Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d’une application sans serveur de traitement de fichiers
L’un des cas d’utilisation les plus courants de Lambda consiste à effectuer des tâches de traitement de fichiers. Par exemple, vous pouvez utiliser une fonction Lambda pour créer automatiquement des fichiers PDF à partir de fichiers HTML ou d’images, ou pour créer des miniatures lorsqu’un utilisateur télécharge une image.
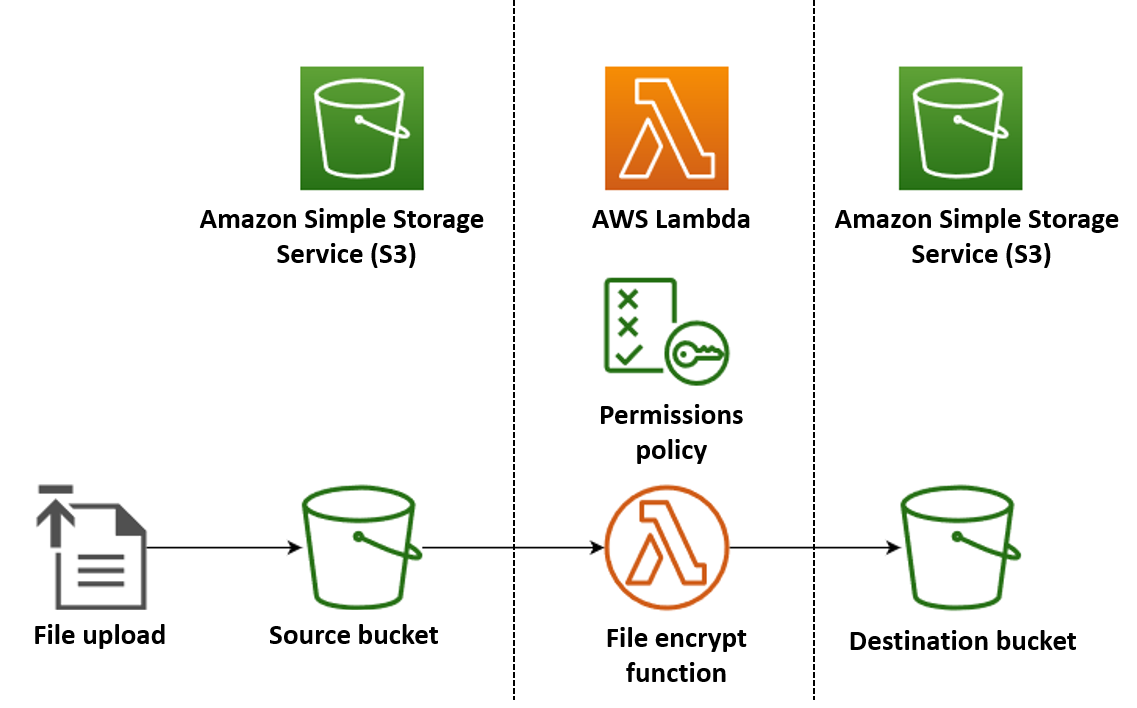
Dans cet exemple, vous créez une application qui chiffre automatiquement les fichiers PDF lorsqu’ils sont chargés dans un compartiment Amazon Simple Storage Service (Amazon S3). Pour mettre en œuvre cette application, vous créez les ressources suivantes :
-
Un compartiment S3 dans lequel les utilisateurs peuvent charger des fichiers PDF
-
Une fonction Lambda en Python qui lit le fichier téléchargé et en crée une version cryptée et protégée par mot de passe
-
Un deuxième compartiment S3 dans lequel Lambda pourra enregistrer le fichier chiffré
Vous créez également une politique Gestion des identités et des accès AWS (IAM) pour autoriser votre fonction Lambda à effectuer des opérations de lecture et d'écriture sur vos compartiments S3.
