기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Apache Cassandra에서 Amazon Keyspaces로 마이그레이션하기 위한 마이그레이션 계획 생성
Apache Cassandra에서 Amazon Keyspaces로 성공적으로 마이그레이션하려면 해당 마이그레이션 개념 및 모범 사례를 검토하고 사용 가능한 옵션을 비교하는 것이 좋습니다.
이 주제에서는 몇 가지 주요 개념과 사용 가능한 도구 및 기법을 도입하여 마이그레이션 프로세스가 작동하는 방식을 간략하게 설명합니다. 다양한 마이그레이션 전략을 평가하여 요구 사항에 가장 적합한 전략을 선택할 수 있습니다.
주제
기능적 호환성
마이그레이션 전에 Apache Cassandra와 Amazon Keyspaces의 기능적 차이점을 신중하게 고려하세요. Amazon Keyspaces는 키스페이스 및 테이블 생성, 데이터 읽기, 데이터 쓰기 등 일반적으로 사용되는 모든 Cassandra 데이터 플레인 작업을 지원합니다.
하지만 일부 Cassandra API는 Amazon Keyspaces에서 지원하지 않습니다. 지원되는 API에 대한 자세한 내용은 지원되는 Cassandra API, 작업, 함수, 데이터 유형 섹션을 참조하세요. Amazon Keyspaces와 Apache Cassandra 간의 모든 기능적 차이점에 대한 개요는 기능적 차이: Amazon Keyspaces와 Apache Cassandra 섹션을 참조하세요.
Amazon Keyspaces에서 지원되는 기능과 사용 중인 Cassandra API 및 스키마를 비교하려면 GitHub
호환성 스크립트 사용 방법
GitHub
에서 호환성 Python 스크립트를 다운로드하여 기존 Apache Cassandra 클러스터에 액세스할 수 있는 위치로 이동합니다. 호환성 스크립트는
CQLSH와 유사한 파라미터를 사용합니다.--host및--port에 클러스터의 Cassandra 노드 중 하나에 쿼리를 연결하고 실행하는 데 사용하는 IP 주소와 포트를 입력합니다.Cassandra 클러스터가 인증을 사용하는 경우
-username및-password도 제공해야 합니다. 호환성 스크립트를 실행하려면 다음 명령을 사용할 수 있습니다.python toolkit-compat-tool.py --hosthostname or IP-u "username" -p "password" --portnative transport port
Amazon Keyspaces 요금 추정
이 섹션에서는 Amazon Keyspaces의 예상 비용을 계산하기 위해 Apache Cassandra 테이블에서 수집해야 하는 정보에 대한 개요를 제공합니다. 각 테이블에는 서로 다른 데이터 유형이 필요하며, 서로 다른 CQL 쿼리를 지원해야 하고, 고유한 읽기/쓰기 트래픽을 유지해야 합니다.
테이블을 기반으로 요구 사항을 고려하면 Amazon Keyspaces 테이블 수준 리소스 격리 및 읽기/쓰기 처리량 용량 모드와 일치합니다. Amazon Keyspaces를 사용하면 테이블의 읽기/쓰기 용량과 자동 조정 정책을 독립적으로 정의할 수 있습니다.
테이블 요구 사항을 이해하면 기능, 비용 및 마이그레이션 노력에 따라 마이그레이션을 위한 테이블의 우선순위를 정하는 데 도움이 됩니다.
마이그레이션 전에 다음 Cassandra 테이블 지표를 수집합니다. 이 정보는 Amazon Keyspaces에서 워크로드 비용을 추정하는 데 도움이 됩니다.
테이블 이름 - 정규화된 키스페이스의 이름과 테이블 이름입니다.
설명 - 테이블의 사용 방식 또는 테이블에 저장되는 데이터 유형과 같은 테이블에 대한 설명입니다.
초당 평균 읽기 - 장기간 동안 테이블에 대한 좌표 수준 읽기의 평균 횟수입니다.
