Notas da versão
Descreve os recursos, as melhorias e as correções de bugs do Amazon Athena por data de lançamento.
Notas de lançamento do Athena para 2026
3 de junho de 2026
Amazon Athena lança a versão 3.8.0 do driver JDBC. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para fazer o download do driver JDBC mais recente, consulte Download do driver JDBC 3.x.
29 de maio de 2026
Amazon Athena lança o driver ODBC 2.2.0.0. Para obter mais informações sobre essa versão do driver JDBC, consulte Notas da versão do ODBC 2.x do Amazon Athena. Para baixar o driver ODBC 2.x, consulte Download do driver ODBC 2.x.
12 de maio de 2026
Publicado em 12/05/2026
Atualizações e melhorias na segurança
Atualizamos as versões das bibliotecas de terceiros conforme descrito a seguir.
-
logback-coreatualizado de 1.3.15 para 1.3.16 -
logback-classicatualizado de 1.3.15 para 1.3.16 -
jackson-annotationsatualizado de 2.16.0 para 2.21.2 -
jackson-coreatualizado de 2.16.0 para 2.21.2 -
jackson-databindatualizado de 2.16.0 para 2.21.2 -
Substituída a autenticação
NTLMhardcoded pelo protocoloNegotiateno fluxo de autenticação SAML do ADFS, ativando o suporte a Kerberos com fallback automático paraNTLMv2
Para obter mais informações e baixar o driver JDBC 2.x, notas de versão e documentação, consulte Driver JDBC 2.x do Athena.
21 de abril de 2026
Publicado em 21/04/2026
O Amazon Athena oferece a partir de agora conectores gerenciados para 12 fontes de dados, incluindo Amazon DynamoDB, PostgreSQL, MySQL e Snowflake. Os conectores gerenciados são conectores federados do AWS Glue Data Catalog que o Athena cria e gerencia em seu nome, para que você possa consultar dados fora do Amazon S3 sem implantar ou manter recursos de conectores em sua conta da AWS. Esses conectores são registrados como catálogos federados no AWS Glue Data Catalog e, opcionalmente, você pode configurar controles de acesso refinados por meio de AWS Lake Formation. Para obter mais informações, consulte Usar a consulta federada do Amazon Athena.
27 de março de 2026
Publicado em 27/3/2026
O Amazon Athena agora oferece suporte as reservas de capacidade nas seguintes Regiões da AWS comerciais: Oeste dos EUA (N. da Califórnia), África (Cidade do Cabo), Ásia-Pacífico (Hong Kong), Ásia-Pacífico (Hyderabad), Ásia-Pacífico (Jacarta), Ásia-Pacífico (Malásia), Ásia-Pacífico (Melbourne), Ásia-Pacífico (Osaka), Ásia-Pacífico (Seul), Ásia-Pacífico (Tailândia), Ásia-Pacífico (Taipei), Canadá (Central), Oeste do Canadá (Calgary), Europa (Frankfurt), Europa (Londres), Europa (Milão), Europa (Paris), Europa (Zurique) e México (Centro).
Para saber mais, consulte Gerenciar a capacidade de processamento de consulta e os Preços do Amazon Athena
20 de março de 2026
Publicado em 20/03/2026
Athena lança o driver ODBC 2.1.0.0. Esta versão inclui melhorias de segurança nos fluxos de autenticação, processamento de consultas e segurança de transporte. Recomendamos o upgrade para esta versão o mais rápido possível. Para obter mais informações sobre essa versão do driver JDBC, consulte Notas da versão do ODBC 2.x do Amazon Athena. Para baixar o driver ODBC 2.x, consulte Download do driver ODBC 2.x.
17 de março de 2026
Publicado em 17/03/2026
O Athena passou a oferecer suporte à autorização baseada em IAM da AWS para tabelas do Amazon S3 e visão materializada do Apache Iceberg. Com a autorização baseada em IAM, você pode definir todas as permissões necessárias nos mecanismos de armazenamento, catálogo e consulta em uma única política do IAM.
10 de fevereiro de 2026
Publicado em 10/02/2026
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
O Amazon Athena agora oferece suporte a reservas de capacidade de 1 minuto e capacidade mínima de 4 unidades de processamento de dados (DPU). As reservas de capacidade fornecem computação sem servidor dedicada para workloads SQL interativas que exigem priorização de consultas e controles de simultaneidade. Com esta versão, agora você pode começar com menos capacidade e ajustá-la com mais frequência para se adequar melhor aos padrões variáveis de workload. Saiba mais no Guia do usuário do Athena.
12 de janeiro de 2026
Publicado em 12/01/2026
O Amazon Athena anuncia a disponibilidade do Athena SQL na região Ásia-Pacífico (Nova Zelândia).
Para obter uma lista completa dos Serviços da AWS disponíveis em cada Região da AWS, consulte Serviços da AWS por região
Notas de lançamento do Athena para 2025
30 de novembro de 2025
Publicado em 30/11/2025
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
O Amazon Athena agora é compatível com as visões materializadas do Catálogo de Dados do AWS Glue, um novo tipo de tabela de resultados pré-processados de consulta que é atualizada automaticamente à medida que seus dados são alterados. As visões materializadas do Catálogo de Dados do Glue são armazenadas como tabelas do Apache Iceberg e podem ser consultadas com instruções SELECT de SQL do Athena e com o Apache Spark versão 3.5. Para saber mais, consulte Consultar as visões materializadas do Catálogo de Dados do AWS Glue e Uso de visões materializadas.
21 de novembro de 2025
Publicado em 21/11/2025
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
O Amazon Athena para Apache Spark agora está disponível em cadernos: fornece aos engenheiros de dados, analistas e cientistas de dados um espaço de trabalho unificado para consultar dados, desenvolver trabalhos, treinar modelos e trabalhar com IA. O Athena para Apache Spark é executado no Spark 3.5.6 e tem novos recursos de depuração, monitoramento em tempo real por meio da interface do usuário do Spark, o Spark Connect para interação segura com os clusters e controles de acesso do AWS Lake Formation no nível de tabela. Saiba mais no guia do usuário do SageMaker.
-
Controles de custos e performance das reservas de capacidade: agora você pode definir limites de uso da unidade de processamento de dados (DPU) no nível do grupo de trabalho ou da consulta e obter detalhes do uso da DPU para consultas que você executa nas reservas de capacidade. Esses controles ajudam você a ajustar a performance da consulta e a gerenciar custos controlando o uso de recursos das suas workloads SQL mais importantes. Para saber mais, consulte Controlar o uso da capacidade.
-
Solução de ajuste de escala automático de reservas de capacidade: agora você pode ajustar automaticamente as reservas de capacidade com base na utilização. A solução do Athena usa o CloudFormation e o Step Functions para eliminar a necessidade de ajustes manuais de capacidade, ajudando você a equilibrar os requisitos de performance com a otimização de custos, e é personalizável para diferentes necessidades. Para saber mais, consulte Ajustar a capacidade reservada.
-
Otimização com estatísticas do Iceberg: o Athena aprimorou a forma como usa as estatísticas do Iceberg para tomar decisões inteligentes sobre ordenação de junções, filtros e comportamento de agregação que podem melhorar a performance das consultas e reduzir custos. Para saber mais, consulte Usar estatísticas da tabela do Iceberg.
-
Indexação de colunas Parquet do Iceberg: o Athena agora é compatível com a indexação de colunas Parquet em tabelas do Iceberg para um descarte preciso de dados durante a execução da consulta. Ele aproveita as estatísticas mínimo/máximo no nível de página para reduzir a quantidade de dados verificados, melhorando a performance da consulta e reduzindo os custos, especialmente para consultas com predicados de filtro seletivo em colunas classificadas. Para saber mais, consulte Usar a indexação de colunas Parquet.
-
Melhorias na performance do Iceberg com o Lake Formation: o Athena adicionou novos comportamentos de descarte de partições para tabelas do Iceberg que têm filtros de linha e máscaras de coluna do Lake Formation e comportamentos adicionais de envio de predicados para todos os outros tipos de tabela que têm filtros de linha e máscaras de coluna do Lake Formation. Essa atualização aprimora a performance das consultas e, ao mesmo tempo, mantém as proteções de segurança.
-
Reutilização dos resultados de consultas: o Athena aprimorou a reutilização dos resultados de consultas para permitir que mais consultas se beneficiem dos resultados em cache. O Athena agora trata consultas semanticamente equivalentes como idênticas, independentemente das diferenças de formatação. Os clientes que usam a reutilização de resultados de consultas se beneficiarão automaticamente do aumento das taxas de acertos de cache, resultando em uma execução mais rápida de consultas e custos reduzidos, sem a necessidade de executar qualquer ação. Para saber mais, consulte Reutilizar os resultados de consultas no Athena.
-
SerDes de arquivos de data lake atualizados: o Athena atualizou seus SerDes para Parquet, JSON, CSV e arquivos de texto. Isso melhora a performance e a confiabilidade das consultas e, ao mesmo tempo, corrige cenários em que os SerDes anteriores retornaram resultados não determinísticos ou incorretos. Os clientes se beneficiarão automaticamente dessas melhorias, sem a necessidade de executar qualquer ação, à medida que forem atualizados com base nas verificações de compatibilidade realizadas pelo Athena.
-
Atualização do Hudi 0.15.0: agora você pode usar o Athena para consultar tabelas do Hudi 0.15.0. Para obter mais informações, consulte Consultar conjuntos de dados do Apache Hudi.
-
Integração da propagação de identidade confiável via navegador: o Athena adicionou um novo plug-in de autenticação para oferecer suporte à integração de propagação de identidade confiável via JWT com drivers JDBC e ODBC. Esse tipo de autenticação permite buscar um JSON Web Token (JWT) de um provedor de identidades externo e autenticá-lo com o Athena. Para obter mais informações, consulte Usar a propagação de identidade confiável com drivers do Amazon Athena.
-
Driver JDBC 3.7.0: o Athena lança o driver JDBC versão 3.7.0. Para obter mais informações sobre essa versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para fazer o download do driver JDBC mais recente, consulte Download do driver JDBC 3.x.
-
Driver ODBC 2.0.6.0: o Athena lança o driver ODBC versão 2.0.6.0. Para obter mais informações sobre essa versão do driver JDBC, consulte Notas da versão do ODBC 2.x do Amazon Athena. Para fazer o download do driver JDBC mais recente, consulte Download do driver ODBC 2.x.
13 de outubro de 2025
Publicado em 13/10/2025
Athena lança o driver ODBC 2.0.5.1. Para obter mais informações sobre essa versão do driver JDBC, consulte Notas da versão do ODBC 2.x do Amazon Athena. Para baixar o driver ODBC 2.x, consulte Download do driver ODBC 2.x.
19 de setembro de 2025
Publicado em 19/9/2025
O Amazon Athena adiciona pares de chaves e métodos de autenticação OAuth para o conector do Snowflake do Amazon Athena. Esses métodos de autenticação substituem o método de autenticação por nome de usuário e senha que o Snowflake planeja desativar até novembro de 2025. Para obter informações sobre como configurar os novos métodos de autenticação, consulte Autenticar com o Snowflake.
10 de setembro de 2025
Publicado em 10/9/2025
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
Configurar a propagação de identidade confiável JWT
O Athena adicionou um novo plug-in de autenticação para oferecer suporte à integração confiável de propagação de identidade JWT com drivers JDBC e ODBC. Esse tipo de autenticação permite usar um JSON Web Token (JWT) obtido de um provedor de identidades externo como parâmetro de conexão para autenticação no Athena. Para obter mais informações, consulte Usar a propagação de identidade confiável com drivers do Amazon Athena.
Driver ODBC 2.0.5.0
Athena lança o driver ODBC 2.0.5.0. Para obter mais informações sobre essa versão do driver JDBC, consulte Notas da versão do ODBC 2.x do Amazon Athena. Para fazer o download do driver JDBC mais recente, consulte Download do driver ODBC 2.x.
Driver JDBC 3.6.0
O Athena lança a versão 3.6.0 do driver JDBC. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para fazer o download do driver JDBC mais recente, consulte Download do driver JDBC 3.x.
5 de setembro de 2025
Publicado em 5/9/2025
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
Driver JDBC 2.2.2
Lançamento dos drivers JDBC 2.2.2 para o Athena.
Atualizações e correções de bugs
Atualizamos as versões das bibliotecas de terceiros conforme descrito a seguir.
-
commons-codecatualizado de 1.15 para 1.18.0 -
commons-csvatualizado de 1.8 para 1.14.0 -
commons-loggingatualizado de 1.2 para 1.3.5 -
Componente Log4j atualizado para 2.24.3.
Correções de bugs
-
Corrigido um erro que ocorria no conector quando um valor nulo era passado para o parâmetro
loginToRpdurante a autenticação do ADFS.
Para obter mais informações e baixar o driver JDBC 2.x, notas de versão e documentação, consulte Driver JDBC 2.x do Athena.
15 de agosto de 2025
Publicado em 15/08/2015
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
Consultas CREATE TABLE AS SELECT (CTAS) para tabelas S3: o Athena agora é compatível com consultas CREATE TABLE AS SELECT (CTAS) para tabelas do S3. Para obter mais informações, consulte Criar tabelas do S3 no Athena.
Remoção da compatibilidade com estatísticas de tabelas legadas do Iceberg: removemos a compatibilidade com o rastreamento de estatísticas de tabelas legadas ao Iceberg no Athena. Se você tiver tabelas que foram escritas antes de 7 de maio de 2023, deverá analisá-las novamente.
11 de agosto de 2025
Publicado em 11/08/2025
Athena anuncia as correções e melhorias a seguir:
-
Mudamos o comportamento de
lead()elag()com relação ao tratamento de desviosNULL. Antes dessa alteração, passar o desvioNULLparalead()elag()geravaNULLcomo saída. Agora, Athena retorna o erro O desvio não deve ser nulo.Isso é feito para tornar o comportamento compatível com os padrões SQL e evitar
NULLimprevistos na saída prevenindo-os proativamente na entrada. Com isso, é recomendável que você não passeNULLcomo desvio paralead()elag(). Embora não recomendável, é possível preservar o comportamento antigo reescrevendo como mostrado no seguinte exemplo:Padrão de consulta original
lead(column1, column_containing_nulls) OVER (...) as transformedPadrão de consulta atualizado
CASE WHEN column_containing_nulls IS NULL THEN NULL ELSE (lead(column1, coalesce(column_containing_nulls, 1)) OVER (...)) END as transformed
17 de julho de 2025
Publicado em 17/07/2025
O Athena lança a versão 3.5.1 do driver JDBC. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para fazer o download do driver JDBC mais recente, consulte Download do driver JDBC 3.x.
30 de junho de 2025
Publicado em 30/06/2025
O Amazon Athena anuncia a disponibilidade do Athena SQL na região Ásia-Pacífico (Taipé).
Para obter uma lista completa dos Serviços da AWS disponíveis em cada Região da AWS, consulte Serviços da AWS por região
17 de junho de 2025
Publicado em 17/6/2024
Athena lança o driver ODBC 2.0.4.0. Para obter mais informações sobre essa versão do driver JDBC, consulte Notas da versão do ODBC 2.x do Amazon Athena. Para baixar o driver ODBC 2.x, consulte Download do driver ODBC 2.x.
3 de junho de 2025
Publicado em 03/6/2025
O Athena apresenta os resultados de consultas gerenciadas, um novo atributo que armazena, protege e gerencia automaticamente os dados dos resultados de consultas para você, sem nenhum custo. Os resultados de consultas gerenciadas ajudam você a começar em menos etapas, eliminando a necessidade de os buckets do Amazon S3 armazenarem resultados de consultas e limparem processos para excluir resultados de consultas que você não precisa mais. Os resultados de consultas gerenciadas geralmente estão disponíveis em todas as regiões em que o Athena está disponível
Ao usar os resultados de consultas gerenciadas, você pode continuar acessando os resultados de consultas por meio das mesmas interfaces do armazenamento tradicional no bucket do S3. Para começar, use o Console de gerenciamento da AWS, os SDK da AWS ou a AWS CLI para configurar seus grupos de trabalho novos ou existentes para usar resultados de consultas gerenciadas. Para obter mais informações, consulte Resultados de consultas gerenciadas.
27 de maio de 2025
Publicado em 27/05/2025
Athena anuncia as correções e melhorias a seguir:
Mensagens de erro aprimoradas para tabelas de metadados do Delta Lake: melhoramos as mensagens de erro das tabelas de metadados do Delta Lake, agora fornecendo um feedback mais claro quando você tenta consultar essas tabelas não compatíveis.
14 de maio de 2025
Publicado em 14/05/2025
Athena anuncia as correções e melhorias a seguir:
Resolvemos um problema que poderia fazer com que arquivos ORC fossem criados com tamanhos de arquivo maiores do que o esperado.
-
Desempenho aprimorado das verificações em tabelas do Delta Lake que usam pontos de verificação v2.
18 de abril de 2025
Publicado em 18/04/2025
Athena anuncia as correções e melhorias a seguir:
Rastreamento de reserva de capacidade: resolvemos um problema em nosso sistema de rastreamento de reserva de capacidade em que as reservas não eram liberadas adequadamente durante os cenários de cancelamento de consultas, especificamente após o planejamento da consulta e antes de os trabalhadores serem adquiridos pela Athena para execução da consulta. A correção permite que o mecanismo de consulta do Athena libere explicitamente a reserva de capacidade quando o cenário acima for encontrado.
16 de abril de 2025
Publicado em 16/04/2025
O Amazon Athena anuncia a disponibilidade do Athena SQL nas regiões Ásia-Pacífico (Tailândia) e México (Centro).
Para obter uma lista completa dos Serviços da AWS disponíveis em cada Região da AWS, consulte Serviços da AWS por região
09 de abril de 2025
Publicado em 09/04/2025
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
Driver JDBC 2.2.1
Lançamento dos drivers JDBC 2.2.1 para o Athena.
Atualizações e aprimoramentos:
-
Atualização das bibliotecas Logback para usar a versão 1.3.15.
Para obter mais informações e baixar o driver JDBC 2.x, notas de versão e documentação, consulte Driver JDBC 2.x do Athena.
18 de março de 2025
Publicado em 18/3/2025
O Athena disponibiliza a versão 3.5.0 do driver JDBC. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para fazer o download do driver JDBC mais recente, consulte Download do driver JDBC 3.x.
14 de março de 2025
Publicado em 14 de março de 2025
O Amazon Athena lança novos recursos para criar e consultar operações de tabela diretamente do console do S3.
Para obter mais informações, consulte Registrar catálogos de buckets de tabela do S3 e consultar tabelas no Athena.
7 de março de 2025
Publicado em 7 de março de 2025
Agora, a capacidade provisionada está disponível para o público em geral na região Ásia-Pacífico (Mumbai). A capacidade provisionada permite executar consultas de SQL com capacidade de computação totalmente gerenciada e fornece recursos de gerenciamento de workload que ajudam a priorizar, controlar e escalar suas workloads interativas mais importantes. Você pode adicionar capacidade a qualquer momento para aumentar o número de consultas que poderão ser executadas simultaneamente, controlar quais workloads usarão a capacidade e compartilhar a capacidade entre as workloads.
Para obter mais informações, consulte Gerenciar a capacidade de processamento de consulta. Para obter informações, acesse a página de preços do Amazon Athena
18 de fevereiro de 2025
Publicado em 18/2/2025
O Athena disponibiliza a versão 3.4.0 do driver JDBC. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para fazer o download do driver JDBC mais recente, consulte Download do driver JDBC 3.x.
22 de janeiro de 2025
Publicado em 22/1/2025
O Athena agora oferece suporte a consultas federadas por meio do Lambda e à criptografia dos resultados da consulta usando o KMS em grupos de trabalho habilitados para TIP. Para obter mais informações, consulte Usar grupos de trabalho do Athena habilitados para o IAM Identity Center.
Notas de lançamento do Athena para 2024
17 de dezembro de 2024
Publicado em 17/12/2024
O Amazon Athena anuncia a disponibilidade do Athena na região Ásia-Pacífico (Malásia).
Para obter uma lista completa dos Serviços da AWS disponíveis em cada Região da AWS, consulte Serviços da AWS por região
16 de dezembro de 2024
Publicado em 16/12/2024
Correção de vetores de exclusão: corrigido um problema com vetores de exclusão em que tabelas particionadas retornavam resultados incorretos no conector do Delta Lake.
3 de dezembro de 2024
Publicado em 03/12/2024
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
Conexões de fonte de dados: o Amazon Athena anuncia um console simplificado e um fluxo de trabalho de API para criar conexões de fonte de dados. Agora, você pode criar e gerenciar conexões de dados do Athena inteiramente no console do Athena, e as propriedades de suas conexões ficarão armazenadas centralmente no AWS Glue Data Catalog.
O armazenamento das propriedades de conexão no AWS Glue permite que você reutilize as conexões em outros serviços da AWS. Por exemplo, após configurar um conector Athena para o Amazon DynamoDB, você poderá reutilizar as propriedades e permissões que especificou para a conexão em um trabalho de ETL do AWS Glue que acesse seus dados no DynamoDB. Para obter mais informações, consulte Usar o console do Athena para conectar a uma fonte de dados no Guia do usuário do Amazon Athena e CreateDataCatalog na Amazon Athena API Reference.
-
Consultar dados do Redshift registrados no AWS Glue Data Catalog: o Athena agora oferece suporte à leitura e gravação em tabelas do Redshift registradas no Glue Data Catalog. Para obter mais informações, consulte Registrar catálogos de dados do Redshift no Athena.