Astuce
Si vous utilisez Lambda pour la première fois, nous vous recommandons de commencer avec le didacticiel Création de votre première fonction Lambda avant de créer cet exemple d’application.
Vous pouvez déployer votre application manuellement en créant et en configurant des ressources à l'aide du AWS Management Console ou du AWS Command Line Interface (AWS CLI). Vous pouvez également déployer l'application en utilisant le AWS Serverless Application Model (AWS SAM). AWS SAM est un outil d'infrastructure en tant que code (IaC). Avec l’IaC, vous ne créez pas de ressources manuellement, mais vous les définissez dans le code, puis vous les déployez automatiquement.
Si vous souhaitez en savoir plus sur l’utilisation de Lambda avec l’IaC avant de déployer cet exemple d’application, consultez Utilisation de Lambda avec infrastructure en tant que code (IaC).
Créer les fichiers de code source de la fonction Lambda
Créez les fichiers suivants dans le répertoire de votre projet :
-
lambda_function.py: le code de fonction Python de la fonction Lambda qui effectue le chiffrement de fichiers -
requirements.txt: un fichier manifeste définissant les dépendances requises par le code de votre fonction Python
Développez les sections suivantes pour afficher le code et pour en savoir plus sur le rôle de chaque fichier. Pour créer les fichiers sur votre machine locale, copiez et collez le code ci-dessous ou téléchargez les fichiers depuis le dépôt GitHub aws-lambda-developer-guide
Copiez et collez le code suivant dans un fichier nommé lambda_function.py.
from pypdf import PdfReader, PdfWriter import uuid import os from urllib.parse import unquote_plus import boto3 # Create the S3 client to download and upload objects from S3 s3_client = boto3.client('s3') def lambda_handler(event, context): # Iterate over the S3 event object and get the key for all uploaded files for record in event['Records']: bucket = record['s3']['bucket']['name'] key = unquote_plus(record['s3']['object']['key']) # Decode the S3 object key to remove any URL-encoded characters download_path = f'/tmp/{uuid.uuid4()}.pdf' # Create a path in the Lambda tmp directory to save the file to upload_path = f'/tmp/converted-{uuid.uuid4()}.pdf' # Create another path to save the encrypted file to # If the file is a PDF, encrypt it and upload it to the destination S3 bucket if key.lower().endswith('.pdf'): s3_client.download_file(bucket, key, download_path) encrypt_pdf(download_path, upload_path) encrypted_key = add_encrypted_suffix(key) s3_client.upload_file(upload_path, f'{bucket}-encrypted', encrypted_key) # Define the function to encrypt the PDF file with a password def encrypt_pdf(file_path, encrypted_file_path): reader = PdfReader(file_path) writer = PdfWriter() for page in reader.pages: writer.add_page(page) # Add a password to the new PDF writer.encrypt("my-secret-password") # Save the new PDF to a file with open(encrypted_file_path, "wb") as file: writer.write(file) # Define a function to add a suffix to the original filename after encryption def add_encrypted_suffix(original_key): filename, extension = original_key.rsplit('.', 1) return f'{filename}_encrypted.{extension}'
Note
Dans cet exemple de code, un mot de passe pour le fichier chiffré (my-secret-password) est codé en dur dans le code de fonction. Dans une application de production, n’incluez pas d’informations sensibles telles que des mots de passe dans votre code de fonction. Créez plutôt un AWS Secrets Manager secret, puis utilisez l'extension Lambda AWS Parameters and Secrets pour récupérer vos informations d'identification dans votre fonction Lambda.
Le code de la fonction python contient trois fonctions : la fonction de gestion que Lambda exécute lorsque votre fonction est invoquée, et deux fonctions distinctes nommées add_encrypted_suffix et encrypt_pdf que le gestionnaire appelle pour effectuer le chiffrement du PDF.
