Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Nota
Amazon Neptune invia i parametri solo quando hanno un CloudWatch valore diverso da zero.
Per tutti le metriche Neptune, la granularità dell'aggregazione è di 5 minuti.
Metriche di Neptune CloudWatch
La tabella seguente elenca le CloudWatch metriche supportate da Neptune.
Nota
Tutti le metriche cumulative vengono azzerate ogni volta che il server viene riavviato, sia per manutenzione, riavvio o ripristino dopo un arresto anomalo.
| Parametro | Descrizione |
|---|---|
|
La quantità totale di spazio di archiviazione di backup, espressa in byte, utilizzata per il supporto dalla finestra di conservazione del backup del cluster database Neptune. Incluso nel totale riportato dal parametro |
|
La percentuale di richieste gestite dalla cache del buffer. Questa metrica può essere utile per diagnosticare la latenza delle query, poiché mancati riscontri della cache provocano una latenza significativa. Se il rapporto di riscontri della cache è inferiore al 99,9%, valutare la possibilità di aggiornare il tipo di istanza per memorizzare nella cache più dati in memoria. |
|
Per una replica di lettura, il ritardo durante la replica degli aggiornamenti dall'istanza principale, in millisecondi. |
|
Il ritardo massimo tra l'istanza primaria e ogni istanza database Neptune nel cluster database, in millisecondi. |
|
Il ritardo minimo tra l'istanza primaria e ogni istanza database Neptune nel cluster database, in millisecondi. |
|
Il numero di crediti CPU accumulati da un'istanza, segnalati a intervalli di 5 minuti. Viene utilizzato per determinare per quanto tempo un'istanza database può superare il proprio livello di prestazioni di base a una determinata velocità. |
|
Il numero di crediti CPU consumati durante il periodo specificato, segnalato a intervalli di 5 minuti. Questa metrica misura la quantità di tempo durante la quale i dati fisici CPUs sono stati utilizzati per l'elaborazione delle istruzioni mediante CPUs allocazioni virtuali all'istanza DB. |
|
Il numero di crediti extra spesi da un'istanza illimitata quando il rispettivo valore |
|
Il numero di crediti in eccesso spesi che non vengono rimborsati dai crediti CPU guadagnati e che comportano un costo aggiuntivo. |
|
La percentuale di utilizzo della CPU. |
|
Il periodo di esecuzione dell'istanza, in secondi. |
|
La quantità di memoria RAM disponibile, in byte. |
|
Il numero di byte di dati di redo log trasferiti dal primario Regione AWS a uno secondario Regione AWS in un database globale di Neptune. |
|
Numero di operazioni di I/O di scrittura replicate dalla Regione AWS primaria nel database globale al volume cluster in una Regione AWS secondaria. I calcoli di fatturazione per ogni cluster database in un database globale Neptune utilizzano la metrica |
|
Numero di millisecondi di ritardo del cluster secondario rispetto al cluster primario sia per le transazioni utente che per le transazioni di sistema. |
|
Numero di errori lato client al secondo negli attraversamenti Gremlin. |
|
Numero di errori lato server al secondo negli attraversamenti Gremlin. |
|
Numero di richieste al secondo al motore Gremlin. |
|
Il numero di WebSocket connessioni aperte verso Neptune. |
|
Numero di errori lato client al secondo da richieste del Loader. |
|
Numero di richieste dello strumento di caricamento al secondo. |
|
Numero di errori lato server del Loader al secondo. |
|
Numero di richieste in attesa di esecuzione nella coda di input. Neptune inizia a limitare le richieste quando superano la capacità massima della coda. |
|
Applicabile solo a un'istanza database o un cluster DB Neptune Serverless. A livello di istanza, riporta una percentuale calcolata come il numero di unità di capacità Neptune NCUs () attualmente utilizzate dall'istanza in questione, diviso per l'impostazione della capacità NCU massima per il cluster. Un'unità di capacità Neptune (NCU, Neptune Capacity Unit) è costituita da 2 GiB (gibibyte) di memoria (RAM) insieme alle reti e alla capacità del processore virtuale (vCPU) associate. A livello di cluster, |
|
La velocità di trasmissione effettiva della rete in byte al secondo in entrata e in uscita dei client per ogni istanza del cluster database Neptune. Questa velocità di trasmissione effettiva non include il traffico di rete tra le istanze del cluster database e il volume del cluster. |
|
La velocità di trasmissione effettiva della rete in byte al secondo in uscita dei client per ogni istanza del cluster database Neptune. Questa velocità di trasmissione effettiva non include il traffico di rete tra le istanze del cluster database e il volume del cluster. |
