Amazon Forecast ya no está disponible para nuevos clientes. Los clientes actuales de Amazon Forecast pueden seguir utilizando el servicio con normalidad. Más información
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Algoritmo DeepAR+
Amazon Forecast DeepAr+ es un algoritmo de aprendizaje supervisado para pronosticar series temporales escalares (unidimensionales) mediante redes neuronales recurrentes (). RNNs Los métodos de previsión clásicos, como el modelo autorregresivo integrado de media móvil (ARIMA) o el suavizamiento exponencial (ETS), encajan en un solo modelo para cada serie temporal individual y, a continuación, utilizan ese modelo para extrapolar la serie temporal en el futuro. En muchas aplicaciones, sin embargo, disponen de muchas series temporales similares en un conjunto de unidades transversales. Estas agrupaciones de series temporales exigen productos, cargas de servidor y solicitudes de páginas web diferentes. En este caso, puede ser beneficioso entrenar un modelo único de forma conjunta en todas las series temporales. DeepAR+toma este enfoque. Cuando el conjunto de datos contiene cientos de series temporales de características, el algoritmo DeepAR+ supera los métodos ARIMA y ETS estándar. También puede utilizar el modelo entrenado para generar previsiones de series temporales nuevas que son similares a las que se han entrenado.
Cuadernos de Python
Para obtener una step-by-step guía sobre el uso del algoritmo DeepAr+, consulta Cómo empezar a
Cómo funciona DeepAR+
Durante el entrenamiento, DeepAR+ utiliza un conjunto de datos de entrenamiento y un conjunto de datos de pruebas. Utiliza el conjunto de datos de pruebas para evaluar el modelo entrenado. En general, los conjuntos de datos de entrenamiento y de prueba no tienen que contener el mismo conjunto de series temporales. Puede utilizar un modelo capacitado en un determinado conjunto de capacitación para generar las previsiones para el futuro de las series temporales en el conjunto de capacitación y para otras series temporales. Tanto los conjuntos de datos de entrenamiento como de pruebas se componen de series temporales objetivo (preferiblemente más de una). Opcionalmente, se pueden asociar a un vector de series temporales de entidades y a un vector de características categóricas (para obtener más información, consulte la Interfaz de entrada/salida DeepAR en SageMaker la Guía para desarrolladores de IA). En el siguiente ejemplo, se muestra su funcionamiento en un elemento de un conjunto de datos de entrenamiento indexado con i. El conjunto de entrenamiento se compone de una serie temporal objetivo zi,t y dos series temporales de características asociadas xi,1,t y xi,2,t.
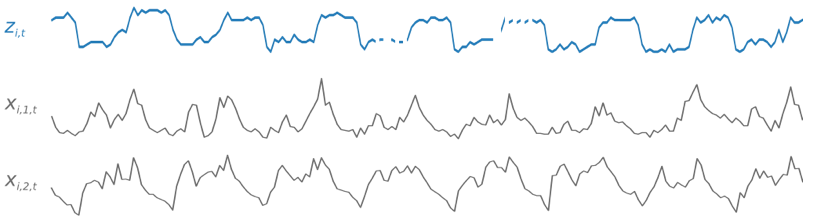
La serie temporal objetivo puede contener valores que faltan (indicados en los gráficos por las interrupciones en la serie temporal). DeepAR+ solo admite series temporales de características que son conocidas en el futuro. Esto le permite ejecutar escenarios "hipotéticos" contrafactuales. Por ejemplo, "¿Qué ocurre si puedo cambiar el precio de un producto de algún modo?"
Cada serie temporal de destino también puede asociarse a un número de características categóricas. Puede utilizarlas para codificar que una serie temporal pertenece a determinadas agrupaciones. Usar características categóricas permite que el modelo aprenda el comportamiento típico de dichas agrupaciones, lo que puede aumentar la precisión. Para realizar la implementación, los modelos obtienen información de un vector de integración de cada grupo que captura las propiedades comunes de todas las series temporales del grupo.
