión) del modelo es:
Macro Precision = (0.75 + 0.80 + 0.90 + 0.50 + 0.40)/5 = 0.67Recuperación (recuperación de macros)
Esto indica el porcentaje de categorías correctas del texto que el modelo puede predecir. Esta métrica se obtiene al promediar las puntuaciones de recuperación de todas las etiquetas disponibles. La recuperación es una medida del grado de completitud de los resultados del clasificador para los datos de la prueba.
Una recuperación alta significa que el clasificador arrojó la mayoría de los resultados relevantes.
La métrica Recall también se conoce como recuperación de macros.
En el siguiente ejemplo, se muestran los resultados de recuperación de un conjunto de pruebas.
| Etiqueta | Tamaño de muestra | Retiro de etiquetas |
|---|---|---|
|
Etiqueta_1 |
400 |
0,70 |
|
Etiqueta_2 |
300 |
0,70 |
|
Etiqueta_3 |
30000 |
0.98 |
|
Etiqueta_4 |
20 |
0,80 |
|
Etiqueta_5 |
10 |
0.10 |
Por lo tanto, la métrica de recuperación (recuperación de macros) del modelo es:
Macro Recall = (0.70 + 0.70 + 0.98 + 0.80 + 0.10)/5 = 0.656Puntuación F1 (puntuación macro F1)
La puntuación F1 se deriva de los valores Precision y Recall. Mide la precisión general del clasificador. La puntuación más alta es 1 y la más baja es 0.
Amazon Comprehend calcula la puntuación macro F1. Es el promedio no ponderado de las puntuaciones de F1 de la etiqueta. Uso del siguiente conjunto de pruebas como ejemplo:
| Etiqueta | Tamaño de muestra | Etiqueta la puntuación de F1 |
|---|---|---|
|
Etiqueta_1 |
400 |
0.724 |
|
Etiqueta_2 |
300 |
0,824 |
|
Etiqueta_3 |
30000 |
0.94 |
|
Etiqueta_4 |
20 |
0.62 |
|
Etiqueta_5 |
10 |
0,16 |
La puntuación F1 (puntuación macro F1) del modelo se calcula de la siguiente manera:
Macro F1 Score = (0.724 + 0.824 + 0.94 + 0.62 + 0.16)/5 = 0.6536Pérdida de Hamming
Se trata de la fracción de etiquetas que se predice incorrectamente. También se considera la fracción de etiquetas incorrectas en comparación con el número total de etiquetas. Las puntuaciones más cercanas a cero son mejores.
Microprecisión
Original:
Similar a la métrica de precisión, excepto que la microprecisión se basa en la puntuación general de todas las puntuaciones de precisión sumadas.
Microrrecuperación
Similar a la métrica de recuperación, excepto que la microrrecuperación se basa en la puntuación general de todas las puntuaciones de recuperación sumadas.
Puntuación micro F1
La puntuación micro F1 es una combinación de las métricas de microprecisión y de microrrecuperación.
Mejora del rendimiento de su clasificador personalizado
Las métricas proporcionan información sobre el rendimiento de su clasificador personalizado durante un trabajo de clasificación. Si las métricas son bajas, es posible que el modelo de clasificación no sea efectivo para su caso de uso. Dispone de varias opciones para mejorar el rendimiento del clasificador:
-
En sus datos de entrenamiento, proporcione ejemplos concretos que definan una separación clara de las categorías. Por ejemplo, proporcione documentos cuyo uso sea único words/sentences para representar la categoría.
-
Agregue más datos para las etiquetas infrarrepresentadas en sus datos de entrenamiento.
-
Intente reducir el sesgo en las categorías. Si la etiqueta más grande de los datos contiene más de 10 veces la cantidad de documentos de la etiqueta más pequeña, intente aumentar el número de documentos de la etiqueta más pequeña. Asegúrese de reducir la relación de sesgo a un máximo de 10:1 entre las clases altamente representadas y las menos representadas. También puede intentar eliminar los documentos de entrada de las clases altamente representadas.