NumIndexDeletesPerSec |
Numero di eliminazioni da singoli indici. Le eliminazioni da ciascun indice vengono contate singolarmente. Ciò include le eliminazioni che possono essere annullate se una query rileva un errore. |
NumIndexInsertsPerSec |
Numero di inserimenti nei singoli indici. Gli inserti in ciascun indice vengono contati separatamente. Ciò include gli inserti che possono essere ripristinati se una query rileva un errore. |
NumIndexReadsPerSec |
Numero di dichiarazioni scansionate da qualsiasi indice. Qualsiasi modello di accesso inizia con una ricerca su un indice e legge tutte le istruzioni corrispondenti. Un aumento di questa metrica può causare un aumento delle latenze di query o dell'utilizzo della CPU. |
|
Il numero di errori del OpenCypher client al secondo. |
|
Il numero di OpenCypher richieste al secondo. |
|
Il numero di errori del OpenCypher server al secondo. |
|
Il numero di richieste in coda al secondo. |
|
Numero di accessi alla cache dei risultati di Gremlin. |
|
Numero di errori nella cache dei risultati di Gremlin. |
|
Il numero di transazioni impegnate correttamente al secondo. |
|
Il numero di transazioni aperte sul server al secondo. |
|
Per le query di scrittura, il numero di transazioni al secondo di cui è stato eseguito il rollback sul server a causa di errori. Per le query di sola lettura, questa metrica è uguale al numero di transazioni di sola lettura completate al secondo. |
NumUndoPagesPurged |
Questa metrica indica il numero di batch eliminati. Questa metrica indica lo stato di avanzamento della rimozione. Il valore è 0 per le istanze Reader e la metrica si applica solo all'istanza Writer. |
|
Numero di richieste al secondo (sia HTTPS che Bolt) al motore openCypher. |
|
Il numero di connessioni Bolt aperte a Neptune. |
|
Dimensione totale stimata (in byte) di tutti gli elementi memorizzati nella cache dei risultati di Gremlin. |
|
Numero di elementi nella cache dei risultati di Gremlin. |
|
Il timestamp dell'elemento più vecchio memorizzato nella cache dei risultati di Gremlin. |
|
Il timestamp dell'elemento più recente memorizzato nella cache dei risultati di Gremlin. |
|
Come metrica a livello di istanza, ServerlessDatabaseCapacity riporta la capacità corrente dell'istanza di una determinata istanza serverless di Neptune, in. NCUs Un'unità di capacità Neptune (NCU, Neptune Capacity Unit) è costituita da 2 GiB (gibibyte) di memoria (RAM) insieme alle reti e alla capacità del processore virtuale (vCPU) associate. A livello di cluster, |
|
La quantità totale di spazio di archiviazione di backup, espressa in byte, utilizzata da tutti gli snapshot per un cluster database Neptune al di fuori della finestra di conservazione dei backup. Incluso nel totale riportato dal parametro |
|
Il numero di errori lato client al secondo in query SPARQL. |
|
Il numero di richieste al secondo al motore SPARQL. |
|
Il numero di errori del server SPARQL al secondo. |
|
Numero totale di istruzioni analizzate per le statistiche DFE dall'avvio del server. Ogni volta che viene attivato il calcolo delle statistiche, questo numero aumenta ma quando non viene eseguito alcun calcolo, rimane statico. Di conseguenza, se lo si rappresenta graficamente nel tempo, è possibile capire quando il calcolo è avvenuto e quando non è avvenuto: 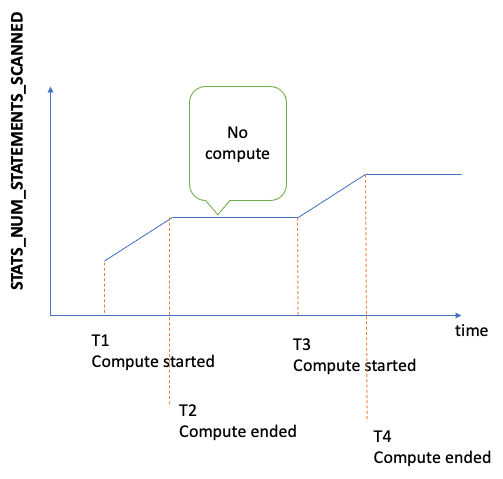
Osservando la pendenza del grafico nei periodi in cui la metrica è in aumento, si può anche capire la velocità di calcolo. Se non esiste una metrica di questo tipo, significa che la funzionalità delle statistiche è disabilitata nel cluster database o che la versione del motore in uso non la include. Se il valore della metrica è zero, significa che non è stato effettuato alcun calcolo delle statistiche. |
|
La quantità di throughput di rete ricevuta dal sottosistema di archiviazione da ogni istanza del cluster Neptune DB. |
StorageNetworkThroughput |
La quantità di throughput di rete ricevuta e inviata al sottosistema di archiviazione da ciascuna istanza del cluster Neptune DB. |
|
La quantità di throughput di rete inviata al sottosistema di archiviazione da ogni istanza del cluster Neptune DB. |
|
La quantità di spazio di scambio utilizzato. |
|
Il numero di IOPS per la lettura e la scrittura sullo storage locale collegato all'istanza DB Neptune. Questo parametro rappresenta un conteggio e viene misurato una volta al secondo. |
|
La quantità di dati trasferiti da e verso l'archiviazione locale associata all'istanza DB Neptune. Questo parametro rappresenta i byte e viene misurato una volta al secondo. |
