기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
온라인 마이그레이션 중에 새 데이터 쓰기
온라인 마이그레이션 계획의 첫 번째 단계는 애플리케이션에서 작성한 모든 새 데이터가 데이터베이스, 기존 Cassandra 클러스터 및 Amazon Keyspaces 모두에 저장되도록 하는 것입니다. 목표는 두 데이터 스토어에서 일관된 뷰를 제공하는 것입니다. 두 데이터베이스 모두에 새 쓰기를 모두 적용하여 이 작업을 수행할 수 있습니다. 이중 쓰기를 구현하려면 다음 세 가지 옵션 중 하나를 고려하세요.
Amazon Keyspaces 마이그레이션을 위한 ZDM 이중 쓰기 프록시 - Github
에서 사용할 수 있는 Amazon Keyspaces용 ZDM 프록시를 사용하면 애플리케이션 가동 중지 없이 Apache Cassandra 워크로드를 Amazon Keyspaces로 마이그레이션할 수 있습니다. 이 향상된 솔루션은 AWS 모범 사례를 구현하고 공식 ZDM 프록시 기능을 확장합니다. -
Apache Cassandra와 Amazon Keyspaces 간에 온라인 마이그레이션을 수행합니다.
-
애플리케이션을 리팩터링하지 않고 소스 테이블과 대상 테이블 모두에 동시에 데이터를 씁니다.
-
이중 읽기 작업을 통해 쿼리를 검증합니다.
이 솔루션은 AWS 및 Amazon Keyspaces와 함께 사용할 수 있도록 다음과 같은 향상된 기능을 제공합니다.
-
컨테이너 배포 - VPC 액세스 가능 배포를 위해 Amazon Elastic Container Registry(Amazon ECR)의 사전 구성된 Docker 이미지를 사용합니다.
-
코드형 인프라 - 자동 설정을 위한 AWS CloudFormation 템플릿을 사용하여 배포합니다 AWS Fargate.
-
Amazon Keyspaces 호환성 - Amazon Keyspaces에 대한 사용자 지정 적응을 통해 시스템 테이블에 액세스합니다.
이 솔루션은 Fargate를 사용하는 Amazon ECS에서 실행되므로 워크로드 요구 사항에 따라 서버리스 확장성을 제공합니다. Network Load Balancer는 고가용성을 위해 여러 Amazon ECS 작업에 수신 애플리케이션 트래픽을 분산합니다.

-
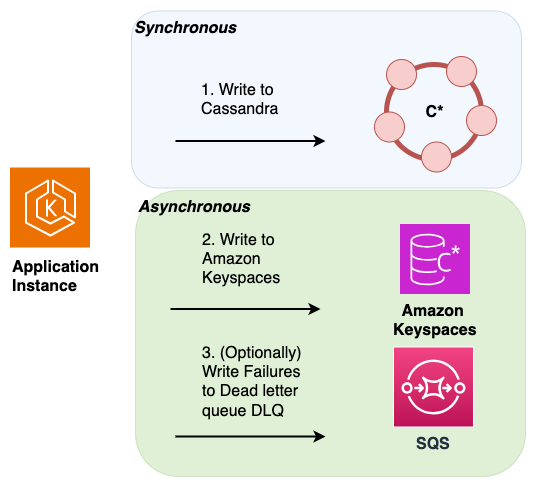
애플리케이션 이중 쓰기 - 기존 Cassandra 클라이언트 라이브러리 및 드라이버를 활용하여 애플리케이션 코드를 최소한으로 변경하여 이중 쓰기를 구현할 수 있습니다. 기존 애플리케이션에서 이중 쓰기를 구현하거나 아키텍처에서 새 계층을 생성하여 이중 쓰기를 처리할 수 있습니다. 기존 애플리케이션에서 이중 쓰기가 구현된 방법을 보여주는 고객 사례 연구 및 자세한 내용은 Cassandra 마이그레이션 사례 연구 섹션
을 참조하세요. 이중 쓰기를 구현할 때 하나의 데이터베이스를 리더로 지정하고 다른 데이터베이스를 팔로워로 지정할 수 있습니다. 이렇게 하면 팔로워 또는 대상 데이터베이스가 애플리케이션의 중요 경로를 중단하지 않고 원본 소스 또는 리더 데이터베이스에 계속 쓸 수 있습니다.
팔로워에 실패한 쓰기를 다시 시도하는 대신 Amazon Simple Queue Service를 사용하여 Dead Letter Queue(DLQ)에 실패한 쓰기를 기록할 수 있습니다. DLQ를 사용하면 팔로워에 대한 실패한 쓰기를 분석하고 대상 데이터베이스에서 처리가 성공하지 못한 이유를 확인할 수 있습니다.
보다 정교한 이중 쓰기 구현을 위해 Saga 패턴을 사용하여 일련의 로컬 트랜잭션을 설계하는 AWS 모범 사례를 따를 수 있습니다. 사가 패턴은 트랜잭션이 실패하면 사가에서 보정 트랜잭션을 실행하여 이전 트랜잭션에서 수행한 데이터베이스 변경 내용을 되돌립니다.
온라인 마이그레이션에 이중 쓰기를 사용하는 경우 각 쓰기가 로컬 트랜잭션이 되도록 사가 패턴에 따라 이중 쓰기를 구성하여 이기종 데이터베이스에서 원자 작업을 보장할 수 있습니다. 에 권장되는 설계 패턴을 사용하여 분산 애플리케이션을 설계하는 방법에 대한 자세한 내용은 클라우드 설계 패턴, 아키텍처 및 구현을 AWS 클라우드참조하세요. https://docs.aws.amazon.com/prescriptive-guidance/latest/cloud-design-patterns/introduction
메시징 계층 이중 쓰기 - 애플리케이션 계층에서 이중 쓰기를 구현하는 대신 기존 메시징 계층을 사용하여 Cassandra 및 Amazon Keyspaces에 이중 쓰기를 수행할 수 있습니다.
이렇게 하려면 메시징 플랫폼에 추가 소비자를 구성하여 두 데이터 스토어에 쓰기를 보낼 수 있습니다. 이 접근 방식은 메시징 계층을 사용하여 두 데이터베이스 모두에서 최종적으로 일관된 두 가지 보기를 생성하는 간단한 로우 코드 전략을 제공합니다.