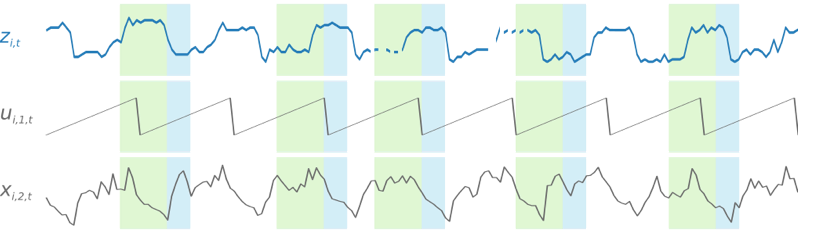
Para facilitar patrones de aprendizaje que dependan del tiempo, como picos durante fines de semana, DeepAR+ crea automáticamente series temporales basándose en la granularidad de las series temporales. Por ejemplo, DeepAR+ crea dos series temporales de características (día del mes y día del año) a una frecuencia de serie temporal semanal. Utiliza estas series temporales de características derivadas junto con la serie temporal de características personalizadas que proporcione durante el entrenamiento y la inferencia. En el siguiente ejemplo se muestran dos características de la serie temporal derivada: ui,1,t representa la hora del día y ui,2,t el día de la semana.

DeepAR+ incluye automáticamente estas series temporales de características basándose en la frecuencia de los datos y el tamaño de los datos de entrenamiento. En la siguiente tabla se muestran las características que se pueden derivar para cada frecuencia temporal básica admitida.
| Frecuencia de la serie temporal | Características derivadas |
|---|---|
| Minuto | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| Hora | hour-of-day, day-of-week, day-of-month, day-of-year |
| Día | day-of-week, day-of-month, day-of-year |
| Semana | week-of-month, week-of-year |
| Mes | month-of-year |
Un modelo DeepAR+ se entrena realizando muestreos aleatorios de varios ejemplos de entrenamiento en cada una de las series temporales del conjunto de datos de entrenamiento. Cada ejemplo de capacitación se compone de un par de ventanas adyacentes de contexto y predicción con longitudes predefinidas fijas. El hiperparámetro context_length controla hasta qué punto del pasado puede ver la red y el parámetro ForecastHorizon controla hasta qué punto del futuro se pueden hacer predicciones. Durante el entrenamiento, Amazon Forecast no tiene en cuenta elementos del conjunto de datos de entrenamiento con series temporales más cortas que la longitud de predicción especificada. En el siguiente ejemplo, se presentan cinco muestras con una longitud de contexto de 12 horas (resaltado en verde) y una longitud de predicción de 6 horas (resaltado en azul), extraídas del elemento i. En aras de la brevedad, hemos excluido las series temporales de características xi,1,t y ui,2,t.
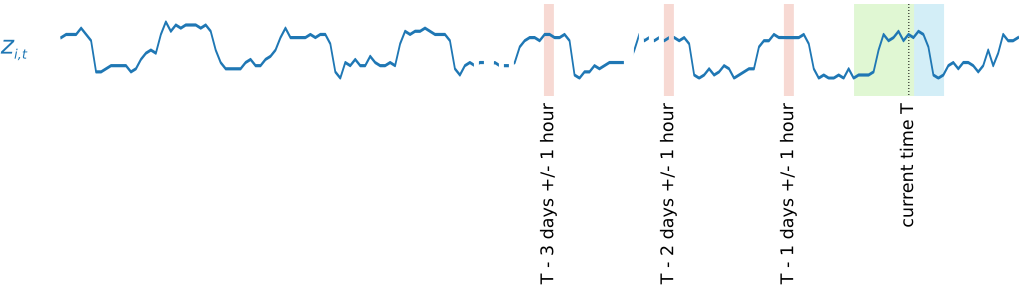
Para capturar los patrones de estacionalidad, DeepAR+ también incluye automáticamente valores atrasados (periodos pasados) procedentes de series temporales de destino. En nuestro ejemplo, que tiene muestras tomadas con una frecuencia de una hora, para cada índice temporal t = T, el modelo expone los valores de zi,t, que se produjeron aproximadamente hace uno, dos y tres días (resaltado en rosa).
Para la inferencia, el modelo entrenado toma como entrada la serie temporal objetivo, que puede haberse usado o no durante el entrenamiento y prevé una distribución de la probabilidad para los siguientes valores de ForecastHorizon. Dado que DeepAR+ se entrena en todo el conjunto de datos, la previsión tiene en cuenta los patrones aprendidos de series temporales similares.
