Prácticas recomendadas para consultar y analizar datos en DynamoDB
En esta sección se explican algunas prácticas recomendadas relativas a las operaciones Query y Scan en Amazon DynamoDB.
Consideraciones sobre el rendimiento de los análisis
En general, las operaciones Scan son menos eficientes que otras operaciones de DynamoDB. Una operación Scan siempre analiza toda la tabla o el índice secundario. Luego filtra los valores para obtener el resultado deseado, para lo cual se agrega el paso adicional de eliminar los datos del conjunto de resultados.
Si es posible, evite usar la operación Scan en una tabla o un índice de gran tamaño con un filtro que elimine muchos resultados. Además, a medida que la tabla o el índice aumentan de tamaño, la operación Scan resulta más lenta. La operación Scan examina cada elemento para comprobar si presenta los valores solicitados y permite utilizar el rendimiento aprovisionado para una tabla o un índice grandes en una sola operación. Para lograr tiempos de respuesta más breves, diseñe las tablas o los índices de tal forma que las aplicaciones puedan utilizar Query en lugar de Scan. (Para las tablas, considere también la posibilidad de usar las API GetItem y BatchGetItem).
De forma alternativa, puede diseñar la aplicación para usar operaciones Scan de tal forma que minimicen el impacto en la tasa de solicitudes. Esto puede incluir el modelado cuando sería más eficiente utilizar un índice secundario global en lugar de una operación Scan. Encontrará más información sobre este proceso en el siguiente vídeo.
Evitar los picos repentinos en la actividad de lectura
Al crear una tabla, establece los requisitos de unidades de capacidad de lectura y escritura. Para las lecturas, las unidades de capacidad se expresan como el número de solicitudes de consistencia alta de lectura de datos de 4 KB por segundo. En el caso de lecturas eventualmente consistentes, una unidad de capacidad de lectura es de dos solicitudes de lectura de 4 KB por segundo. Una operación Scan realiza lecturas eventualmente consistentes de forma predeterminada y puede devolver hasta 1 MB (una página) de datos. Por lo tanto, una única solicitud de Scan puede consumir (tamaño de página de 1 MB /tamaño de elemento 4 KB)/2 (lecturas eventualmente consistentes) = 128 operaciones de lectura. Si desea solicitar lecturas fuertemente consistentes en su lugar, la operación Scan consumiría el doble de rendimiento aprovisionado, es decir, 256 operaciones de lectura.
Esto representa un pico repentino de uso en comparación con la capacidad de lectura configurada para la tabla. Este uso de unidades de capacidad en un análisis impide que otras solicitudes más importantes para la misma tabla utilicen las unidades de capacidad disponibles. En consecuencia, es probable que obtenga una excepción ProvisionedThroughputExceeded para esas solicitudes.
El problema no reside exclusivamente al aumento repentino de unidades de capacidad que Scan utiliza. El análisis probablemente consuma todas sus unidades de capacidad en la misma partición, porque las solicitudes de análisis leen elementos que se encuentran contiguos en la partición. Esto significa que la solicitud se dirige a la misma partición, con lo que provoca que se consuman todas sus unidades de capacidad e impone una limitación controlada que impide que la partición reciba otras solicitudes. Si la solicitud de lectura de datos se distribuye entre varias particiones, la operación no impone una limitación controlada a una partición determinada.
En el siguiente diagrama se ilustra el impacto de un pico repentino del uso de unidades de capacidad que provocan las operaciones Query y Scan, así como su impacto en las demás solicitudes para la misma tabla.
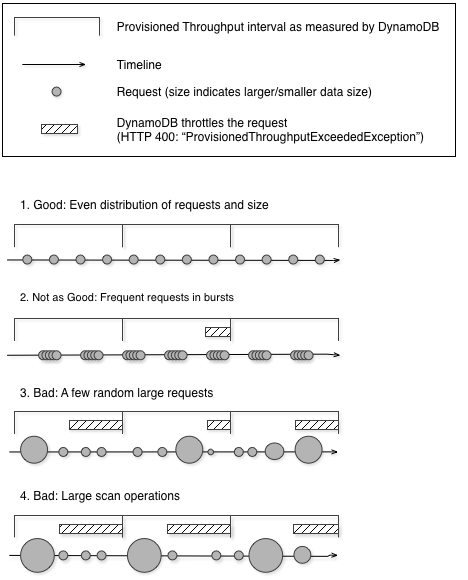
Como se muestra aquí, el pico de uso puede afectar el rendimiento aprovisionado de la tabla de varias maneras:
-
Bueno: distribución uniforme de las solicitudes y el tamaño
-
No tan bueno: solicitudes frecuentes en ráfagas
-
Malo: algunas solicitudes grandes aleatorias
-
Malo: operaciones de análisis grandes
En lugar de utilizar una gran operación Scan, puede utilizar las técnicas siguientes para minimizar el impacto de un examen en el desempeño provisionado de una tabla.