-
Consultar tabelas do S3 via Athena: os buckets de tabela do S3 são um tipo de bucket no Amazon S3 criado especificamente para armazenar dados tabulares nas tabelas do Apache Iceberg. O Athena agora oferece suporte a consultas DQL e DML em tabelas do S3. Para obter mais informações, consulte Registrar catálogos de buckets de tabela do S3 e consultar tabelas no Athena.
30 de outubro de 2024
Publicado em 30/10/2024
Athena lança o driver JDBC versão 3.3.0. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para baixar o driver JDBC 3.x, consulte Download do driver JDBC 3.x.
23 de agosto de 2024
Publicado em 5/9/2024
O Athena anuncia o seguinte:
-
Consulta a visualizações federadas com consultas de passagem: as consultas de passagem federadas agora são compatíveis com visualizações. Para obter mais informações, consulte Consultar visualizações federadas.
-
Várias consultas de passagem: você agora pode executar mais de uma consulta de passagem federada na mesma execução de consulta. Para obter mais informações, consulte Usar consultas de passagem federadas.
-
Correção de OPTIMIZE em tabela do Iceberg: corrigido um problema em que a execução de
OPTIMIZEem uma tabela do Iceberg não removia os arquivos "excluir" ao reescrever arquivos de dados que tinham um arquivo de exclusão associado. Para obter mais informações, consulte OPTIMIZE. -
Compatibilidade com gravação de Parquet LZ4 e LZO: o Athena não é mais compatível com gravação de arquivos compactados Parquet com os formatos LZ4 ou LZO. Ainda há compatibilidade com as leituras desses formatos de compactação. Para obter informações sobre os formatos de compactação no Athena, consulte Usar compactação no Athena.
29 de julho de 2024
Publicado em 29/07/2024
Athena lança o driver JDBC versão 3.2.2. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para baixar o driver JDBC 3.x, consulte Download do driver JDBC 3.x.
26 de julho de 2024
Publicado em 1/8/2024
Athena anuncia as melhorias a seguir.
-
Suporte a vetores de exclusão de tabela do Delta Lake: o Athena agora oferece suporte à leitura de tabelas do Delta Lake com vetores de exclusão
. Para obter mais informações, consulte Consultar tabelas do Linux Foundation Delta Lake.
3 de julho de 2024
Publicado em 03/07/2024
Athena lança o driver JDBC versão 3.2.1. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para baixar o driver JDBC 3.x, consulte Download do driver JDBC 3.x.
26 de junho de 2024
Publicado em 26/06/2024
A capacidade provisionada agora está publicamente disponível nas regiões América do Sul (São Paulo) e Europa (Espanha). A capacidade provisionada permite executar consultas de SQL com capacidade de computação totalmente gerenciada e fornece recursos de gerenciamento de workload que ajudam a priorizar, controlar e escalar suas workloads interativas mais importantes. Você pode adicionar capacidade a qualquer momento para aumentar o número de consultas que poderão ser executadas simultaneamente, controlar quais workloads usarão a capacidade e compartilhar a capacidade entre as workloads.
Para obter mais informações, consulte Gerenciar a capacidade de processamento de consulta. Para obter informações, acesse a página de preços do Amazon Athena
10 de maio de 2024
Publicado em 15/07/2024
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
Delta Lake — O Athena adicionou otimizações que filtram entradas desnecessárias dos arquivos de ponto de verificação. Essas otimizações melhoram significativamente o desempenho para consultas com grandes arquivos de ponto de verificação que fazem referência a muitos arquivos de dados do Parquet.
Para obter informações sobre o uso de tabelas do Delta Lake no Linux Foundation, consulte Consultar tabelas do Linux Foundation Delta Lake.
26 de abril de 2024
Publicado em 26/04/2024
Athena lança o driver JDBC versão 3.2.0. Para obter mais informações sobre esta versão do driver JDBC, consulte Notas de versão do JDBC 3.x do Amazon Athena. Para baixar o driver JDBC 3.x, consulte Download do driver JDBC 3.x.
24 de abril de 2024
Publicado em 24/04/2024
Athena anuncia as correções e melhorias a seguir.
-
Parquet: o Athena agora suporta leituras compatíveis com versões anteriores no Parquet para campos primitivos repetidos e sem anotações que não estão contidos em uma lista ou grupo de mapas. Essa alteração evita que resultados silenciosamente incorretos sejam retornados e melhora as mensagens de erro de incompatibilidades de esquema.
Para obter mais informações, consulte Support backwards compatible reads for unannotated repeated primitive fields in Parquet
em GitHub.com. -
Iceberg OPTIMIZE: resolução de um problema com consultas
OPTIMIZEque causava a perda de dados quando um filtro de chave sem partição era usado em uma cláusulaWHERE. Para obter mais informações, consulte OPTIMIZE.
16 de abril de 2024
Publicado em 16/04/2024
Use o novo recurso de passagem de consultas federadas do Amazon Athena para executar consultas inteiras diretamente na fonte de dados subjacente. As consultas de passagem federadas ajudam você a aproveitar as exclusivas funções, linguagem de consulta e recursos de desempenho da fonte de dados original. Por exemplo, você pode executar consultas do Athena no DynamoDB usando a linguagem partiQL. As consultas de passagem federadas também são úteis quando você quiser executar consultas SELECT que agreguem, unam ou invoquem funções da sua fonte de dados que não estejam disponíveis no Athena. O uso de consultas de passagem pode reduzir a quantidade de dados processados pelo Athena e resultar em menores tempos de consulta.
Para obter mais informações, consulte Usar consultas de passagem federadas. Para atualizar com a versão mais recente os conectores que você já utiliza, consulte Atualizar um conector de fonte de dados.
10 de abril de 2024
Publicado em 10/04/2024
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
Driver ODBC 1.2.3.1000
Lançamento do driver ODBC 1.2.3.1000 para o Athena.
Problemas resolvidos:
-
Problema de conexão do servidor proxy: quando um servidor proxy era usado sem o certificado raiz, o conector não conseguia estabelecer uma conexão.
Para obter mais informações e baixar o driver ODBC 1.x, notas de versão e documentação, consulte Driver ODBC 1.x do Athena.
Driver JDBC 2.1.5
Lançamento do driver JBDC 2.1.5 para o Athena.
Atualizações e aprimoramentos:
-
Atualização do AWS Java SDK para usar a versão 1.12.687.
-
Atualização das bibliotecas Jackson para usar a versão 2.16.0.
-
Atualização das bibliotecas Logback para usar a versão 1.3.14.
Para obter mais informações e baixar o driver JDBC 2.x, notas de versão e documentação, consulte Driver JDBC 2.x do Athena.
8 de abril de 2024
Publicado em 08/04/2024
Athena anuncia o driver ODBC versão 2.0.3.0. Para obter mais informações, consulte as notas de versão do 2.0.3.0. Para baixar o driver ODBC v2, consulte Download do driver ODBC 2.x. Para obter informações sobre conexão, consulte o Amazon Athena ODBC 2.x.
15 de março de 2024
Publicado em 18/03/2024
Amazon Athena anuncia a disponibilidade do Athena SQL na região Oeste do Canadá (Calgary).
Para obter uma lista completa dos Serviços da AWS disponíveis em cada Região da AWS, consulte Serviços da AWS por região
15 de fevereiro de 2024
Publicado em 15/02/2024
Athena lança o driver JDBC versão 3.1.0.
A versão 3.1.0 do driver JDBC do Amazon Athena acrescenta compatibilidade com a autenticação integrada do Windows por meio do Microsoft Active Directory Federation Services (AD FS) e autenticação com base em formulário. A versão 3.1.0 também inclui outras pequenas melhorias e correções de problemas.
Para baixar o driver JDBC v3, consulte Download do driver JDBC 3.x.
31 de janeiro de 2024
Publicado em 31/01/2024
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
Atualização do Hudi: agora, você pode usar o Athena SQL para consultar tabelas do Hudi 0.14.0. Para obter informações sobre como usar o Athena SQL para consultar tabelas do Hudi, consulte. Consultar conjuntos de dados do Apache Hudi
Notas de lançamento do Athena para 2023
14 de dezembro de 2023
Publicado em 14/12/2023
Athena anuncia as correções e melhorias a seguir.
Athena lança a versão 2.1.3 do driver JDBC. O driver resolve os seguintes problemas:
-
O registro em log foi aprimorado para evitar conflitos com o registro em log das aplicações Spring Boot e Gradle.
-
Ao usar o método
executeBatch()do JDBC para inserir registros, o driver inseriu somente um registro de forma incorreta. Como o Athena não oferece suporte à execução de consultas em lote, o driver passou a relatar um erro quando você usaexecuteBatch(). Para compensar a limitação, é possível enviar consultas únicas em um loop.
Para baixar o novo driver JDBC, as notas de lançamento e a documentação, consulte Driver JDBC 2.x do Athena.
9 de dezembro de 2023
Publicado em 9/12/2023
Lançamento do driver ODBC 1.2.1.1000 para o Athena.
Recursos e aprimoramentos:
-
Suporte atualizado para o RStudio: o driver ODBC passou a oferecer suporte ao RStudio no macOS.
-
Suporte para catálogo e esquema únicos: agora o conector pode retornar um catálogo e um esquema únicos. Para obter mais informações, consulte o guia de instalação e de configuração disponíveis para download.
Problemas resolvidos:
-
Instruções preparadas: quando instruções preparadas com uma matriz de parâmetros que usa o esquema em colunas eram executadas, o conector retornava um resultado de consulta incorreto.
-
Tamanho da coluna: quando a coluna do sistema
$file_modified_timeera selecionada, o conector retornava um tamanho de coluna incorreto. -
Função SQLPrepare: ao vincular parâmetros relacionados a
SQLPrepareem consultasSELECT, o conector retornava um erro.
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Driver ODBC 1.x do Athena.
7 de dezembro de 2023
Publicado em 7/12/2023
O Athena anuncia a versão 2.0.2.1 do driver ODBC. Para obter mais informações, consulte as notas de versão do 2.0.2.1. Para baixar o driver ODBC v2, consulte Download do driver ODBC 2.x. Para obter informações sobre conexão, consulte o Amazon Athena ODBC 2.x.
5 de dezembro de 2023
Publicado em 5/12/2023
Agora, é possível criar grupos de trabalho do Athena SQL que usam o modo de autenticação do Centro de Identidade do AWS IAM. Esses grupos de trabalho são compatíveis com o atributo de propagação de identidade confiável do Centro de Identidade do IAM. A propagação de identidade confiável permite que as identidades sejam usadas em serviços de analytics da AWS, como o Amazon Athena e o Amazon EMR Studio.
Para obter mais informações, consulte Usar grupos de trabalho do Athena habilitados para o IAM Identity Center.
28 de novembro de 2023
Publicado em 28/11/2023
Agora, é possível consultar dados na classe de armazenamento Amazon S3 Express One Zone
Para obter mais informações, consulte Consultar dados do S3 Express One Zone.
27 de novembro de 2023
Publicado em 27/11/2023
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
Visualizações do Catálogo de Dados do Glue: as visualizações do Catálogo de Dados do Glue fornecem uma perspectiva única e comum sobre os serviços da AWS, como o Amazon Athena e o Amazon Redshift. Nas visualizações do Catálogo de Dados do Glue, as permissões de acesso são definidas pelo usuário que criou a visualização, e não pelo usuário que consulta a visualização. Essas visualizações fornecem maior controle sobre o acesso, ajudam a garantir registros completos, oferecem segurança aprimorada e podem impedir o acesso a tabelas subjacentes.
Para obter mais informações, consulte Usar visualizações do Catálogo de Dados no Athena.
-
Suporte ao CloudTrail Lake: passou a ser possível usar o Amazon Athena para analisar dados no AWS CloudTrail Lake. O AWS CloudTrail Lake corresponde a um data lake gerenciado para o CloudTrail que você pode usar para agregar, armazenar e analisar logs de atividades de forma imutável para investigações operacionais, de auditoria e de segurança. Para consultar os logs de atividades do CloudTrail Lake usando o Athena, não é necessário mover dados ou desenvolver pipelines de processamento de dados separados. Nenhuma operação de ETL é exigida.
Para começar a usar, habilite a federação de dados no CloudTrail Lake. Quando você compartilha os metadados relativos ao armazenamento de dados de eventos do CloudTrail Lake com o AWS Glue Data Catalog, o CloudTrail cria os recursos necessários do AWS Glue Data Catalog e registra os dados com o AWS Lake Formation. No Lake Formation, é possível especificar os usuários e os perfis que podem usar o Athena para consultar o seu armazenamento de dados de eventos.
Para obter mais informações, consulte Enable Lake query federation no Guia do usuário do AWS CloudTrail.
17 de novembro de 2023
Publicado em 17/11/2023
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
Recursos
-
Otimizador baseado em custos: o Athena anuncia a disponibilidade geral da otimização baseada em custos usando as estatísticas do AWS Glue. Para otimizar as consultas no Athena SQL, você pode solicitar que o Athena colete estatísticas no nível da tabela ou da coluna para as tabelas do AWS Glue. Se todas as tabelas em sua consulta tiverem estatísticas, o Athena usará essas estatísticas para examinar planos de execução alternativos e selecionar o que tiver a probabilidade de ser o mais rápido.
Para obter mais informações, consulte Usar o otimizador baseado em custos.
-
Integração com o Amazon EMR Studio: agora você pode usar o Athena em um Amazon EMR Studio sem precisar usar o console do Athena diretamente. Com a integração do Athena no Amazon EMR, você pode executar as seguintes tarefas:
-
Fazer consultas SQL do Athena
-
Visualizar resultados da consulta
-
Visualizar o histórico de consultas
-
Visualizar as consultas salvas
-
Fazer consultas parametrizadas
-
Visualizar bancos de dados, tabelas e visualizações de um catálogo de dados
Para obter mais informações, consulte Amazon EMR Studio no tópico Integrações de AWS service (Serviço da AWS) ao Athena.
-
-
Controle de acesso aninhado: o Athena anuncia que terá compatibilidade com o controle de acesso do Lake Formation para dados aninhados. No Lake Formation, você pode definir e aplicar filtros de dados em colunas aninhadas que tenham os tipos de dados
struct. Você pode usar a filtragem de dados para restringir o acesso do usuário às subestruturas das colunas aninhadas. Para obter mais informações sobre como criar filtros para dados aninhados, consulte Creating a data filter no AWS Lake Formation Developer Guide. -
Métricas de uso da capacidade provisionada: o Athena anuncia novas métricas do CloudWatch para reservas de capacidade. Você pode usar as novas métricas para acompanhar o número de DPUs provisionadas e o número de DPUs sendo usadas por suas consultas. Quando as consultas terminam, você também pode visualizar o número de DPUs que elas consumiram.
Para obter mais informações, consulte Monitorar métricas de consultas do Athena com o CloudWatch.
Melhorias
-
Alteração da mensagem de erro: a mensagem de erro
Insufficient Lake Formation permissionsagora dizTable not foundouSchema not found. Essa alteração foi feita para evitar que agentes mal-intencionados inferissem a existência de recursos de tabela ou banco de dados a partir da mensagem de erro.
16 de novembro de 2023
Publicado em 16/11/2023
O Athena lançou um novo driver JDBC que melhora a experiência de conexão, consulta e visualização de dados das aplicações SQL compatíveis de desenvolvimento e business intelligence. O novo driver é fácil de atualizar. O driver pode ler resultados de consultas diretamente no Amazon S3, disponibilizando-os em menos tempo.
Para obter mais informações, consulte Driver JDBC 3.x do Athena.
31 de outubro de 2023
Publicado em 31/10/2023
O Amazon Athena anuncia reservas de 1 hora para capacidade provisionada. A partir de hoje, você pode reservar e liberar a capacidade provisionada depois de uma hora. Essa alteração simplifica a otimização de custos de workloads cuja demanda muda com o tempo.
A capacidade provisionada é um atributo do Athena que oferece recursos de gerenciamento de workload que ajudam a priorizar, controlar e escalar as workloads interativas mais importantes. Você pode adicionar capacidade a qualquer momento para aumentar o número de consultas que poderão ser executadas simultaneamente, controlar quais workloads usarão a capacidade e compartilhar a capacidade entre as workloads.
Para obter mais informações, consulte Gerenciar a capacidade de processamento de consulta. Para obter informações de preço, visite a página Preços do Amazon Athena
25 de outubro de 2023
Publicado em 26/10/2023
Athena anuncia as correções e melhorias a seguir.
pacote do jackson-core: agora ocorrerá falha no texto JSON com um valor numérico com mais de 1.000 caracteres.
17 de outubro de 2023
Publicado em 17/10/2023
O Athena anuncia o driver ODBC versão 2.0.2.0. Para obter mais informações, consulte as notas de versão do 2.0.2.0. Para baixar o driver ODBC v2, consulte Download do driver ODBC 2.x. Para obter informações sobre conexão, consulte o Amazon Athena ODBC 2.x.
26 de setembro de 2023
Publicado em 26/09/2023
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
Suporte de leitura do Lake Formation para tabelas do Delta Lake. Para obter informações sobre o uso de tabelas do Delta Lake no Athena, consulte Consultar tabelas do Linux Foundation Delta Lake.
23 de agosto de 2023
Publicado em 23/08/2023
O Amazon Athena anuncia a disponibilidade do Athena SQL na região de Israel (Tel Aviv).
Para obter uma lista completa dos Serviços da AWS disponíveis em cada Região da AWS, consulte Serviços da AWS por região
10 de agosto de 2023
Publicado em 10/08/2023
Athena anuncia as correções e melhorias a seguir.
Driver ODBC versão 2.0.1.1
O Athena anuncia o driver ODBC versão 2.0.1.1. Para obter mais informações, consulte as notas de versão do 2.0.1.1. Para baixar o driver ODBC v2, consulte Download do driver ODBC 2.x. Para obter informações sobre conexão, consulte o Amazon Athena ODBC 2.x.
Driver JDBC versão 2.1.1
Athena lança o driver JDBC versão 2.1.1. O driver resolve os seguintes problemas:
-
Um erro que ocorria quando uma tabela era criada com uma instrução que continha uma expressão regular.
-
Um problema que causava o parâmetro de conexão
ApplicationNamea ser aplicado incorretamente.
Para baixar o novo driver JDBC, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com JDBC.
31 de julho de 2023
Publicado em 31/07/2023
O Amazon Athena anuncia a disponibilidade do Athena SQL em outras Regiões da AWS.
Esta versão expande a disponibilidade do Athena SQL para incluir Ásia-Pacífico (Hyderabad), Ásia-Pacífico (Melbourne), Europa (Espanha) e Europa (Zurique).
Para obter uma lista completa dos Serviços da AWS disponíveis em cada Região da AWS, consulte Serviços da AWS por região
27 de julho de 2023
Publicado em 27/7/2023
Athena lança a versão 2023.30.1 do conector Google BigQuery. Essa versão do conector reduz o tempo de execução da consulta e adiciona suporte à consulta em endpoints privados do BigQuery.
Para obter informações sobre o conector do Google BigQuery, consulte Conector do Amazon Athena para o Google BigQuery. Para obter mais informações sobre como atualizar os conectores da fonte de dados existentes, consulte Atualizar um conector de fonte de dados.
24 de julho de 2023
Publicado em 24/7/2023
Athena anuncia as correções e melhorias a seguir.
-
Consultas com uniões: melhorou o desempenho de determinadas consultas com uniões.
-
Junções com comparações de tipos: corrigiu uma possível falha de consulta para instruções
JOINque incluíam uma comparação entre dois tipos diferentes. -
Subconsultas em colunas aninhadas: corrigiu um problema relacionado a falhas de consulta quando as subconsultas eram correlacionadas em colunas aninhadas.
-
Visualizações do Iceberg: corrigiu um problema de compatibilidade com a precisão das colunas de timestamps nas visualizações do Apache Iceberg. As visualizações do Iceberg que têm colunas de timestamp agora podem ser lidas independentemente de terem sido criadas em versões anteriores do mecanismo ou na versão 3 do mecanismo do Athena.
20 de julho de 2023
Publicado em 20/7/2023
Athena lança o driver JDBC versão 2.1.0. O driver contém novos aprimoramentos e resolveu um problema.
Melhorias
As seguintes bibliotecas Jackson
-
jackson-annotations 2.15.2 (anteriormente 2.14.0)
-
jackson-core 2.15.2 (anteriormente 2.14.0)
-
jackson-databind 2.15.2 (anteriormente 2.14.0)
Problemas resolvidos
-
Foi corrigido um problema com a passagem de parâmetros de matriz quando a biblioteca sql2o
foi usada.
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com JDBC.
13 de julho de 2023
Publicado em 09/19/2023
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
EXPLAIN ANALYZE — Foi adicionado suporte para fila, análise, planejamento e tempo de execução à saída de
EXPLAIN ANALYZE. -
EXPLAIN — a
EXPLAINsaída agora mostra estatísticas quando a consulta contém agregações. -
Parquet Hive SerDe — Foi adicionada a
parquet.ignore.statisticspropriedade para permitir que as estatísticas de processamento sejam ignoradas ao ler dados do Parquet. Para mais informações, consulte Ignorar estatísticas do Parquet.
Para obter mais informações sobre EXPLAIN e EXPLAIN ANALYZE, consulte Usar EXPLAIN e EXPLAIN ANALYZE no Athena. Para obter mais informações sobre o Parquet Hive SerDe, consulte Parquet SerDe.
