Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comment fonctionne Iceberg
Iceberg suit les fichiers de données individuels dans une table plutôt que dans des répertoires. Ainsi, les rédacteurs peuvent créer des fichiers de données sur place (les fichiers ne sont ni déplacés ni modifiés). De plus, les rédacteurs ne peuvent ajouter des fichiers à la table que dans le cadre d'un commit explicite. L'état de la table est conservé dans les fichiers de métadonnées. Toutes les modifications apportées à l'état de la table créent un nouveau fichier de métadonnées qui remplace automatiquement les anciennes métadonnées. Le fichier de métadonnées de table suit le schéma de la table, la configuration du partitionnement et d'autres propriétés.
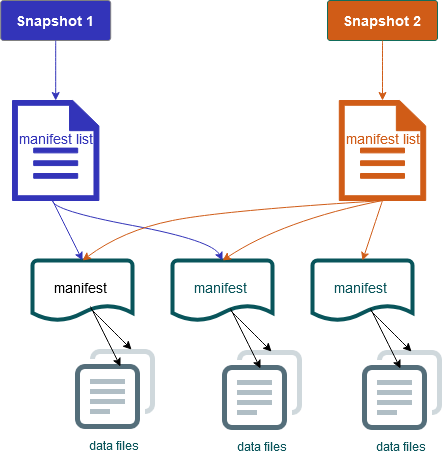
Il inclut également des instantanés du contenu du tableau. Chaque instantané est un ensemble complet de fichiers de données figurant dans le tableau à un moment donné. Les instantanés sont répertoriés dans le fichier de métadonnées, mais les fichiers d'un instantané sont stockés dans des fichiers manifestes distincts. Les transitions atomiques d'un fichier de métadonnées de table à l'autre permettent d'isoler les instantanés. Les lecteurs utilisent l'instantané actuel lorsqu'ils ont chargé les métadonnées de la table. Les lecteurs ne sont pas affectés par les modifications tant qu'ils n'ont pas actualisé et sélectionné un nouvel emplacement de métadonnées. Les fichiers de données des instantanés sont stockés dans un ou plusieurs fichiers manifestes qui contiennent une ligne pour chaque fichier de données de la table, ses données de partition et ses métriques. Un instantané est l'union de tous les fichiers contenus dans ses manifestes. Les fichiers manifestes peuvent également être partagés entre les instantanés afin d'éviter de réécrire des métadonnées peu modifiées.
Schéma d'instantané d'Iceberg
Iceberg offre les fonctionnalités suivantes :
-
Prend en charge les transactions ACID et les voyages dans le temps dans votre lac de données Amazon S3.
-
Les nouvelles tentatives de validation bénéficient des avantages en termes de performances d'une simultanéité optimiste
. -
La résolution des conflits au niveau des fichiers entraîne une forte simultanéité.
-
Avec des statistiques min-max par colonne dans les métadonnées, vous pouvez ignorer des fichiers, ce qui améliore les performances des requêtes sélectives.
-
Vous pouvez organiser les tables selon des configurations de partition flexibles, l'évolution des partitions permettant de mettre à jour les schémas de partition. Les requêtes et les volumes de données peuvent alors changer sans recourir à des répertoires physiques.
-
Prend en charge l'évolution des schémas
et leur application. -
Les tables Iceberg agissent comme des puits idempotents et des sources rejouables. Cela permet le streaming et le support par lots avec des pipelines uniques. Les récepteurs idempotents suivent les opérations d'écriture réussies dans le passé. Par conséquent, le récepteur peut à nouveau demander des données en cas de panne et supprimer des données si elles ont été envoyées plusieurs fois.
-
Consultez l'historique et le lignage, y compris l'évolution des tables, l'historique des opérations et les statistiques pour chaque validation.
-
Migrez depuis un jeu de données existant avec un choix de format de données (Parquet, ORC, Avro) et de moteur d'analyse (Spark, Trino, PrestoDB, Flink, Hive).
