Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Anotación de archivos PDF
Antes de que puedas anotar tu entrenamiento PDFs en SageMaker AI Ground Truth, completa los siguientes requisitos previos:
-
Instale python3.8.x
-
Instale jq
-
Instale la CLI de AWS
Si utiliza la región us-east-1, puede omitir la instalación de la AWS CLI porque ya está instalada en su entorno Python. En este caso, se crea un entorno virtual para usar Python 3.8 en AWS Cloud9.
-
Configuración de sus credenciales de AWS
-
Cree una fuerza laboral privada de SageMaker AI Ground Truth para respaldar la anotación
Asegúrese de registrar el nombre del equipo de trabajo que elija en su nuevo personal privado, a medida que lo utilice durante la instalación.
Temas
Configuración del entorno
-
Si usa Windows, instale Cygwin
; si usa Linux o Mac, omita este paso. -
Descarga los artefactos de anotación de
. GitHub Descomprima el archivo. -
Desde la ventana del terminal, navegue hasta la carpeta descomprimida (-)amazon-comprehend-semi-structured. documents-annotation-tools-main
-
Esta carpeta incluye una selección de las
Makefilesque puede ejecutar para instalar dependencias, configurar un entorno virtual de Python e implementar los recursos necesarios. Revise el archivo readme para hacer su elección. -
La opción recomendada utiliza un solo comando para instalar todas las dependencias en un entorno virtual, crea la pila a partir de la plantilla y despliega la CloudFormation pila en la suya con una guía interactiva. Cuenta de AWS Use el siguiente comando:
make ready-and-deploy-guidedEste comando presenta un conjunto de opciones de configuración. Asegúrese de que la suya es correcta. Región de AWS Para todos los demás campos, puede aceptar los valores predeterminados o rellenar los valores personalizados. Si modificas el nombre de la CloudFormation pila, anótalo según lo necesites en los siguientes pasos.
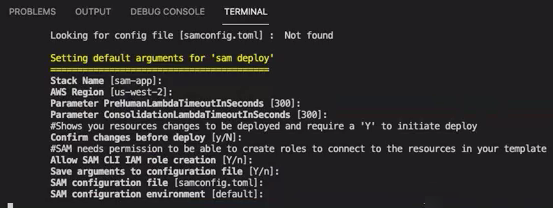
La CloudFormation pila crea y administra las AWS lambdas
, las funciones de AWS IAM y los cubos de AWS S3 necesarios para la herramienta de anotación. Puedes revisar cada uno de estos recursos en la página de detalles de la pila de la consola. CloudFormation
-
El comando le pide que inicie la implementación. CloudFormation crea todos los recursos de la región especificada.
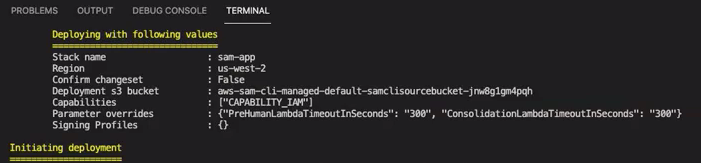
Cuando el estado de la CloudFormation pila pasa a ser de creación completa, los recursos están listos para usarse.
Carga de un PDF en un bucket de S3
En la sección Configuración, implementaste una CloudFormation pila que crea un bucket de S3 llamado comprehend-semi-structured-documents-$ {}. AWS::Region}-${AWS::AccountId Ahora puede cargar sus documentos PDF de origen en este bucket.
nota
Este bucket contiene los datos necesarios para su trabajo de etiquetado. La política de roles de ejecución de Lambda otorga permiso a la función de Lambda para acceder a este bucket.
Puedes encontrar el nombre del bucket de S3 en los detalles de la CloudFormation pila con la tecla «SemiStructuredDocumentsS3Bucket».
-
En el bucket de S3, cree una carpeta nueva. Asigne el nombre “src” a esta nueva carpeta.
-
Añada sus archivos PDF fuente a su carpeta “src”. En un paso posterior, anotará estos archivos para entrenar su reconocedor.