3 de julho de 2023
Publicado em 25/7/2023
A partir de 3 de julho de 2023, o Athena começou a ocultar as strings de consulta dos logs do CloudTrail. A string de consulta agora tem um valor de ***OMITTED***. Essa alteração foi feita para evitar a divulgação não intencional de nomes de tabelas ou valores de filtro que poderiam incluir informações sensíveis. Se você anteriormente dependia dos logs do CloudTrail para acesso total de strings de consulta, recomendamos usar a API Athena::GetQueryExecution e transmitir no valor de responseElements.queryExecutionId do log do CloudTrail. Para obter mais informações, consulte a ação GetQueryExecution na Amazon Athena API Reference.
30 de junho de 2023
Publicado em 30/6/2023
O editor de consultas do Athena agora é compatível com sugestões de código de digitação antecipada para proporcionar uma experiência de criação de consultas mais rápida. Agora você pode escrever consultas SQL com maior precisão e eficiência usando os seguintes atributos:
-
Enquanto você digita, as sugestões são exibidas em tempo real para palavras-chave, variáveis locais, trechos e itens de catálogo.
-
Quando você digita um nome de banco de dados ou nome de tabela seguido por um ponto, o editor exibe, de maneira conveniente, uma lista de tabelas ou colunas para escolher.
-
Quando você passa o mouse sobre uma sugestão de trecho, uma sinopse exibe uma breve visão geral da sintaxe e do uso do trecho.
-
Para melhorar a legibilidade do código, as palavras-chave e as respectivas regras de destaque também foram atualizadas para se alinharem à sintaxe mais recente do Trino e do Hive.
Esse recurso está habilitado por padrão. É possível habilitar ou desabilitar o atributo nas configurações de preferências do editor de código.
Para experimentar as sugestões de código de digitação antecipada no editor de consultas do Athena, acesse o console do Athena em https://console.aws.amazon.com/athena/
29 de junho de 2023
Publicado em 29/6/2023
-
O Athena anuncia o driver ODBC versão 2.0.1.0. Para obter mais informações, consulte as notas de versão do 2.0.1.0. Para baixar o driver ODBC v2, consulte Download do driver ODBC 2.x. Para obter informações sobre conexão, consulte o Amazon Athena ODBC 2.x.
-
O Athena e seus atributos
agora estão disponíveis na região do Oriente Médio (EAU). Para obter uma lista completa dos Serviços da AWS disponíveis em cada Região da AWS, consulte Serviços da AWS por região .
28 de junho de 2023
Publicado em 28/6/2023
Já é possível usar o Amazon Athena para consultar objetos restaurados das classes de armazenamento do Amazon S3 S3 Glacier Flexible Retrieval (antigo Glacier) e S3 Glacier Deep Archive. Configure esse recurso com base em tabelas. O atributo é compatível somente com tabelas do Apache Hive no mecanismo do Athena versão 3.
Para obter mais informações, consulte Consultar os objetos restaurados do Amazon Glacier.
12 de junho de 2023
Publicado em 12/6/2023
Athena anuncia as correções e melhorias a seguir.
-
Timestamps do Parquet Reader: a leitura de timestamps como
bigint(millissegundos) agora é compatível para o Parquet Reader. Esta atualização fornece paridade com o suporte em versões anteriores do mecanismo. -
EXPLAIN ANALYZE: foi adicionado o tempo de leitura da entrada física às estatísticas da consulta e à saída de
EXPLAIN ANALYZE. Para saber mais sobre oEXPLAIN ANALYZE, consulte Usar EXPLAIN e EXPLAIN ANALYZE no Athena. -
INSERT: melhoria na performance de consulta em tabelas gravadas com
INSERT. Para saber mais sobre oINSERT, consulte INSERT INTO. -
Tabelas do Delta Lake: foi corrigido um problema com as tabelas
DROP TABLEdo Delta Lake que impedia que elas fossem totalmente excluídas quando sujeitas a modificações simultâneas.
8 de junho de 2023
Publicado em 8/6/2023
O Amazon Athena para Apache Spark anuncia os novos atributos a seguir.
-
Suporte para bibliotecas e configurações personalizadas de Java: você já pode usar seus próprios pacotes e configurações personalizadas de Java para suas sessões do Apache Spark no Athena. Use as propriedades do Spark para especificar arquivos
.jar, pacotes ou outras configurações personalizadas com o console do Athena, a AWS CLI ou a API do Athena. Para obter mais informações, consulte Usar as propriedades do Spark para especificar uma configuração personalizada. -
Suporte para tabelas Apache Hudi, Apache Iceberg e Delta Lake: o Athena para Spark já é compatível com os formatos de tabela de armazenamento de data lake de código aberto Apache Iceberg, Apache Hudi e Linux Foundation Delta Lake. Para obter mais informações, consulte Usar formatos de tabela não Hive no Athena para Spark e os tópicos individuais de uso de tabelas Usar tabelas do Apache Iceberg no Athena para Spark, Usar tabelas do Apache Hudi no Athena para Spark e Usar tabelas do Linux Foundation Delta Lake no Amazon Athena para Apache Spark no Athena para Spark.
-
Criptografia compatível para o Apache Spark: no Athena para Spark, já é possível habilitar a criptografia em dados em trânsito entre os nós do Spark e em dados em repouso locais armazenados em disco pelo Spark. Para habilitar a criptografia do Spark, você pode usar o console do Athena, a AWS CLI ou a API do Athena. Para obter mais informações, consulte Habilitar a criptografia do Apache Spark.
Para obter mais informações sobre o Amazon Athena para Apache Spark, consulte Usar o Apache Spark no Amazon Athena.
2 de junho de 2023
Publicado em 02/06/2023
Agora você pode excluir reservas de capacidade no Athena e usar modelos do CloudFormation para especificar as reservas de capacidade do Athena.
-
Excluir reservas de capacidade: agora você pode excluir reservas de capacidade canceladas no Athena. Uma reserva deve ser cancelada para poder ser excluída. A exclusão de uma reserva de capacidade remove-a da sua conta imediatamente. A reserva excluída não pode mais ser referenciada nem por seu ARN. Para excluir uma reserva, você pode usar o console ou a API do Athena. Para obter mais informações, consulte Excluir uma reserva de capacidade no Guia do usuário do Amazon Athena e DeleteCapacityReservation na Referência de API do Amazon Athena.
-
Usar modelos do CloudFormation para reservas de capacidade: agora você pode usar modelos do AWS CloudFormation para especificar as reservas de capacidade do Athena usando o recurso
AWS::Athena::CapacityReservation. Para obter mais informações, consulte AWS::Athena::CapacityReservation no Guia do usuário do AWS CloudFormation.
Para obter mais informações sobre o uso de reservas de capacidade para provisionar capacidade no Athena, consulte Gerenciar a capacidade de processamento de consulta.
25 de maio de 2023
Publicado em 25/05/2023
O Athena lançou atualizações de conectores de fonte de dados que melhoram a performance em consultas federadas. Novas otimizações de passagem direta e filtragem dinâmica permitem que mais operações sejam realizadas no banco de dados de origem em vez ocorrerem no Athena. Essas otimizações reduzem o runtime das consultas e a quantidade de dados examinados. Essas melhorias requerem o mecanismo Athena versão 3.
Os seguintes conectores foram atualizados:
Para obter mais informações sobre como atualizar os conectores de fonte de dados, consulte Atualizar um conector de fonte de dados.
18 de maio de 2023
Publicado em 18/05/2023
Agora você pode usar o AWS PrivateLink para conexões de entrada IPv6 com o Amazon Athena.
O Amazon Athena ampliou a compatibilidade com conexões de entrada por endpoints Internet Protocol versão 6 (IPv6) para incluir o AWS PrivateLink
O rápido crescimento da Internet está esgotando a disponibilidade de endereços IPv4 (Protocolo de Internet versão 4). O IPv6 aumenta a quantidade de endereços disponíveis para que você não precise mais gerenciar espaços de endereço sobrepostos em suas VPCs. Com essa versão, agora você pode combinar os benefícios do endereçamento IPv6 com as vantagens de segurança e performance do AWS PrivateLink.
Para se conectar de forma programática a um serviço da AWS, você pode usar a AWS CLI
15 de maio de 2023
Publicado em 15/05/2023
O Athena anuncia o lançamento dos conectores DataSourceV2 (DSV2) do Apache Spark para o DynamoDB, o CloudWatch Logs, o CloudWatch Metrics e o AWS CMDB. Use os novos conectores DSV2 para consultar essas fontes de dados usando o Spark. Os conectores DSV2 usam os mesmos parâmetros dos conectores federados Athena correspondentes. Os conectores DSV2 são executados diretamente nos operadores do Spark e não exigem que você implante uma função do Lambda para usá-los.
Para obter mais informações, consulte Trabalhar com conectores de fonte de dados do Athena para o Apache Spark.
10 de maio de 2023
Publicado em 10/05/2023
Lançamento do driver ODBC 1.1.20 para o Athena.
Recursos e aprimoramentos:
-
Compatibilidade de endpoint Lake Formation com substituição.
-
O plug-in de autenticação do ADFS tem um novo parâmetro para definir o valor de Terceira parte confiável (
LoginToRP). -
AWSAtualizações da biblioteca da .
Correções de bugs:
-
Falha ao desalocar instrução previamente preparada quando ocorria uma falha no envio do método
SQLPrepare(). -
Erro ao vincular parâmetros de instrução previamente preparada ao converter um tipo C em SQL.
-
Falha no retorno de dados quando as consultas
EXPLAINeEXPLAIN ANALYZEusavamSQLPrepare()eSQLExecute().
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com ODBC.
8 de maio de 2023
Publicado em 08/05/2023
Athena anuncia as correções e melhorias a seguir.
-
Atualização da integração com o Hudi: o Athena atualizou sua integração com o Apache Hudi. Agora você pode usar o Athena para consultar as tabelas do Hudi 0.12.2, e as tabelas do Hudi agora são compatíveis com listagem de metadados do Hudi. Para obter informações, consulte Consultar conjuntos de dados do Apache Hudi e Usar de metadados Hudi para aprimorar a performance.
-
Correção de conversão de timestamp: foi corrigido o tratamento de conversões de timestamp para um tipo de dados de menor precisão. Anteriormente, o mecanismo Athena versão 3 arredondava incorretamente o valor para o tipo de destino em vez de truncá-lo durante a conversão.
Os exemplos a seguir ilustram o tratamento incorreto antes da correção.
Exemplo 1: conversão de um timestamp em microssegundos para milissegundos
Dados de exemplo
A, 2020-06-10 15:55:23.383 B, 2020-06-10 15:55:23.382 C, 2020-06-10 15:55:23.383345 D, 2020-06-10 15:55:23.383945 E, 2020-06-10 15:55:23.383345734 F, 2020-06-10 15:55:23.383945278A consulta a seguir tenta recuperar os timestamps que correspondem a um valor específico.
SELECT * FROM table WHERE timestamps.col = timestamp'2020-06-10 15:55:23.383'A consulta retorna os resultados a seguir.
A, 2020-06-10 15:55:23.383 C, 2020-06-10 15:55:23.383 E, 2020-06-10 15:55:23.383Antes da correção, o Athena não incluía os valores
2020-06-10 15:55:23.383945ou2020-06-10 15:55:23.383945278porque eles eram arredondados para2020-06-10 15:55:23.384.Exemplo 2: conversão de um timestamp em data
A consulta a seguir retornou um resultado incorreto.
SELECT date(timestamp '2020-12-31 23:59:59.999')Resultado
2021-01-01Antes da correção, o Athena arredondava o valor, adiantando, portanto, o dia. Esses valores agora são truncados em vez de arredondados.
28 de abril de 2023
Publicado em 28/4/2023
Já é possível usar reservas de capacidade no Amazon Athena para executar consultas SQL em capacidade de computação totalmente gerenciada.
A capacidade provisionada fornece recursos de gerenciamento de workload que ajudam a priorizar, controlar e escalar suas workloads interativas mais importantes. Você pode adicionar capacidade a qualquer momento para aumentar o número de consultas que poderão ser executadas simultaneamente, controlar quais workloads usarão a capacidade e compartilhar a capacidade entre as workloads.
Para obter mais informações, consulte Gerenciar a capacidade de processamento de consulta. Para obter informações, acesse a página de preços do Amazon Athena
17 de abril de 2023
Publicado em 17/4/2023
O Athena libera o driver JDBC versão 2.0.36. O driver contém novos recursos e resolveu um problema.
Novos atributos
-
Já é possível usar identificadores personalizáveis de terceiros confiáveis com a autenticação AD FS.
-
Já é possível adicionar o nome da aplicação que está usando o conector à string do agente do usuário.
Problemas resolvidos
-
Foi corrigido um erro que ocorria com o uso de
getSchema()para recuperar um esquema inexistente.
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com JDBC.
14 de abril de 2023
Publicado em 20/6/2023
Athena anuncia as correções e melhorias a seguir.
-
Quando você converte uma string para timestamp, é necessário um espaço entre o dia e a hora ou o fuso horário. Para obter mais informações, consulte Espaço necessário entre os valores de data e hora ao converter de string para timestamp.
-
Foi removida uma alteração importante na forma como a precisão do timestamp era tratada. Para manter a consistência entre versões anteriores do mecanismo e o mecanismo do Athena versão 3, a precisão do timestamp foi padronizada para milissegundos em vez de microssegundos.
-
O Athena agora impõe, de maneira consistente, o acesso ao bucket de saída da consulta ao executar consultas. Certifique-se de que todas as entidades principais do IAM que executam a ação StartQueryExecution tenham a permissão S3:GetBucketLocation no bucket de saída da consulta.
4 de abril de 2023
Publicado em 4/4/2023
Já é possível usar o Amazon Athena para criar e consultar visualizações em fontes de dados federadas. Use uma única visualização federada para consultar várias tabelas externas ou subconjuntos de dados. Isso simplifica o SQL necessário e oferece a flexibilidade de ofuscar fontes de dados de usuários finais que precisam usar SQL para consultar os dados.
Para obter mais informações, consulte Trabalhar com visualizações e Executar consultas federadas.
30 de março de 2023
Publicado em 30/3/2023
O Amazon Athena anuncia a disponibilidade do Amazon Athena para Apache Spark em outras Regiões da AWS.
Esta versão expandiu o Amazon Athena para Apache Spark e agora inclui Ásia-Pacífico (Mumbai), Ásia-Pacífico (Singapura), Ásia-Pacífico (Sydney) e Europa (Frankfurt).
Para obter mais informações sobre o Amazon Athena para Apache Spark, consulte Usar o Apache Spark no Amazon Athena.
28 de março de 2023
Publicado em 28/3/2023
Athena anuncia as correções e melhorias a seguir.
-
Nas respostas às ações de API
GetQueryExecutioneBatchGetQueryExecutiondo Athena, o novo camposubStatementTypemostra o tipo de consulta executada (por exemplo,SELECT,INSERT,UNLOAD,CREATE_TABLEouCREATE_TABLE_AS_SELECT). -
Foi corrigido um bug no qual os arquivos de manifesto não eram criptografados corretamente para as operações de gravação do Apache Hive.
-
O mecanismo Athena versão 3 agora manipula valores
NaNeInfinitycorretamente na funçãoapprox_percentile. A funçãoapprox_percentileretorna o percentil aproximado de um conjunto de dados na porcentagem dada.O mecanismo Athena versão 2 trata incorretamente
NaNcomo um valor maior queInfinity. O mecanismo Athena versão 3 agora manipulaNaNeInfinityde acordo com o tratamento desses valores em outras funções analíticas e estatísticas. Os pontos a seguir descrevem o novo comportamento com mais detalhes.-
Se
NaNestiver presente no conjunto de dados, o Athena retornaráNaN. -
Se
NaNnão estiver presente, masInfinityestiver presente, o Athena trataráInfinitycomo um número muito grande. -
Se vários valores
Infinityestiverem presentes, o Athena os tratará como o mesmo número muito grande. Se necessário, o Athena produzInfinity. -
Se um único conjunto de dados tiver tanto
Infinitycomo-Double.MAX_VALUE, e um resultado percentil for-Double.MAX_VALUE, o Athena retornará-Infinity. -
Se um único conjunto de dados tiver tanto
InfinitycomoDouble.MAX_VALUE, e um resultado percentil forDouble.MAX_VALUE, o Athena retornaráInfinity. -
Para excluir
InfinityeNaNde um cálculo, use a funçãois_finite(), como no exemplo a seguir.approx_percentile(x, 0.5) FILTER (WHERE is_finite(x))
-
27 de março de 2023
Publicado em 27/3/2023
Agora é possível especificar um nível mínimo de criptografia em grupos de trabalho de SQL do Athena no Amazon Athena. Esse recurso garante que os resultados de todas as consultas do grupo de trabalho de SQL do Athena sejam criptografados no nível de criptografia especificado ou acima. É possível escolher entre vários níveis de força de criptografia para proteger os dados. Para configurar o nível mínimo de criptografia desejado, use o console, a AWS CLI, a API ou o SDK do Athena.
O recurso de criptografia mínima não está disponível para grupos de trabalho habilitados para o Apache Spark. Para obter mais informações, consulte Configurar criptografia mínima para um grupo de trabalho.
17 de março de 2023
Publicado em 17/3/2023
Athena anuncia as correções e melhorias a seguir.
-
Foi corrigido um problema com o conector do Amazon Athena para DynamoDB que fazia com que as consultas falhassem com a mensagem de erro
KeyConditionExpressions deve conter apenas uma condição por chave.Esse problema ocorre porque o mecanismo Athena versão 3 reconhece a oportunidade de propagar mais tipos de predicados do que o mecanismo Athena versão 2. No mecanismo Athena versão 3, cláusulas como
some_column LIKE 'someprefix%são propagadas como predicados de filtro que aplicam um limite inferior e superior a determinada coluna. O mecanismo Athena versão 2 não propagava esses predicados. No mecanismo Athena versão 3, quandosome_columné uma coluna de chave de classificação, o mecanismo propaga o predicado do filtro até o conector do DynamoDB. Em seguida, o predicado do filtro é propagado ainda para o serviço do DynamoDB. Como o DynamoDB não oferece suporte a mais de uma condição de filtro em uma chave de classificação, o DynamoDB retorna o erro.Para corrigir esse problema, atualize o conector do Amazon Athena para DynamoDB para a versão 2023.11.1. Para obter instruções sobre como atualizar o conector, consulte Atualizar um conector de fonte de dados.
8 de março de 2023
Publicado em 8/3/2023
Athena anuncia as correções e melhorias a seguir.
-
Foi corrigido um problema com consultas federadas que fazia com que os valores dos predicados de timestamp fossem enviados como microssegundos em vez de milissegundos.
15 de fevereiro de 2023
Publicado em 15/2/2023
Athena anuncia as correções e melhorias a seguir.
-
Já é possível usar a criptografia do lado do cliente para criptografar dados no Amazon S3 para operações de gravação do Iceberg.
-
Foi corrigido um problema que afetava a criptografia do lado do servidor no Amazon S3 em operações de gravação do Iceberg.
31 de janeiro de 2023
Publicado em 31/01/2023
Agora você pode usar o Amazon Athena para consultar dados no Google Cloud Storage. Como o Amazon S3, o Google Cloud Storage é um serviço gerenciado que armazena dados em buckets. Para executar consultas federadas interativas em seus dados externos, use o conector do Athena para Google Cloud Storage.
Para obter mais informações, consulte Conector Google Cloud Storage para Amazon Athena.
20 de janeiro de 2023
Publicado em 20/01/2023
Agora você pode ver a documentação expandida referente ao suporte à compactação do Athena. Foram adicionados tópicos adicionais referentes a Compactação de tabelas do Hive, Compactação de tabelas do Iceberg e Níveis de compactação ZSTD.
Para obter mais informações, consulte Usar compactação no Athena.
3 de janeiro de 2023
Publicado em 3/1/2023
O Athena anuncia as atualizações a seguir:
-
Comandos adicionais para metastores do Hive: é possível usar o Athena para se conectar ao Apache Hive Metastore autogerenciado como um catálogo de metadados e dados de consulta armazenados no Amazon S3. Com esta versão, é possível usar
CREATE TABLE AS(CTAS),INSERT INTOe 12 comandos adicionais de linguagem de definição de dados (DDL) para interagir com o Apache Hive Metastore. Você pode gerenciar os esquemas do Hive Metastore diretamente do Athena usando esse conjunto expandido de recursos SQL.Para obter mais informações, consulte Usar um metastore externa do Hive.
-
Driver JDBC versão 2.0.35: o Athena realiza o lançamento do driver JDBC versão 2.0.35. O driver JDBC 2.0.35 contém as atualizações a seguir:
-
O driver passou a usar as bibliotecas a seguir para o analisador Jackson JSON.
-
jackson-annotations 2.14.0 (anteriormente 2.13.2)
-
jackson-core 2.14.0 (anteriormente 2.13.2)
-
jackson-databind 2.14.0 (anteriormente 2.13.2.2)
-
-
O suporte para o JDBC versão 4.1 foi descontinuado.
Para obter mais informações e baixar do novo driver, das notas de lançamento e da documentação, consulte Conectar ao Amazon Athena com JDBC.
-
Notas de release do Athena para 2022
14 de dezembro de 2022
Publicado em 14/12/2022
Agora é possível usar o conector do Amazon Athena para Kafka para executar consultas SQL em dados de streaming. Por exemplo, você pode executar consultas analíticas em dados de streaming em tempo real no Amazon Managed Streaming for Apache Kafka (Amazon MSK) e associá-los a dados históricos em seu data lake no Amazon S3.