|
La quantità totale di spazio di archiviazione di backup fatturata per un determinato cluster database Neptune, in byte. Include lo storage di backup misurato dai parametri |
|
Il numero totale di richieste al secondo al server da tutte le origini. |
|
Il numero totale al secondo di richieste che hanno causato errori a causa di problemi lato client. |
|
Il numero totale al secondo di richieste che hanno causato errori nel server a causa di errori interni. |
|
Il numero di log di annullamento nell'elenco dei log di annullamento. I log di annullamento contengono i record delle transazioni sottoposte a commit che scadono quando tutte le transazioni attive sono più recenti dell'ora del commit. I record scaduti vengono eliminati periodicamente. L'eliminazione dei record per le operazioni di eliminazione può richiedere più tempo rispetto ai record per altri tipi di transazione. L'eliminazione viene eseguita esclusivamente dall'istanza di scrittura del cluster database, quindi la velocità di eliminazione dipende dal tipo di istanza di scrittura. Se il valore Inoltre, se si sta effettuando l'aggiornamento alla versione |
|
La quantità totale di archiviazione allocata al cluster database Neptune, espressa in byte. Questa è la quantità di spazio di archiviazione che ti viene fatturata. È la quantità massima di archiviazione allocata al cluster DB in qualsiasi momento della sua esistenza, non la quantità che si sta attualmente utilizzando (consulta Fatturazione dell'archiviazione Neptune). |
|
Il numero totale di operazioni di I/O di lettura fatturate da un volume del cluster è stato riportato a intervalli di 5 minuti. Le operazioni di lettura fatturate sono calcolate a livello del volume del cluster, aggregate da tutte le istanze nel cluster database Neptune e, in seguito, indicate a intervalli di 5 minuti. |
VolumeWriteIOPs |
Il numero totale di operazioni di I/O del disco di scrittura sul volume del cluster, riportate a intervalli di 5 minuti. |
CloudWatch Metriche che ora sono obsolete in Neptune
L'uso di queste metriche Neptune è ora obsoleto. Sono ancora supportati, ma potrebbero essere eliminati in futuro man mano che nuove e migliori metriche diventano disponibili.
Parametro |
Descrizione |
|---|---|
|
Numero di risposte HTTP 1xx per l'endpoint Gremlin al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di risposte HTTP 2xx per l'endpoint Gremlin al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 4xx per l'endpoint Gremlin al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 5xx per l'endpoint Gremlin al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori negli attraversamenti Gremlin. |
|
Numero di richieste al motore Gremlin. |
|
Numero di WebSocket connessioni riuscite all'endpoint Gremlin al secondo. |
|
Numero di errori del WebSocket client sull'endpoint Gremlin al secondo. |
|
Numero di errori del WebSocket server sull'endpoint Gremlin al secondo. |
|
Numero di potenziali WebSocket connessioni attualmente disponibili. |
|
Numero di risposte HTTP 100 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di risposte HTTP 101 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di risposte HTTP 1xx per l'endpoint al secondo. |
|
Numero di risposte HTTP 200 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di risposte HTTP 2xx per l'endpoint al secondo. |
|
Numero di errori HTTP 400 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 403 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 405 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 413 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 429 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 4xx per l'endpoint al secondo. |
|
Numero di errori HTTP 500 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 501 per l'endpoint al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 5xx per l'endpoint al secondo. |
|
Numero di errori delle richieste dello strumento di caricamento. |
|
Numero di richieste dello strumento di caricamento. |
|
Numero di risposte HTTP 1xx per l'endpoint SPARQL al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di risposte HTTP 2xx per l'endpoint SPARQL al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 4xx per l'endpoint SPARQL al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori HTTP 5xx per l'endpoint SPARQL al secondo. Al suo posto, ti consigliamo di utilizzare il nuovo parametro combinato |
|
Numero di errori nelle query SPARQL. |
|
Numero di richieste al motore SPARQL. |
|
Numero di errori dell'endpoint dello stato. |
|
Numero di richieste all'endpoint dello stato. |