-
Reducir el tamaño de la página
Dado que una operación de análisis lee una página completa (de forma predeterminada, 1 MB), puede reducir el impacto de la operación de análisis configurando un tamaño de página menor. La operación
Scanproporciona el parámetro Limit (Límite) que se puede utilizar para establecer el tamaño de página de la solicitud. Cada solicitudQueryoScanque tiene un tamaño de página menor utiliza menos operaciones de lectura y crea una "pausa" entre ellas. Por ejemplo, suponga que cada elemento es de 4 KB y establece el tamaño de página en 40 elementos. Una solicitudQueryconsumiría solo 20 operaciones de lectura eventualmente consistentes o 40 operaciones de lectura fuertemente consistentes. Un mayor número de operacionesQueryoScanpermitiría que las demás solicitudes esenciales se realizasen correctamente sin que se aplicara la limitación controlada. -
Aislar las operaciones de análisis
DynamoDB se ha diseñado para facilitar la escalabilidad. En consecuencia, una aplicación puede crear tablas para fines distintos e, incluso, duplicar contenido entre varias de ellas. Si desea realizar análisis en una tabla que no recibe tráfico "esencial". Algunas aplicaciones controlan esta carga rotando el tráfico cada hora entre dos tablas; una para el tráfico esencial y otra de registro. Las demás aplicaciones pueden efectuar este control realizando cada escritura en dos tablas: una tabla "esencial" y otra tabla "duplicada".
Configure la aplicación de modo que repita las solicitudes que reciban un código de respuesta que indique que se ha superado el rendimiento aprovisionado. O bien, aumente el rendimiento aprovisionado para su tabla mediante la operación UpdateTable. Si la carga de trabajo presenta picos temporales que pueden provocar que el rendimiento supere ocasionalmente el nivel aprovisionado, repita la solicitud con retroceso exponencial. Para obtener más información sobre cómo implementar el retardo exponencial, consulte Reintentos de error y retroceso exponencial.
Aprovechamiento de los análisis paralelos
Muchas aplicaciones pueden beneficiarse si se usan las operaciones Scan en paralelo, en lugar de análisis secuenciales. Por ejemplo, una aplicación que procesa una gran tabla de datos históricos puede llevar a cabo un análisis en paralelo mucho más rápidamente que uno secuencial. Varios subprocesos de trabajo contenidos en un proceso de "barrido" en segundo plano podrían analizar una tabla con menor prioridad sin afectar al tráfico de producción. En todos estos ejemplos, se utiliza una operación Scan de tal forma que no priva a las demás aplicaciones de los recursos de desempeño provisionado.
Aunque los análisis en paralelo pueden ser beneficiosos, pueden suponer una demanda excesiva del rendimiento aprovisionado. Con un análisis paralelo, la aplicación tiene varios trabajadores que están ejecutando operaciones Scan simultáneas. Esto puede consumir rápidamente toda la capacidad de lectura aprovisionada de su tabla. En ese caso, las demás aplicaciones que necesiten obtener acceso a la tabla podrían sufrir una limitación controlada que se lo impida.
Un examen en paralelo puede ser la elección adecuada si se cumplen las siguientes condiciones:
El tamaño de la tabla es de 20 GB o mayor.
El rendimiento de lectura aprovisionado de la tabla no se está utilizando en su totalidad.
Las operaciones
Scansecuenciales son demasiado lentas.
Elección de TotalSegments
La configuración más idónea de TotalSegments depende de los datos concretos, de los ajustes de rendimiento aprovisionado de la tabla y de los requisitos de rendimiento. Probablemente deba experimentar para lograr los resultados deseados. Recomendamos comenzar por una proporción sencilla; por ejemplo, un segmento por cada 2 GB de datos. Por ejemplo, en el caso de una tabla de 30 GB, podría establecer TotalSegments en 15 (30 GB/2 GB). En este caso, la aplicación utilizaría 15 procesos de trabajo, cada uno de los cuales analizaría un segmento diferente.
También puede elegir un valor de TotalSegments que se base en los recursos del cliente. Puede establecer TotalSegments en cualquier número comprendido entre 1 y 1 000 000. DynamoDB le permitirá analizar esa cantidad de segmentos. Por ejemplo, si el cliente limita el número de subprocesos que se pueden ejecutar de forma simultánea, puede aumentar gradualmente el valor de TotalSegments hasta obtener el mejor rendimiento de Scan con la aplicación.
Monitoree los exámenes en paralelo para optimizar la utilización del rendimiento aprovisionado, además de asegurarse de no privar de recursos a las demás aplicaciones. Aumente el valor de TotalSegments si no se consume todo el rendimiento aprovisionado pero las solicitudes Scan siguen siendo objeto de una limitación controlada. Reduzca el valor de TotalSegments si las solicitudes Scan consumen más desempeño provisionado del que desea utilizar.