-
(Opcional) Este es un ejemplo de AWS CLI que puede usar para cargar sus documentos fuente desde un directorio local a un bucket de S3:
aws s3 cp --recursivelocal-path-to-your-source-docss3://deploy-guided/src/O bien, con su región e ID de cuenta:
aws s3 cp --recursivelocal-path-to-your-source-docss3://deploy-guided-Region-AccountID/src/ Ahora tienes una plantilla privada de SageMaker AI Ground Truth y has subido tus archivos fuente al bucket de S3, deploy-guided/src/; estás listo para empezar a anotar.
Creación de un trabajo de anotación
El script comprehend-ssie-annotation-tool-cli.py del bin directorio es un comando contenedor simple que agiliza la creación de un trabajo de etiquetado de SageMaker AI Ground Truth. El script de Python lee los documentos fuente del bucket de S3 y crea el correspondiente archivo de manifiesto de una sola página con un documento fuente por línea. A continuación, el script crea un trabajo de etiquetado, que requiere el archivo de manifiesto como entrada.
El script de Python usa el depósito y la CloudFormation pila de S3 que configuraste en la sección Configuración. Los parámetros de entrada necesarios para el script incluyen:
-
input-s3-path: Uri de S3 de los documentos fuente que cargó en su bucket de S3. Por ejemplo:
s3://deploy-guided/src/. También puede añadir su región y el ID de cuenta a esta ruta. Por ejemplo:s3://deploy-guided-Region-AccountID/src/. -
cfn-name: el nombre de la CloudFormation pila. Si usó el valor predeterminado para el nombre de la pila, su nombre cfn-name es sam-app.
-
work-team-name: El nombre de la fuerza laboral que creaste cuando creaste la fuerza laboral privada en SageMaker AI Ground Truth.
-
job-name-prefix: El prefijo para el trabajo de etiquetado de SageMaker AI Ground Truth. Tenga en cuenta que hay un límite de 29 caracteres para este campo. Se añade una marca de tiempo a este valor. Por ejemplo:
my-job-name-20210902T232116. -
tipos de entidad: las entidades que desea utilizar durante su trabajo de etiquetado, separadas por comas. Esta lista debe incluir todas las entidades que quiera anotar en su conjunto de datos de entrenamiento. El trabajo de etiquetado Ground Truth muestra solo estas entidades para que los anotadores etiqueten el contenido en los documentos PDF.
Para ver los argumentos adicionales que admite el script, utilice la opción -h para mostrar el contenido de ayuda.
Ejecute el siguiente script con los parámetros de entrada tal y como se describe en la lista anterior.
python bin/comprehend-ssie-annotation-tool-cli.py \ --input-s3-path s3://deploy-guided-Region-AccountID/src/ \ --cfn-namesam-app\ --work-team-namemy-work-team-name\ --regionus-east-1\ --job-name-prefixmy-job-name-20210902T232116\ --entity-types "EntityA,EntityB,EntityC" \ --annotator-metadata "key=info,value=sample,key=Due Date,value=12/12/2021"El script produce la siguiente salida:
Downloaded files to temp local directory /tmp/a1dc0c47-0f8c-42eb-9033-74a988ccc5aa Deleted downloaded temp files from /tmp/a1dc0c47-0f8c-42eb-9033-74a988ccc5aa Uploaded input manifest file to s3://comprehend-semi-structured-documents-us-west-2-123456789012/input-manifest/my-job-name-20220203-labeling-job-20220203T183118.manifest Uploaded schema file to s3://comprehend-semi-structured-documents-us-west-2-123456789012/comprehend-semi-structured-docs-ui-template/my-job-name-20220203-labeling-job-20220203T183118/ui-template/schema.json Uploaded template UI to s3://comprehend-semi-structured-documents-us-west-2-123456789012/comprehend-semi-structured-docs-ui-template/my-job-name-20220203-labeling-job-20220203T183118/ui-template/template-2021-04-15.liquid Sagemaker GroundTruth Labeling Job submitted: arn:aws:sagemaker:us-west-2:123456789012:labeling-job/my-job-name-20220203-labeling-job-20220203t183118 (amazon-comprehend-semi-structured-documents-annotation-tools-main) user@3c063014d632 amazon-comprehend-semi-structured-documents-annotation-tools-main %
Anotando con SageMaker AI Ground Truth
Ahora que ha configurado los recursos necesarios y ha creado un trabajo de etiquetado, puede iniciar sesión en el portal de etiquetado y hacer anotaciones. PDFs
-
Inicie sesión en la consola de SageMaker IA
mediante los navegadores web Chrome o Firefox. -
Seleccione Etiquetado de personal y elija Privado.