Lorsque votre fonction est invoquée par Amazon S3, Lambda transmet un argument d’événement au format JSON à la fonction contenant des informations sur l’événement à l’origine de l’invocation. Dans ce cas, les informations incluent le nom du compartiment S3 et les clés d’objet pour les fichiers téléchargés. Pour de plus amples informations sur le format de l’objet d’événement pour Amazon S3, consultez Traiter les notifications d’événements Amazon S3 avec Lambda.
Votre fonction utilise ensuite le AWS SDK pour Python (Boto3) pour télécharger les fichiers PDF spécifiés dans l'objet d'événement vers son répertoire de stockage temporaire local, avant de les chiffrer à l'aide de la pypdf
Enfin, la fonction utilise le kit SDK Boto3 pour stocker le fichier chiffré dans votre compartiment de destination S3.
Copiez et collez le code suivant dans un fichier nommé requirements.txt.
boto3 pypdf
Dans cet exemple, le code de votre fonction ne comporte que deux dépendances qui ne font pas partie de la bibliothèque Python standard : le kit SDK pour Python (Boto3) et le package pypdf utilisé par la fonction pour effectuer le chiffrement du PDF.
Note
Une version du kit SDK pour Python (Boto3) est incluse dans l’environnement d’exécution Lambda, de sorte que votre code s’exécute sans ajouter Boto3 au package de déploiement de votre fonction. Toutefois, pour garder le contrôle total des dépendances de votre fonction et éviter d’éventuels problèmes de désalignement de version, la bonne pratique pour Python consiste à inclure toutes les dépendances de fonction dans le package de déploiement de votre fonction. Pour en savoir plus, consultez Dépendances d’exécution dans Python.
Déployer l’application
Vous pouvez créer et déployer les ressources pour cet exemple d'application manuellement ou à l'aide de AWS SAM. Dans un environnement de production, nous vous recommandons d'utiliser un outil IaC AWS SAM pour déployer rapidement et de manière répétitive des applications complètes sans serveur sans recourir à des processus manuels.
Pour déployer votre application manuellement :
-
Créez les compartiments Amazon S3 source et destination
-
Créez une fonction Lambda qui chiffre un fichier PDF et enregistre la version chiffrée dans un compartiment S3
-
Configurez un déclencheur Lambda qui invoque votre fonction lorsque des objets sont chargés dans votre compartiment source
Avant de commencer, assurez-vous que Python
Création de deux compartiments S3
Créez deux compartiments S3. Le premier compartiment est le compartiment source dans lequel vous allez charger vos fichiers PDF. Le second compartiment est utilisé par Lambda pour enregistrer les fichiers chiffrés lorsque vous invoquez votre fonction.

Créer un rôle d’exécution
Un rôle d'exécution est un rôle IAM qui accorde à une fonction Lambda l'autorisation d' Services AWS accès et de ressources. Pour donner à votre fonction un accès en lecture et en écriture à Amazon S3, vous attachez la politique gérée par AWS AmazonS3FullAccess.
Créer le package de déploiement de la fonction
Pour créer votre fonction, vous créez un package de déploiement contenant le code de votre fonction et ses dépendances. Pour cette application, votre code de fonction utilise une bibliothèque distincte pour le chiffrement du PDF.
Pour créer le package de déploiement
-
Accédez au répertoire du projet contenant les
requirements.txtfichierslambda_function.pyet que vous avez créés ou téléchargés GitHub précédemment et créez un nouveau répertoire nommépackage. -
Installez les dépendances spécifiées dans le fichier
requirements.txtde votre répertoirepackageen exécutant la commande suivante.pip install -r requirements.txt --target ./package/ -
Créez un fichier .zip contenant le code de votre application et ses dépendances. Sous Linux ou macOS, exécutez les commandes suivantes depuis votre interface de ligne de commande.
cd package zip -r ../lambda_function.zip . cd .. zip lambda_function.zip lambda_function.pySous Windows, utilisez l’outil zip de votre choix pour créer le fichier
lambda_function.zip. Assurez-vous que votre fichierlambda_function.pyet les dossiers contenant vos dépendances sont installés à la racine du fichier .zip.
