本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
本節提供以 Amazon Rekognition Image 和 Amazon Rekognition Video 來偵測映像和影片內標籤的資訊。
標籤或標記是指映像中的物件或概念 (包括場景和動作),根據映像或影片的內容決定。例如,熱帶海灘上的人物映像可能包含諸如棕櫚樹 (物件)、沙灘 (場景)、跑步 (動作) 和戶外 (概念) 等標籤。
Rekognition 標籤偵測操作支援的標籤
注意
Amazon Rekognition 根據特定映像中人物的外觀進行性別二元制 (男人、女人、女孩等) 預測。這種預測不是為了對一個人的性別身份進行分類而設計,不應使用 Amazon Rekognition 做出該判定。比方說,可能将出于扮演角色需要戴假长发和耳環的男性演員預測為女性。
使用 Amazon Rekognition 進行性別二元論預測最適合用於需要分析彙總性別分佈統計資料而無需識別特定使用者的使用案例。例如,在社交媒體平台上,女性使用者與男性相比的百分比。
我們不建議採用性別二元論預測來制定會影響個人權利、隱私或服務存取的決策。
Amazon Rekognition 傳回英文標籤。您可以使用 Amazon Translate
下圖顯示呼叫操作的順序,取決於您使用 Amazon Rekognition Image 或 Amazon Rekognition Video 操作的目標:
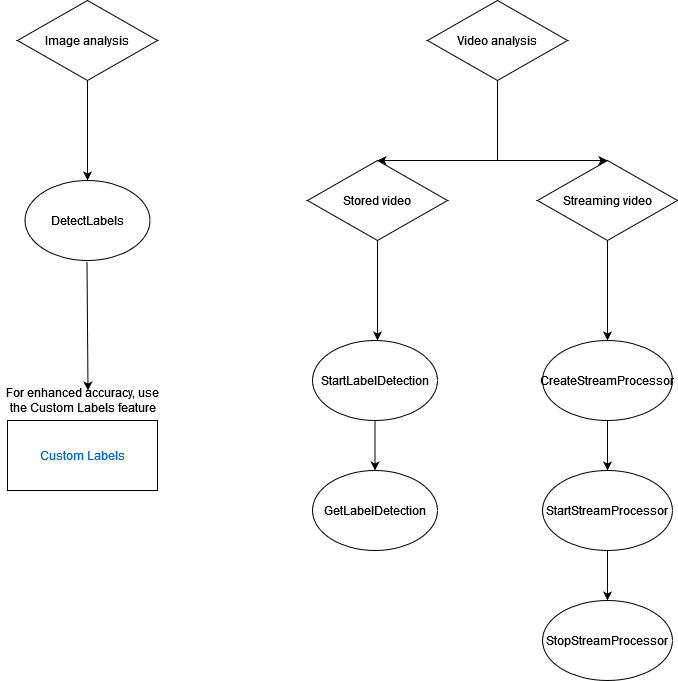
標籤回應物件
週框方塊
Amazon Rekognition Image 和 Amazon Rekognition Video 可以傳回常見物件標籤的週框方塊,例如人員、汽車、家具、服飾或寵物。對於較不常用的物件標籤,系統不會傳回週框方塊資訊。您可以使用週框方塊,來找出物件在映像中的確切位置、已偵測到物件的計數實例,或使用週框方塊維度測量物件的大小。
例如,在以下映像中,Amazon Rekognition Image 能夠偵測人物、滑板、停好的車或其他資訊。Amazon Rekognition Image 也會傳回偵測到的人員的邊界外框,以及其他偵測到的物件 (例如汽車和車輪)。

可信度分數
Amazon Rekognition Video 和 Amazon Rekognition Image 提供了一個百分比分數,以表示 Amazon Rekognition 每個偵測到的標籤的準確性的可信度是多少。
父系
Amazon Rekognition Image 和 Amazon Rekognition Video 使用祖先標籤的階層分類法對標籤進行分類。例如,走在路上的人員可能會被偵測為行人。行人的父標籤為人員。在回應中會傳回這兩個標籤。系統會傳回所有上階標籤,而且指定的標籤包含一個清單,其中列出其父標籤和其他上階標籤。例如,祖父和曾祖父標籤 (如果它們存在的話)。您可以使用父標籤來建置相關標籤的群組,並允許在一或多個映像中查詢類似標籤。例如,查詢所有車輛可能從某個映像傳回汽車,而從另一個映像傳回摩托車。
類別