-
En Resumen de personal privado, selecciona la URL de inicio de sesión del portal de etiquetado que creó con su personal privado. Inicie sesión con las credenciales correspondientes.
Si no ve ningún trabajo en la lista, no se preocupe, la actualización puede tardar un tiempo en función de la cantidad de archivos que haya subido para su anotación.
-
Seleccione el trabajo y, en la esquina superior derecha, seleccione Comenzar a trabajar para abrir la pantalla de anotaciones.
Verá uno de sus documentos abierto en la pantalla de anotaciones y, encima, los tipos de entidades que proporcionó durante la configuración. A la derecha de los tipos de entidad, hay una flecha que puede usar para navegar por los documentos.
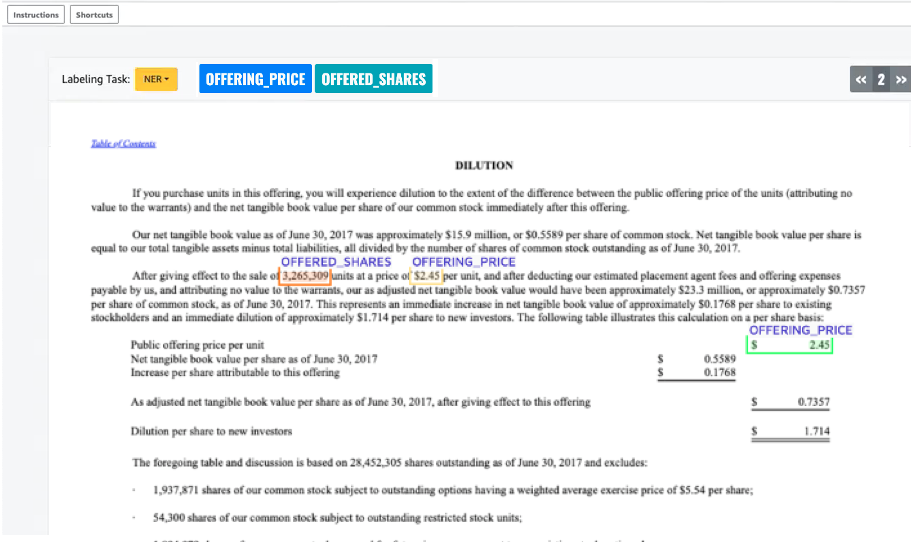
Anote el documento abierto. También puede eliminar, deshacer o etiquetar automáticamente las anotaciones en cada documento; estas opciones están disponibles en el panel derecho de la herramienta de anotación.
Para usar el etiquetado automático, anote una instancia de una de sus entidades; todas las demás instancias de esa palabra específica se anotarán automáticamente con ese tipo de entidad.
Cuando haya terminado, seleccione Enviar en la parte inferior derecha y, a continuación, utilice las flechas de navegación para pasar al siguiente documento. Repite esto hasta que hayas anotado todas tus. PDFs
Tras anotar todos los documentos de entrenamiento, podrá encontrar las anotaciones en formato JSON en el bucket de Amazon S3 en esta ubicación:
/output/your labeling job name/annotations/
La carpeta de salida también contiene un archivo de manifiesto de salida, en el que se enumeran todas las anotaciones de los documentos de entrenamiento. Puede encontrar el archivo de manifiesto de salida en la siguiente ubicación.
/output/your labeling job name/manifests/