초당 평균 쓰기 - 장기간 동안 테이블에 대한 좌표 수준 쓰기의 평균 횟수입니다.
바이트 단위의 평균 행 크기 - 바이트 단위의 평균 행 크기입니다.
스토리지 크기(GB) - 테이블의 원시 스토리지 크기입니다.
읽기 일관성 분석 - 최종 일관성(
LOCAL_ONE또는ONE)과 강력한 일관성(LOCAL_QUORUM)을 사용하는 읽기의 백분율입니다.
이 표는 마이그레이션을 계획할 때 함께 가져와야 하는 테이블에 대한 정보의 예를 보여줍니다.
| 테이블 이름 | 설명 | 초당 평균 읽기 | 초당 평균 쓰기 | 바이트 단위의 평균 행 크기 | 스토리지 크기(GB) | 읽기 일관성 분석 |
|---|---|---|---|---|---|---|
|
mykeyspace.mytable |
장바구니 기록을 저장하는 데 사용 |
10,000 |
5,000 |
2,200 |
2,000 |
100% |
mykeyspace.mytable2 |
최신 프로필 정보를 저장하는 데 사용 |
20,000건 |
1,000 |
850 |
1,000 |
25% |
테이블 지표를 수집하는 방법
이 섹션에서는 기존 Cassandra 클러스터에서 필요한 테이블 지표를 수집하는 방법에 대한 단계별 지침을 제공합니다. 이러한 지표에는 행 크기, 테이블 크기 및 초당 읽기/쓰기 요청(RPS)이 포함됩니다. 이를 통해 Amazon Keyspaces 테이블에 대한 처리량 용량 요구 사항을 평가하고 가격을 추정할 수 있습니다.
Cassandra 소스 테이블에서 테이블 지표를 수집하는 방법
행 크기 결정
행 크기는 Amazon Keyspaces에서 읽기 용량 및 쓰기 용량 사용률을 결정하는 데 중요합니다. 다음 다이어그램은 Cassandra 토큰 범위에 대한 일반적인 데이터 배포를 보여줍니다.
GitHub
에서 사용할 수 있는 행 크기 샘플러 스크립트를 사용하여 Cassandra 클러스터의 각 테이블에 대한 행 크기 지표를 수집할 수 있습니다. 스크립트는
cqlsh및awk를 사용하여 구성 가능한 테이블 데이터 샘플 세트에 대한 행 크기의 최소, 최대, 평균 및 표준 편차를 계산하여 Apache Cassandra에서 테이블 데이터를 내보냅니다. 행 크기 샘플러는 인수를cqlsh에 전달하므로 동일한 파라미터를 사용하여 Cassandra 클러스터를 연결하고 읽을 수 있습니다.다음 문은 이에 대한 예입니다.
./row-size-sampler.sh10.22.33.449142 \\ -u "username" -p "password" --sslAmazon Keyspaces에서 행 크기를 계산하는 방법에 대한 자세한 내용은 Amazon Keyspaces에서 행 크기 추정 섹션을 참조하세요.
테이블 크기 결정
Amazon Keyspaces를 사용하면 스토리지를 미리 프로비저닝할 필요가 없습니다. Amazon Keyspaces는 테이블의 청구 가능 크기를 지속적으로 모니터링하여 스토리지 요금을 결정합니다. 스토리지는 월별 GB로 결제됩니다. Amazon Keyspaces 테이블 크기는 단일 복제본의 원시 크기(압축되지 않음)를 기반으로 합니다.
Amazon Keyspaces에서 테이블 크기를 모니터링하려면 AWS Management Console의 각 테이블에 대해 표시되는 지표
BillableTableSizeInBytes를 사용할 수 있습니다.Amazon Keyspaces 테이블의 청구 가능 크기를 추정하려면 다음 두 가지 방법 중 하나를 사용할 수 있습니다.