Vous pouvez également créer votre package de déploiement à l’aide d’un environnement virtuel Python. Consultez Travailler avec des archives de fichiers .zip pour les fonctions Lambda Python
Créer la fonction Lambda
Vous utilisez maintenant le package de déploiement que vous avez créé à l’étape précédente pour déployer votre fonction Lambda.
Configuration d’un déclencheur Amazon S3 pour invoquer la fonction
Pour que votre fonction Lambda s’exécute lorsque vous chargez un fichier dans votre compartiment source, vous devez configurer un déclencheur pour votre fonction. Vous pouvez configurer le déclencheur Amazon S3 à l’aide de la console ou de la AWS CLI.
Important
Cette procédure configure le compartiment S3 pour qu'il invoque votre fonction chaque fois qu'un objet est créé dans le compartiment. Veillez à configurer cela uniquement pour le compartiment source. Si votre fonction Lambda crée des objets dans le même compartiment que celui qui l’invoque, votre fonction peut être invoquée en continu dans une boucle
Avant de commencer, assurez-vous que Docker
-
Dans le répertoire de votre projet, copiez et collez le code suivant dans un fichier nommé
template.yaml. Remplacez les espaces réservés des noms des compartiments :-
Pour le compartiment source, remplacez
amzn-s3-demo-bucketpar un nom conforme aux règles de dénomination des compartiments S3. -
Pour le compartiment de destination, remplacez
amzn-s3-demo-bucket-encryptedpar<source-bucket-name>-encrypted, où<source-bucket>est le nom que vous avez choisi pour votre compartiment source.
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Resources: EncryptPDFFunction: Type: AWS::Serverless::Function Properties: FunctionName: EncryptPDF Architectures: [x86_64] CodeUri: ./ Handler: lambda_function.lambda_handler Runtime: python3.12 Timeout: 15 MemorySize: 256 LoggingConfig: LogFormat: JSON Policies: - AmazonS3FullAccess Events: S3Event: Type: S3 Properties: Bucket: !Ref PDFSourceBucket Events: s3:ObjectCreated:* PDFSourceBucket: Type: AWS::S3::Bucket Properties: BucketName:amzn-s3-demo-bucketEncryptedPDFBucket: Type: AWS::S3::Bucket Properties: BucketName:amzn-s3-demo-bucket-encryptedLe AWS SAM modèle définit les ressources que vous créez pour votre application. Dans cet exemple, le modèle définit une fonction Lambda utilisant le type
AWS::Serverless::Functionet deux compartiments S3 utilisant le typeAWS::S3::Bucket. Les noms de compartiments spécifiés dans le modèle sont des espaces réservés. Avant de déployer l'application à l'aide de AWS SAM, vous devez modifier le modèle pour renommer les compartiments avec des noms uniques au niveau mondial conformes aux règles de dénomination des compartiments S3. Cette étape est expliquée plus en détail dans Déployez les ressources à l'aide de AWS SAM.La définition de la ressource de fonction Lambda configure un déclencheur pour la fonction à l’aide de la propriété d’événement
S3Event. Ce déclencheur entraîne l’invocation de votre fonction chaque fois qu’un objet est créé dans votre compartiment source.La définition de la fonction spécifie également une politique Gestion des identités et des accès AWS (IAM) à associer au rôle d'exécution de la fonction. La politique gérée par AWS
AmazonS3FullAccessdonne à votre fonction les autorisations dont elle a besoin pour lire et écrire des objets sur Amazon S3. -
-
Exécutez la commande suivante dans le répertoire où vous avez enregistré les fichiers
template.yaml,lambda_function.pyetrequirements.txt.sam build --use-containerCette commande rassemble les artefacts de compilation pour votre application et les place dans le format et l’emplacement appropriés pour les déployer. La spécification de l'
--use-containeroption crée votre fonction dans un conteneur Lambda-like Docker. Nous l’utilisons ici, vous n’avez donc pas besoin d’installer Python 3.12 sur votre machine locale pour que la compilation fonctionne.Pendant le processus de génération, AWS SAM recherche le code de la fonction Lambda à l'emplacement que vous avez spécifié avec la
CodeUripropriété dans le modèle. Dans ce cas, nous avons spécifié le répertoire actuel comme emplacement (./).Si un
requirements.txtfichier est présent, AWS SAM utilisez-le pour rassembler les dépendances spécifiées. Par défaut, AWS SAM crée un package de déploiement .zip avec le code de votre fonction et ses dépendances. Vous pouvez également choisir de déployer votre fonction sous forme d'image de conteneur à l'aide de la PackageTypepropriété. -
Pour déployer votre application et créer les ressources Lambda et Amazon S3 spécifiées dans votre AWS SAM modèle, exécutez la commande suivante.
