Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Politique de dimensionnement basée sur Amazon SQS
Important
Les informations et étapes suivantes vous montrent comment calculer le backlog de file d'attente Amazon SQS par instance à l'aide de l'attribut ApproximateNumberOfMessages queue avant de le publier sous forme de métrique personnalisée sur. CloudWatch Cependant, vous pouvez désormais réduire les coûts et les efforts consacrés à la publication de votre propre métrique en utilisant une expression mathématique appliquée à une métrique. Pour de plus amples informations, veuillez consulter Création d'une politique de dimensionnement pour le suivi des cibles à l'aide de mathématiques métriques.
Vous pouvez redimensionner votre groupe Auto Scaling en fonction des modifications de la charge du système dans une file d'attente Amazon Simple Queue Service (Amazon SQS). Pour en savoir plus sur la façon dont vous pouvez utiliser Amazon SQS, veuillez consulter le Guide du développeur Amazon Simple Queue Service.
Il existe des scénarios dans lesquels vous pourriez envisager la mise à l'échelle en réponse à une activité dans une file d'attente Amazon SQS. Supposons par exemple que vous disposez d'une application web qui permet aux utilisateurs de charger des images et de les utiliser en ligne. Dans ce scénario, chaque image doit être codée et redimensionnée avant de pouvoir être publiée. L'application s'exécute sur des instances EC2 dans un groupe Auto Scaling et elle est configurée pour gérer les taux de chargement classiques. Les instances non saines sont résiliées et remplacées pour maintenir des niveaux d'instance actuels à tout moment. L'application place les données bitmap brutes des images dans une file d'attente SQS afin qu'elles soient traitées. Elle traite les images, puis publie les images traitées à un emplacement où elles peuvent être affichées par les utilisateurs. L'architecture de ce scénario fonctionne correctement si le nombre de chargements d'images ne varie pas au fil du temps. En revanche, si le nombre de chargements varie au fil du temps, vous pouvez envisager d'utiliser la mise à l'échelle dynamique pour mettre à l'échelle la capacité de votre groupe Auto Scaling.
Table des matières
Utiliser un suivi de la cible avec la métrique appropriée
Si vous utilisez une politique de suivi des objectifs et d'échelonnement basée sur une métrique de file d'attente Amazon SQS personnalisée, la mise à l'échelle dynamique peut s'adapter plus efficacement à la courbe de la demande de votre application. Pour de plus amples informations sur le choix des métriques pour le suivi de la cible, veuillez consulter Choisissez métriques.
Le problème lié à l'utilisation d'une métrique CloudWatch Amazon SQS, comme ApproximateNumberOfMessagesVisible pour le suivi des cibles, est que le nombre de messages dans la file d'attente peut ne pas changer proportionnellement à la taille du groupe Auto Scaling qui traite les messages de la file d'attente. En effet, le nombre de messages dans votre file d'attente SQS ne définit pas uniquement le nombre d'instances nécessaires. Le nombre d'instances du groupe Auto Scaling peut être dicté par plusieurs facteurs, y compris le temps nécessaire pour traiter un message et la durée de latence acceptable (délai de file d'attente).
La solution consiste à utiliser une métrique d'éléments en attente par instance avec la valeur cible constituant les éléments en attente acceptables par instance à conserver. Vous pouvez calculer ces valeurs comme suit :
-
Éléments en attente par instance : pour calculer les éléments en attente par instance, commencez avec l'attribut de file d'attente
ApproximateNumberOfMessagespour déterminer la longueur de la file d'attente SQS (nombre de messages disponibles dans cette file d'attente). Divisez ce nombre par la capacité d'exécution du parc, ce qui correspond dans le cas d'un groupe Auto Scaling au nombre d'instances dans l'étatInService, pour obtenir les éléments en attente par instance. -
Éléments en attente acceptables par instance : pour calculer votre valeur cible, commencez par déterminer ce que votre application peut accepter en termes de latence. Prenez ensuite la valeur de latence acceptable et divisez-la par le temps moyen nécessaire à une instance EC2 pour traiter un message.