Amazon Rekognition Image 和 Amazon Rekognition Video 傳回的有關標籤類別資訊。標籤是根據常用功能和環境 (例如「車輛和汽車」和「食品和飲料」) 將單個標籤組合在一起的類別的一部分。標示品類可以是父品類的子品類。
Aliases
除了傳回標籤之外,Amazon Rekognition Image 和 Amazon Rekognition Video 還會傳回與該標籤相關聯的任何別名。別名是具有相同含義的標籤或與傳回的主標籤可以在視覺上互換的標籤。例如,「手機」是「移動電話」的別名。
在舊版中,Amazon Rekognition Image 會在包含「手機」的主要標籤名稱清單中傳回「行動電話」等別名。Amazon Rekognition Image 目前在主標籤名稱清單中名為「別名」和「移動電話」的字段傳回「手機」。如果您的應用程式依賴於舊版 Rekognition 傳回的結構,您可能需要將映像或影片標籤偵測作業傳回的目前回應轉換為先前的回應結構,其中所有標籤和別名都會作為主要標籤傳回。
如果您需要將目前的回應從 DetectLabel API (用於映像中的標籤偵測) 轉換為先前的回應結構,請參閱 轉換 DetectLabels 回應 中的程式碼範例。
如果您需要將 GetLabelDetection API 的目前回應 (用於儲存影片中的標籤偵測) 轉換為先前的回應結構,請參閱 轉換 GetLabelDetection 回應 中的程式碼範例。
映像屬性
Amazon Rekognition Image 會傳回整個映像的映像品質 (銳利度、亮度和對比度) 的相關資訊。映像的前景和背景也會傳回銳利度和亮度。「映像屬性」也可以用於偵測整個映像、前景、背景和具有邊界方框之物件的主要顏色。

以下是針對所進行映像執行的 DetectLabel 作業回應中包含的 ImageProperties 資料範例:
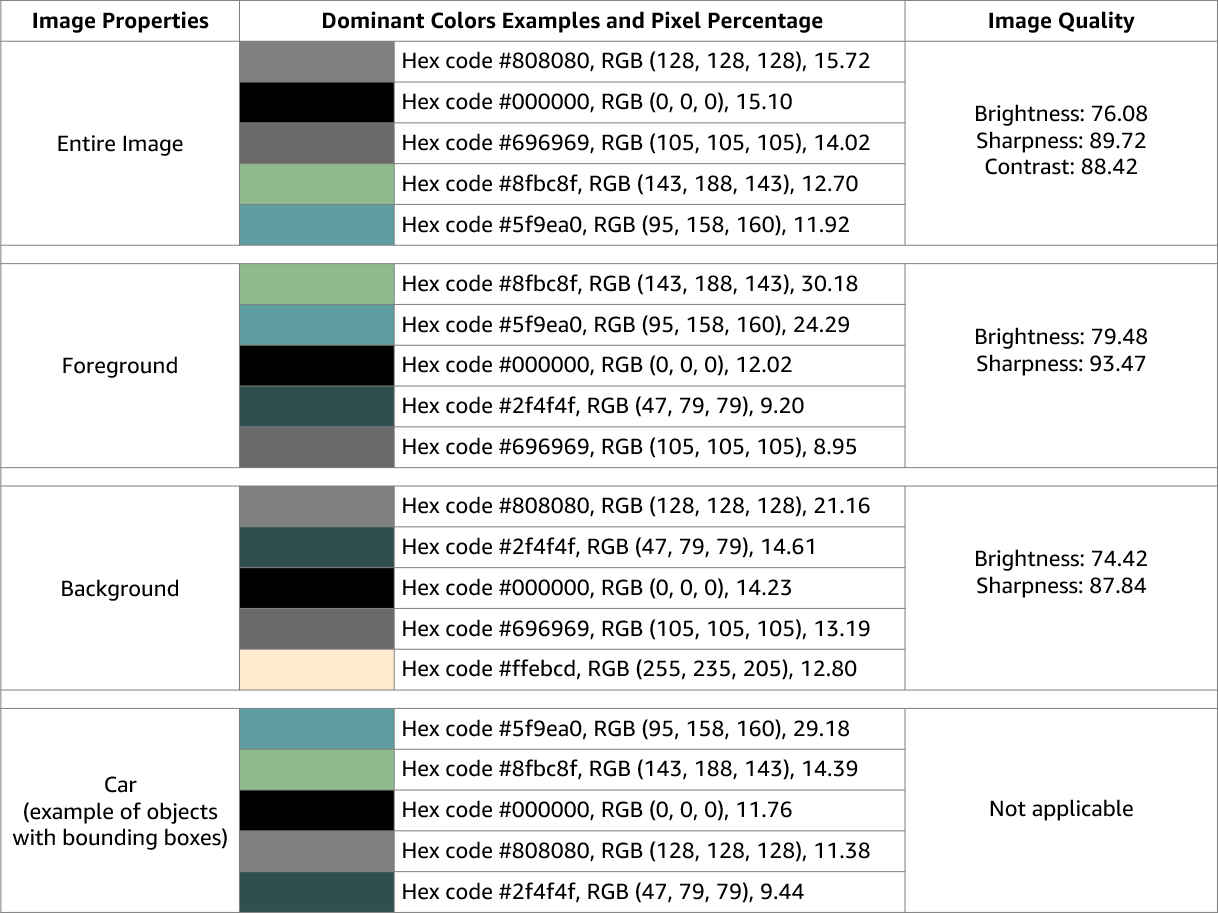
映像屬性不適用於 Amazon Rekognition Video。
模型版本控制
Amazon Rekognition Image 和 Amazon Rekognition Video 都會傳回用來在映像或已儲存影片中偵測標籤的標籤偵測模型版本。
包含性或排斥性的篩選
您可以篩選 Amazon Rekognition Image 和 Amazon Rekognition Video 標籤偵測操作傳回的結果。透過提供標籤和類別的篩選條件來篩選結果。標籤篩選器可以是包含性或排斥性的。
請參閱 在映像中偵測標籤 有關由 DetectLabels 獲得的結果篩選的更多資訊。
請參閱 偵測影片中的標籤 有關由 GetLabelDetection 獲得的結果篩選的更多資訊。
排序和彙總結果
從某些 Amazon Rekognition Video 操作取得的結果可以根據時間戳記和影片區段進行排序和彙總。使用 GetLabelDetection 或 GetContentModeration 分別擷取標籤偵測或內容管制操作的結果時,您可以使用 SortBy 和 AggregateBy 引數來指定傳回結果的方式。您可以將 SortBy 與 TIMESTAMP 或 NAME (標籤名稱) 搭配使用,並將 TIMESTAMPS 或 SEGMENTS 與 AggregateBy 引數搭配使用。
