O conector do Amazon Athena para o Amazon MSK
Esse conector não usa o Glue Connections para centralizar as propriedades de configuração no Glue. A configuração da conexão é feita por meio do Lambda.
Pré-requisitos
Implante o conector na sua Conta da AWS usando o console do Athena ou o AWS Serverless Application Repository. Para obter mais informações, consulte Criar uma conexão de fonte de dados ou Usar o AWS Serverless Application Repository para implantar um conector de fonte de dados.
Limitações
-
Não há suporte para operações de gravação de DDL.
-
Quaisquer limites relevantes do Lambda. Para obter mais informações, consulte Cotas do Lambda no Guia do desenvolvedor do AWS Lambda.
-
Em condições de filtro, você deve converter os tipos de dados date e timestamp para os tipos de dados apropriados.
-
Os tipos de dados de data e carimbo de data/hora não são compatíveis com o tipo de arquivo CSV e são tratados como valores varchar.
-
Não há suporte para o mapeamento em campos JSON aninhados. O conector mapeia somente os campos de nível superior.
-
O conector não é compatível com tipos complexos. Tipos complexos são interpretados como strings.
-
Para extrair ou trabalhar com valores JSON complexos, use as funções relacionadas ao JSON disponíveis no Athena. Para ter mais informações, consulte Extrair dados JSON de strings.
-
O conector não oferece suporte ao acesso a metadados de mensagens do Kafka.
Termos
-
Manipulador de metadados: um manipulador Lambda que recupera metadados da sua instância de banco de dados.
-
Manipulador de registros: um manipulador Lambda que recupera registros de dados da sua instância de banco de dados.
-
Manipulador composto: um manipulador Lambda que recupera tanto metadados quanto registros de dados da sua instância de banco de dados.
-
Endpoint do Kafka: uma string de texto que estabelece uma conexão com uma instância do Kafka.
Compatibilidade de cluster
O conector MSK pode ser usado com os seguintes tipos de cluster:
-
Cluster provisionado pelo MSK: você especifica, monitora e escala manualmente a capacidade do cluster.
-
Cluster do MSK Serverless: fornece uma capacidade sob demanda que é escalada automaticamente conforme a escalabilidade de E/S da aplicação.
-
Kafka dedicado: uma conexão direta com o Kafka (autenticada ou não autenticada).
Métodos de autenticação compatíveis
O conector é compatível com os métodos de autenticação a seguir.
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NO_AUTH
Para ter mais informações, consulte Configuração da autenticação para o conector MSK do Athena.
Formatos de dados de entrada compatíveis
O conector é compatível com os seguintes formatos de dados de entrada:
-
JSON
-
CSV
Parâmetros
Use os parâmetros nesta seção para configurar o conector do MSK para o Athena.
-
auth_type: especifica o tipo de autenticação do cluster. O conector é compatível com os tipos de autenticação a seguir:
-
NO_AUTH: conexão direta ao Kafka sem autenticação (por exemplo, um cluster do Kafka implantado em uma instância do EC2 que não usa autenticação).
-
SASL_SSL_PLAIN: esse método usa o protocolo de segurança
SASL_SSLe o mecanismo SASLPLAIN. -
SASL_PLAINTEXT_PLAIN: esse método usa o protocolo de segurança
SASL_PLAINTEXTe o mecanismo SASLPLAIN.nota
Os tipos de autenticação
SASL_SSL_PLAINeSASL_PLAINTEXT_PLAINsão compatíveis com o Apache Kafka, mas não no Amazon MSK. -
SASL_SSL_AWS_MSK_IAM: o controle de acesso do IAM para o Amazon MSK permite que você gerencie a autenticação e a autorização para o cluster do MSK. As credenciais da AWS do seu usuário (chave secreta e chave de acesso) serão usadas para se conectar ao cluster. Para obter mais informações, consulte IAM access control (Controle de acesso do IAM) no Guia do desenvolvedor do Amazon Managed Streaming for Apache Kafka.
-
SASL_SSL_SCRAM_SHA512: você pode usar esse tipo de autenticação para controlar o acesso aos seus clusters do Amazon MSK. Esse método armazena o nome do usuário e a senha no AWS Secrets Manager. O segredo deve estar associado ao cluster do Amazon MSK. Para obter mais informações, consulte Setting up SASL/SCRAM authentication for an Amazon MSK cluster (Configuração da autenticação SASL/SCRAM para um cluster do Amazon MSK) no Guia do desenvolvedor do Amazon Managed Streaming for Apache Kafka.