Par exemple, disons que vous avez actuellement un groupe Auto Scaling avec 10 instances et le nombre de messages visibles dans la file d'attente (ApproximateNumberOfMessages) s'élève à 1500. Si le temps de traitement moyen est de 0,1 seconde pour chaque message et si la plus grande latence acceptable est de 10 secondes, alors les éléments en attente acceptables par instance sont de 10/0,1, ce qui équivaut à 100 messages. Cela signifie que 100 est la valeur cible pour votre politique de suivi des objectifs et d'échelonnement. Lorsque les éléments en attente par instance atteignent la valeur cible, une diminution se produit. Si les éléments en attente par instance sont actuellement à 150 messages (1500 messages / 10 instances), votre groupe augmente de cinq instances pour maintenir la proportion de la valeur cible.
Les procédures suivantes montrent comment publier la métrique personnalisée et créer la politique de suivi des objectifs et d'échelonnement qui configure la mise à l'échelle du groupe Auto Scaling en fonction de ces calculs.
Important
N'oubliez pas que pour réduire les coûts, vous pouvez utiliser une expression mathématique appliquée à une métrique. Pour de plus amples informations, veuillez consulter Création d'une politique de dimensionnement pour le suivi des cibles à l'aide de mathématiques métriques.
Il existe trois parties principales pour cette configuration :
-
Un groupe Auto Scaling pour gérer les instances EC2 afin de traiter les messages d'une file d'attente SQS.
-
Une métrique personnalisée à envoyer à Amazon CloudWatch qui mesure le nombre de messages dans la file d'attente par instance EC2 du groupe Auto Scaling.
-
Une politique de suivi des cibles qui configure votre groupe Auto Scaling pour qu'il évolue en fonction de la métrique personnalisée et d'une valeur cible définie. CloudWatch les alarmes invoquent la politique de dimensionnement.
Le graphique suivant illustre l'architecture de cette configuration.
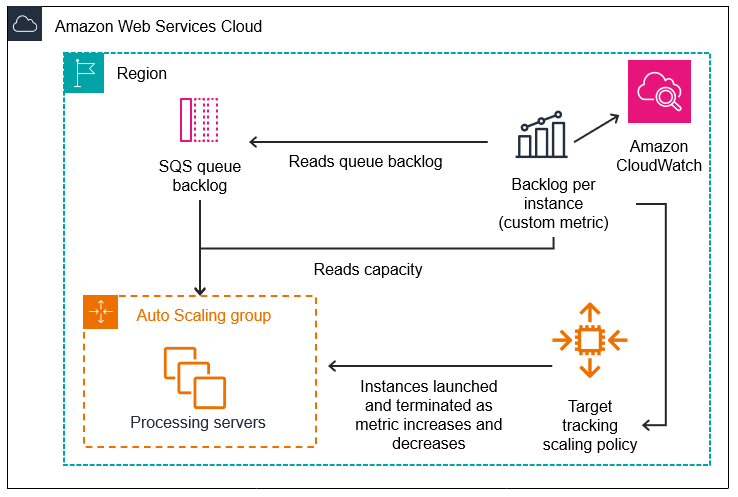
Limitations
Vous devez utiliser le AWS CLI ou un SDK pour publier votre métrique personnalisée sur. CloudWatch Vous pouvez ensuite surveiller votre métrique à l'aide du AWS Management Console.
Dans les sections suivantes, vous utilisez le AWS CLI pour les tâches que vous devez effectuer. Par exemple, pour obtenir des données métriques reflétant l'utilisation actuelle de la file d'attente, vous devez utiliser la get-queue-attributes
Protection contre la mise à l'échelle horizontale d'instance et Amazon SQS
Les messages qui n'ont pas été traités au moment de la résiliation d'une instance sont renvoyés à la file d'attente SQS où ils peuvent être traités par une autre instance qui est encore en cours d'exécution. Pour les applications dans lesquelles des tâches longues sont exécutées, vous pouvez éventuellement utiliser la protection contre la mise à l'échelle horizontale d'instance pour contrôler les processus Worker de file d'attente qui sont résiliés lorsque votre groupe Auto Scaling est mis à l'échelle.
Le pseudocode suivant illustre une façon de protéger les processus Worker de longue durée pilotés par la file d'attente contre la résiliation de mise à l'échelle horizontale.
while (true) { SetInstanceProtection(False); Work = GetNextWorkUnit(); SetInstanceProtection(True); ProcessWorkUnit(Work); SetInstanceProtection(False); }
Pour de plus amples informations, veuillez consulter Concevez vos applications pour gérer avec élégance la résiliation des instances.