O conector do Amazon Athena para Kafka é compatível com consultas em diversos mecanismos de streaming. É possível usar o Athena para executar consultas SQL em clusters provisionados e com tecnologia sem servidor do Amazon MSK, em implantações autogerenciadas do Kafka e em streaming de dados na Confluent Cloud.
Para obter mais informações, consulte Conector MSK do Amazon Athena.
2 de dezembro de 2022
Publicado em 2/12/2022
O Athena realiza o lançamento do driver JDBC versão 2.0.34. O driver JDBC 2.0.34 inclui os novos recursos e problemas resolvidos apresentados a seguir:
-
Reutilização dos resultados da consulta compatível: agora é possível reutilizar os resultados de consultas executadas anteriormente até um limite de tempo especificado, em vez de fazer com que o Athena recalcule os resultados sempre que a consulta for executada. Para obter mais informações, consulte o Guia de instalação e configuração, disponível na página de download do JDBC, e Reutilização de resultados da consulta no Athena.
-
Suporte para EC2InstanceMetadata: o driver JDBC passou a ser compatível com o método de autenticação EC2InstanceMetadata usando perfis de instância do IAM.
-
Correção de exceção baseada em caracteres: uma exceção que ocorria com consultas contendo determinados caracteres de idioma foi corrigida.
-
Correção de vulnerabilidade: uma vulnerabilidade relacionada às dependências da AWS empacotadas com o conector.
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com JDBC.
30 de novembro de 2022
Publicado em 30/11/2022
Agora é possível criar e executar, de forma interativa, aplicações Apache Spark e cadernos compatíveis com Jupyter no Athena. Execute data analytics no Athena usando o Spark sem a necessidade de planejar, configurar ou gerenciar recursos. Envie o código Spark para processamento e receba os resultados de forma direta. Use a experiência simplificada de cadernos no console do Amazon Athena para desenvolver aplicações do Apache Spark usando Python ou Usar APIs do Athena Spark.
O Apache Spark no Amazon Athena corresponde a uma tecnologia sem servidor e oferece uma escalabilidade automática sob demanda que fornece computação instantânea para atender aos volumes de dados em constante mudança e aos requisitos de processamento.
Para obter mais informações, consulte Usar o Apache Spark no Amazon Athena.
18 de novembro de 2022
Publicado em 18/11/2022
Agora é possível usar o conector do Amazon Athena para IBM Db2 para consultar o Db2 do Athena. Por exemplo, você pode executar consultas analíticas em um data warehouse no Db2 e em um data lake no Amazon S3.
O conector Db2 do Amazon Athena apresenta diversas opções de configurações por meio de variáveis de ambiente do Lambda. Para obter informações sobre as opções de configuração, os parâmetros, as strings de conexão, a implantação e as limitações, consulte Conector IBM Db2 do Amazon Athena.
17 de novembro de 2022
Publicado em 17/11/2022
O suporte ao Apache Iceberg na versão 3 do mecanismo do Athena passou a oferecer os recursos de transação ACID aprimorados a seguir:
-
Compatibilidade do ORC e Avro: crie tabelas do Iceberg usando os formatos de arquivo Apache Avro
e Apache ORC baseados em linha e coluna. O suporte para esses formatos é adicional ao suporte existente para Parquet. -
MERGE INTO: use o comando
MERGE INTOpara mesclar dados em escala de forma eficiente.MERGE INTOcombina as operaçõesINSERT,UPDATEeDELETEem uma única transação. Isso reduz a sobrecarga de processamento em seu pipeline de dados e requer menos SQL para ser gravado. Para obter mais informações, consulte Atualizar dados nas tabelas do Iceberg e MERGE INTO. -
Compatibilidade do CTAS e VIEW: use as instruções
CREATE TABLE AS SELECT(CTAS) eCREATE VIEWcom tabelas do Iceberg. Para obter mais informações, consulte CREATE TABLE AS e CREATE VIEW e da CREATE PROTECTED MULTI DIALECT VIEW. -
Compatibilidade do VACUUM: é possível usar a instrução
VACUUMpara otimizar seu data lake ao excluir snapshots e dados que não são mais necessários. Você pode usar esse recurso para melhorar a performance de leitura e atender aos requisitos regulatórios, como o GDPR. Para obter mais informações, consulte Otimizar tabelas do Iceberg e VACUUM.
Esses novos recursos requerem a versão 3 do mecanismo do Athena e estão disponíveis em todas as regiões em que o Athena é compatível. É possível usá-los com drivers, APIs ou com o console do Athena
Para obter informações sobre como usar o Iceberg no Athena, consulte Consultar tabelas do Apache Iceberg.
14 de novembro de 2022
Publicado em 14/11/2022
O Amazon Athena passou a ser compatível com endpoints do IPv6 para conexões de entrada que você pode usar para invocar funções do Athena usando o IPv6. É possível usar esse recurso para atender aos requisitos de conformidade do IPv6. Isso também elimina a necessidade de equipamentos de rede adicionais para tratar da conversão de endereços entre o IPv4 e o IPv6.
Para usar esse recurso, configure suas aplicações para usar os novos endpoints de pilha dupla do Athena, que são compatíveis com IPv4 e IPv6. Os endpoints de pilha dupla, usam o formato athena.. Por exemplo, o endpoint de pilha dupla na região Leste dos EUA (Norte da Virgínia) é region.api.awsathena.us-east-1.api.aws.
Quando você realiza uma solicitação para um endpoint de pilha dupla do Athena, o endpoint decide para um endereço IPv6 ou IPv4, dependendo do protocolo usado pela rede e pelo cliente. Para se conectar de forma programática a um serviço da AWS, você pode usar a AWS CLI
Para obter mais informações sobre endpoints de serviço, consulte Endpoints de serviço da AWS. Para saber mais sobre os endpoints de serviço do Athena, consulte Amazon Athena endpoints and quotas (Endpoints e cotas do Amazon Athena) na documentação da AWS.
É possível usar os novos endpoints de pilha dupla do Athena para conexões de entrada sem custos adicionais. Os endpoints de pilha dupla geralmente estão disponíveis em todas as Regiões da AWS.
11 de novembro de 2022
Publicado em 11/11/2022
Athena anuncia as correções e melhorias a seguir.
-
Expansão do controle de acesso detalhado do Lake Formation: agora é possível usar políticas de controle de acesso detalhado do AWS Lake Formation
nas consultas do Athena para dados armazenados em qualquer formato de arquivo ou tabela compatível. É possível usar o controle de acesso detalhado no Lake Formation para restringir o acesso aos dados nos resultados da consulta ao usar filtros de dados para obter segurança em nível de coluna, de linha e de célula. Os formatos de tabela compatíveis no Athena incluem Apache Iceberg, Apache Hudi e Apache Hive. A expansão do controle de acesso detalhado está disponível em todas as regiões compatíveis com o Athena. O suporte expandido para formatos de tabelas e arquivos requer a Mecanismo Athena versão 3, que oferece novos recursos e performance de consulta aprimorada , mas não altera a forma como você configura as políticas de controle de acesso detalhadas no Lake Formation. O uso dessa expansão de controle de acesso detalhado no Athena tem as seguintes considerações:
-
EXPLAIN: as informações de filtragem de linhas ou de células definidas no Lake Formation e as informações de estatísticas da consulta não são mostradas na saída do
EXPLAINe doEXPLAIN ANALYZE. Para obter informações sobre oEXPLAINno Athena, consulte Usar EXPLAIN e EXPLAIN ANALYZE no Athena. -
Metastores do Hive externos: as colunas ocultas do Apache Hive não podem ser usadas para filtragem de controle de acesso detalhado, e as tabelas de sistema ocultas do Apache Hive não tem suporte pelo controle de acesso detalhado. Para saber mais, consulte Considerações e limitações no tópico Usar um metastore externa do Hive.
-
Estatísticas de consulta: as informações referentes a contagem de linhas e ao tamanho dos dados de entrada e saída em nível de estágio não são mostradas nas estatísticas de consulta do Athena quando uma consulta tem filtros em nível de linha definidos no Lake Formation. Para obter informações sobre como visualizar estatísticas para consultas do Athena, consulte Visualizar estatísticas e detalhes de execução para consultas concluídas e GetQueryRuntimeStatistics.
-
Grupos de trabalho: os usuários do mesmo grupo de trabalho do Athena podem visualizar os dados que o controle de acesso detalhado do Lake Formation configurou para serem acessíveis ao grupo de trabalho. Para obter informações sobre como usar o Athena para consultar dados registrados no Lake Formation, consulte Usar o Athena para consultar dados registrados no AWS Lake Formation.
Para obter informações sobre como usar o controle de acesso detalhado no Lake Formation, consulte Gerenciar o controle de acesso detalhado usando o AWS Lake Formation
no AWS Big Data Blog. -
-
Consulta federada do Athena: a consulta federada do Athena passou a preservar a capitalização original de nomes de campo em objetos
struct. Anteriormente, os nomes dos camposstructeram automaticamente transformados em minúsculas.
8 de novembro de 2022
Publicado em 8/11/2022
Agora é possível usar o recurso de armazenamento em cache para reutilização dos resultados da consulta com a finalidade de acelerar consultas repetidas no Athena. Uma consulta repetida corresponde a uma consulta SQL idêntica a uma enviada recentemente que produz resultados semelhantes. Quando você tem necessidade de executar diversas consultas idênticas, o armazenamento em cache para reutilização de resultados pode diminuir o tempo necessário para produzir resultados. O armazenamento em cache para reutilização de resultados também reduz os custos ao reduzir o número de bytes verificados.
Para obter mais informações, consulte Reutilização de resultados da consulta no Athena.
13 de outubro de 2022
Publicado em 13/10/2022
Athena anuncia o mecanismo Athena versão 3.
O Athena atualizou seu mecanismo de consulta SQL para incluir os recursos mais recentes do projeto de código aberto Trino
Para obter mais informações, consulte Mecanismo Athena versão 3.
10 de outubro de 2022
Publicado em 10/10/2022
Athena lança o driver JDBC versão 2.0.33. O driver JDBC 2.0.33 inclui as seguintes alterações:
-
Adição de nova versão do driver, versão do JDBC e propriedades de nome do plug-in à string user-agent na classe do provedor de credenciais.
-
As mensagens de erro foram corrigidas e as informações necessárias foram adicionadas.
-
Agora, as declarações preparadas são desalocadas se a conexão for encerrada ou se a execução da instrução preparada pelo Athena falhar.
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com JDBC.
23 de setembro de 2022
Publicado em 26/9/2022
Agora, o conector Amazon Athena Neptune oferece suporte à correspondência sem fazer distinção entre maiúsculas e minúsculas em nomes de colunas e tabelas.
-
O conector da fonte de dados do Neptune é capaz de resolver nomes de colunas em tabelas do Neptune que usam letras maiúsculas e minúsculas, mesmo que os nomes das colunas estejam todos em minúsculas na tabela em AWS Glue. Para ativar esse comportamento, defina a variável de ambiente
enable_caseinsensitivematchcomotruena função Lambda do conector Neptune. -
Como o AWS Glue só é compatível com nomes de tabelas em letras minúsculas, ao criar uma tabela AWS Glue para o Neptune, especifique o parâmetro
"glabel" =da tabela AWS Glue.table_name
Para obter mais informações sobre o conector Neptune, consulte Conector do Amazon Athena para o Neptune.
13 de setembro de 2022
Publicado em 13/9/2022
Athena anuncia as correções e melhorias a seguir.
-
Metastore externo do Hive: o Athena agora retorna
NULLem vez de lançar uma exceção quando uma cláusulaWHEREinclui uma partição que não exista em um metastore externo do Hive (EHMS). O novo comportamento corresponde ao do AWS Glue Data Catalog. -
Consultas parametrizadas: valores em consultas parametrizadas agora pode ser convertidos para o tipo de dados
DOUBLE. -
Apache Iceberg: as operações de escrita em tabelas do Iceberg agora têm êxito quando Object Lock (Bloquear objetos) está habilitado em um bucket do Amazon S3.
31 de agosto de 2022
Publicado em 31/8/2022
O Amazon Athena anuncia a disponibilidade do Athena e de seus recursos
Esta versão expande a disponibilidade do Athena nas regiões Ásia-Pacífico para incluir Ásia-Pacífico (Hong Kong), Ásia-Pacífico (Jacarta), Ásia-Pacífico (Mumbai), Ásia-Pacífico (Osaka), Ásia-Pacífico (Seul), Ásia-Pacífico (Singapura), Ásia-Pacífico (Sydney) e Ásia-Pacífico (Tóquio). Para ver uma lista completa dos Serviços da AWS disponíveis nessas e em outras regiões, consulte a Lista de serviços por Região da AWS
23 de agosto de 2022
Publicado em 23/8/2022
A versão v2022.32.1
-
Foi adicionado suporte ao conector de fonte de dados Amazon Athena Oracle para conexões baseadas em SSL para instâncias do Amazon RDS. O suporte é limitado ao protocolo Transport Layer Security (TLS) e à autenticação do servidor pelo cliente. Como não há suporte para autenticação mútua no Amazon RDS, a atualização não inclui suporte para autenticação mútua.
Para obter mais informações, consulte Conector do Amazon Athena para Oracle.
3 de agosto de 2022
Publicado em 3/8/2022
Athena lança o driver JDBC versão 2.0.32. O driver JDBC 2.0.32 inclui as seguintes alterações:
-
A cadeia de caracteres
User-Agentenviada ao SDK do Athena foi estendida para conter a versão do driver, a versão da especificação JDBC e o nome do plugin de autenticação. -
Um
NullPointerExceptionque era lançado quando nenhum valor era fornecido para o parâmetroCheckNonProxyHostfoi corrigido. -
Um problema com análise de
login_urlno plugin de autenticação BrowserSaml foi corrigido. -
Um problema de host do proxy que ocorria quando o parâmetro
UseProxyforIdpera definido comotruefoi corrigido.
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com JDBC.
1º de agosto de 2022
Publicado em 01/08/2022
Athena anuncia melhorias no SDK do Athena Query Federation e em conectores de fonte de dados pré-criados do Athena. As melhorias incluem:
-
Análise de structs: correção de um problema de análise
GlueFieldLexerno SDK do Athena Query Federation que impedia que certos structs complicados exibissem todos os seus dados. Esse problema afetava os conectores criados no SDK do Athena Query Federation. -
Tabelas de AWS Glue: inclusão de suporte adicional para os tipos de colunas
setedecimalem tabelas de AWS Glue. -
Conector DynamoDB: inclusão da capacidade de ignorar a capitalização em nomes de atributos do DynamoDB. Para obter mais informações, consulte
disable_projection_and_casingna seção Parâmetros da página Conector do Amazon Athena para o DynamoDB.
Para obter mais informações, consulte a Versão v2022.30.2 do Athena Query Federation
21 de julho de 2022
Publicado em 21/07/2022
Agora, é possível analisar e depurar consultas usando métricas de performance e ferramentas interativas de análise de consultas visuais no console do Athena. Os dados de performance e os detalhes de execução de consultas podem ajudar você a identificar limitações em consultas, inspecionar os operadores e as estatísticas de cada estágio de uma consulta, acompanhar o volume de dados que fluem entre os estágios e validar o impacto de predicados de consultas. Agora é possível:
-
Acesse o plano de execução distribuída e lógica da sua consulta com um único clique.
-
Explore as operações em cada estágio antes que ele seja executado.
-
Visualize a performance de consultas concluídas com métricas para o tempo gasto nos estágios de enfileiramento, planejamento e execução.
-
Obtenha informações sobre o número de linhas e a quantidade de dados de origem processados e gerados pela consulta.
-
Veja detalhes de execução granulares para suas consultas apresentados em contexto e formatados como um gráfico interativo.
-
Use detalhes de execução precisos em nível de estágio para compreender o fluxo de dados na sua consulta.
-
Analise dados de performance de consulta programaticamente usando novas APIs para obter estatísticas de runtime de consultas, também lançadas hoje.
Para saber como usar esses recursos nas suas consultas, assista ao tutorial em vídeo Optimize Amazon Athena Queries with New Query Analysis Tools
Para acessar a documentação, consulte Visualização de planos de execução para consultas SQL e Visualizar estatísticas e detalhes de execução para consultas concluídas.
11 de julho de 2022
Publicado em 11/07/2022
Agora, é possível executar consultas parametrizadas diretamente do console ou da API do Athena sem preparar instruções SQL com antecedência.
Quando você executa consultas no console do Athena que têm parâmetros em forma de pontos de interrogação, a interface do usuário agora solicita que valores sejam inseridos diretamente para os parâmetros. Isso dispensa a necessidade de modificar valores literais no editor de consultas todas as vezes que você quiser executar a consulta.
Se você usar a API aprimorada de execução de consultas, agora poderá fornecer os parâmetros de execução e seus valores em uma única chamada.
Para obter mais informações, consulte Usar consultas parametrizadas neste guia do usuário e a postagem no Blog de Big Data da AWS Use Amazon Athena parameterized queries to provide data as a service
8 de julho de 2022
Publicado em 08/07/2022
Athena anuncia as correções e melhorias a seguir.
-
Correção de um problema com o tratamento de conversão de colunas
DATEpara endpoints do SageMaker AI (UDF) que estava causando falhas de consultas.
6 de junho de 2022
Publicado em 06/06/2022
Athena lança o driver JDBC versão 2.0.31. O driver JDBC 2.0.31 inclui as seguintes alterações:
-
Problema de dependência log4j: implantação de solução para uma mensagem de erro
Cannot find driver class(Não é possível localizar a classe do driver) causada por uma dependência log4j.
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com JDBC.
25 de maio de 2022
Publicado em 25/05/2022
Athena anuncia as correções e melhorias a seguir.
-
Compatibilidade com Iceberg
-
Lançamento de compatibilidade para consultas entre regiões. Agora é possível consultar tabelas do Iceberg em uma Região da AWS diferente da Região da AWS que você está usando. Não há suporte para consultas entre regiões nas regiões da China.
-
Lançamento de compatibilidade com configuração de criptografia no lado do servidor. Agora você pode usar SSE-S3/SSE-KMS para criptografar dados de operações de gravação do Iceberg no Amazon S3.
Para obter mais informações sobre como usar o Apache Iceberg no Athena, consulte Consultar tabelas do Apache Iceberg.
-
-
Lançamento do driver JDBC
O driver JDBC 2.0.30 para Athena oferece as seguintes melhorias:
-
Correção de um problema de corrida de dados que afetava instruções preparadas parametrizadas.
-
Correção de um problema de inicialização do aplicativo que ocorria em ambientes de compilação do Gradle.
Para baixar o driver JDBC 2.0.30, ver as notas de release e a documentação, consulte Conectar ao Amazon Athena com JDBC.
-
6 de maio de 2022
Publicado em 06/05/2022
Lançamento dos drivers JDBC 2.0.29 e ODBC 1.1.17 para o Athena.
Esses drivers incluem as seguintes alterações:
-
Atualização do processo de inicialização do navegador de plugins SAML.
Para obter mais informações sobre essas alterações e baixar os novos drivers, as notas de release e a documentação, consulte Conectar ao Amazon Athena com JDBC e Conectar ao Amazon Athena com ODBC.
22 de abril de 2022
Publicado em 22/04/2022
Athena anuncia as correções e melhorias a seguir.
-
Correção de um problema no recurso de índices de partição e filtragem
com o cache de partição que ocorria quando as seguintes condições eram atendidas: -
A chave
partition_filtering.enabledera definida comotruenas propriedades da tabela do AWS Glue para uma tabela. -
A mesma tabela era usada várias vezes com valores diferentes de filtro de partição.
-
21 de abril de 2022
Publicado em 21/04/2022
Agora você pode usar o Amazon Athena para executar consultas federadas em novas origens de dados, incluindo Google BigQuery, Azure Synapse e Snowflake. Os novos conectores de origem dos dados incluem:
Para obter a lista completa das fontes de dados compatíveis com o Athena, consulte Conectores de fonte de dados disponíveis.
Para facilitar a navegação pelas origens disponíveis e se conectar a seus dados, agora você pode pesquisar, classificar e filtrar os conectores disponíveis em uma tela Data Sources (Fontes de dados) atualizada no console do Athena.
Para saber mais sobre como consultar fontes federadas, consulte Usar a consulta federada do Amazon Athena e Executar consultas federadas.
13 de abril de 2022
Publicado em 13/04/2022
Athena lança o driver JDBC versão 2.0.28. O driver JDBC 2.0.28 inclui as seguintes alterações:
-
Suporte a JWT: agora o driver oferece suporte a tokens da Web JSON (JWT) para fins de autenticação. Para obter informações sobre o uso de JWT com o driver JDBC, consulte o guia de instalação e configuração, disponível para download na página do driver JDBC.
-
Atualização das bibliotecas do Log4j: o driver JDBC agora usa as seguintes bibliotecas do Log4j:
-
Log4j-api 2.17.1 (anteriormente 2.17.0)
-
Log4j-core 2.17.1 (anteriormente 2.17.0)
-
Log4j-jcl 2.17.2
-
-
Outras melhorias: o novo driver também inclui as seguintes melhorias e correções de erros:
-
O recurso de instruções preparadas do Athena agora está disponível usando o JDBC. Para obter informações sobre instruções preparadas, consulte Usar consultas parametrizadas.
-
A federação SAML para o driver JDBC do Athena agora funciona nas regiões da China.
-
Pequenas melhorias adicionais.
-
Para obter mais informações e baixar os novos drivers, as notas de lançamento e a documentação, consulte Conectar ao Amazon Athena com JDBC.
30 de março de 2022
Publicado em 30/03/2022
Athena anuncia as correções e melhorias a seguir.