sam deploy --guidedL'utilisation du
--guideddrapeau signifie que des instructions vous AWS SAM seront affichées pour vous guider tout au long du processus de déploiement. Pour ce déploiement, acceptez les options par défaut en appuyant sur Entrée.
Au cours du processus de déploiement, AWS SAM crée les ressources suivantes dans votre Compte AWS :
-
Une CloudFormation pile nommée
sam-app -
Une fonction Lambda nommée
EncryptPDF -
Deux compartiments S3 portant les noms que vous avez choisis lorsque vous avez modifié le
template.yamlAWS SAM fichier modèle -
Un rôle d’exécution IAM pour votre fonction avec le format de nom
sam-app-EncryptPDFFunctionRole-2qGaapHFWOQ8
Lorsque vous avez AWS SAM terminé de créer vos ressources, le message suivant devrait s'afficher :
Successfully created/updated stack - sam-app in us-east-2Tester l'application
Pour tester votre application, chargez un fichier PDF dans votre compartiment source et vous confirmez que Lambda crée une version chiffrée du fichier dans votre compartiment de destination. Dans cet exemple, vous pouvez le tester manuellement à l'aide de la AWS CLI console ou du script de test fourni.
Pour les applications de production, vous pouvez utiliser des méthodes et techniques de test traditionnelles, telles que les tests unitaires, pour confirmer le bon fonctionnement de votre code de fonction Lambda. Les pratiques exemplaires consistent également à effectuer des tests comme ceux du script de test fourni, qui réalisent des tests d’intégration avec des ressources réelles, basées sur le cloud. Les tests d’intégration dans le cloud confirment que votre infrastructure a été correctement déployée et que les événements circulent entre les différents services comme prévu. Pour en savoir plus, veuillez consulter la section Commenter tester des fonctions et des applications sans serveur.
Vous pouvez tester votre fonction manuellement en ajoutant un fichier PDF à votre compartiment source Amazon S3. Lorsque vous ajoutez votre fichier au compartiment source, votre fonction Lambda doit être automatiquement invoquée et doit stocker une version chiffrée du fichier dans votre compartiment cible.
Créez les fichiers suivants dans le répertoire de votre projet :
-
test_pdf_encrypt.py: un script de test que vous pouvez utiliser pour tester automatiquement votre application -
pytest.ini: un fichier de configuration pour le script de test
Développez les sections suivantes pour afficher le code et pour en savoir plus sur le rôle de chaque fichier.
Copiez et collez le code suivant dans un fichier nommé test_pdf_encrypt.py. Veillez à remplacer les espaces réservés de nom de compartiment :
-
Dans la fonction
test_source_bucket_available, remplacezamzn-s3-demo-bucketpar le nom de votre compartiment source. -
Dans la fonction
test_encrypted_file_in_bucket, remplacezamzn-s3-demo-bucket-encryptedparsource-bucket-encrypted, oùsource-bucket>est le nom de votre compartiment source. -
Dans la fonction
cleanup, remplacezamzn-s3-demo-bucketpar le nom de votre compartiment source et remplacezamzn-s3-demo-bucket-encryptedpar le nom de votre compartiment source.
