Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Anda dapat menggunakan sebuah Perayap AWS Glue untuk mengisi AWS Glue Data Catalog dengan database dan tabel. Ini adalah metode utama yang digunakan oleh sebagian besar AWS Glue pengguna. Sebuah crawler dapat melakukan perayapan pada beberapa penyimpanan data dalam satu kali eksekusi. Setelah selesai, crawler tersebut membuat atau memperbarui satu atau beberapa tabel dalam Katalog Data Anda. Ekstrak, ubah, dan muat (ETL) pekerjaan yang Anda tentukan AWS Glue gunakan tabel Katalog Data ini sebagai sumber dan target. Tugas ETL membaca dari dan menulis ke penyimpanan data yang ditentukan dalam sumber dan target tabel Katalog Data.
Alur kerja
Diagram alur kerja berikut menunjukkan bagaimana AWS Glue crawler berinteraksi dengan penyimpanan data dan elemen lain untuk mengisi Katalog Data.
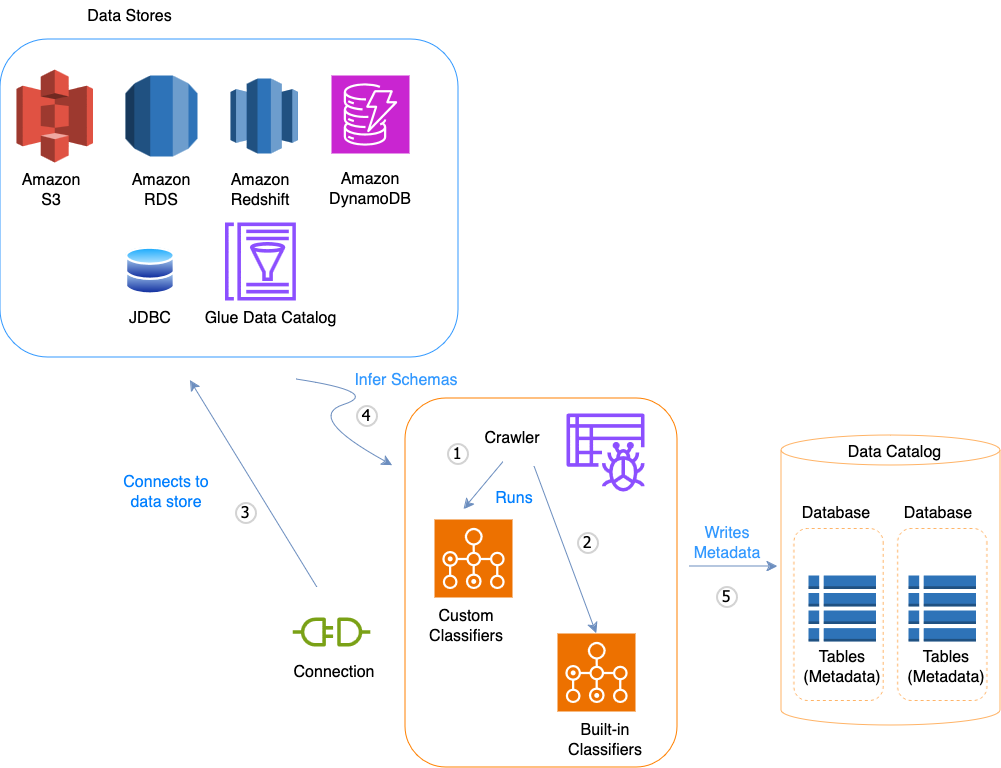
Berikut ini adalah alur kerja umum bagaimana crawler mengisi AWS Glue Data Catalog:
-
Sebuah crawler menjalankan setiap pengklasifikasi kustom yang Anda pilih untuk menyimpulkan format dan skema data Anda. Anda menyediakan kode untuk pengklasifikasi kustom, dan mereka berjalan dengan urutan yang Anda tentukan.
Pengklasifikasi kustom pertama yang berhasil mengenali struktur data Anda digunakan untuk membuat sebuah skema. Pengklasifikasi kustom yang ada di bagian bawah daftar dilewati.
-
Jika tidak ada pengklasifikasi kustom yang cocok dengan skema data Anda, maka pengklasifikasi bawaan mencoba mengenali skema data Anda. Contoh pengklasifikasi bawaan adalah pengklasifikasi yang mengenali JSON.