평균 행 크기를 사용하고 숫자 또는 행을 곱합니다.
평균 행 크기에 Cassandra 소스 테이블의 행 수를 곱하여 Amazon Keyspaces 테이블의 크기를 추정할 수 있습니다. 이전 섹션의 행 크기 샘플 스크립트를 사용하여 평균 행 크기를 캡처합니다. 행 수를 캡처하려면
dsbulk count와 같은 도구를 사용하여 소스 테이블의 총 행 수를 확인할 수 있습니다.nodetool을 사용하여 테이블 메타데이터를 수집합니다.Nodetool은 Apache Cassandra 배포에서 제공되는 관리 도구로, Cassandra 프로세스의 상태에 대한 통찰력을 제공하고 테이블 메타데이터를 반환합니다.nodetool을 사용하여 테이블 크기에 대한 메타데이터를 샘플링하고 Amazon Keyspaces에서 테이블 크기를 추론할 수 있습니다.사용할 명령은
nodetool tablestats입니다. Tablestats는 테이블의 크기와 압축 비율을 반환합니다. 테이블의 크기는 테이블의tablelivespace로 저장되며compression ratio로 나눌 수 있습니다. 그런 다음 이 크기 값을 노드 수로 곱합니다. 마지막으로 복제 인수(일반적으로 3)로 나눕니다.테이블 크기를 평가하는 데 사용할 수 있는 계산의 전체 공식입니다.
((tablelivespace / compression ratio) * (total number of nodes))/ (replication factor)Cassandra 클러스터에 12개의 노드가 있다고 가정해 보겠습니다.
nodetool tablestats명령을 실행하면 200GB의tablelivespace와 0.5의compression ratio가 반환됩니다. 키스페이스의 복제 계수는 3입니다.이 예제의 계산은 다음과 같습니다.
(200 GB / 0.5) * (12 nodes)/ (replication factor of 3) = 4,800 GB / 3 = 1,600 GB is the table size estimate for Amazon Keyspaces
읽기 및 쓰기 수 캡처
Amazon Keyspaces 테이블의 용량 및 크기 조정 요구 사항을 확인하려면 마이그레이션 전에 Cassandra 테이블의 읽기 및 쓰기 요청 속도를 캡처합니다.
Amazon Keyspaces는 서버리스이며 사용한 비용만 지불하면 됩니다. 일반적으로 Amazon Keyspaces의 읽기/쓰기 처리량 가격은 요청 수와 크기를 기반으로 합니다.
Amazon Keyspaces에는 두 가지 용량 모드가 있습니다.
온디맨드 - 용량을 계획할 필요 없이 초당 수천 개의 요청을 처리할 수 있는 유연한 청구 옵션입니다. 읽기 및 쓰기 요청에 대해 요청당 지불 가격을 제공하므로 사용하는 만큼에 대해서만 비용을 지불하면 됩니다.
프로비저닝됨 - 프로비저닝된 처리량 용량 모드를 선택하는 경우 애플리케이션에 필요한 초당 읽기 및 쓰기 횟수를 지정합니다. 이렇게 하면 Amazon Keyspaces 사용량을 관리하여 정의된 요청 속도 이하로 유지하여 예측 가능성을 유지할 수 있습니다.
프로비저닝 모드는 오토 스케일링을 제공하므로 프로비저닝된 속도를 자동으로 조정하여 규모를 늘리거나 축소하여 운영 효율성을 개선할 수 있습니다. 서버리스 리소스 관리에 대한 자세한 정보는 Amazon Keyspaces(Apache Cassandra용)에서 서버리스 리소스 관리 섹션을 참조하세요.
Amazon Keyspaces에서 읽기 및 쓰기 처리량 용량을 별도로 프로비저닝하므로 기존 테이블의 읽기 및 쓰기 요청 속도를 독립적으로 측정해야 합니다.