-
Consultas entre regiões: agora você pode usar o Athena para consultar dados localizados em um bucket do Amazon S3 entre Regiões da AWS, incluindo Ásia-Pacífico (Hong Kong), Oriente Médio (Bahrein), África (Cidade do Cabo) e Europa (Milão). Não há suporte para consultas entre regiões nas regiões da China.
-
Para obter uma lista de Regiões da AWS em que o Athena está disponível, consulte Amazon Athena endpoints and quotas (Endpoints e cotas do Amazon Athena).
-
Para obter informações sobre como habilitar uma Região da AWS que está desativada por padrão, consulte Enabling a Region (Habilitar uma região).
-
Para obter informações sobre consultas entre regiões, visite Consulta entre regiões.
-
18 de março de 2022
Publicado em 18/03/2022
Athena anuncia as correções e melhorias a seguir.
-
Filtragem dinâmica: a filtragem dinâmica foi melhorada para colunas de inteiros aplicando eficientemente o filtro a cada registro de uma tabela correspondente.
-
Iceberg: corrigido um problema que causava falhas ao gravar arquivos Iceberg Parquet maiores que 2 GB.
-
Saída descompactada: as instruções CREATE TABLE agora são compatíveis com a gravação de arquivos não compactados. Para gravar arquivos descompactados, use a seguinte sintaxe:
-
CREATE TABLE (arquivo de texto ou JSON): Em
TBLPROPERTIES, especifiquewrite.compression = NONE. -
CREATE TABLE (Parquet): em
TBLPROPERTIES, especifiqueparquet.compression = UNCOMPRESSED. -
CREATE TABLE (ORC): em
TBLPROPERTIES, especifiqueorc.compress = NONE.
-
-
Compactação: corrigido um problema com inserções para tabelas de arquivos de texto que criavam arquivos compactados em um formato, mas usavam outra extensão de arquivo de formato de compactação quando métodos de compactação não padrão eram usados.
-
Avro: corrigidos problemas que ocorriam ao ler decimais do tipo fixo dos arquivos Avro.
2 de março de 2022
Publicado em 02/03/2022
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
Agora, você pode conceder ao proprietário do bucket do Amazon S3 acesso de controle total sobre os resultados das consultas quando ACLs estão habilitadas para o bucket de resultados de consultas. Para obter mais informações, consulte Especificar um local para resultados de consultas.
-
Agora, é possível atualizar consultas nomeadas existentes. Para obter mais informações, consulte Usar consultas salvas.
23 de fevereiro de 2022
Publicado em 23/02/2022
Athena anuncia as seguintes correções e melhorias de performance.
-
Melhorias de tratamento de memória para aumentar a performance e reduzir erros de memória.
-
Agora, o Athena faz a leitura de colunas de timestamp ORC com informações de fuso horário armazenadas em rodapés de faixas e grava arquivos ORC com fuso horário (UTC) em rodapés. Isso afeta somente o comportamento de leituras de timestamp quando o arquivo ORC a ser lido foi criado em um ambiente de fuso horário não UTC.
-
Correção de estimativas incorretas de tamanho de tabela de links simbólicos que resultavam em planos de consulta inferiores ao ideal.
-
Exibições laterais explodidas agora podem ser consultadas no console do Athena a partir de origens de dados de metastore do Hive.
-
Melhorias em mensagens de erro de leitura do Amazon S3 para incluir informações mais detalhadas sobre o Código de erro do Amazon S3.
-
Correção de um problema que fazia com que arquivos de saída no formato ORC perdessem a compatibilidade com o Apache Hive 3.1.
-
Correção de um problema que fazia com que nomes de tabelas com aspas falhassem em certas consultas DML e DDL.
15 de fevereiro de 2022
Publicado em 15/02/2022
Amazon Athena aumentou a cota de consultas DML ativas em todas as Regiões da AWS. Consultas ativas incluem consultas em execução e também consultas enfileiradas. Com essa alteração, agora é possível ter mais consultas DML em estado ativo do que antes.
Para obter informações sobre as cotas de serviço do Athena, consulte Service Quotas. Para as cotas de consultas na região onde você usa o Athena, consulte Endpoints e cotas do Amazon Athena na Referência geral da AWS.
Para monitorar o uso da cota, é possível usar métricas de uso do CloudWatch. O Athena publica a métrica ActiveQueryCount a seguir no namespace AWS/Usage. Para obter mais informações, consulte Monitorar métricas de uso do Athena com o CloudWatch.
Depois de revisar o uso, será possível usar o console do Service Quotas
14 de fevereiro de 2022
Publicado em 14/02/2022
Este lançamento inclui o subcampo ErrorType para o objeto de resposta AthenaError na alçai de API GetQueryExecution do Athena.
Enquanto o campo ErrorCategory existente indica a origem geral de uma consulta com falha (sistema, usuário ou outro), o novo campo ErrorType fornece informações mais detalhadas sobre o erro ocorrido. Combine as informações de ambos os campos para obter insights sobre as causas da falha da consulta.
Para obter mais informações, consulte Catálogo de erros do Athena.
9 de fevereiro de 2022
Publicado em 09/02/2022
O console antigo do Athena não está mais disponível O novo console do Athena suporta todos os recursos do console anterior, mas com uma interface moderna e fácil de usar, e inclui novos recursos que melhoram a experiência de desenvolvimento de consultas, análise de dados e gerenciamento de uso. Para usar o novo console do Athena, acesse https://console.aws.amazon.com/athena/
8 de fevereiro de 2022
Publicado em 08/02/2022
Proprietário do bucket esperado: como uma medida de segurança adicional, agora você tem a opção de especificar o ID da Conta da AWS que você espera ser a proprietária do bucket do local de saída dos resultados da consulta no Athena. Se o ID da conta do proprietário do bucket dos resultados da consulta não corresponder ao ID de conta que você especificar, as tentativas de enviar a saída para o bucket falharão com o erro de permissões do Amazon S3. Você pode fazer essa configuração no nível de cliente ou de grupo de trabalho.
Para obter mais informações, consulte Especificar um local para resultados de consultas.
28 de janeiro de 2022
Publicado em 28/01/2022
O Athena anuncia aprimoramentos a seguir nos recursos do mecanismo.
-
Apache Hudi: agora as consultas de snapshots em tabelas Hudi Merge on Read (MoR) podem ler colunas de timestamp com o tipo de dados
INT64. -
Consultas UNION: melhoria de performance e redução de dados para determinadas consultas
UNIONque verificam a mesma tabela várias vezes. -
Consultas de disjunção: melhoria de performance para consultas que têm apenas valores de disjunção para cada coluna de partição no filtro.
-
Melhorias na projeção de partições
-
Vários valores de disjunção agora são permitidos na condição de filtro para colunas do tipo
injected. Para obter mais informações, consulte Tipo injected. -
Melhoria de performance para colunas de tipos baseados em strings, como
CHARouVARCHARque têm apenas valores de disjunção no filtro.
-
13 de janeiro de 2022
Publicado em 13/01/2022
Lançamento dos drivers JDBC 2.0.27 e ODBC 1.1.15 para o Athena.
O driver JDBC 2.0.27 inclui as seguintes alterações:
-
O driver foi atualizado para recuperar catálogos externos.
-
O número da versão do driver estendido agora está incluído na string
user-agentcomo parte da chamada de API do Athena.
O driver ODBC 1.1.15 inclui as seguintes alterações:
-
Corrige um problema com as segundas chamadas para
SQLParamData().
Para obter mais informações sobre essas alterações e baixar os novos drivers, as notas de release e a documentação, consulte Conectar ao Amazon Athena com JDBC e Conectar ao Amazon Athena com ODBC.
Notas de release do Athena para 2021
26 de novembro de 2021
Publicado em 26/11/2021
O Athena anuncia a versão de pré-lançamento público das transações ACID do Athena, que adicionam operações de gravação, exclusão, atualização e viagem no tempo à SQL Data Manipulation Language (DML) do Athena. As transações ACID do Athena permitem que vários usuários simultâneos façam modificações confiáveis nos dados do Amazon S3 no nível da linha. Baseadas no formato de tabela Apache Iceberg
As transações do ACID do Athena e a sintaxe SQL familiar simplificam as atualizações de dados empresariais e regulamentares. Por exemplo, para responder a uma solicitação de eliminação de dados, você pode executar uma operação DELETE em SQL. Para fazer correções manuais em registros, você pode usar uma única instrução UPDATE. Para recuperar dados que foram excluídos recentemente, você pode emitir consultas de viagem no tempo usando uma instrução SELECT. As transações do Athena estão disponíveis por meio do console do Athena, de operações de API e dos drivers ODBC e JDBC.
Para obter mais informações, consulte Usar transações ACID do Athena.
24 de novembro de 2021
Publicado em 24/11/2021
Athena anuncia suporte a leitura e gravação de dados nos formatos ORG, Parquet e textfile compactados como ZStandard
Para obter mais informações sobre compactação de dados no Athena, consulte Usar compactação no Athena.
22 de novembro de 2021
Publicado em 22/11/2021
Agora é possível gerenciar fluxos de trabalho do AWS Step Functions no console do Amazon Athena, facilitando a criação de pipelines de processamento de dados escaláveis, a execução de consultas com base em uma lógica de negócios personalizada, a automatização de tarefas administrativas e de alertas, e muito mais.
O Step Functions agora é integrado no console atualizado do Athena, e você pode usá-lo para visualizar um diagrama de fluxo de trabalho interativo de suas máquinas de estado que invocam o Athena. Para começar, selecione Workflows (Fluxos de trabalho) No painel de navegação esquerdo. Se você tiver máquinas de estado existentes com consultas do Athena, selecione uma máquina de estado para exibir um diagrama interativo do fluxo de trabalho. Se você nunca usou Step Functions antes, pode começar iniciando um projeto de amostra no console do Athena e personalizando-o para atender aos seus casos de uso.
Para obter mais informações, consulte Criar e orquestrar pipelines ETL usando o Amazon Athena e o AWS Step Functions
18 de novembro de 2021
Publicado em 18/11/2021
O Athena anuncia novos recursos e aperfeiçoamentos.
-
Suporte a spill-to-disk para consultas de agregação que contêm
DISTINCT,ORDER BYou ambos, como no seguinte exemplo:SELECT array_agg(orderstatus ORDER BY orderstatus) FROM orders GROUP BY orderpriority, custkey -
Problemas de tratamento de memória resolvidos para consultas que usam
DISTINCT. Para evitar mensagens de erro comoConsultar recursos esgotados nesse fator de escalaquando você usas consultasDISTINCT, escolha colunas que tenham uma baixa cardinalidade paraDISTINCTou reduza o tamanho dos dados da consulta. -
Em consultas
SELECT COUNT(*)que não especificam uma coluna, melhor performance e uso de memória, mantendo apenas a contagem, sem buffer de linhas. -
Introduzidas as funções de string a seguir.
-
translate(source, from, to): retorna a stringsourcecom os caracteres encontrados na stringfromsubstituídos pelos caracteres correspondentes da stringto. Se a stringfromcontiver duplicatas, somente a primeira será usada. Se o caracteresourcenão ocorrer na stringfrom, o caracteresourceserá copiado sem tradução. Se o índice do caractere correspondente na stringfromfor maior do que o comprimento da stringto, o caractere será omitido da string resultante. -
concat_ws(string0, array(varchar)): retorna a concatenação de elementos na matriz usandostring0como separador. Sestring0for null, o valor retornado será nulo. Todos os valores null na matriz são ignorados.
-
-
Corrigido um bug em que as consultas falhavam ao tentar acessar um subcampo ausente em um
struct. As consultas agora retornam null para o subcampo ausente. -
Corrigido um problema de hashing inconsistente para o tipo de dados decimal.
-
Correção de um problema que causava a exaustão de recursos quando havia muitas colunas em uma partição.
17 de novembro de 2021
Publicado em 17/11/2021
O Amazon Athena
Ao consultar tabelas particionadas, o Athena recupera e filtra as partições de tabela disponíveis para o subconjunto relevante para a sua consulta. À medida que novos dados e partições são adicionados, mais tempo é necessário para processar as partições e o runtime da consulta pode aumentar. Para otimizar o processamento de partições e melhorar a performance das consultas em tabelas altamente particionadas, o Athena agora suporta os índices de partição do AWS Glue.
Para obter mais informações, consulte Otimizar consultas com indexação e filtragem de partições do AWS Glue.
16 de novembro de 2021
Publicado em 16/11/2021
O novo console aprimorado do Amazon Athena
-
Reorganizar, navegar até ou fechar várias guias de consulta a partir de uma barra de guias de consulta redesenhada.
-
Ler e editar consultas com mais facilidade com formatação SQL e texto aprimorada.
-
Copiar os resultados da consulta para a área de transferência, além de baixar o conjunto completo de resultados.
-
Classificar seu histórico de consultas, consultas salvas e grupos de trabalho, e escolher quais as colunas a serem exibidas ou ocultadas.
-
Usar uma interface simplificada para configurar origens de dados e grupos de trabalho em menos cliques.
-
Definir preferências para exibir resultados da consulta, histórico de consultas, quebra de linha e muito mais.
-
Aumentar sua produtividade com atalhos de teclado novos e aprimorados e documentação de produto incorporada.
Com o anúncio de hoje, o console reformulado
Se desejar, você pode usar o console anterior fazendo login em seu Conta da AWS, escolhendo o Amazon Athena e desmarcando New Athena experience (Nova experiência do Athena) no painel de navegação à esquerda.
12 de novembro de 2021
Publicado em 12/11/2021
Agora você pode usar o Amazon Athena para executar consultas federadas em origens dos dados localizadas em um conta da AWS que não seja a sua. Até hoje, consultar esses dados exigia que a origem dos dados e seu conector usassem a mesma Conta da AWS que o usuário que consultou os dados.
Como administrador de dados, você pode habilitar consultas federadas entre contas compartilhando seu conector de dados com uma conta de analista de dados. Como analista de dados, você pode adicionar um conector de dados que um administrador de dados compartilhou com você à sua conta. As alterações de configuração no conector na conta de origem se aplicam automaticamente ao conector compartilhado.
Para obter informações sobre consultas federadas, consulte Habilitar consultas federadas entre contas. Para saber mais sobre como consultar fontes federadas, consulte Usar a consulta federada do Amazon Athena e Executar consultas federadas.
2 de novembro de 2021
Publicado em 02/11/2021
Agora é possível usar a instrução EXPLAIN ANALYZE no Athena para visualizar o plano de execução e o custo de cada operação das consultas SQL.
Para obter mais informações, consulte Usar EXPLAIN e EXPLAIN ANALYZE no Athena.
29 de outubro de 2021
Publicado em 29/10/2021
Athena lança os drivers JDBC 2.0.25 e ODBC 1.1.13, e anuncia recursos e aprimoramentos.
Drivers JDBC e ODBC
Lançamento dos drivers JDBC 2.0.25 e ODBC 1.1.13 para o Athena. Ambos os drivers oferecem suporte a autenticação multifator SAML do navegador, que pode ser configurada para funcionar com qualquer provedor de SAML 2.0.
O driver JDBC 2.0.25 inclui as seguintes alterações:
-
Suporte a autenticação SAML do navegador. O driver inclui um plug-in SAML de navegador que pode ser configurado para funcionar com qualquer provedor de SAML 2.0.
-
Suporte a chamadas de API do AWS Glue. Você pode usar o parâmetro
GlueEndpointOverridepara substituir o endpoint AWS Glue. -
Alterado o caminho da classe
com.simba.athena.amazonawsparacom.amazonaws.
O driver ODBC 1.1.13 inclui as seguintes alterações:
-
Suporte a autenticação SAML do navegador. O driver inclui um plug-in SAML de navegador que pode ser configurado para funcionar com qualquer provedor de SAML 2.0. Para obter um exemplo de como usar o plugin SAML de navegador com o driver ODBC, consulte Configurar Single Sign-On com uso de ODBC, SAML 2.0 e o provedor de identidade Okta.
-
Agora você pode configurar a duração da sessão da função quando usa ADFS, Azure AD ou Browser Azure AD para autenticação.
Para obter mais informações sobre essas e outras alterações e baixar os novos drivers, as notas de release e a documentação, consulte Conectar ao Amazon Athena com JDBC e Conectar ao Amazon Athena com ODBC.
Recursos e melhorias
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
Uma nova regra de otimização foi introduzida para evitar varreduras de tabelas duplicadas em determinados casos.
4 de outubro de 2021
Publicado em 04/10/2021
O Athena anuncia novos recursos e aperfeiçoamentos a seguir.
-
SQL OFFSET: a cláusula SQL
OFFSETagora é suportada nas instruçõesSELECT. Para obter mais informações, consulte SELECT. -
Métricas de uso do CloudWatch: o Athena agora publica a métrica
ActiveQueryCountno namespaceAWS/Usage. Para obter mais informações, consulte Monitorar métricas de uso do Athena com o CloudWatch. -
Planejamento de consulta: corrigido um bug que, em casos raros, poderia causar o esgotamento dos tempos limites de planejamento de consulta.
16 de setembro de 2021
Publicado em 16/07/2021
O Athena anuncia os novos recursos e aperfeiçoamentos a seguir.
Recursos
-
Ocorreu adição de suporte para especificar os arquivos de texto e a compactação JSON em CTAS usando a propriedade de tabela
write_compression. Também é possível especificar a propriedadewrite_compressionCTAS para os formatos Parquet e ORC. Para obter mais informações, consulte Propriedades da tabela CTAS. -
O formato de compactação BZIP2 passou a ser compatível com a gravação de arquivos de texto e arquivos JSON. Para obter mais informações sobre os formatos de compactação no Athena, consulte Usar compactação no Athena.
Melhorias
-
Corrigido um bug no qual as informações de identidade não eram enviadas para a função UDF do Lambda.
-
Corrigido um problema de pushdown de predicado com condições de filtro de disjunção.
-
Corrigido um problema de hashing para tipos decimais.
-
Corrigido um problema de coleta de estatísticas desnecessárias.
-
Removida uma mensagem de erro inconsistente.
-
Melhor performance de junção de transmissão aplicando redução dinâmica de partição no nó de processamento.
-
Para consultas federadas:
-
Configuração alterada para reduzir a ocorrência de erros
CONSTRAINT_VIOLATIONem consultas federadas.
-
15 de setembro de 2021
Publicado em 15/09/2021
Agora você pode usar um console do Amazon Athena redesenhado (versão de demonstração). Um novo driver JDBC do Athena foi lançado.
Versão de demonstração do console do Athena
Agora é possível usar um console do Amazon Athena
Para alternar para o novo console
Comece a usar o novo console
Driver JDBC 2.0.24 do Athena
O Athena anuncia a disponibilidade do driver JDBC versão 2.0.24 para o Athena. Esta versão atualiza o suporte a proxy para todos os provedores de credenciais. O driver agora oferece suporte à autenticação de proxy para todos os hosts que não são suportados pela propriedade de conexão NonProxyHosts.
Para conveniência, esta versão inclui downloads do driver JDBC com e sem o SDK do AWS. Esta versão do driver JDBC permite que você tenha o AWS-SDK e o driver JDBC do Athena incorporados no projeto.
Para obter mais informações e baixar o novo driver, as notas de release e a documentação, consulte Conectar ao Amazon Athena com JDBC.
31 de agosto de 2021
Publicado em 31/08/2021
Athena anuncia as seguintes melhorias de recursos e correções de bugs.
-
Melhorias na federação do Athena: o Athena incluiu suporte a tipos de mapas e aprimorou o suporte a tipos complexos como parte do Athena Query Federation SDK
. Esta versão também inclui alguns aprimoramentos de memória e otimizações de performance. -
Novas categorias de erro: as categorias de erro
USEReSYSTEMforam incluídas nas mensagens de erro. Essas categorias ajudam a distinguir entre os erros que você mesmo pode corrigir (USER) e os erros podem precisar da ajuda do suporte do Athena (SYSTEM). -
Mensagens de erro de consulta federada: as categorizações
USER_ERRORforam atualizadas para erros relacionados à consulta federada. -
JOIN: os bugs relacionados a vazamento em disco (spill-to-disk) e os problemas de memória foram corrigidos para melhorar a performance e reduzir erros de memória nas operações
JOIN.
12 de agosto de 2021
Publicado em 12/08/2021
Lançamento do driver ODBC 1.1.12 para Athena. Esta versão corrige problemas relacionados a SQLPrepare(), SQLGetInfo() e EndpointOverride.
Para baixar o novo driver, as notas de release e a documentação, consulte Conectar ao Amazon Athena com ODBC.
6 de agosto de 2021
Publicado em 06/08/2021
O Amazon Athena anuncia a disponibilidade do Athena e de seus recursos
Esta versão expande a disponibilidade do Athena nas regiões Ásia-Pacífico para incluir Ásia-Pacífico (Hong Kong), Ásia-Pacífico (Mumbai), Ásia-Pacífico (Osaka), Ásia-Pacífico (Seul), Ásia-Pacífico (Singapura), Ásia-Pacífico (Sydney) e Ásia-Pacífico (Tóquio). Para ver uma lista completa dos Serviços da AWS disponíveis nessas e em outras regiões, consulte a Lista de serviços por Região da AWS
5 de agosto de 2021
Publicado em 05/08/2021
Você pode usar a instrução UNLOAD para gravar a saída de uma consulta SELECT nos formatos PARQUET, ORC, AVRO e JSON.
Para obter mais informações, consulte UNLOAD.
30 de julho de 2021
Publicado em 30/07/2021
Athena anuncia as seguintes melhorias de recursos e correções de bugs.