import boto3 import json import pytest import time import os @pytest.fixture def lambda_client(): return boto3.client('lambda') @pytest.fixture def s3_client(): return boto3.client('s3') @pytest.fixture def logs_client(): return boto3.client('logs') @pytest.fixture(scope='session') def cleanup(): # Create a new S3 client for cleanup s3_client = boto3.client('s3') yield # Cleanup code will be executed after all tests have finished # Delete test.pdf from the source bucket source_bucket = 'amzn-s3-demo-bucket' source_file_key = 'test.pdf' s3_client.delete_object(Bucket=source_bucket, Key=source_file_key) print(f"\nDeleted {source_file_key} from {source_bucket}") # Delete test_encrypted.pdf from the destination bucket destination_bucket = 'amzn-s3-demo-bucket-encrypted' destination_file_key = 'test_encrypted.pdf' s3_client.delete_object(Bucket=destination_bucket, Key=destination_file_key) print(f"Deleted {destination_file_key} from {destination_bucket}") @pytest.mark.order(1) def test_source_bucket_available(s3_client): s3_bucket_name = 'amzn-s3-demo-bucket' file_name = 'test.pdf' file_path = os.path.join(os.path.dirname(__file__), file_name) file_uploaded = False try: s3_client.upload_file(file_path, s3_bucket_name, file_name) file_uploaded = True except: print("Error: couldn't upload file") assert file_uploaded, "Could not upload file to S3 bucket" @pytest.mark.order(2) def test_lambda_invoked(logs_client): # Wait for a few seconds to make sure the logs are available time.sleep(5) # Get the latest log stream for the specified log group log_streams = logs_client.describe_log_streams( logGroupName='/aws/lambda/EncryptPDF', orderBy='LastEventTime', descending=True, limit=1 ) latest_log_stream_name = log_streams['logStreams'][0]['logStreamName'] # Retrieve the log events from the latest log stream log_events = logs_client.get_log_events( logGroupName='/aws/lambda/EncryptPDF', logStreamName=latest_log_stream_name ) success_found = False for event in log_events['events']: message = json.loads(event['message']) status = message.get('record', {}).get('status') if status == 'success': success_found = True break assert success_found, "Lambda function execution did not report 'success' status in logs." @pytest.mark.order(3) def test_encrypted_file_in_bucket(s3_client): # Specify the destination S3 bucket and the expected converted file key destination_bucket = 'amzn-s3-demo-bucket-encrypted' converted_file_key = 'test_encrypted.pdf' try: # Attempt to retrieve the metadata of the converted file from the destination S3 bucket s3_client.head_object(Bucket=destination_bucket, Key=converted_file_key) except s3_client.exceptions.ClientError as e: # If the file is not found, the test will fail pytest.fail(f"Converted file '{converted_file_key}' not found in the destination bucket: {str(e)}") def test_cleanup(cleanup): # This test uses the cleanup fixture and will be executed last pass
Le script de test automatique exécute trois fonctions de test pour confirmer le bon fonctionnement de votre application :
-
Le test
test_source_bucket_availableconfirme que votre compartiment source a été créé avec succès en y téléchargeant un fichier PDF de test. -
Le test
test_lambda_invokedinterroge le dernier flux du journal CloudWatch Logs de votre fonction afin de confirmer que lorsque vous avez chargé le fichier de test, votre fonction Lambda s'est exécutée et a signalé un succès. -
Le test
test_encrypted_file_in_bucketconfirme que votre compartiment de destination contient le fichier chiffrétest_encrypted.pdf.
Une fois tous ces tests exécutés, le script exécute une étape de nettoyage supplémentaire pour supprimer les fichiers test.pdf et test_encrypted.pdf de vos compartiments source et de destination.
Comme pour le AWS SAM modèle, les noms de compartiments spécifiés dans ce fichier sont des espaces réservés. Avant d’exécuter le test, vous devez modifier ce fichier avec les noms de compartiment réels de votre application. Cette étape est expliquée plus en détail dans Test de l’application avec le script automatique.
