Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d’une application de maintenance planifiée de la base de données
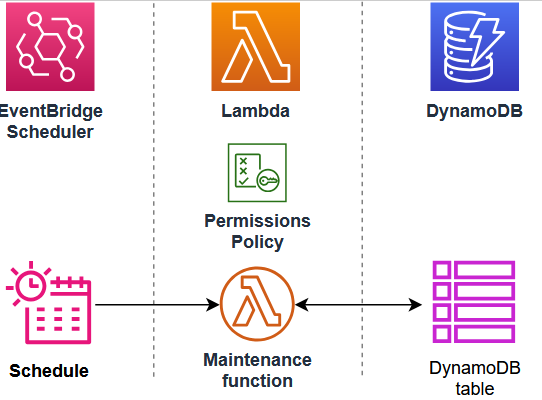
Vous pouvez l'utiliser AWS Lambda pour remplacer les processus planifiés tels que les sauvegardes automatisées du système, les conversions de fichiers et les tâches de maintenance. Dans cet exemple, vous créez une application sans serveur qui effectue une maintenance planifiée régulière sur une table DynamoDB en supprimant les anciennes entrées. L'application utilise EventBridge Scheduler pour appeler une fonction Lambda selon un calendrier cron. Lorsqu’elle est invoquée, la fonction rechercher dans la table pour les éléments datant de plus d’un an et les supprime. La fonction enregistre chaque élément supprimé dans CloudWatch Logs.
Pour implémenter cet exemple, créez d’abord une table DynamoDB et remplissez-la avec des données de test que votre fonction doit interroger. Créez ensuite une fonction Lambda Python avec un déclencheur EventBridge Scheduler et un rôle d'exécution IAM qui autorise la fonction à lire et à supprimer des éléments de votre table.
Astuce
Si vous utilisez Lambda pour la première fois, nous vous recommandons de suivre le tutoriel Création de votre première fonction Lambda avant de créer cet exemple d’application.
Vous pouvez déployer votre application manuellement en créant et en configurant des ressources à l'aide du AWS Management Console. Vous pouvez également déployer l'application en utilisant le AWS Serverless Application Model (AWS SAM). AWS SAM est un outil d'infrastructure en tant que code (IaC). Avec l’IaC, vous ne créez pas de ressources manuellement, mais vous les définissez dans le code, puis vous les déployez automatiquement.
Si vous souhaitez en savoir plus sur l’utilisation de Lambda avec l’IaC avant de déployer cet exemple d’application, consultez Utilisation de Lambda avec infrastructure en tant que code (IaC).
Conditions préalables
Avant de créer l’exemple d’application, assurez-vous que les outils et programmes de ligne de commande requis sont installés.
-
Python
Pour remplir la table DynamoDB que vous créez pour tester votre application, cet exemple utilise un script Python et un fichier CSV pour écrire des données dans la table. Assurez-vous que Python 3.8 ou version ultérieure est installé sur votre machine.
-
AWS SAM INTERFACE DE LIGNE DE COMMANDE (CLI)
Si vous souhaitez créer la table DynamoDB et déployer l'exemple d'application à l' AWS SAM aide, vous devez installer la CLI. AWS SAM Suivez les instructions d’installation dans le Guise de l’utilisateur AWS SAM .
-
AWS CLI
Pour utiliser le script Python fourni pour remplir votre table de test, vous devez avoir installé et configuré l’ AWS CLI. Cela est dû au fait que le script utilise le AWS SDK pour Python (Boto3), qui doit accéder à vos informations d'identification Gestion des identités et des accès AWS (IAM). Vous devez également l' AWS CLI installer pour déployer des ressources à l'aide de AWS SAM. Installez la CLI en suivant les instructions d’installation du Guide de l’utilisateur AWS Command Line Interface .
-
Docker
Pour déployer l'application à l'aide de Docker AWS SAM, vous devez également être installé sur votre machine de compilation. Suivez les instructions dans Install Docker Engine
sur le site Web de documentation de Docker.