-
Filtragem dinâmica e redução de partições: as melhorias aumentam a performance e reduzem a quantidade de dados verificados em determinadas consultas, como no exemplo a seguir.
Este exemplo assume que
Table_Bé uma tabela não particionada com tamanhos de arquivos que somam menos de 20 MB. Para consultas como esta, menos dados são lidos emTable_Ae a consulta é concluída com mais rapidez.SELECT * FROM Table_A JOIN Table_B ON Table_A.date = Table_B.date WHERE Table_B.column_A = "value" -
ORDER BY com LIMIT, DISTINCT com LIMIT: melhorias na performance de consultas que usam
ORDER BYouDISTINCTseguido de uma cláusulaLIMIT. -
Arquivos do Amazon Glacier Deep Archive: quando o Athena consulta uma tabela que contém uma mistura de arquivos do Amazon Glacier Deep Archive com arquivos que não são do Amazon Glacier Deep Archive, o Athena agora ignora os arquivos do Amazon Glacier Deep Archive para você. Antes, era necessário mover manualmente esses arquivos do local da consulta para evitar falha. Se quiser usar o Athena para consultar objetos no armazenamento Amazon Glacier Deep Archive, você deverá restaurá-los. Para obter mais informações, consulte Restaurar objetos arquivados no Manual do usuário do Amazon S3.
-
Um bug foi corrigido em que arquivos vazios criados pela propriedade de tabela
bucketed_byde CTAS não eram criptografados corretamente.
21 de julho de 2021
Publicado em 21/07/2021
Com o lançamento de julho de 2021 do Microsoft Power BI Desktop
Como o conector usa o nome da origem dos dados ODBC existente (DSN) para se conectar e executar consultas no Athena, ele requer o driver ODBC do Athena. Para baixar o driver ODBC mais recente, consulte Conectar ao Amazon Athena com ODBC.
Para obter mais informações, consulte Usar o conector do Power BI para Amazon Athena.
16 de julho de 2021
Publicado em 16/07/2021
Amazon Athena atualizou sua integração com o Apache Hudi. O Hudi é um framework de gerenciamento de dados de código aberto que simplifica o processamento incremental de dados em data lakes do Amazon S3. A integração atualizada permite que você use o Athena para consultar tabelas do Hudi 0.8.0 gerenciadas pelo Amazon EMR, Apache Spark, Apache Hive ou outros serviços compatíveis. Além disso, o Athena agora inclui dois recursos adicionais: consultas de snapshot em tabelas Merge-on-Read (MoR – Mesclar na leitura) e suporte para leitura em tabelas de bootstrap.
O Apache Hudi oferece processamento de dados no nível do registro que pode ajudar você a simplificar o desenvolvimento de pipelines de Change Data Capture (CDC – Captura de dados de alteração), cumprir as atualizações e exclusões orientadas pelo RGPD e gerenciar melhor os dados de streaming de sensores ou dispositivos que exigem inserção de dados e atualizações de eventos. A versão 0.8.0 facilita a migração de tabelas grandes do Parquet para o Hudi sem copiar os dados para que você possa consultá-las e analisá-las usando o Athena. Você pode usar o novo suporte do Athena para consultas de snapshot para obter visualizações quase em tempo real das suas atualizações de tabela de transmissão.
Para saber mais como usar o Hudi com o Athena, consulte Consultar conjuntos de dados do Apache Hudi.
8 de julho de 2021
Publicado em 08/07/2021
Lançamento do driver ODBC 1.1.11 para Athena. O driver ODBC agora pode autenticar a conexão usando um JSON Web Token (JWT). No Linux, o valor padrão da propriedade Workgroup (Grupo de trabalho) foi definido como Primary (Primário).
Para obter mais informações e baixar o novo driver, as notas de release e a documentação, consulte Conectar ao Amazon Athena com ODBC.
1.º de julho de 2021
Publicado em 01/07/2021
Em 1º de julho de 2021, o processamento especial dos grupos de trabalho de previsualização foi encerrado. Os grupos de trabalho AmazonAthenaPreviewFunctionality mantêm o nome, mas não têm mais um status especial. Você pode continuar usando os grupos de trabalho AmazonAthenaPreviewFunctionality para visualizar, modificar, organizar e executar consultas. No entanto, as consultas que usam recursos que antes estavam em previsualização agora estão sujeitas aos termos e condições de cobrança padrão do Athena. Para obter informações, consulte Preços do Amazon Athena
23 de junho de 2021
Publicado em 23/06/2021
Lançamento dos drivers JDBC 2.0.23 e ODBC 1.1.10 para o Athena. Os dois drivers oferecem melhor performance de leitura e aceitam as instruções EXPLAIN e as consultas parametrizadas.
EXPLAINAs instruções mostram o plano de execução lógico ou distribuído de uma consulta SQL. As consultas parametrizadas permitem que a mesma consulta seja usada várias vezes com valores diferentes fornecidos no runtime.
A versão do JDBC também inclui suporte para os Serviços de Federação do Active Directory 2019 e uma opção de substituição de endpoint personalizada para AWS STS. A versão do ODBC corrige um problema com as credenciais de perfil do IAM.
Para obter mais informações e baixar os novos drivers, as notas de release e a documentação, consulte Conectar ao Amazon Athena com JDBC e Conectar ao Amazon Athena com ODBC.
12 de maio de 2021
Publicado em 12/05/2021
Agora você pode usar o Amazon Athena para registrar um catálogo do AWS Glue de uma conta diferente da sua. Depois de configurar as permissões do IAM necessárias para o AWS Glue, você poderá usar o Athena para executar consultas entre contas.
Para obter mais informações, consulte Registrar um catálogo de dados de outra conta e Configurar o acesso entre contas aos catálogos de dados do AWS Glue.
10 de maio de 2021
Publicado em 10/05/2021
Lançamento do driver ODBC versão 1.1.9.1001 para o Athena. Esta versão corrige um problema com o tipo de autenticação BrowserAzureAD ao usar o Azure Active Directory (AD).
Para baixar os novos drivers, as notas de release e a documentação, consulte Conectar ao Amazon Athena com ODBC.
5 de maio de 2021
Publicado em 05/05/2021
Agora você pode usar o conector do Vertica para Amazon Athena em consultas federadas para consultar origens de dados do Vertica usando o Athena. Por exemplo, você pode executar consultas analíticas em um data warehouse no Vertica e um data lake no Amazon S3.
Para implantar o conector do Vertica para Athena, visite a página AthenaVerticaConnector
O conector do Vertica para Amazon Athena expõe várias opções de configuração por meio das variáveis de ambiente do Lambda. Para obter informações sobre as opções de configuração, os parâmetros, as strings de conexão, a implantação e as limitações, consulte Conector do Amazon Athena para o Vertica.
Para obter informações detalhadas sobre como usar o conector do Vertica, veja Consultar uma origem dos dados do Vertica no Amazon Athena usando o Athena Federated Query SDK
30 de abril de 2021
Publicado em 30/04/2021
Lançamento dos drivers JDBC 2.0.21 e ODBC 1.1.9 para o Athena. As duas versões aceitam a autenticação SAML com o Azure Active Directory (AD) e a autenticação SAML com o PingFederate. A versão do JDBC também aceita consultas parametrizadas. Para obter informações sobre consultas parametrizadas no Athena, leia Usar consultas parametrizadas.
Para baixar os novos drivers, as notas de release e a documentação, consulte Conectar ao Amazon Athena com JDBC e Conectar ao Amazon Athena com ODBC.
29 de abril de 2021
Publicado em 29/04/2021
O Amazon Athena anuncia a disponibilidade do mecanismo do Athena versão 2 nas regiões China (Pequim) e China (Ningxia).
26 de abril de 2021
Publicado em 26/04/2021
As funções de valor de janela no mecanismo do Athena versão 2 agora aceitam IGNORE NULLS e RESPECT NULLS.
Para obter mais informações, consulte Funções de valor
21 de abril de 2021
Publicado em 21/04/2021
O Amazon Athena anuncia a disponibilidade do mecanismo do Athena versão 2 nas regiões Europa (Milão) e África (Cidade do Cabo).
5 de abril de 2021
Publicado em 05/04/2021
Instrução EXPLAIN
Agora é possível usar a instrução EXPLAIN no Athena para visualizar o plano de execução das suas consultas SQL.
Para obter mais informações, consulte Usar EXPLAIN e EXPLAIN ANALYZE no Athena e Noções básicas dos resultados da instrução EXPLAIN do Athena.
Modelos de machine learning do SageMaker AI em consultas SQL
Agora, a inferência do modelo de machine learning com do Amazon SageMaker AI está disponível ao público geral no Amazon Athena. Use os modelos de machine learning em consultas SQL para simplificar tarefas complexas, como detecção de anomalias, análise de coorte de clientes e previsões de série temporal, invocando uma função em uma consulta SQL.
Para obter mais informações, consulte Usar Machine Learning (ML) com o Amazon Athena.
Funções definidas pelo usuário (UDFs)
As funções definidas pelo usuário (UDFs) agora estão em disponibilidade geral para o Athena. Use as UDFs para aproveitar as funções personalizadas que processam registros ou grupos de registros em uma única consulta SQL.
Para obter mais informações, consulte Consultar com funções definidas pelo usuário.
30 de março de 2021
Publicado em 30/03/2021
O Amazon Athena anuncia a disponibilidade do mecanismo do Athena versão 2 nas regiões Ásia-Pacífico (Hong Kong) e Oriente Médio (Bahrein).
25 de março de 2021
Publicado em 25/03/2021
O Amazon Athena anuncia a disponibilidade do mecanismo do Athena versão 2 na região Europa (Estocolmo).
5 de março de 2021
Publicado em 05/03/2021
O Amazon Athena anuncia a disponibilidade do mecanismo do Athena versão 2 nas regiões Canadá (Central), Europa (Frankfurt) e América do Sul (São Paulo).
25 de fevereiro de 2021
Publicado em 25/02/2021
O Amazon Athena anuncia a disponibilidade geral do mecanismo do Athena versão 2 nas regiões Ásia-Pacífico (Seul), Ásia-Pacífico (Singapura), Ásia-Pacífico (Sydney), Europa (Londres) e Europa (Paris).
Notas de release do Athena para 2020
16 de dezembro de 2020
Publicado em 16/12/2020
O Amazon Athena anuncia a disponibilidade do mecanismo do Athena versão 2, da consulta federada do Athena e do AWS PrivateLink em mais regiões.
Mecanismo do Athena versão 2 e consulta federada do Athena
O Amazon Athena anuncia a disponibilidade geral do mecanismo do Athena versão 2 e da consulta federada do Athena nas regiões Ásia-Pacífico (Mumbai), Ásia-Pacífico (Tóquio), Europa (Irlanda) e Oeste dos EUA (N. da Califórnia). O mecanismo do Athena versão 2 e as consultas federadas já estão disponíveis nas regiões Leste dos EUA (Norte da Virgínia), Leste dos EUA (Ohio) e Oeste dos EUA (Oregon).
AWS PrivateLink
AWS PrivateLinkO para o Athena agora está disponível na região Europa (Estocolmo). Para obter informações sobre o AWS PrivateLink para o Athena, consulte Conectar-se ao Amazon Athena usando um endpoint da VPC de interface.
24 de novembro de 2020
Publicado em 24/11/2020
Lançamento dos drivers JDBC 2.0.16 e ODBC 1.1.6 para o Athena. Essas versões aceitam a Multifactor Authentication (MFA – Autenticação multifator) do Okta Verify no nível da conta. Você também pode usar a MFA do Okta para configurar a autenticação SMS e do Google Authenticator como fatores.
Para baixar os novos drivers, as notas de release e a documentação, consulte Conectar ao Amazon Athena com JDBC e Conectar ao Amazon Athena com ODBC.
11 de novembro de 2020
Publicado em 11/11/2020
O Amazon Athena anuncia a disponibilidade geral nas regiões Leste dos EUA (Norte da Virgínia), Leste dos EUA (Ohio) e Oeste dos EUA (Oregon) para o mecanismo do Athena versão 2 e as consultas federadas.
Mecanismo do Athena versão 2
O Amazon Athena anuncia a disponibilidade geral de uma nova versão do mecanismo de consulta, o mecanismo do Athena versão 2, nas regiões Leste dos EUA (Norte da Virgínia), Leste dos EUA (Ohio) e Oeste dos EUA (Oregon).
O mecanismo do Athena versão 2 inclui melhorias na performance e novas funcionalidades de recursos, como suporte à evolução de esquema para dados no formato Parquet, funções geoespaciais adicionais, suporte para leitura de esquema aninhado para reduzir custos e melhorias na performance das operações JOIN e AGGREGATE.
-
Para obter informações sobre como fazer upgrade, consulte Alterar versões do mecanismo do Athena.
-
Para obter informações sobre teste de consultas, consulte Testar consultas antes da atualização da versão do mecanismo.
Consultas SQL federadas
Agora é possível usar a consulta federada do Athena nas regiões Leste dos EUA (Norte da Virgínia), Leste dos EUA (Ohio) e Oeste dos EUA (Oregon) sem usar o grupo de trabalho AmazonAthenaPreviewFunctionality.
Use consultas SQL federadas para executar consultas SQL em fontes de dados relacionais, não relacionais, de objeto e personalizadas. Graças às consultas federadas, é possível enviar uma única consulta SQL que verifica dados de várias fontes em execução on-premises ou hospedadas na nuvem.
A execução de analytics em dados distribuídos entre aplicativos pode ser complexa e demorada pelos seguintes motivos:
-
Os dados necessários para realizar analytics costumam estar distribuídos em armazenamentos de dados relacionais, documentais, gráficos, na memória, de busca, de objetos, com séries temporais, com valores-chave e livros contábeis.
-
Para analisar dados de todas essas fontes, são criados pipelines complexos para extrair, transformar e carregar dados em um data warehouse, para que eles possam ser consultados.
-
Para acessar dados de várias fontes, é necessário aprender novas linguagens de programação e construções de acesso de dados.
As consultas SQL federadas no Athena eliminam essa complexidade porque permitem que os usuários consultem os dados no local onde quer que eles residam. Os analistas podem usar as construções SQL conhecidas para fazer JOIN dos dados em várias origens para análises rápidas e armazenar os resultados no Amazon S3 para uso futuro.
Conectores de fontes de dados
Para processar as consultas federadas, o Athena usa seus conectores de origem dos dados executados no AWS Lambda
Conectores de fontes de dados personalizados
Com o uso do Athena Query Federation SDK
Próximas etapas
-
Para saber mais sobre o recurso de consulta federada, acesse Usar a consulta federada do Amazon Athena.
-
Para começar a usar um conector existente, consulte Criar uma conexão de fonte de dados.
-
Para saber como criar o próprio conector de origem dos dados usando o Athena Query Federation SDK, consulte Exemplo de conector do Athena
no GitHub.
22 de outubro de 2020
Publicado em 22/10/2020
Agora é possível chamar o Athena com o AWS Step Functions. O AWS Step Functions pode controlar determinados Serviços da AWS diretamente no Amazon States Language. Você pode usar o Step Functions com o Athena para iniciar e interromper a execução da consulta, acessar os resultados da consulta, executar consultas de dados específicas ou agendadas e recuperar os resultados de data lakes no Amazon S3.
Para obter mais informações, consulte Chamar o Athena com o Step Functions no Guia do desenvolvedor do AWS Step Functions.
29 de julho de 2020
Publicado em 29/07/2020
Lançamento do driver JDBC versão 2.0.13. Essa versão permite usar vários catálogos de dados registrados no Athena, o serviço Okta para autenticação e conexões com endpoints da VPC.
Para baixar e usar a nova versão do driver, consulte Conectar ao Amazon Athena com JDBC.
9 de julho de 2020
Publicado em 09/07/2020
O Amazon Athena inclui suporte para consultar conjuntos de dados compactados do Hudi e o recurso AWS::Athena::DataCatalog do CloudFormation para criar, atualizar ou excluir catálogos de dados registrados no Athena.
Consultar conjuntos de dados do Apache Hudi
O Apache Hudi é um framework de gerenciamento de dados de código aberto que simplifica o processamento incremental de dados. O Amazon Athena agora permite a consulta da visualização otimizada para leitura de um conjunto de dados do Apache Hudi em seu data lake baseado no Amazon S3.
Para obter mais informações, consulte Consultar conjuntos de dados do Apache Hudi.
CloudFormationRecurso de catálogo de dados do
Para usar o recurso de consulta federada do Amazon Athena para consultar qualquer origem dos dados, você deve primeiro registrar seu catálogo de dados no Athena. Agora é possível usar o recurso AWS::Athena::DataCatalog do CloudFormation para criar, atualizar ou excluir catálogos de dados registrados no Athena.
Para obter mais informações, consulte AWS::Athena::DataCatalog no Manual do usuário do CloudFormation.
1 de junho de 2020
Publicado em 01-06-2020
Usar o metastore do Apache Hive como um metacatálogo com o Amazon Athena
Agora é possível conectar o Athena a um ou mais metastores do Apache Hive, além do AWS Glue Data Catalog com o Athena.
Para se conectar a um metastore do Hive auto-hospedado, você precisa de um conector de metastore do Athena Hive. O Athena inclui um conector de implementação de referência que você pode usar. O conector é executado na sua conta como uma função do AWS Lambda.
Para obter mais informações, consulte Usar um metastore externa do Hive.
21 de maio de 2020
Publicado em 21/05/2020
O Amazon Athena oferece suporte para projeção de partições. Use a projeção de partições para acelerar o processamento de consultas de tabelas altamente particionadas e automatizar o gerenciamento de partições. Para obter mais informações, consulte Usar projeção de partições com o Amazon Athena.
1 de abril de 2020
Publicado em 01-04-2020
Além da região Leste dos EUA (Norte da Virgínia), os recursos de consulta federada, funções definidas pelo usuário (UDFs), inferência de machine learning e metastore externo do Hive do Amazon Athena agora estão disponíveis em versão prévia nas regiões Ásia-Pacífico (Mumbai), Europa (Irlanda) e Oeste dos EUA (Oregon).
11 de março de 2020
Publicado em 11-03-2020
O Amazon Athena agora publica os eventos do Amazon EventBridge para as transições de estado das consultas. Quando uma consulta faz a transição entre estados, por exemplo, de Em execução para um estado terminal, como Com êxito ou Cancelada, o Athena publica um evento de alteração de estado da consulta no EventBridge. O evento contém informações sobre a transição do estado da consulta. Para obter mais informações, consulte Monitorar eventos de consulta do Athena com o EventBridge.
6 de março de 2020
Publicado em 06-03-2020
Agora você pode criar e atualizar grupos de trabalho do Amazon Athena usando o recurso AWS::Athena::WorkGroup do CloudFormation. Para obter mais informações, consulte AWS::Athena::WorkGroup no Guia do usuário do CloudFormation.
Notas de release do Athena para 2019
26 de novembro de 2019
Publicado em 17-12-2019
O Amazon Athena inclui suporte para executar consultas SQL em origens de dados relacionais, não relacionais, de objeto e personalizadas, invocar modelos de machine learning em consultas SQL e funções definidas pelo usuário (UDFs) (previsualização), usar o metastore do Apache Hive como um catálogo de metadados com o Amazon Athena (previsualização) e mais quatro métricas relacionadas a consulta.
Consultas SQL federadas
Use consultas SQL federadas para executar consultas SQL em fontes de dados relacionais, não relacionais, de objeto e personalizadas.
Agora é possível usar a consulta federada do Athena para verificar os dados armazenados em origens de dados relacionais, não relacionais, de objeto e personalizadas. Graças às consultas federadas, é possível enviar uma única consulta SQL que verifica dados de várias fontes em execução on-premises ou hospedadas na nuvem.
A execução de analytics em dados distribuídos entre aplicativos pode ser complexa e demorada pelos seguintes motivos:
-
Os dados necessários para realizar analytics costumam estar distribuídos em armazenamentos de dados relacionais, documentais, gráficos, na memória, de busca, de objetos, com séries temporais, com valores-chave e livros contábeis.
-
Para analisar dados de todas essas fontes, são criados pipelines complexos para extrair, transformar e carregar dados em um data warehouse, para que eles possam ser consultados.
-
Para acessar dados de várias fontes, é necessário aprender novas linguagens de programação e construções de acesso de dados.
As consultas SQL federadas no Athena eliminam essa complexidade porque permitem que os usuários consultem os dados no local onde quer que eles residam. Os analistas podem usar as construções SQL conhecidas para fazer JOIN dos dados em várias origens para análises rápidas e armazenar os resultados no Amazon S3 para uso futuro.
Conectores de fontes de dados
O Athena processa as consultas federadas usando seus conectores de origem dos dados executados em AWS Lambda
Conectores de fontes de dados personalizados
Com o uso do Athena Query Federation SDK
Disponibilidade de visualização
A consulta federada do Athena está disponível em previsualização na região Leste dos EUA (Norte da Virgínia).
Próximas etapas
-
Para iniciar sua previsualização, siga as instruções nas Perguntas frequentes sobre recursos em previsualização do Athena
. -
Para saber mais sobre o recurso de consulta federada, veja Usar a consulta federada do Amazon Athena (previsualização).
-
Para começar a usar um conector existente, consulte Criar uma conexão de fonte de dados.
-
Para saber como criar o próprio conector de origem dos dados usando o Athena Query Federation SDK, consulte Exemplo de conector do Athena
no GitHub.
Chamar modelos de machine learning em consultas SQL
Agora é possível invocar modelos de machine learning para inferência diretamente das suas consultas do Athena. A capacidade de usar modelos de machine learning em consultas SQL simplifica tarefas complexas como detecção de anomalias, análise de coorte de clientes e previsões de vendas, para que sejam tão simples quanto invocar uma função em uma consulta SQL.