기존 Cassandra 클러스터에서 가장 정확한 사용률 지표를 수집하려면 단일 데이터 센터의 모든 노드에서 집계되는 테이블에 대해 장기간 동안 조정자 수준 읽기 및 쓰기 작업에 대한 RPS(초당 평균 요청)를 캡처합니다.
다음 다이어그램과 같이 최소 몇 주 동안 평균 RPS를 캡처하면 트래픽 패턴의 피크와 밸리가 캡처됩니다.
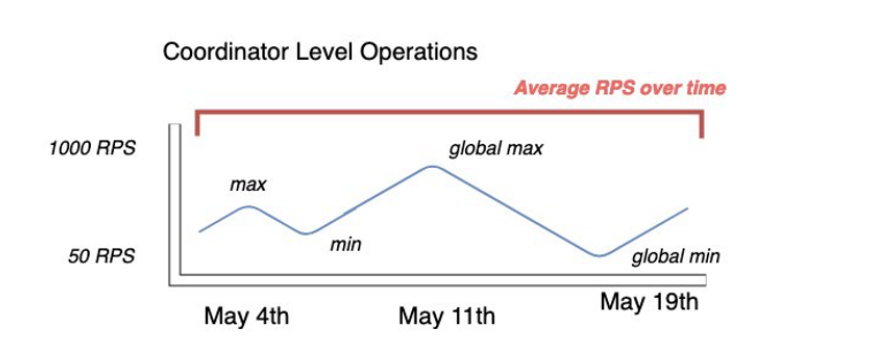
Cassandra 테이블의 읽기 및 쓰기 요청 속도를 결정하는 두 가지 옵션이 있습니다.
기존 Cassandra 모니터링 사용
다음 표에 표시된 지표를 사용하여 읽기 및 쓰기 요청을 관찰할 수 있습니다. 지표 이름은 사용 중인 모니터링 도구에 따라 변경될 수 있습니다.
측정 기준 Cassandra JMX 지표 쓰기
org.apache.cassandra.metrics:type=ClientRequest, scope=Write,name=Latency#Count읽기
org.apache.cassandra.metrics:type=ClientRequest, scope=Read,name=Latency#Countnodetool사용nodetool tablestats및nodetool info를 사용하여 테이블에서 평균 읽기 및 쓰기 작업을 캡처합니다.tablestats는 노드가 시작된 시간부터 총 읽기 및 쓰기 수를 반환합니다.nodetool info는 노드의 가동 시간을 초 단위로 제공합니다.읽기 및 쓰기의 초당 평균을 받으려면 읽기 및 쓰기 수를 노드 가동 시간으로 초 단위로 나눕니다. 그런 다음 읽기의 경우 복제 계수로 나눈 쓰기에 대한 일관성 수준 광고로 나눕니다. 이러한 계산은 다음 공식으로 표현됩니다.
초당 평균 읽기 수식:
((number of reads * number of nodes in cluster) / read consistency quorum (2)) / uptime초당 평균 쓰기 수식:
((number of writes * number of nodes in cluster) / replication factor of 3) / uptime4주 동안 가동된 12개의 노드 클러스터가 있다고 가정해 보겠습니다.
nodetool info는 2,419,200초의 가동 시간을 반환하고nodetool tablestats는 10억 개의 쓰기와 20억 개의 읽기를 반환합니다. 이 예제에서는 다음과 같은 계산을 수행합니다.((2 billion reads * 12 in cluster) / read consistency quorum (2)) / 2,419,200 seconds = 12 billion reads / 2,419,200 seconds = 4,960 read request per second ((1 billion writes * 12 in cluster) / replication factor of 3) / 2,419,200 seconds = 4 billion writes / 2,419,200 seconds = 1,653 write request per second
테이블의 용량 사용률 결정
평균 용량 사용률을 추정하려면 Cassandra 소스 테이블의 평균 요청 속도와 평균 행 크기로 시작합니다.