Para obtener información sobre las operaciones matemáticas que se encuentran detrás de DeepAR+, consulte DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
Hiperparámetros de DeepAR+
En la siguiente tabla se enumeran los hiperparámetros que puede usar en el algoritmo de DeepAR+. Los parámetros en negrita participan en la optimización de hiperparámetros (HPO).
| Nombre del parámetro | Descripción |
|---|---|
context_length |
El número de puntos de tiempo que el modelo lee antes de realizar la predicción. El valor de este parámetro debe ser básicamente el mismo que
|
epochs |
Número máximo de iteraciones que consultar en los datos de capacitación. El valor óptimo depende del tamaño de los datos y de la tasa de aprendizaje. Los conjuntos de datos más pequeños y las velocidades aprendizaje más lentas requieren más fechas de inicio ("epoch") para lograr buenos resultados.
|
learning_rate |
La tasa de aprendizaje utilizada en la capacitación.
|
learning_rate_decay |
La velocidad a la que disminuye el aprendizaje. Como mucho, la tasa de aprendizaje se reduce las veces indicadas en
|
likelihood |
El modelo genera una previsión de probabilidad y puede proporcionar cuantiles de la distribución y devolver muestras. En función de sus datos, elija una probabilidad apropiada (modelo de ruido) que se utilice para estimaciones de incertidumbre. Valores válidos
|
max_learning_rate_decays |
El número máximo de reducciones de tasa de aprendizaje que debe producirse.
|
num_averaged_models |
En DeepAR+, una trayectoria de entrenamiento puede encontrar varios modelos. Cada modelo podría tener diferentes puntos fuertes y débiles de previsión. DeepAR+ puede calcular la media de los comportamientos del modelo para aprovechar los puntos fuertes de todos los modelos.
|
num_cells |
El número de celdas que usar en cada capa oculta de la RNN.
|
num_layers |
El número de capas ocultas en la RNN.
|
Ajustar modelos DeepAR+
Para ajustar modelos DeepAR+ de Amazon Forecast, siga estas recomendaciones para optimizar el proceso de entrenamiento y la configuración de hardware.
Prácticas recomendadas para la optimización de procesos
Para lograr los mejores resultados, siga estas recomendaciones:
-
Salvo cuando se dividan los conjuntos de datos de entrenamiento y pruebas, proporcione siempre series temporales completas para el entrenamiento y las pruebas, y cuando se llame al modelo para inferencias. Independientemente de cómo se establezca
context_length, no divida la serie temporal ni proporcione solo una parte de ella. El modelo utilizará puntos de datos situados más atrás quecontext_lengthpara la característica de valores con retraso. -
Para el ajuste de modelos, puede dividir el conjunto de datos en conjuntos de datos de entrenamiento y pruebas. En un escenario de evaluación típico, debe probar el modelo en la misma serie temporal utilizada en el entrenamiento, pero en los puntos de tiempo de
ForecastHorizonfuturos, inmediatamente después del último punto de tiempo visible durante el entrenamiento. Para crear conjuntos de datos de entrenamiento y pruebas que se ajusten a estos criterios, utilice el conjunto de datos completo (todos los de la serie temporal) como un conjunto de datos de pruebas y elimine los últimos puntos deForecastHorizonde cada serie temporal para el entrenamiento. De esta forma, durante el entrenamiento, el modelo no ve los valores objetivo de los puntos de tiempo en los que se evalúa durante las pruebas. En esta fase de pruebas, se conservan los últimos puntos deForecastHorizonde cada serie temporal de conjunto de datos de pruebas y se genera una predicción. La previsión se comparará después con los valores reales de los últimos puntos deForecastHorizon. Puede crear evaluaciones más complejas repitiendo series temporales varias veces en el conjunto de datos de pruebas, pero cortándolas en diferentes puntos finales. Esto produce métricas de precisión que se promedian sobre las múltiples previsiones de diferentes puntos de tiempo. -
Evite utilizar valores muy grandes (> 400) para
ForecastHorizon, ya que esto ralentiza el modelo y hace que resulte menos preciso. Si desea realizar previsiones en el futuro, considere agregar a una frecuencia superior. Por ejemplo, utilice5minen lugar de1min. -
Debido a los retrasos, el modelo puede retroceder más en el tiempo que
context_length. Por tanto, no tiene que establecer este parámetro en un valor grande. Un buen punto inicial para este parámetro es el mismo valor queForecastHorizon. -
Entrene modelos DeepAR+ con tantas series temporales como sea posible. Aunque un modelo DeepAR+ entrenado en una sola serie temporal ya podría funcionar bien, los métodos de previsión estándar como ARIMA o ETS podrían ser más precisos y estar más adaptados a este caso de uso. DeepAR+ empieza a superar los métodos estándar cuando el conjunto de datos contiene cientos de series temporales de características. En la actualidad, DeepAR+ requiere que el número total de observaciones disponibles en todas las series temporales de entrenamiento, sea al menos 300.