Téléchargement des exemples de fichiers d’application
Pour créer la base de données d’exemple et l’application de maintenance planifiée, vous devez créer les fichiers suivants dans le répertoire de votre projet :
Exemples de fichiers de base de données
-
template.yaml- un AWS SAM modèle que vous pouvez utiliser pour créer la table DynamoDB -
sample_data.csv: un fichier CSV contenant des exemples de données à charger dans votre tableau -
load_sample_data.py: un script Python qui écrit les données du fichier CSV dans le tableau
Scheduled-maintenance fichiers d'application
-
lambda_function.py: le code de fonction Python de la fonction Lambda qui effectue la maintenance de la base de données -
requirements.txt: un fichier manifeste définissant les dépendances requises par le code de votre fonction Python -
template.yaml- un AWS SAM modèle que vous pouvez utiliser pour déployer l'application
Fichier de test
-
test_app.py: un script Python qui scanne la table et confirme le bon fonctionnement de votre fonction en affichant tous les enregistrements datant de plus d’un an
Développez les sections suivantes pour afficher le code et pour en savoir plus sur le rôle de chaque fichier dans la création et le test de votre application. Pour créer les fichiers sur votre ordinateur local, copiez et collez le code ci-dessous.
Copiez et collez le code suivant dans un fichier nommé template.yaml.
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: SAM Template for DynamoDB Table with Order_number as Partition Key and Date as Sort Key Resources: MyDynamoDBTable: Type: AWS::DynamoDB::Table DeletionPolicy: Retain UpdateReplacePolicy: Retain Properties: TableName: MyOrderTable BillingMode: PAY_PER_REQUEST AttributeDefinitions: - AttributeName: Order_number AttributeType: S - AttributeName: Date AttributeType: S KeySchema: - AttributeName: Order_number KeyType: HASH - AttributeName: Date KeyType: RANGE SSESpecification: SSEEnabled: true GlobalSecondaryIndexes: - IndexName: Date-index KeySchema: - AttributeName: Date KeyType: HASH Projection: ProjectionType: ALL PointInTimeRecoverySpecification: PointInTimeRecoveryEnabled: true Outputs: TableName: Description: DynamoDB Table Name Value: !Ref MyDynamoDBTable TableArn: Description: DynamoDB Table ARN Value: !GetAtt MyDynamoDBTable.Arn
Note
AWS SAM les modèles utilisent une convention de dénomination standard detemplate.yaml. Dans cet exemple, vous disposez de deux fichiers modèles : l’un pour créer la base de données d’exemple et l’autre pour créer l’application elle-même. Enregistrez-les dans des sous-répertoires distincts dans votre dossier de projet.
Ce AWS SAM modèle définit la ressource de table DynamoDB que vous créez pour tester votre application. La table utilise une clé primaire Order_number avec une clé de tri Date. Pour que votre fonction Lambda puisse rechercher des éléments directement par date, nous définissons également un index secondaire global nommé Date-index.
Pour en savoir plus sur la création et la configuration d’une table DynamoDB à l’aide de cette ressource AWS::DynamoDB::Table, consultez AWS::DynamoDB::Table dans le Guide de l’utilisateur AWS CloudFormation .
Copiez et collez le code suivant dans un fichier nommé sample_data.csv.
Date,Order_number,CustomerName,ProductID,Quantity,TotalAmount 2023-09-01,ORD001,Alejandro Rosalez,PROD123,2,199.98 2023-09-01,ORD002,Akua Mansa,PROD456,1,49.99 2023-09-02,ORD003,Ana Carolina Silva,PROD789,3,149.97 2023-09-03,ORD004,Arnav Desai,PROD123,1,99.99 2023-10-01,ORD005,Carlos Salazar,PROD456,2,99.98 2023-10-02,ORD006,Diego Ramirez,PROD789,1,49.99 2023-10-03,ORD007,Efua Owusu,PROD123,4,399.96 2023-10-04,ORD008,John Stiles,PROD456,2,99.98 2023-10-05,ORD009,Jorge Souza,PROD789,3,149.97 2023-10-06,ORD010,Kwaku Mensah,PROD123,1,99.99 2023-11-01,ORD011,Li Juan,PROD456,5,249.95 2023-11-02,ORD012,Marcia Oliveria,PROD789,2,99.98 2023-11-03,ORD013,Maria Garcia,PROD123,3,299.97 2023-11-04,ORD014,Martha Rivera,PROD456,1,49.99 2023-11-05,ORD015,Mary Major,PROD789,4,199.96 2023-12-01,ORD016,Mateo Jackson,PROD123,2,199.99 2023-12-02,ORD017,Nikki Wolf,PROD456,3,149.97 2023-12-03,ORD018,Pat Candella,PROD789,1,49.99 2023-12-04,ORD019,Paulo Santos,PROD123,5,499.95 2023-12-05,ORD020,Richard Roe,PROD456,2,99.98 2024-01-01,ORD021,Saanvi Sarkar,PROD789,3,149.97 2024-01-02,ORD022,Shirley Rodriguez,PROD123,1,99.99 2024-01-03,ORD023,Sofia Martinez,PROD456,4,199.96 2024-01-04,ORD024,Terry Whitlock,PROD789,2,99.98 2024-01-05,ORD025,Wang Xiulan,PROD123,3,299.97
Ce fichier contient des exemples de données de test à utiliser dans votre table DynamoDB au format CSV (valeurs séparées par des virgules) standard.