Amazon Keyspaces는 읽기 용량 단위(RCU) 및 쓰기 용량 단위(WCU)를 사용하여 테이블에 대한 읽기 및 쓰기의 프로비저닝된 처리량 용량을 측정합니다. 이 추정치에서는 이러한 단위를 사용하여 마이그레이션 후 새 Amazon Keyspaces 테이블의 읽기 및 쓰기 용량 요구 사항을 계산합니다.
이 주제의 뒷부분에서는 프로비저닝된 용량 모드와 온디맨드 용량 모드 중에서 선택한 것이 결제에 어떤 영향을 미치는지 설명합니다. 그러나 이 예제의 용량 사용률 추정치를 위해 테이블이 프로비저닝된 모드라고 가정합니다.
읽기 - RCU 1은 최대 4KB 크기의 행에 대한
LOCAL_QUORUM읽기 요청 1회 또는LOCAL_ONE읽기 요청 2회를 나타냅니다. 4KB보다 큰 행을 읽어야 하는 경우 읽기 작업에 추가 RCU가 사용됩니다. 필요한 총 RCU 수는 행 크기,LOCAL_QUORUM또는LOCAL_ONE읽기 일관성을 사용하려는지 여부에 따라 다릅니다.예를 들어 8KB 행을 읽으려면
LOCAL_QUORUM읽기 일관성을 사용하는 2RCU가 필요하고LOCAL_ONE읽기 일관성을 선택한 경우 1RCU가 필요합니다.쓰기 - WCU 1은 최대 1KB 크기의 행에 대한 1회의 쓰기를 나타냅니다. 모든 쓰기는
LOCAL_QUORUM일관성을 사용하며 간단한 트랜잭션(LWT) 사용에 대한 추가 비용은 없습니다.필요한 WCU의 총 수는 행 크기에 따라 달라집니다. 1KB보다 큰 행을 써야 하는 경우 쓰기 작업에 추가 WCU가 사용됩니다. 예를 들어 행 크기가 2KB인 경우 쓰기 요청 하나를 수행하려면 2WCU가 필요합니다.
다음 공식을 사용하여 필요한 RCU 및 WCU를 추정할 수 있습니다.
RCU의 읽기 용량은 초당 읽기 수에 읽기당 읽기 행 수를 곱하고 평균 행 크기를 4KB로 나눈 다음 가장 가까운 정수로 반올림하여 결정할 수 있습니다.
WCU의 쓰기 용량은 요청 수에 평균 행 크기를 1KB로 나누고 가장 가까운 정수로 반올림하여 결정할 수 있습니다.
이는 다음 공식으로 표현됩니다.
Read requests per second * ROUNDUP((Average Row Size)/4096 per unit) = RCUs per second Write requests per second * ROUNDUP(Average Row Size/1024 per unit) = WCUs per second예를 들어 Cassandra 테이블에서 행 크기가 2.5KB인 4,960개의 읽기 요청을 수행하는 경우 Amazon Keyspaces에 4,960RCU가 필요합니다. 현재 Cassandra 테이블에서 행 크기가 2.5KB인 초당 1,653개의 쓰기 요청을 수행하는 경우 Amazon Keyspaces에서 초당 4,959WCU가 필요합니다.
이 예제는 다음 공식으로 표현됩니다.
4,960 read requests per second * ROUNDUP( 2.5KB /4KB bytes per unit) = 4,960 read requests per second * 1 RCU = 4,960 RCUs 1,653 write requests per second * ROUNDUP(2.5KB/1KB per unit) = 1,653 requests per second * 3 WCUs = 4,959 WCUseventual consistency를 사용하면 각 읽기 요청에서 처리량 용량의 최대 절반을 절약할 수 있습니다. 최종적으로 일관된 각 읽기는 최대 8KB를 소비할 수 있습니다. 다음 공식과 같이 이전 계산에 0.5를 곱하여 최종적으로 일관된 읽기를 계산할 수 있습니다.4,960 read requests per second * ROUNDUP( 2.5KB /4KB per unit) * .5 = 2,480 read request per second * 1 RCU = 2,480 RCUs-
Amazon Keyspaces에 대한 월별 요금 추정 계산
읽기/쓰기 용량 처리량을 기준으로 테이블의 월별 결제를 추정하려면 다른 공식을 사용하여 온디맨드 및 프로비저닝 모드의 요금을 계산하고 테이블의 옵션을 비교할 수 있습니다.