-
SSL: a autenticação SSL usa os arquivos de armazenamento de chaves e de armazenamento confiável para se conectar ao cluster do Amazon MSK. Você deve gerar os arquivos de armazenamento confiável e de armazenamento de chaves, carregá-los em um bucket do Amazon S3 e fornecer a referência ao Amazon S3 ao implantar o conector. O armazenamento de chaves, o armazenamento confiável e a chave SSL serão armazenados no AWS Secrets Manager. Seu cliente deve fornecer a chave secreta da AWS ao implantar o conector. Para obter mais informações, consulte Mutual TLS authentication (Autenticação mútua TLS) no Guia do desenvolvedor do Amazon Managed Streaming for Apache Kafka.
Para ter mais informações, consulte Configuração da autenticação para o conector MSK do Athena.
-
-
certificates_s3_reference: o local do Amazon S3 que contém os certificados (os arquivos de armazenamento de chaves e de armazenamento confiável).
-
disable_spill_encryption: (opcional) quando definido como
True, desativa a criptografia do derramamento. É padronizado comoFalse, para que os dados transmitidos para o S3 sejam criptografados usando o AES-GCM — usando uma chave gerada aleatoriamente ou o KMS para gerar chaves. Desativar a criptografia do derramamento pode melhorar a performance, especialmente se o local do derramamento usar criptografia no lado do servidor. -
kafka_endpoint: os detalhes do endpoint a serem fornecidos para o Kafka. Por exemplo, para um cluster do Amazon MSK, você fornece um URL de inicialização para o cluster.
-
secrets_manager_secret: o nome do segredo da AWS no qual as credenciais são salvas. Esse parâmetro não é necessário para a autenticação do IAM.
-
Parâmetros de vazamento: as funções do Lambda armazenam temporariamente dados (“de vazamentos”) que não cabem na memória do Amazon S3. Todas as instâncias do banco de dados acessadas pela mesma função do Lambda derramam no mesmo local. Use os parâmetros na tabela a seguir para especificar o local do vazamento.
Parâmetro Descrição spill_bucketObrigatório. O nome do bucket do Amazon S3 no qual a função do Lambda pode realizar o vazamento dos dados. spill_prefixObrigatório. O prefixo que acompanha o bucket de vazamento no qual a função do Lambda pode realizar o vazamento dos dados. spill_put_request_headers(Opcional) Um mapa codificado em JSON de cabeçalhos e valores de solicitações para a solicitação putObjectdo Amazon S3 usada para o derramamento (por exemplo,{"x-amz-server-side-encryption" : "AES256"}). Para outros cabeçalhos possíveis, consulte PutObject na Referência da API do Amazon Simple Storage Service.
Suporte ao tipo de dados
A tabela a seguir apresenta os tipos de dados correspondentes compatíveis com o Kafka e o Apache Arrow.
| Kafka | Arrow |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP | MILLISECOND |
| DATA | DAY |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOUBLE | FLOAT8 |
Partições e divisões
Os tópicos do Kafka são divididos em partições. Cada partição é ordenada. Cada mensagem em uma partição tem um ID incremental denominado deslocamento. Cada partição do Kafka é separada em diversas divisões para o processamento paralelo. Os dados estão disponíveis para o período de retenção configurado nos clusters do Kafka.
Práticas recomendadas
Como prática recomendada, use o empilhamento de predicados ao consultar o Athena, como mostrado nos exemplos a seguir.
SELECT *
FROM "msk_catalog_name"."glue_schema_registry_name"."glue_schema_name"
WHERE integercol = 2147483647SELECT *
FROM "msk_catalog_name"."glue_schema_registry_name"."glue_schema_name"
WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'Configuração do conector MSK
Antes de usar o conector, você deve configurar seu cluster do Amazon MSK. Use o registro de esquemas do AWS Glue para definir seu esquema e configurar a autenticação para o conector.
nota
Se você implantar o conector em uma VPC para acessar recursos privados e também quiser estabelecer uma conexão com um serviço acessível ao público, como o Confluent, deverá associar o conector a uma sub-rede privada que tenha um gateway NAT. Para obter mais informações, consulte Gateways NAT no Guia do usuário da Amazon VPC.
Ao trabalhar com o registro de esquemas do AWS Glue, preste atenção aos seguintes pontos:
-
Certifique-se de que o texto no campo Description (Descrição) do registro de esquemas do AWS Glue inclua a string
{AthenaFederationMSK}. Essa string de marcação é necessária para os registros do AWS Glue usados com o conector MSK do Amazon Athena. -
Para obter a melhor performance, use somente letras minúsculas para nomes de banco de dados e nomes de tabela. O uso de maiúsculas e minúsculas mistas faz com que o conector execute uma pesquisa que não diferencia maiúsculas de minúsculas e é mais computacionalmente intensiva.