Copiez et collez le code suivant dans un fichier nommé pytest.ini.
[pytest] markers = order: specify test execution order
Cela est nécessaire pour spécifier l’ordre dans lequel les tests du script test_pdf_encrypt.py s’exécutent.
Pour exécuter l’exemple, procédez comme suit :
-
Assurez-vous que le module
pytestest installé dans votre environnement local. Vous pouvez installerpytesten exécutant les commandes suivantes :pip install pytest -
Enregistrez un fichier PDF nommé
test.pdfdans le répertoire contenant les fichierstest_pdf_encrypt.pyetpytest.ini. -
Ouvrez un terminal ou un exécuteur shell et exécutez la commande suivante depuis le répertoire contenant les fichiers de test.
pytest -s -vLorsque le test est terminé, vous devriez obtenir un résultat semblable à celui qui suit :
============================================================== test session starts ========================================================= platform linux -- Python 3.12.2, pytest-7.2.2, pluggy-1.0.0 -- /usr/bin/python3 cachedir: .pytest_cache hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/home/pdf_encrypt_app/.hypothesis/examples') Test order randomisation NOT enabled. Enable with --random-order or --random-order-bucket=<bucket_type> rootdir: /home/pdf_encrypt_app, configfile: pytest.ini plugins: anyio-3.7.1, hypothesis-6.70.0, localserver-0.7.1, random-order-1.1.0 collected 4 items test_pdf_encrypt.py::test_source_bucket_available PASSED test_pdf_encrypt.py::test_lambda_invoked PASSED test_pdf_encrypt.py::test_encrypted_file_in_bucket PASSED test_pdf_encrypt.py::test_cleanup PASSED Deleted test.pdf from amzn-s3-demo-bucket Deleted test_encrypted.pdf from amzn-s3-demo-bucket-encrypted =============================================================== 4 passed in 7.32s ==========================================================
Étapes suivantes
Maintenant que vous avez créé cet exemple d’application, vous pouvez utiliser le code fourni comme base pour créer d’autres types d’applications de traitement de fichiers. Modifiez le code du fichier lambda_function.py pour mettre en œuvre la logique de traitement de fichiers adaptée à votre cas d’utilisation.
De nombreux cas d’utilisation typiques du traitement de fichiers impliquent le traitement d’image. Lorsque vous utilisez Python, les bibliothèques de traitement d’image les plus populaires telles que pillow
Lorsque vous déployez vos ressources avec AWS SAM, vous devez prendre des mesures supplémentaires pour inclure la distribution source appropriée dans votre package de déploiement. Étant donné que les dépendances AWS SAM ne seront pas installées pour une plate-forme différente de celle de votre machine de génération, la spécification de la distribution source (.whlfichier) correcte dans votre requirements.txt fichier ne fonctionnera pas si votre machine de génération utilise un système d'exploitation ou une architecture différent de l'environnement d'exécution Lambda. Au lieu de cela, vous devriez procéder à l’une des opérations suivantes :
-
Utilisez l’option
--use-containerlors de l’exécution desam build. Lorsque vous spécifiez cette option, AWS SAM télécharge une image de base de conteneur compatible avec l'environnement d'exécution Lambda et crée le package de déploiement de votre fonction dans un conteneur Docker à l'aide de cette image. Pour en savoir plus, consultez Building a Lambda function inside of a provided container. -
Créez vous-même le package de déploiement .zip de votre fonction en utilisant le binaire de distribution source approprié et enregistrez le fichier .zip dans le répertoire que vous spécifiez
CodeUridans le AWS SAM modèle. Pour en savoir plus sur la création de packages de déploiement .zip pour Python à l’aide de distributions binaires, consultez Création d’un package de déploiement .zip avec dépendances et Création de packages de déploiement .zip avec des bibliothèques natives.