프로비저닝 모드 - 읽기 및 쓰기 용량 소비량은 초당 용량 단위를 기준으로 시간당 요금으로 청구됩니다. 먼저 이 비율을 0.7로 나누어 기본 오토 스케일링 대상 사용률 70%를 나타냅니다. 그런 다음 역일 기준 30일, 하루 24시간 및 지역 요금 요금을 곱합니다.
이 계산은 다음 공식에 요약되어 있습니다.
(read capacity per second / .7) * 24 hours * 30 days * regional rate (write capacity per second / .7) * 24 hours * 30 days * regional rate온디맨드 모드 - 읽기 및 쓰기 용량은 요청 속도당 요금으로 청구됩니다. 먼저 요청 속도를 30일, 하루 24시간으로 곱합니다. 그런 다음 요청 단위를 100만 단위로 나눕니다. 마지막으로 리전 비율을 곱합니다.
이 계산은 다음 공식에 요약되어 있습니다.
((read capacity per second * 30 * 24 * 60 * 60) / 1 Million read request units) * regional rate ((write capacity per second * 30 * 24 * 60 * 60) / 1 Million write request units) * regional rate
마이그레이션 전략을 선택합니다.
Apache Cassandra에서 Amazon Keyspaces로 마이그레이션할 때 다음 마이그레이션 전략 중에서 선택할 수 있습니다.
온라인 - 이중 쓰기를 사용하여 Amazon Keyspaces와 Cassandra 클러스터에 새 데이터를 동시에 쓰기 시작하는 실시간 마이그레이션입니다. 이 마이그레이션 유형은 마이그레이션 중에 가동 중지 시간이 없고 쓰기 일관성 이후 읽기가 필요한 애플리케이션에 권장됩니다.
온라인 마이그레이션 전략을 계획하고 구현하는 방법에 대한 자세한 내용은 Amazon Keyspaces로 온라인 마이그레이션: 전략 및 모범 사례 섹션을 참조하세요.
오프라인 - 이 마이그레이션 기법에는 가동 중지 시간 동안 Cassandra에서 Amazon Keyspaces로 데이터세트를 복사하는 작업이 포함됩니다. 오프라인 마이그레이션은 애플리케이션을 변경하거나 기록 데이터와 새 쓰기 간에 충돌을 해결할 필요가 없기 때문에 마이그레이션 프로세스를 간소화할 수 있습니다.
오프라인 마이그레이션을 계획하는 방법에 대한 자세한 내용은 오프라인 마이그레이션 프로세스: Apache Cassandra에서 Amazon Keyspaces로 섹션을 참조하세요.
하이브리드 - 이 마이그레이션 기술을 사용하면 변경 사항을 Amazon Keyspaces에 거의 실시간으로 복제할 수 있지만 쓰기 일관성 후에는 읽지 않아도 됩니다.
하이브리드 마이그레이션을 계획하는 방법에 대한 자세한 내용은 하이브리드 마이그레이션 솔루션 사용: Apache Cassandra에서 Amazon Keyspaces로 섹션을 참조하세요.
이 주제에서 설명한 마이그레이션 기법과 모범 사례를 검토한 후 의사 결정 트리에 사용 가능한 옵션을 배치하여 요구 사항과 사용 가능한 리소스에 따라 마이그레이션 전략을 설계할 수 있습니다.