Copiez et collez le code suivant dans un fichier nommé load_sample_data.py.
import boto3 import csv from decimal import Decimal # Initialize the DynamoDB client dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('MyOrderTable') print("DDB client initialized.") def load_data_from_csv(filename): with open(filename, 'r') as file: csv_reader = csv.DictReader(file) for row in csv_reader: item = { 'Order_number': row['Order_number'], 'Date': row['Date'], 'CustomerName': row['CustomerName'], 'ProductID': row['ProductID'], 'Quantity': int(row['Quantity']), 'TotalAmount': Decimal(str(row['TotalAmount'])) } table.put_item(Item=item) print(f"Added item: {item['Order_number']} - {item['Date']}") if __name__ == "__main__": load_data_from_csv('sample_data.csv') print("Data loading completed.")
Ce script Python utilise d'abord le AWS SDK pour Python (Boto3) pour créer une connexion à votre table DynamoDB. Il effectue ensuite une itération sur chaque ligne du fichier CSV de données d’exemple, crée un élément à partir de cette ligne et écrit l’élément dans la table DynamoDB à l’aide du kit SDK boto3.
Copiez et collez le code suivant dans un fichier nommé lambda_function.py.
import boto3 from datetime import datetime, timedelta from boto3.dynamodb.conditions import Key, Attr import logging logger = logging.getLogger() logger.setLevel("INFO") def lambda_handler(event, context): # Initialize the DynamoDB client dynamodb = boto3.resource('dynamodb') # Specify the table name table_name = 'MyOrderTable' table = dynamodb.Table(table_name) # Get today's date today = datetime.now() # Calculate the date one year ago one_year_ago = (today - timedelta(days=365)).strftime('%Y-%m-%d') # Scan the table using a global secondary index response = table.scan( IndexName='Date-index', FilterExpression='#date < :one_year_ago', ExpressionAttributeNames={ '#date': 'Date' }, ExpressionAttributeValues={ ':one_year_ago': one_year_ago } ) # Delete old items with table.batch_writer() as batch: for item in response['Items']: Order_number = item['Order_number'] batch.delete_item( Key={ 'Order_number': Order_number, 'Date': item['Date'] } ) logger.info(f'deleted order number {Order_number}') # Check if there are more items to scan while 'LastEvaluatedKey' in response: response = table.scan( IndexName='DateIndex', FilterExpression='#date < :one_year_ago', ExpressionAttributeNames={ '#date': 'Date' }, ExpressionAttributeValues={ ':one_year_ago': one_year_ago }, ExclusiveStartKey=response['LastEvaluatedKey'] ) # Delete old items with table.batch_writer() as batch: for item in response['Items']: batch.delete_item( Key={ 'Order_number': item['Order_number'], 'Date': item['Date'] } ) return { 'statusCode': 200, 'body': 'Cleanup completed successfully' }
Le code de la fonction Python contient la fonction de gestion (lambda_handler) que Lambda exécute lorsque votre fonction est appelée.
Lorsque la fonction est invoquée par le EventBridge planificateur, il utilise le AWS SDK pour Python (Boto3) pour créer une connexion à la table DynamoDB sur laquelle la tâche de maintenance planifiée doit être effectuée. Il utilise ensuite la bibliothèque Python datetime pour calculer la date d’il y a un an, avant de rechercher dans la table les éléments plus anciens et de les supprimer.
Notez que les réponses issues des opérations de requête et d’analyse DynamoDB sont limitées à une taille d’au maximum 1 Mo. Si la réponse est supérieure à 1 Mo, DynamoDB pagine les données et renvoie un élément LastEvaluatedKey dans la réponse. Pour garantir que notre fonction traite tous les enregistrements de la table, nous vérifions la présence de cette clé et continuons à analyser la table à partir de la dernière position évaluée jusqu’à ce que toute la table ait été analysée.
Copiez et collez le code suivant dans un fichier nommé requirements.txt.
boto3
Dans cet exemple, le code de votre fonction n’a qu’une seule dépendance qui ne fait pas partie de la bibliothèque Python standard : le kit SDK pour Python (Boto3) que la fonction utilise pour analyser et supprimer des éléments de la table DynamoDB.