-
Crawler terhubung ke penyimpanan data. Beberapa penyimpanan data memerlukan properti koneksi untuk akses crawler.
-
Skema kesimpulan dibuat untuk data Anda.
-
Crawler menulis metadata ke Katalog Data. Definisi tabel berisi metadata tentang data yang ada di penyimpanan data Anda. Tabel tersebut ditulis ke sebuah basis data, yang merupakan kontainer dari tabel dalam Katalog Data. Atribut sebuah tabel termasuk klasifikasi, yang merupakan label yang dibuat oleh pengklasifikasi yang telah menyimpulkan skema tabel.
Topik
Cara kerja crawler
Saat sebuah crawler berjalan, crawler tersebut melakukan tindakan berikut untuk mengambil data dari penyimpanan data:
-
Mengklasifikasikan data untuk menentukan format, skema, dan properti terkait data mentah — Anda dapat mengkonfigurasi hasil klasifikasi dengan membuat sebuah pengklasifikasi kustom.
-
Mengelompokkan data ke dalam tabel atau partisi — Data dikelompokkan dalam grup berdasarkan heuristik crawler.
-
Menulis metadata ke Katalog Data — Anda dapat mengkonfigurasi bagaimana crawler menambahkan, memperbarui, dan menghapus tabel dan partisi.
Saat menentukan crawler, Anda memilih satu atau beberapa pengklasifikasi yang mengevaluasi format data Anda untuk menyimpulkan sebuah skema. Ketika crawler tersebut berjalan, pengklasifikasi pertama dalam daftar Anda, agar berhasil mengenali penyimpanan data Anda, digunakan untuk membuat sebuah skema untuk tabel Anda. Anda dapat menggunakan pengklasifikasi bawaan atau menggunakan pengklasifikasi Anda sendiri. Anda menentukan pengklasifikasi kustom Anda dalam operasi terpisah, sebelum Anda menentukan crawler. AWS Glue menyediakan pengklasifikasi bawaan untuk menyimpulkan skema dari file umum dengan format yang mencakup JSON, CSV, dan Apache Avro. Untuk daftar pengklasifikasi bawaan saat ini di AWS Glue, lihat Pengklasifikasi bawaan.
Tabel metadata yang dibuat crawler terkandung dalam sebuah basis data ketika Anda menentukan sebuah crawler. Jika crawler Anda tidak menentukan sebuah basis data, maka tabel Anda ditempatkan di basis data default. Selain itu, setiap tabel memiliki sebuah kolom klasifikasi yang diisi oleh pengklasifikasi yang pertama kali berhasil mengenali penyimpanan data.
Jika file yang di-crawl dikompresi, maka crawler harus mengunduhnya untuk memprosesnya. Ketika sebuah crawler berjalan, crawler tersebut mengambil data dari file untuk menentukan format dan jenis kompresi mereka dan menulis properti ini ke dalam Katalog Data. Beberapa format file (misalnya, Apache Parket) memungkinkan Anda untuk meng-kompresi bagian dari file seperti yang tertulis. Untuk file-file ini, data terkompresi adalah komponen internal file, dan AWS Glue tidak mengisi compressionType properti ketika menulis tabel ke dalam Katalog Data. Sebaliknya, jika seluruh file dikompresi oleh sebuah algoritme kompresi (misalnya, gzip), maka properti compressionType diisi ketika tabel ditulis ke dalam Katalog Data.
Crawler menghasilkan nama-nama untuk tabel yang dibuatnya. Nama-nama tabel yang disimpan dalam AWS Glue Data Catalog mengikuti aturan ini:
-
Hanya karakter alfanumerik dan garis bawah (
_) yang boleh digunakan. -
Prefiks kustom tidak boleh lebih dari 64 karakter.
-
Panjang nama maksimum tidak dapat lebih panjang dari 128 karakter. Crawler memotong nama yang dihasilkan agar sesuai dengan batasan.
-
Jika ada nama tabel duplikat yang ditemukan, maka crawler menambahkan akhiran string hash ke nama tersebut.