Modelos de ML
É possível usar mais de dez algoritmos de machine learning incorporados disponíveis no Amazon SageMaker
Disponibilidade de visualização
A funcionalidade de ML do Athena está disponível hoje em pré-visualização na região Leste dos EUA (Norte da Virgínia).
Próximas etapas
-
Para iniciar sua previsualização, siga as instruções nas Perguntas frequentes sobre recursos em previsualização do Athena
. -
Para saber mais sobre o recurso de machine learning, consulte Usar machine learning (ML) com Amazon Athena (previsualização).
Funções definidas pelo usuário (UDFs) (visualização)
Agora você pode escrever funções escalares personalizadas e chamá-las em consultas do Athena. É possível escrever as UDFs em Java usando o Athena Query Federation SDKSELECT e FILTER de uma consulta SQL. E possível chamar vários UDFs na mesma consulta.
Disponibilidade de visualização
A funcionalidade de UDF do Athena está disponível no modo de previsualização na região Leste dos EUA (Norte da Virgínia).
Próximas etapas
-
Para iniciar sua previsualização, siga as instruções nas Perguntas frequentes sobre recursos em previsualização do Athena
. -
Para saber mais, consulte Consultar com funções definidas pelo usuário (visualização).
-
Para ver exemplos de implementação de UDF, consulte Conector de UDF do Amazon Athena
no GitHub. -
Para saber como escrever as próprias funções usando o Athena Query Federation SDK, consulte Criar e implantar uma UDF usando o Lambda.
Usar o metastore do Apache Hive como um metacatálogo com o Amazon Athena (previsualização)
Agora é possível conectar o Athena a um ou mais metastores do Apache Hive, além do AWS Glue Data Catalog com o Athena.
Conector de metastore
Para se conectar a um metastore do Hive auto-hospedado, você precisa de um conector de metastore do Athena Hive. O Athena inclui um conector de implementação de referência
Disponibilidade de visualização
O recurso de metastore do Hive está disponível no modo de previsualização na região Leste dos EUA (Norte da Virgínia).
Próximas etapas
-
Para iniciar sua previsualização, siga as instruções nas Perguntas frequentes sobre recursos em previsualização do Athena
. -
Para saber mais sobre esse recurso, acesse Usar o conector de dados do Athena para metastore externo do Hive (previsualização).
Novas métricas relacionadas à consulta
O Athena agora publica métricas de consulta adicionais que podem ajudar você a saber como está a performance do Amazon Athena
-
Query Planning Time (Tempo de planejamento da consulta): o tempo necessário para planejar a consulta. Isso inclui o tempo gasto recuperando partições de tabela da fonte de dados.
-
Query Queuing Time (Tempo de fila da consulta): o tempo que a consulta ficou na fila aguardando recursos.
-
Service Processing Time (Tempo de processamento do serviço): o tempo que levou para gravar os resultados após a conclusão do processamento do mecanismo de consulta.
-
Rntime totale: o tempo necessário para o Athena executar a consulta.
Para consumir essas novas métricas de consulta, é possível criar painéis personalizados, definir alarmes e acionadores baseados em métricas no CloudWatch ou usar painéis já preenchidos diretamente no console do Athena.
Próximas etapas
Para obter mais informações, leia Monitorar consultas do Athena com as métricas do CloudWatch.
12 de novembro de 2019
Publicado em 17-12-2019
O Amazon Athena já está disponível na região Oriente Médio (Bahrein).
8 de novembro de 2019
Publicado em 17-12-2019
O Amazon Athena já está disponível nas regiões Oeste dos EUA (N. da Califórnia) e Europa (Paris).
8 de outubro de 2019
Publicado em 17-12-2019
O Amazon Athena
Para criar um endpoint da VPC de interface para se conectar ao Athena, é possível usar o Console de gerenciamento da AWS ou a AWS Command Line Interface (AWS CLI). Para obter informações sobre como criar um endpoint de interface, consulte Criar um endpoint de interface.
Ao usar um endpoint da VPC de interface, a comunicação entre a VPC e as APIs do Athena fica protegida e permanece dentro da rede da AWS. Não há custos adicionais do Athena para usar esse recurso. São aplicáveis taxas
Para saber mais sobre esse recurso, consulte Conectar-se ao Amazon Athena usando um endpoint da VPC de interface.
19 de setembro de 2019
Publicado em 17-12-2019
O Amazon Athena inclui suporte para inserir novos dados em uma tabela existente usando a instrução INSERT INTO. É possível inserir linhas em uma tabela de destino com base em uma instrução de consulta SELECT executada em uma tabela de origem ou em um conjunto de valores informados como parte da instrução de consulta. Os formatos de dados compatíveis incluem arquivos Avro, JSON, ORC, Parquet e de texto.
INSERT INTOAs instruções também podem ajudar a simplificar processos de ETL. Por exemplo, é possível usar INSERT INTO em uma única consulta para selecionar dados de uma tabela de origem no formato JSON e gravá-los em uma tabela de destino no formato Parquet.
As instruções INSERT INTO são cobradas conforme o número de bytes que são verificados na fase SELECT, de modo similar à cobrança das consultas SELECT do Athena. Para obter mais informações, consulte Preços do Amazon Athena
Para obter mais informações sobre como usar INSERT INTO, incluindo formatos compatíveis, SerDes e exemplos, consulte INSERT INTO no Manual do usuário do Athena.
12 de setembro de 2019
Publicado em 17-12-2019
Agora o Amazon Athena está disponível na região da Ásia-Pacífico (Hong Kong).
16 de agosto de 2019
Publicado em 17-12-2019
O Amazon Athena
Quando um bucket do Amazon S3 é configurado como pagamento a cargo do solicitante, o solicitante, não o proprietário do bucket, paga pelos custos de solicitação e de transferência de dados do Amazon S3. No Athena, os administradores de grupo de trabalho agora podem definir as configurações do grupo de trabalho para permitir que seus membros consultem os buckets de pagamento a cargo do solicitante do S3.
Para obter informações sobre como definir a configuração de pagamento a cargo do solicitante em seu grupo de trabalho, consulte Criar um grupo de trabalho no Manual do usuário do Amazon Athena. Para obter mais informações, consulte Buckets de pagamento a cargo do solicitante no Guia do desenvolvedor do Amazon Simple Storage Service.
9 de agosto de 2019
Publicado em 17-12-2019
O Amazon Athena agora permite a aplicação de políticas do AWS Lake Formation
Você pode usar esse recurso nas seguintes Regiões da AWS: Leste dos EUA (Ohio), Leste dos EUA (Norte da Virgínia), Oeste dos EUA (Oregon), Ásia-Pacífico (Tóquio) e Europa (Irlanda). Não há cobranças adicionais por esse recurso.
Para obter mais informações sobre o uso desse recurso, consulte Usar o Athena para consultar dados registrados no AWS Lake Formation. Para obter mais informações sobre AWS Lake Formation, consulte AWS Lake Formation
26 de junho de 2019
O Amazon Athena já está disponível na região Europa (Estocolmo). Para obter uma lista de regiões e endpoints compatíveis, consulte Regiões da AWS e endpoints.
24 de maio de 2019
Publicado em 2019-05-24
O Amazon Athena já está disponível nas regiões AWS GovCloud (EUA-Leste) e AWS GovCloud (EUA-Oeste). Para obter uma lista de regiões e endpoints compatíveis, consulte Regiões da AWS e endpoints.
05 de março de 2019
Publicado em 2019-03-05
O Amazon Athena já está disponível na região Canadá (Central). Para obter uma lista de regiões e endpoints compatíveis, consulte Regiões da AWS e endpoints. A nova versão do driver ODBC foi lançada com suporte a grupos de trabalho do Athena. Para obter mais informações, consulte as Notas de release do driver ODBC
Para fazer download do driver ODBC versão 1.0.5 e da respectiva documentação, consulte Conectar ao Amazon Athena com ODBC. Para obter mais informações sobre essa versão, consulte as Notas de release do driver ODBC
Para usar grupos de trabalho com o driver ODBC, defina a nova propriedade de conexão, Workgroup, na string de conexão, conforme mostrado no exemplo a seguir:
Driver=Simba Athena ODBC Driver;AwsRegion=[Region];S3OutputLocation=[S3Path];AuthenticationType=IAM Credentials;UID=[YourAccessKey];PWD=[YourSecretKey];Workgroup=[WorkgroupName]
Para obter mais informações, procure "workgroup" no ODBC Driver Installation and Configuration Guide versão 1.0.5
Essa versão do driver permite que você use as ações de grupo de trabalho da API do Athena para criar e gerenciar grupos de trabalho e as ações de etiqueta da API do Athena para adicionar, listar ou remover etiquetas dos grupos de trabalho. Antes de começar, você deve ter permissões no nível do recurso no IAM para as ações nos grupos de trabalho e nas etiquetas.
Para obter mais informações, consulte:
Se você usa o driver JDBC ou o AWS SDK, faça upgrade para a versão mais recente do driver e do SDK, ambos já incluem suporte para grupos de trabalho e etiquetas no Athena. Para obter mais informações, consulte Conectar ao Amazon Athena com JDBC.
22 de fevereiro de 2019
Publicado em 2019-02-22
Suporte incluído para etiquetas de grupos de trabalho no Amazon Athena. Uma tag consiste em uma chave e um valor, ambos definidos por você. Quando você marca um grupo de trabalho, atribui metadados personalizados a ele. É possível adicionar tags a grupos de trabalho para ajudar a categorizá-los, usando as práticas recomendadas de marcação com tags da AWS. Você pode usar tags para restringir o acesso a grupos de trabalho e rastrear custos. Por exemplo, crie um grupo de trabalho para cada centro de custo. Ao adicionar etiquetas a esses grupos de trabalho, você pode acompanhar os gastos com o Athena para cada centro de custo. Para obter mais informações, consulte Usar tags para faturamento no Guia do usuário do Gerenciamento de Faturamento e Custos da AWS;.
Você pode trabalhar com etiquetas usando o console do Athena ou as operações de API. Para obter mais informações, consulte Marcar recursos do Athena com tags.
No console do Athena, você pode adicionar uma ou mais etiquetas a cada um dos grupos de trabalho e pesquisá-las. Os grupos de trabalho são um recurso controlado pelo IAM no Athena. No IAM, você pode restringir quem pode adicionar, remover ou listar etiquetas nos grupos de trabalho que você cria. Você também pode usar a operação de API CreateWorkGroup que tenha o parâmetro de tag opcional para adicionar uma ou mais tags ao grupo de trabalho. Para adicionar, remover ou listar tags, use TagResource, UntagResource e ListTagsForResource. Para obter mais informações, consulte Usar API e operações de tag da AWS CLI.
Para permitir que os usuários adicionem etiquetas ao criar grupos de trabalho, você deve conceder a cada usuário permissões do IAM para as ações da API TagResource e CreateWorkGroup. Para ter mais informações e exemplos, consulte Usar políticas de controle de acesso do IAM baseadas em tags.
Não há alterações para o driver JDBC ao usar tags nos grupos de trabalho. Se você criar grupos de trabalho e usar o driver JDBC ou o AWS SDK, faça upgrade para a versão mais recente do driver e do SDK. Para mais informações, consulte Conectar ao Amazon Athena com JDBC.
18 de fevereiro de 2019
Publicado em 2019-02-18
Adição da capacidade de controlar os custos de consulta ao executar consultas nos grupos de trabalho. Para mais informações, consulte Usar grupos de trabalho para controlar o acesso a consultas e os custos. Melhoria no JSON OpenX SerDe usado no Athena, foi corrigido um problema em que o Athena não ignorava os objetos que fizeram a transição para a classe de armazenamento do GLACIER e foram incluídos exemplos de consulta de logs do Network Load Balancer.
Foram feitas as seguintes alterações:
-
Adição de suporte a grupos de trabalho. Uso de grupos de trabalho para separar usuários, equipes, aplicativos ou cargas de trabalho e para definir limites de quantidade de dados que cada consulta ou todo o grupo de trabalho pode processar. Como os grupos de trabalho atuam como recursos do IAM, você pode usar permissões no nível do recurso para controlar o acesso a um determinado grupo de trabalho. Você também pode visualizar as métricas relacionadas à consulta no Amazon CloudWatch, controlar os custos das consultas configurando limites para a quantidade de dados verificada, criar limites e acionar ações, como alarmes do Amazon SNS, quando esses limites são violados. Para obter mais informações, consulte Usar grupos de trabalho para controlar o acesso a consultas e os custos e Usar o CloudWatch e o EventBridge para monitorar as consultas e controlar os custos.
Os grupos de trabalho são um recurso do IAM. Para obter uma lista completa de recursos, condições e ações relacionados a grupo de trabalho no IAM, consulte Ações, recursos e chaves de condição do Amazon Athena na Referência de autorização do serviço. Antes de criar grupos de trabalho, não esqueça de usar as políticas de grupo de trabalho do IAM e a AWSPolítica gerenciada pela : AmazonAthenaFullAccess.
Você pode usar grupos de trabalho no console com operações de API de grupo de trabalho ou com o driver JDBC. Para obter informações sobre a criação de grupos de trabalho, consulte Criar um grupo de trabalho. Para baixar o driver JDBC com suporte ao grupo de trabalho, consulte Conectar ao Amazon Athena com JDBC.
Se você usar grupos de trabalho com o driver JDBC, defina o nome do grupo de trabalho na string de conexão usando o parâmetro de configuração
Workgroup, como no exemplo a seguir:jdbc:awsathena://AwsRegion=<AWSREGION>;UID=<ACCESSKEY>; PWD=<SECRETKEY>;S3OutputLocation=s3://amzn-s3-demo-bucket/<athena-output>-<AWSREGION>/; Workgroup=<WORKGROUPNAME>;Não há alterações na forma como você executa instruções SQL ou faz chamadas de API JDBC para o driver. O driver passa o nome do grupo de trabalho para o Athena.
Para obter informações sobre as diferenças introduzidas com os grupos de trabalho, consulte Usar APIs de grupos de trabalho do Athena e Solucionar erros de grupo de trabalho.
-
Melhoria no JSON OpenX SerDe usado no Athena. As melhorias incluem, entre outros:
-
Suporte à propriedade
ConvertDotsInJsonKeysToUnderscores. Quando definido comoTRUE, permite que o SerDe substitua por sublinhados os pontos nos nomes de chaves. Por exemplo, se o conjunto de dados JSON tem uma chave chamada"a.b", você pode usar essa propriedade para definir o nome da coluna como"a_b"no Athena. O padrão éFALSE. Por padrão, o Athena não permite pontos nos nomes de coluna. -
Suporte à propriedade
case.insensitive. Por padrão, o Athena exige que todas as chaves do conjunto de dados JSON estejam em letras minúsculas. O uso deWITH SERDE PROPERTIES ("case.insensitive"= FALSE;)permite usar nomes de chaves com diferenciação de maiúsculas e minúsculas nos seus dados. O padrão éTRUE. Quando definido comoTRUE, o SerDe converte todas as colunas em maiúsculas para minúsculas.
Para obter mais informações, consulte OpenX JSON SerDe.
-
-
Um problema foi corrigido em que o Athena retornava mensagens de erro
"access denied"quando processava objetos do Amazon S3 arquivados no Glacier pelas políticas de ciclo de vida do Amazon S3. Como resultado da correção desse problema, o Athena ignora os objetos que fizeram a transição para a classe de armazenamento doGLACIER. O Athena não permite a consulta de dados na classe de armazenamento doGLACIER.Para obter mais informações, consulte Considerações sobre o Amazon S3 e Transição para a classe de armazenamento do GLACIER (arquivamento de objetos) no Guia do usuário do Amazon Simple Storage Service.
-
Adição de exemplos para consultar logs de acesso do Network Load Balancer que recebem informações sobre as solicitações de Transport Layer Security (TLS). Para obter mais informações, consulte Consultar logs do Network Load Balancer.
Notas de release do Athena para 2018
20 de novembro de 2018
Publicado em 2018-11-20
As novas versões dos drivers JDBC e ODBC foram lançadas com suporte para acesso federado à API do Athena com o AD FS e o SAML 2.0 (Security Assertion Markup Language 2.0). Para obter mais detalhes, consulte as Notas de release do driver JDBC
Com essa versão, o acesso federado ao Athena é permitido para o Active Directory Federation Service (AD FS 3.0). O acesso é estabelecido por meio das versões dos drivers JDBC ou ODBC que oferecem suporte ao SAML 2.0. Para obter informações sobre como configurar o acesso federado à API do Athena, consulte Habilitar o acesso federado à API do Athena.
Para fazer download do driver JDBC versão 2.0.6 e da respectiva documentação, consulte Conectar ao Amazon Athena com JDBC. Para obter mais informações sobre essa versão, consulte as Notas de release do driver JDBC
Para fazer download do driver ODBC versão 1.0.4 e da respectiva documentação, consulte Conectar ao Amazon Athena com ODBC. Para obter mais informações sobre essa versão, consulte as Notas de release do driver ODBC
Para obter mais informações sobre o suporte ao SAML 2.0 na AWS, consulte Sobre a federação do SAML 2.0 no Manual do usuário do IAM.
15 de outubro de 2018
Publicado em 2018-10-15
Se você tiver atualizado para o AWS Glue Data Catalog, haverá dois novos recursos que fornecem suporte para:
-
Criptografia de metadados do Catálogo de dados. Se você criptografar os metadados no Catálogo de dados, deverá adicionar políticas específicas ao Athena. Para obter mais informações, consulte Acesso a metadados criptografados no AWS Glue Data Catalog.
-
Permissões refinadas para acessar recursos no AWS Glue Data Catalog. Agora você pode definir políticas baseadas em identidade (IAM) que restringem ou permitem o acesso a bancos de dados e tabelas específicos do Catálogo de dados usados no Athena. Para obter mais informações, consulte Configurar o acesso a bancos de dados e tabelas no AWS Glue Data Catalog.
nota
Os dados residem nos buckets do Amazon S3 e o acesso a eles é controlado pelas Controlar o acesso ao Amazon S3 do Athena. Para acessar os dados em bancos de dados e tabelas, continue usando as políticas de controle de acesso aos buckets do Amazon S3 que armazenam os dados.
10 de outubro de 2018
Publicado em 2018-10-10
O Athena oferece suporte a CREATE TABLE AS SELECT, que cria uma tabela com base no resultado de uma instrução de consulta SELECT. Para obter detalhes, consulte Criar uma tabela a partir de resultados da consulta (CTAS).
Antes de criar consultas CTAS, é importante conhecer melhor o comportamento delas na documentação do Athena. Ela inclui informações sobre o local para salvar os resultados das consultas no Amazon S3, a lista de formatos compatíveis para armazenar resultados das consultas CTAS, o número de partições que é possível criar e os formatos de compactação permitidos. Para obter mais informações, consulte Considerações e limitações de consultas CTAS.
Use consultas CTAS para:
-
Crie uma tabela a partir de resultados da consulta em uma etapa.
-
Crie consultas CTAS no console do Athena, usando Exemplos. Para obter informações sobre a sintaxe, consulte CREATE TABLE AS.
-
Transforme resultados da consulta em outros formatos de armazenamento, como PARQUET, ORC, AVRO, JSON e TEXTFILE. Para obter mais informações, consulte Considerações e limitações de consultas CTAS e Usar formatos de armazenamento colunares.
6 de setembro de 2018
Publicado em 2018-09-06
Lançada a nova versão do driver ODBC (versão 1.0.3). A nova versão do driver ODBC transmite resultados por padrão, em vez de paginação por meio deles, permitindo que as ferramentas de business intelligence recuperem grandes conjuntos de dados com mais rapidez. Essa versão também inclui melhorias, correções de erros e uma documentação atualizada para "Usar SSL com um servidor de proxy". Para obter detalhes, consulte as Notas de release
Para fazer download do driver ODBC versão 1.0.3 e da respectiva documentação, consulte Conectar ao Amazon Athena com ODBC.
O recurso de streaming de resultados está disponível com essa nova versão do driver ODBC. Também está disponível com o driver JDBC. Para obter informações sobre o streaming de resultados, consulte o Guia de instalação e configuração do driver ODBC
O driver ODBC versão 1.0.3 é um substituto pronto para a versão anterior do driver. Recomendamos que você migre para o driver atual.
Importante
Para usar o driver ODBC versão 1.0.3, siga estes requisitos:
-
Mantenha a porta 444 aberta para tráfego de saída.
-
Adicione a ação da política
athena:GetQueryResultsStreamà lista de políticas do Athena. Essa ação de política não é exposta diretamente com a API e só é usada com os drivers ODBC e JDBC, como parte do suporte ao streaming de resultados. Para visualizar um exemplo de política, consulte AWSPolítica gerenciada : AWSQuicksightAthenaAccess.
23 de agosto de 2018
Publicado em 2018-08-23
Adicionado suporte para estes recursos relacionados à DDL e corrigidos vários erros, como a seguir:
-
Adicionado suporte para os tipos de dados
BINARYeDATEpara dados no Parquet, e para os tipos de dadosDATEeTIMESTAMPpara dados no Avro. -
Adicionamos suporte para
INTeDOUBLEem consultas DDL.INTEGERé um alias paraINT, eDOUBLE PRECISIONé um alias paraDOUBLE. -
Melhor performance de consultas
DROP TABLEeDROP DATABASE. -
Foi removida a criação de objeto
_$folder$no Amazon S3 quando um bucket de dados está vazio. -
Corrigido um problema em que
ALTER TABLE ADD PARTITIONgerou um erro quando nenhum valor de partição foi fornecido. -
Corrigido um problema em que
DROP TABLEignorou o nome do banco de dados ao verificar partições após o nome qualificado ter sido especificado na instrução.