Note
Une version du kit SDK pour Python (Boto3) est incluse dans l’environnement d’exécution Lambda, de sorte que votre code s’exécute sans ajouter Boto3 au package de déploiement de votre fonction. Toutefois, pour garder le contrôle total des dépendances de votre fonction et éviter d’éventuels problèmes de désalignement de version, la bonne pratique pour Python consiste à inclure toutes les dépendances de fonction dans le package de déploiement de votre fonction. Pour en savoir plus, consultez Dépendances d’exécution dans Python.
Copiez et collez le code suivant dans un fichier nommé template.yaml.
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: SAM Template for Lambda function and EventBridge Scheduler rule Resources: MyLambdaFunction: Type: AWS::Serverless::Function Properties: FunctionName: ScheduledDBMaintenance CodeUri: ./ Handler: lambda_function.lambda_handler Runtime: python3.11 Architectures: - x86_64 Events: ScheduleEvent: Type: ScheduleV2 Properties: ScheduleExpression: cron(0 3 1 * ? *) Description: Run on the first day of every month at 03:00 AM Policies: - CloudWatchLogsFullAccess - Statement: - Effect: Allow Action: - dynamodb:Scan - dynamodb:BatchWriteItem Resource: !Sub 'arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/MyOrderTable' LambdaLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: !Sub /aws/lambda/${MyLambdaFunction} RetentionInDays: 30 Outputs: LambdaFunctionName: Description: Lambda Function Name Value: !Ref MyLambdaFunction LambdaFunctionArn: Description: Lambda Function ARN Value: !GetAtt MyLambdaFunction.Arn
Note
AWS SAM les modèles utilisent une convention de dénomination standard detemplate.yaml. Dans cet exemple, vous disposez de deux fichiers modèles : l’un pour créer la base de données d’exemple et l’autre pour créer l’application elle-même. Enregistrez-les dans des sous-répertoires distincts dans votre dossier de projet.
Ce AWS SAM modèle définit les ressources de votre application. Nous définissons la fonction Lambda à l’aide de la ressource AWS::Serverless::Function. Le calendrier du EventBridge planificateur et le déclencheur permettant d'appeler la fonction Lambda sont créés à l'aide de la Events propriété de cette ressource à l'aide d'un type de. ScheduleV2 Pour en savoir plus sur la définition des plannings du EventBridge planificateur dans les AWS SAM modèles, consultez ScheduleV2 dans le manuel du développeur.AWS Serverless Application Model
Outre la fonction Lambda et le calendrier du EventBridge planificateur, nous définissons également un groupe de CloudWatch journaux auquel votre fonction doit envoyer les enregistrements des éléments supprimés.
Copiez et collez le code suivant dans un fichier nommé test_app.py.
import boto3 from datetime import datetime, timedelta import json # Initialize the DynamoDB client dynamodb = boto3.resource('dynamodb') # Specify your table name table_name = 'YourTableName' table = dynamodb.Table(table_name) # Get the current date current_date = datetime.now() # Calculate the date one year ago one_year_ago = current_date - timedelta(days=365) # Convert the date to string format (assuming the date in DynamoDB is stored as a string) one_year_ago_str = one_year_ago.strftime('%Y-%m-%d') # Scan the table response = table.scan( FilterExpression='#date < :one_year_ago', ExpressionAttributeNames={ '#date': 'Date' }, ExpressionAttributeValues={ ':one_year_ago': one_year_ago_str } ) # Process the results old_records = response['Items'] # Continue scanning if we have more items (pagination) while 'LastEvaluatedKey' in response: response = table.scan( FilterExpression='#date < :one_year_ago', ExpressionAttributeNames={ '#date': 'Date' }, ExpressionAttributeValues={ ':one_year_ago': one_year_ago_str }, ExclusiveStartKey=response['LastEvaluatedKey'] ) old_records.extend(response['Items']) for record in old_records: print(json.dumps(record)) # The total number of old records should be zero. print(f"Total number of old records: {len(old_records)}")
Ce script de test utilise le AWS SDK pour Python (Boto3) pour créer une connexion à votre table DynamoDB et rechercher les éléments datant de plus d'un an. Pour confirmer que la fonction Lambda s’est bien exécutée, à la fin du test, la fonction affiche le nombre d’enregistrements de plus d’un an encore présents dans la table. Si l’exécution de la fonction Lambda a réussi, le nombre d’anciens enregistrements dans la table doit être égal à zéro.
