기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
오프라인 마이그레이션 프로세스: Apache Cassandra에서 Amazon Keyspaces로
오프라인 마이그레이션은 마이그레이션을 수행하기 위한 가동 중지 시간을 감당할 수 있는 경우에 적합합니다. 패치, 대규모 릴리스 또는 하드웨어 업그레이드 또는 주요 업그레이드에 대한 가동 중지 시간을 위한 유지 관리 기간이 있는 것은 기업에서 흔히 발생합니다. 오프라인 마이그레이션은 이 창을 사용하여 데이터를 복사하고 Apache Cassandra에서 Amazon Keyspaces로 애플리케이션 트래픽을 전환할 수 있습니다.
오프라인 마이그레이션은 Cassandra와 Amazon Keyspaces에 동시에 통신할 필요가 없기 때문에 애플리케이션 수정을 줄입니다. 또한 데이터 흐름이 일시 중지된 경우 뮤테이션을 유지하지 않고도 정확한 상태를 복사할 수 있습니다.
이 예제에서는 Amazon Simple Storage Service(Amazon S3)를 오프라인 마이그레이션 중에 데이터의 스테이징 영역으로 사용하여 가동 중지 시간을 최소화합니다. Spark Cassandra 커넥터 및 AWS Glue를 사용하여 Amazon S3의 Parquet 형식으로 저장한 데이터를 Amazon Keyspaces 테이블로 자동으로 가져올 수 있습니다. 다음 섹션에서는 프로세스의 상위 수준 개요를 보여줍니다. 이 프로세스의 코드 예제는 Github
Amazon S3를 사용하여 Apache Cassandra에서 Amazon Keyspaces로 오프라인 마이그레이션 프로세스를 수행하려면 다음 AWS Glue 작업이 AWS Glue 필요합니다.
CQL 데이터를 추출 및 변환하여 Amazon S3 버킷에 저장하는 ETL 작업입니다.
버킷에서 Amazon Keyspaces로 데이터를 가져오는 두 번째 작업입니다.
증분 데이터를 가져오는 세 번째 작업입니다.
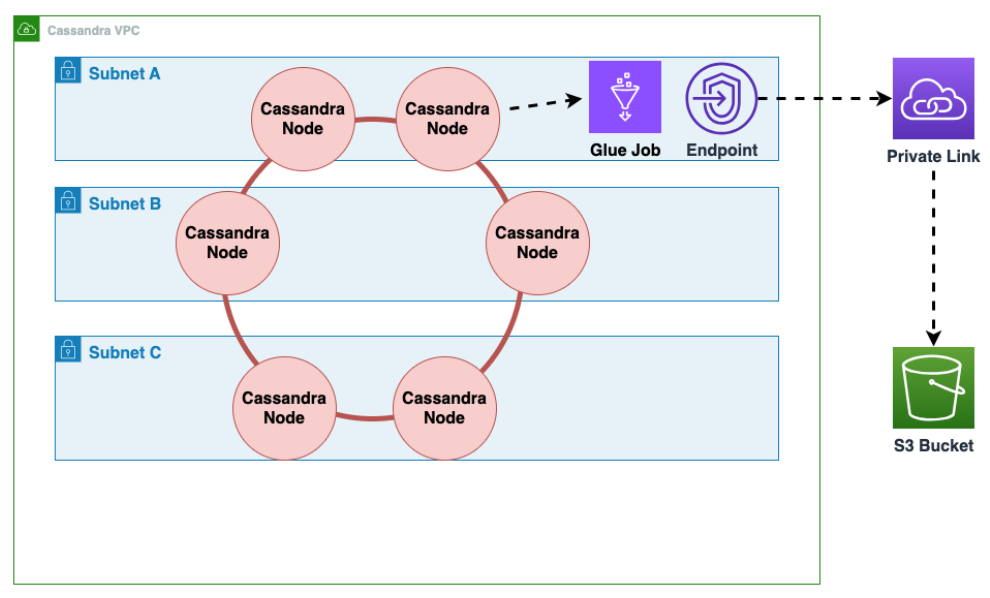
Amazon Virtual Private Cloud의 Amazon EC2에서 실행되는 Cassandra에서 Amazon Keyspaces로 오프라인 마이그레이션을 수행하는 방법
먼저 AWS Glue 를 사용하여 Cassandra에서 Parquet 형식으로 테이블 데이터를 내보내고 Amazon S3 버킷에 저장합니다. Cassandra를 실행하는 Amazon EC2 인스턴스가 있는 VPC에 대한 AWS Glue 커넥터를 사용하여 AWS Glue 작업을 실행해야 합니다. 그런 다음 Amazon S3 프라이빗 엔드포인트를 사용하여 Amazon S3 버킷에 데이터를 저장할 수 있습니다.
다음 다이어그램은 이러한 단계를 보여줍니다.
Amazon S3 버킷의 데이터를 셔플하여 데이터 무작위화를 개선합니다. 균등하게 가져온 데이터를 사용하면 대상 테이블에서 더 많은 분산 트래픽을 사용할 수 있습니다.
이 단계는 대규모 파티션(1,000개 이상의 행이 있는 파티션)이 있는 Cassandra에서 데이터를 내보내는 경우 Amazon Keyspaces에 데이터를 삽입할 때 단축키 패턴을 피하기 위해 필요합니다. 핫 키 문제는 Amazon Keyspaces의
WriteThrottleEvents에서 발생하며 로드 시간이 늘어납니다.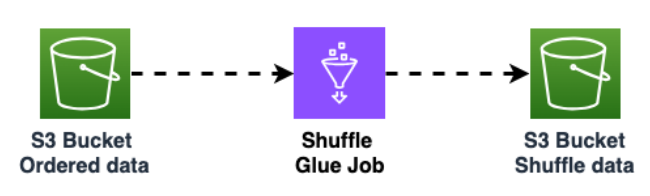
다른 AWS Glue 작업을 사용하여 Amazon S3 버킷에서 Amazon Keyspaces로 데이터를 가져옵니다. Amazon S3 버킷의 셔플 데이터는 Parquet 형식으로 저장됩니다.
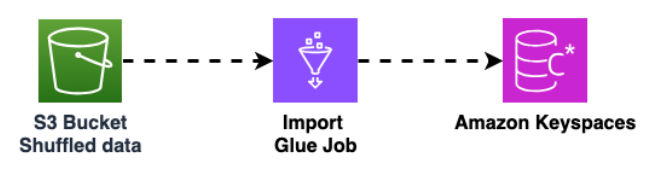
오프라인 마이그레이션 프로세스에 대한 자세한 내용은를 사용한 Amazon Keyspaces AWS Glue