Para saber mais sobre os tipos de dados compatíveis com o Athena, consulte Tipos de dados no Amazon Athena.
Para obter informações sobre os mapeamentos de tipos de dados permitidos entre os tipos no Athena, o driver JDBC e os tipos de dados do Java, consulte a seção "Tipos de dados" no Guia de instalação e configuração do driver JDBC
16 de agosto de 2018
Publicado em 2018-08-16
Lançado o driver JDBC versão 2.0.5. A nova versão do driver JDBC transmite resultados por padrão, em vez de paginação por meio deles, permitindo que as ferramentas de business intelligence recuperem grandes conjuntos de dados com mais rapidez. Em comparação com a versão anterior do driver JDBC, houve as seguintes melhorias de performance:
-
Aproximadamente, o dobro da performance ao obter menos que 10.000 linhas.
-
Aproximadamente, cinco a seis vezes de aumento na performance ao obter mais que 10.000 linhas.
O recurso de streaming de resultados está disponível apenas com o driver JDBC. Não está disponível com o driver ODBC. Você não pode usá-lo com a API do Athena. Para obter informações sobre o streaming de resultados, consulte o Guia de instalação e configuração do driver JDBC
Para fazer download do driver JDBC versão 2.0.5 e da respectiva documentação, consulte Conectar ao Amazon Athena com JDBC.
O driver JDBC versão 2.0.5 é um substituto pronto para a versão anterior do driver (2.0.2). Para garantir que você possa usar o driver JDBC versão 2.0.5, adicione a ação da política athena:GetQueryResultsStream à lista de políticas do Athena. Essa ação de política não é exposta diretamente com a API e só é usada com o driver JDBC, como parte do suporte ao streaming de resultados. Para visualizar um exemplo de política, consulte AWSPolítica gerenciada : AWSQuicksightAthenaAccess. Para obter mais informações sobre como migrar da versão 2.0.2 para a versão 2.0.5 do driver, consulte o Guia de migração do driver JDBC
Se estiver migrando de um driver 1.x para um driver 2.x, você precisará migrar suas configurações existentes para a nova configuração. É altamente recomendável migrar para a versão atual do driver. Para obter mais informações, consulte e o Guia de migração do driver JDBC
7 de agosto de 2018
Publicado em 2018-08-07
Agora você pode armazenar logs de fluxo do Amazon Virtual Private Cloud diretamente no Amazon S3 em um formato GZIP que você pode consultar no Athena. Para obter informações, consulte Consultar os logs de fluxo do Amazon VPC e Logs de fluxo da Amazon VPC agora podem ser entregues para o S3
5 de junho de 2018
Publicado em 2018-06-05
Suporte para exibições
Adicionado suporte para exibições. Agora você pode usar CREATE VIEW e da CREATE PROTECTED MULTI DIALECT VIEW, DESCRIBE VIEW, DROP VIEW, SHOW CREATE VIEW e SHOW VIEWS no Athena. A consulta que define a exibição é executada sempre que você faz referência à exibição em uma consulta. Para obter mais informações, consulte Trabalhar com visualizações.
Melhorias e atualizações em mensagens de erro
-
Foi incluída uma biblioteca GSON 2.8.0 no CloudTrail SerDe para resolver um problema com o CloudTrail SerDe e habilitar a análise de strings JSON.
-
Validação aprimorada do esquema de partição no Athena para Parquet e, em alguns casos, para ORC, permitindo a reclassificação de colunas. Isso permite que o Athena processe melhor as alterações feitas na evolução do esquema ao longo do tempo e as tabelas adicionadas pelo Crawler do AWS Glue. Para obter mais informações, consulte Lidar com atualizações de esquemas.
-
Foi adicionado suporte para análise de
SHOW VIEWS. -
Feitas as seguintes melhorias nas mensagens de erro mais comuns:
-
Foi substituída uma mensagem de
Internal Error(Erro interno) por uma mensagem descritiva do erro quando um SerDe não consegue analisar a coluna em uma consulta do Athena. Antes, o Athena emitia um erro interno em caso de erros de análise. A nova mensagem de erro lê:" HIVE_BAD_DATA: Erro ao analisar o valor de campo para o campo 0: java.lang. A string não pode ser convertida para org.openx.data.jsonserde.json.JSONObject". -
Mensagens de erro aprimoradas sobre permissões insuficientes, adicionando mais detalhes.
-
Correções de bugs
Corrigidos os seguintes bugs:
-
Corrigido um problema que permite a conversão interna dos tipos de dados
REALemFLOAT. Isso melhora a integração com o crawler do AWS Glue que retorna tipos de dadosFLOAT. -
Foi corrigido um problema em que o Athena não convertia
DECIMALdo AVRO (um tipo lógico) em um tipoDECIMAL. -
Foi corrigido um problema em que o Athena não retornava resultados das consultas em dados do Parquet com cláusulas
WHEREque faziam referência a valores no tipo de dadosTIMESTAMP.
17 de maio de 2018
Publicado em 2018-05-17
A cota de simultaneidade de consultas no Athena foi aumentada de cinco para vinte. Isso significa que você pode enviar e executar até 20 consultas DDL e 20 consultas SELECT de cada vez. Observe que as cotas de simultaneidade são separadas para as consultas DDL e SELECT.
As cotas de simultaneidade no Athena são definidas como o número de consultas que podem ser enviadas ao mesmo tempo para o serviço. Você pode enviar até 20 consultas do mesmo tipo (DDL ou SELECT) por vez. Se você enviar uma consulta que exceda a cota de consultas simultâneas, a API do Athena exibirá uma mensagem de erro.
Depois que você envia suas consultas para o Athena, ele as processa atribuindo recursos com base na carga de serviço geral e na quantidade de solicitações recebidas. Nós monitoramos e fazemos ajustes continuamente no serviço para que suas consultas sejam processadas o mais rápido possível.
Para mais informações, consulte Service Quotas. Esta é uma cota ajustável. Você pode usar o console do Service Quotas
19 de abril de 2018
Publicado em 2018-04-19
Lançada a nova versão do driver JDBC (versão 2.0.2) com suporte para retorno de dados de ResultSet como um tipo de dados Array, melhorias e correções de bugs. Para obter detalhes, consulte as Notas de release
Para obter informações sobre como fazer download do novo driver JDBC versão 2.0.2 e respectiva documentação, consulte Conectar ao Amazon Athena com JDBC.
A versão mais recente do driver JDBC é a 2.0.2. Se estiver migrando de um driver 1.x para um driver 2.x, você precisará migrar suas configurações existentes para a nova configuração. É altamente recomendável que você migre para o driver atual.
Para obter informações sobre as alterações introduzidas na nova versão do driver, as diferenças de versão e os exemplos, consulte o Guia de migração do driver JDBC
6 de abril de 2018
Publicado em 2018-04-06
Use o preenchimento automático para digitar consultas no console do Athena.
15 de março de 2018
Publicado em 2018-03-15
Recurso incluído para criação automática de tabelas do Athena para arquivos de log do CloudTrail diretamente no console do CloudTrail. Para mais informações, consulte Usar o console do CloudTrail para criar uma tabela do Athena com logs do CloudTrail.
2 de fevereiro de 2018
Publicado em 2018-02-12
Adicionada a capacidade de descarregar com segurança dados intermediários no disco para consultas com uso intensivo de memória que empregam a cláusula GROUP BY. Isso melhora a confiabilidade dessas consultas, evitando erros do tipo "Query resource exhausted" (Recurso de consulta esgotado).
19 de janeiro de 2018
Publicado em 2018-01-19
O Athena usa o Presto, um mecanismo de consulta distribuído de código aberto, para executar consultas.
Com o Athena, não há versões a serem gerenciadas. Fizemos upgrade transparente do mecanismo subjacente no Athena para uma versão baseada no Presto 0.172. Não é necessária nenhuma ação de sua parte.
Com o upgrade, você pode usar as funções e os operadores do Presto 0.172, incluindo as expressões do Lambda para Presto 0.172 no Athena.
Entre as principais atualizações desta versão, inclusive correções de contribuição da comunidade, estão:
-
Suporte para ignorar cabeçalhos. Você pode usar a propriedade
skip.header.line.countao definir tabelas para permitir que o Athena ignore os cabeçalhos. Esse recurso é permitido para consultas que usam o LazySimpleSerDe e o SerDe do OpenCSV, e não o SerDes do Grok ou Regex. -
Suporte para o tipo de dados
CHAR(n)em funçõesSTRING. O intervalo deCHAR(n)é[1.255], e o intervalo deVARCHAR(n)é[1,65535]. -
Suporte para subconsultas correlacionadas.
-
Suporte para expressões e funções do Lambda do Presto.
-
Performance aprimorada do tipo
DECIMALe dos operadores. -
Suporte para agregações filtradas, como
SELECT sum(col_name) FILTER, em queid > 0. -
Predicados para os tipos de dados
DECIMAL,TINYINT,SMALLINTeREAL. -
Suporte para predicados de comparação quantificados:
ALL,ANYeSOME. -
Funções adicionadas:
arrays_overlap(), array_except(), levenshtein_distance(), codepoint(), skewness(), kurtosis(), e typeof(). -
Adicionada uma variante da função
from_unixtime()que utiliza um argumento de fuso horário. -
Adicionadas as funções de agregação
bitwise_and_agg()e bitwise_or_agg(). -
Adicionadas as funções
xxhash64()e to_big_endian_64(). -
Suporte adicional para aspas duplas ou barras invertidas de escape usando uma barra invertida com um sublinhado de caminho JSON nas funções
json_extract()e json_extract_scalar(). Isso altera a semântica de qualquer invocação usando uma barra invertida, porque as barras invertidas já foram tratados como caracteres normais.
Para obter mais informações sobre as funções e os operadores, consulte Consultas, funções e operadores em DML neste guia e Functions and operators
O Athena não permite todos os recursos do Presto. Para obter mais informações, consulte Limitações.
Notas de release do Athena para 2017
13 de novembro de 2017
Publicado em 2017-11-13
Suporte adicional para conectar o Athena ao driver ODBC. Para mais informações, consulte Conectar ao Amazon Athena com ODBC.
1 de novembro de 2017
Publicado em 2017-11-01
Adicionado suporte para consultar dados geoespaciais e para regiões Ásia-Pacífico (Seul), Ásia-Pacífico (Mumbai) e UE (Londres). Para obter informações, consulte Consultar dados geoespaciais e Regiões da AWS e Endpoints.
19 de outubro de 2017
Publicado em 2017-10-19
Adicionado suporte para UE (Frankfurt). Para obter uma lista de regiões e endpoints compatíveis, consulte Regiões da AWS e Endpoints.
3 de outubro de 2017
Publicado em 2017-10-03
Crie consultas nomeadas do Athena com o CloudFormation. Para obter mais informações, consulte AWS::Athena::NamedQuery no Guia do usuário do AWS CloudFormation.
25 de setembro de 2017
Publicado em 2017-09-25
Suporte incluído para a região Ásia-Pacífico (Sydney). Para obter uma lista de regiões e endpoints compatíveis, consulte Regiões da AWS e Endpoints.
14 de agosto de 2017
Publicado em 2017-08-14
Integração incluída com o AWS Glue Data Catalog e um assistente de migração para atualizar do catálogo de dados gerenciados do Athena para o AWS Glue Data Catalog. Para obter mais informações, consulte Usar o AWS Glue Data Catalog para se conectar aos seus dados.
4 de agosto de 2017
Publicado em 2017-08-04
Adicionado suporte para Grok SerDe, que oferece um padrão de correspondência mais simples para registros em arquivos de texto desestruturados, como logs. Para obter mais informações, consulte Grok SerDe. Adicionados atalhos de teclado para percorrer o histórico de consultas usando o console (CTRL + ⇧/⇩ usando o Windows, CMD + ⇧/⇩ usando o Mac).
22 de junho de 2017
Publicado em 2017-06-22
Suporte incluído para as regiões Ásia-Pacífico (Tóquio) e Ásia-Pacífico (Singapura). Para obter uma lista de regiões e endpoints compatíveis, consulte Regiões da AWS e Endpoints.
8 de junho de 2017
Publicado em 2017-06-08
Suporte incluído para a região Europa (Irlanda). Para obter mais informações, consulte Regiões da AWS e endpoints.
19 de maio de 2017
Publicado em 2017-05-19
Foram incluídos uma API do Amazon Athena e suporte à AWS CLI no Athena; o driver JDBC foi atualizado para a versão 1.1.0; vários problemas foram corrigidos.
-
O Amazon Athena permite a programação do aplicativo para o Athena. Para obter mais informações, consulte Referência de API do Amazon Athena. Os AWS SDKs mais recentes são compatíveis com a API do Athena. Para links da documentação e downloads, consulte a seção SDKs em Ferramentas da Amazon Web Services
. -
A AWS CLI inclui novos comandos para o Athena. Para obter mais informações, consulte a Referência de API do Amazon Athena.
-
Um novo driver JDBC 1.1.0 está disponível, o que oferece suporte à nova API do Athena, bem como aos recursos e às correções de bugs mais recentes. Faça download do driver em https://downloads.athena.us-east-1.amazonaws.com/drivers/AthenaJDBC41-1.1.0.jar
. Recomendamos atualizar para a versão mais recente do driver JDBC do Athena. No entanto, você ainda pode usar a versão do driver anterior. As versões anteriores do driver não oferecem suporte à API do Athena. Para obter mais informações, consulte Conectar ao Amazon Athena com JDBC. -
Ações específicas em declarações de política em versões anteriores do Athena foram substituídas. Se atualizar a versão do driver JDBC 1.1.0 e tiver políticas do IAM gerenciadas por clientes ou em linha anexadas a usuários do JDBC, você deverá atualizar as políticas do IAM. Por outro lado, as versões anteriores do driver JDBC não oferecem suporte à API do Athena. Dessa maneira, você só pode especificar ações obsoletas em políticas anexadas a usuários JDBC de uma versão anterior. Por esse motivo, você não precisa atualizar políticas do IAM gerenciadas pelo cliente ou em linha.
-
Essas ações específicas da política foram usadas no Athena antes do lançamento da API do Athena. Use essas ações obsoletas em políticas apenas com drivers JDBC anteriores a essa versão 1.1.0. Se estiver atualizando o driver JDBC, substitua as declarações de políticas que permitem ou negam ações obsoletas por ações da API apropriada conforme listadas ou ocorrerão erros:
| Ação específica da política obsoleta | Ação da API do Athena correspondente |
|---|---|
|
|
|
|
|
|
Melhorias
-
Aumentado o limite de tamanho da string de consulta para 256 KB.
Correções de bugs
-
Corrigido um problema que fazia os resultados da consulta terem aparência malformada durante a rolagem pelos resultados no console.
-
Corrigido um problema em que uma string de caractere
\u0000em arquivos de dados do Amazon S3 causaria erros. -
Corrigido um problema que fazia as solicitações para cancelar uma consulta feita pelo driver JDBC falharem.
-
Foi corrigido um problema que fazia com que o SerDe do AWS CloudTrail falhasse com dados do Amazon S3 na região Leste dos EUA (Ohio).
-
Corrigido um problema que fez com que
DROP TABLEfalhasse em uma tabela particionada.
4 de abril de 2017
Publicado em 2017-04-04
Adicionado suporte adicional para criptografia de dados do Amazon S3 e liberada atualização do driver JDBC (versão 1.0.1) com suporte à criptografia, melhorias e correções de bugs.
Recursos
-
Adicionados os seguintes recursos de criptografia:
-
Suporte para consultar dados criptografados no Amazon S3.
-
Suporte para criptografar resultados da consulta do Athena.
-
-
Uma nova versão do driver oferece suporte a novos recursos de criptografia, adiciona melhorias e corrige problemas.
-
Adicionada a possibilidade de adicionar, substituir e alterar colunas usando
ALTER TABLE. Para obter mais informações, consulte Alter Columnna documentação do Hive. -
Adicionado suporte para consultar dados compactados por LZO.
Para obter mais informações, consulte Criptografia em repouso.
Melhorias
-
Melhor performance da consulta JDBC com melhorias no tamanho da página, retornando 1.000 linhas, em vez de 100.
-
Adicionada capacidade para cancelar uma consulta usando a interface do driver JDBC.
-
Adicionada capacidade para especificar opções de JDBC no URL de conexão JDBC. Consulte Conectar ao Amazon Athena com JDBC para obter o driver JDBC mais atual.
-
Adicionada configuração de PROXY ao driver, que já pode ser definida usando ClientConfiguration no AWS SDK for Java.
Correções de bugs
Corrigidos os seguintes bugs:
-
Erros de controle de utilização ocorreriam quando várias consultas foram emitidas usando a interface do driver JDBC.
-
O driver JDBC era interrompido durante a projeção de um tipo de dados decimal.
-
O driver JDBC retornaria cada tipo de dados como uma string, independentemente de como o tipo de dados foi definido na tabela. Por exemplo, selecionar uma coluna definida como um tipo de dados
INTusandoresultSet.GetObject()retornaria um tipo de dadosSTRING, em vez deINT. -
O driver JDBC verificaria credenciais no momento em que uma conexão foi estabelecida, e não no momento em que uma consulta seria executada.
-
As consultas feitas por meio do driver JDBC falhariam quando um esquema fosse especificado com o URL.
24 de março de 2017
Publicado em 2017-03-24
Foi adicionado o SerDe do AWS CloudTrail, a performance foi melhorada, os problemas de partição foram corrigidos.
Recursos
-
Ocorreu a adição do SerDe para o AWS CloudTrail, que desde então foi substituído pelo Hive JSON SerDe para leitura de logs do CloudTrail. Para obter informações sobre a consulta de logs do CloudTrail, consulte Consultar logs do AWS CloudTrail.
Melhorias
-
Melhorada a performance durante o exame de um grande número de partições.
-
Melhorada a performance na operação
MSCK Repair Table. -
Recurso incluído para consultar dados do Amazon S3 armazenados em regiões diferentes da região principal. Taxas de transferência de dados entre regiões padrão do Amazon S3 se aplicam, além de cobranças do Athena padrão.
Correções de bugs
-
Corrigido um bug em que um erro "tabela não encontrada" poderá ocorrer se nenhuma partição for carregada.
-
Corrigido um bug para evitar lançar uma exceção com consultas
ALTER TABLE ADD PARTITION IF NOT EXISTS. -
Corrigido um bug em
DROP PARTITIONS.
20 de fevereiro de 2017
Publicado em 2017-02-20
Suporte incluído para AvroSerDe e OpenCSVSerDe, região Leste dos EUA (Ohio) e edição em massa de colunas no assistente do console. Melhorada a performance em tabelas Parquet grandes.
Recursos
-
Introduzido suporte para novo SerDes:
-
Lançamento da região Leste dos EUA (Ohio) (us-east-2) launch. Você já pode executar consultas nessa região.
-
Agora é possível usar o formulário Create Table From S3 bucket data (Criar tabela a partir de dados do bucket do S3) para definir o esquema da tabela em massa. No editor de consultas, escolha Criar, Dados do bucket do S3 e Adicionar colunas em massa na seção Detalhes da coluna.
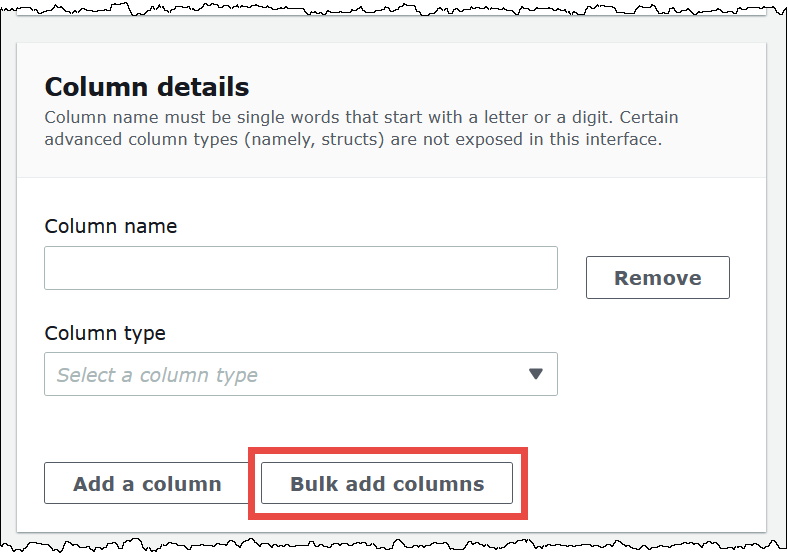
Digite os pares de nome e valor na caixa de texto e escolha Add.
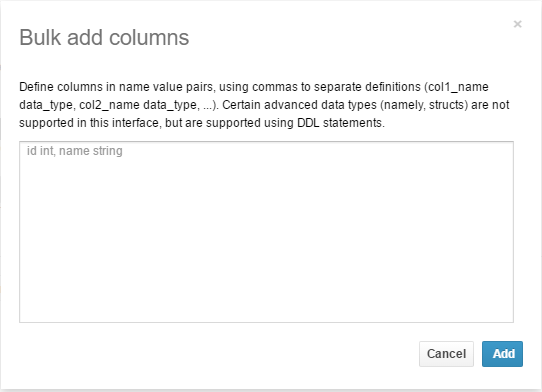
Melhorias
-
Melhorada a performance em tabelas Parquet grandes.