Création et remplissage de l’exemple de table DynamoDB
Pour tester votre application de maintenance planifiée, vous devez d’abord créer une table DynamoDB et la remplir avec des exemples de données. Vous pouvez créer le tableau manuellement à l’aide de l’ AWS Management Console ou en utilisant AWS SAM. Nous vous recommandons de l'utiliser AWS SAM pour créer et configurer rapidement le tableau à l'aide de quelques AWS CLI commandes.
Après avoir créé votre table, vous devez ensuite ajouter des exemples de données pour tester votre application. Le fichier CSV sample_data.csv que vous avez téléchargé précédemment contient un certain nombre d’exemples d’entrées comprenant des numéros de commande, des dates et des informations sur les clients et les commandes. Utilisez le script python load_sample_data.py fourni pour ajouter ces données à votre table.
Pour ajouter les exemples de données à la table
-
Naviguez jusqu’au répertoire contenant les fichiers
sample_data.csvetload_sample_data.py. Si ces fichiers se trouvent dans des répertoires distincts, déplacez-les afin qu’ils soient enregistrés au même endroit. -
Créez un environnement virtuel Python dans lequel exécuter le script en exécutant la commande suivante. Nous vous recommandons d’utiliser un environnement virtuel, car lors de l’étape suivante, vous devrez installer l’ AWS SDK pour Python (Boto3).
python -m venv venv -
Activez l’environnement virtuel en exécutant la commande suivante.
source venv/bin/activate -
Installez le kit SDK for Python (Boto3) dans votre environnement virtuel en exécutant la commande suivante. Le script utilise cette bibliothèque pour se connecter à votre table DynamoDB et ajouter les éléments.
pip install boto3 -
Exécutez le script pour remplir la table en exécutant la commande suivante.
python load_sample_data.pySi le script s’exécute correctement, il doit afficher chaque élément sur la console au fur et à mesure du chargement et du rapport
Data loading completed. -
Désactivez l’environnement virtuel en exécutant la commande suivante.
deactivate -
Vous pouvez vérifier que les données ont été chargées dans votre table DynamoDB en procédant comme suit :
-
Ouvrez la page Explorer les éléments
de la console DynamoDB et sélectionnez votre table ( MyOrderTable). -
Dans le volet Éléments renvoyés, vous devriez voir les 25 éléments du fichier CSV que le script a ajouté à la table.
-
Création de l’application de maintenance planifiée
Vous pouvez créer et déployer les ressources pour cet exemple d'application étape par étape en utilisant AWS Management Console ou en utilisant AWS SAM. Dans un environnement de production, nous vous recommandons d'utiliser un outil Infrustracture-as-Code (iAc) permettant de déployer de manière répétitive des applications sans serveur sans recourir AWS SAM à des processus manuels.
Pour cet exemple, suivez les instructions de la console pour savoir comment configurer chaque AWS ressource séparément, ou suivez les AWS SAM instructions pour déployer rapidement l'application à l'aide de AWS CLI commandes.
Test de l’application
Pour vérifier que votre planification déclenche correctement votre fonction et que celle-ci nettoie correctement les enregistrements de la base de données, vous pouvez modifier temporairement votre planification pour qu’elle ne s’exécute qu’une seule fois à une heure précise. Vous pouvez ensuite exécuter à nouveau sam deploy pour réinitialiser votre planification récurrente afin qu’elle s’exécute une fois par mois.
Pour exécuter l'application à l'aide du AWS Management Console
-
Retournez à la page de la console du EventBridge planificateur.
-
Choisissez votre planification, puis choisissez Modifier.
-
Dans la section Schéma de planification, sous Récurrence, choisissez One-time planification.
-
Réglez votre durée d’invocation sur quelques minutes, vérifiez vos paramètres, puis choisissez Enregistrer.
Une fois la planification exécutée et sa cible invoquée, vous exécutez le script test_app.py pour vérifier que votre fonction a bien supprimé tous les anciens enregistrements de la table DynamoDB.
Pour vérifier que les anciens enregistrements sont supprimés à l’aide d’un script Python
-
Dans votre ligne de commande, accédez au dossier dans lequel vous avez enregistré
test_app.py. -
Exécutez le script.
python test_app.pyEn cas de succès, vous verrez la sortie suivante.
Total number of old records: 0
Étapes suivantes
Vous pouvez désormais modifier le calendrier du EventBridge planificateur pour répondre aux exigences spécifiques de votre application. EventBridge Le planificateur prend en charge les expressions de planification suivantes : cron, rate et plannings ponctuels.
Pour plus d'informations sur les expressions de planification du EventBridge planificateur, consultez la section Types de planification dans le guide de l'utilisateur du EventBridge planificateur. Gestion des accès dans le guide de l’utilisateur IAM