Jika crawler Anda berjalan lebih dari sekali, mungkin berdasarkan jadwal, maka crawler tersebut akan mencari file atau tabel baru atau yang diubah di penyimpanan data Anda. Output dari crawler termasuk tabel baru dan partisi yang ditemukan sejak eksekusi sebelumnya.
Bagaimana crawler menentukan kapan harus membuat partisi?
Ketika sebuah AWS Glue crawler memindai stpre data Amazon S3 dan mendeteksi beberapa folder dalam ember, ini menentukan root tabel dalam struktur folder dan folder mana yang merupakan partisi tabel. Nama tabel didasarkan pada prefiks Amazon S3 atau nama folder. Anda memberikan Termasuk path yang mengarahkan ke tingkat folder yang akan di-crawl. Ketika sebagian besar skema pada tingkat folder serupa, crawler tersebut menciptakan partisi dari sebuah tabel bukan tabel terpisah. Untuk mempengaruhi crawler agar membuat tabel terpisah, tambahkan folder akar dari setiap tabel sebagai penyimpanan data terpisah ketika Anda menentukan crawler.
Sebagai contoh, pertimbangkan struktur folder Amazon S3 berikut.
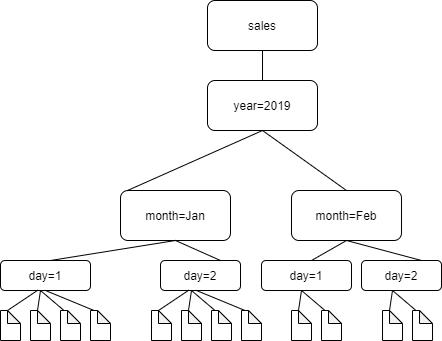
Path ke folder empat tingkat terendah adalah sebagai berikut:
S3://sales/year=2019/month=Jan/day=1
S3://sales/year=2019/month=Jan/day=2
S3://sales/year=2019/month=Feb/day=1
S3://sales/year=2019/month=Feb/day=2Asumsikan bahwa target crawler ditetapkan pada Sales, dan bahwa semua file dalam folder day=n mempunyai format yang sama (sebagai contoh, JSON, tidak dienkripsi), dan mempunyai skema yang sama atau sangat serupa. Crawler tersebut akan membuat sebuah tabel tunggal dengan empat partisi, dengan kunci partisi year, month, dan day.
Pada contoh selanjutnya, pertimbangkan struktur Amazon S3 berikut:
s3://bucket01/folder1/table1/partition1/file.txt
s3://bucket01/folder1/table1/partition2/file.txt
s3://bucket01/folder1/table1/partition3/file.txt
s3://bucket01/folder1/table2/partition4/file.txt
s3://bucket01/folder1/table2/partition5/file.txt
Jika skema untuk file di bawah table1 dan table2 skemanya serupa, dan penyimpanan data tunggal didefinisikan dalam crawler dengan Termasuk path s3://bucket01/folder1/, maka crawler membuat sebuah tabel tunggal dengan dua kolom kunci partisi. Kolom kunci partisi pertama berisi table1 dan table2, dan kolom kunci partisi kedua berisi partition1 hingga partition3 untuk partisi table1 dan partition4 dan partition5 untuk partisi table2. Untuk membuat dua tabel terpisah, tentukan crawler dengan dua penyimpanan data. Dalam contoh ini, tentukan Termasuk path yang pertama sebagai s3://bucket01/folder1/table1/ dan yang kedua sebagai s3://bucket01/folder1/table2.
catatan
Di Amazon Athena, setiap tabel sesuai dengan prefiks Amazon S3 dengan semua objek di dalamnya. Jika objek memiliki skema yang berbeda, maka Athena tidak akan mengenali objek yang berbeda dalam prefiks yang sama sebagai tabel terpisah. Hal ini dapat terjadi jika crawler membuat beberapa tabel dari prefiks Amazon S3 yang sama. Hal ini mungkin menyebabkan kueri di Athena mengembalikan hasil nol. Bagi Athena, untuk dapat mengenali dan meng-kueri tabel dengan benar, buatlah crawler dengan Termasuk path terpisah untuk setiap skema tabel yang berbeda dalam struktur folder Amazon S3. Untuk informasi selengkapnya, lihat Praktik Terbaik Saat Menggunakan Athena dengan AWS Gluedan artikel Pusat AWS
Pengetahuan ini