Para configurar o ambiente do Amazon MSK e o registro de esquemas do AWS Glue
-
Configure o ambiente do Amazon MSK. Para obter mais informações e etapas, consulte Setting up Amazon MSK (Configuração do Amazon MSK) e Getting started using Amazon MSK (Comece a usar o Amazon MSK) no Guia do desenvolvedor do Amazon Managed Streaming for Apache Kafka.
-
Faça o upload do arquivo de descrição do tópico do Kafka (ou seja, seu esquema) no formato JSON para o registro de esquemas do AWS Glue. Para obter mais informações, consulte Integração com o registro de esquemas do AWS Glue no Guia do desenvolvedor do AWS Glue. Para obter esquemas de exemplo, consulte a seção a seguir.
Use o formato dos exemplos apresentados nessa seção ao fazer upload de seu esquema para o registro de esquemas do AWS Glue.
Exemplo de esquema: tipo JSON
No exemplo a seguir, o esquema a ser criado no registro de esquemas do AWS Glue especifica json como o valor para dataFormat e usa datatypejson para topicName.
nota
O valor para topicName deve usar a mesma capitalização que o nome do tópico no Kafka.
{
"topicName": "datatypejson",
"message": {
"dataFormat": "json",
"fields": [
{
"name": "intcol",
"mapping": "intcol",
"type": "INTEGER"
},
{
"name": "varcharcol",
"mapping": "varcharcol",
"type": "VARCHAR"
},
{
"name": "booleancol",
"mapping": "booleancol",
"type": "BOOLEAN"
},
{
"name": "bigintcol",
"mapping": "bigintcol",
"type": "BIGINT"
},
{
"name": "doublecol",
"mapping": "doublecol",
"type": "DOUBLE"
},
{
"name": "smallintcol",
"mapping": "smallintcol",
"type": "SMALLINT"
},
{
"name": "tinyintcol",
"mapping": "tinyintcol",
"type": "TINYINT"
},
{
"name": "datecol",
"mapping": "datecol",
"type": "DATE",
"formatHint": "yyyy-MM-dd"
},
{
"name": "timestampcol",
"mapping": "timestampcol",
"type": "TIMESTAMP",
"formatHint": "yyyy-MM-dd HH:mm:ss.SSS"
}
]
}
}Exemplo de esquema: tipo CSV
No exemplo a seguir, o esquema a ser criado no registro de esquemas do AWS Glue especifica csv como o valor para dataFormat e usa datatypecsvbulk para topicName. O valor para topicName deve usar a mesma capitalização que o nome do tópico no Kafka.
{
"topicName": "datatypecsvbulk",
"message": {
"dataFormat": "csv",
"fields": [
{
"name": "intcol",
"type": "INTEGER",
"mapping": "0"
},
{
"name": "varcharcol",
"type": "VARCHAR",
"mapping": "1"
},
{
"name": "booleancol",
"type": "BOOLEAN",
"mapping": "2"
},
{
"name": "bigintcol",
"type": "BIGINT",
"mapping": "3"
},
{
"name": "doublecol",
"type": "DOUBLE",
"mapping": "4"
},
{
"name": "smallintcol",
"type": "SMALLINT",
"mapping": "5"
},
{
"name": "tinyintcol",
"type": "TINYINT",
"mapping": "6"
},
{
"name": "floatcol",
"type": "DOUBLE",
"mapping": "7"
}
]
}
}Configuração da autenticação para o conector MSK do Athena
É possível usar uma variedade de métodos para autenticar seu cluster do Amazon MSK, incluindo IAM, SSL, SCRAM e Kafka dedicado.
A tabela a seguir mostra os tipos de autenticação para o conector, e o protocolo de segurança e o mecanismo SASL para cada um. Para obter mais informações, consulte Authentication and authorization for Apache Kafka APIs (Autenticação e autorização para APIs do Apache Kafka) no Guia do desenvolvedor do Amazon Managed Streaming for Apache Kafka.
| auth_type | security.protocol | sasl.mechanism |
|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
SASL_SSL_AWS_MSK_IAM |
SASL_SSL |
AWS_MSK_IAM |
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
SSL |
SSL |
N/D |
nota
Há suporte para os tipos de autenticação SASL_SSL_PLAIN e SASL_PLAINTEXT_PLAIN no Apache Kafka, mas não no Amazon MSK.
SASL/IAM
Se o cluster usar a autenticação do IAM, você deverá configurar a política do IAM para o usuário ao configurar o cluster. Para obter mais informações, consulte IAM access control (Controle de acesso do IAM) no Guia do desenvolvedor do Amazon Managed Streaming for Apache Kafka.
Para usar esse tipo de autenticação, defina a variável de ambiente do Lambda auth_type como SASL_SSL_AWS_MSK_IAM para o conector.
SSL
Se o cluster for autenticado por SSL, você deverá gerar os arquivos de armazenamento confiável e de armazenamento de chaves, e fazer o upload deles no bucket do Amazon S3. Você deverá fornecer essa referência do Amazon S3 ao implantar o conector. O armazenamento de chaves, o armazenamento confiável e a chave SSL serão armazenados no AWS Secrets Manager. Você fornecerá a chave secreta da AWS ao implantar o conector.
Para obter informações sobre como criar um segredo no Secrets Manager, consulte Criação de um segredo do AWS Secrets Manager.
Para usar esse tipo de autenticação, defina as variáveis de ambiente conforme mostrado na tabela a seguir.
| Parâmetro | Valor |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
O local do Amazon S3 que contém os certificados. |
secrets_manager_secret |
O nome da chave secreta da AWS. |
Após a criação de um segredo no Secrets Manager, é possível visualizá-lo no console do Secrets Manager.
Para visualizar o segredo no Secrets Manager
Abra o console do Secrets Manager em https://console.aws.amazon.com/secretsmanager/
. -
No painel de navegação, escolha Secrets (Segredos).
-
Na página Secrets (Segredos), selecione o link do seu segredo.
-
Na página de detalhes do seu segredo, escolha Retrieve secret value (Recuperar valor do segredo).
A imagem a seguir apresenta um exemplo de segredo com três pares chave/valor:
keystore_password,truststore_passwordessl_key_password.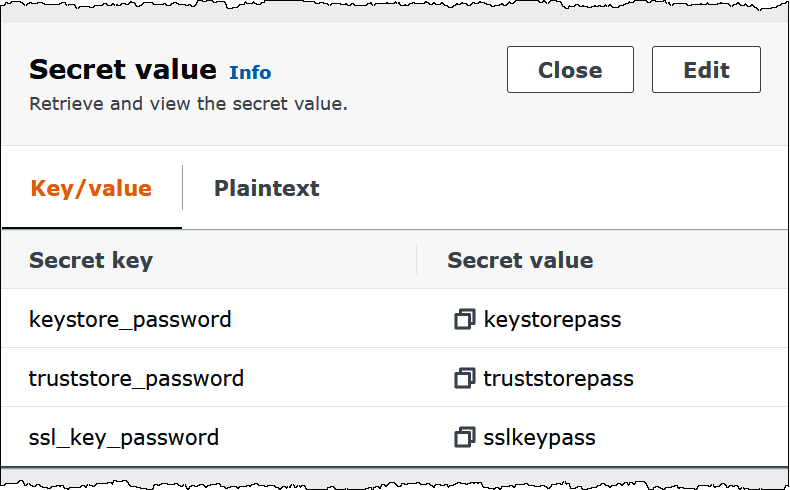
SASL/SCRAM
Se o cluster usar a autenticação SCRAM, forneça a chave do Secrets Manager associada ao cluster ao implantar o conector. As credenciais da AWS do usuário (chave secreta e chave de acesso) serão usadas para realizar a autenticação com o cluster.
Defina as variáveis de ambiente conforme mostrado na tabela a seguir.
| Parâmetro | Valor |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
O nome da chave secreta da AWS. |
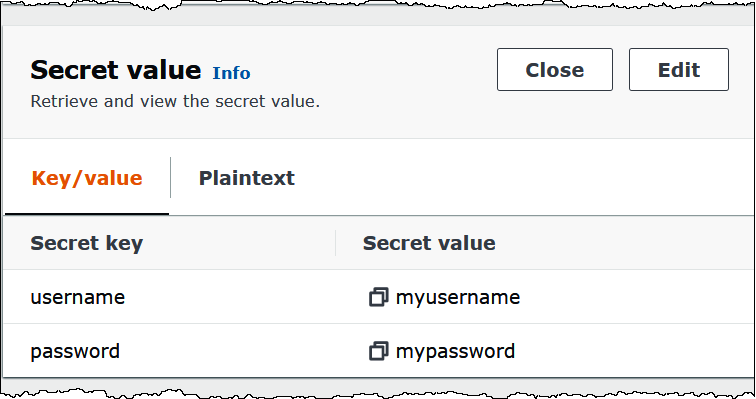
A imagem a seguir apresenta um exemplo de segredo no console do Secrets Manager com dois pares chave/valor: um para username e outro para password.
Informações de licença
Ao usar esse conector, você reconhece a inclusão de componentes de terceiros, cuja lista pode ser encontrada no arquivo pom.xml
Recursos adicionais
Para obter mais informações sobre esse conector, visite o site correspondente
