Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Note
Amazon Neptune envoie des métriques CloudWatch uniquement lorsqu'elles ont une valeur différente de zéro.
Pour toutes les métriques Neptune, la granularité d'agrégation est de cinq minutes.
Métriques Neptune CloudWatch
Le tableau suivant répertorie les CloudWatch mesures prises en charge par Neptune.
Note
Toutes les métriques cumulées sont réinitialisées chaque fois que le serveur redémarre, que ce soit pour des raisons de maintenance, de redémarrage ou de reprise après un incident.
| Métrique | Description |
|---|---|
|
Quantité totale de stockage de sauvegarde, en octets, utilisée pour prendre en charge la fenêtre de rétention de sauvegarde du cluster de bases de données Neptune. Incluse dans le total indiqué par la métrique |
|
Pourcentage de demandes traitées par le cache de tampon. Cette métrique peut être utile pour diagnostiquer la latence des requêtes, car les erreurs de cache induisent une latence importante. Si le taux d'accès au cache est inférieur à 99,9 %, envisagez de mettre à niveau le type d'instance afin de mettre en cache davantage de données en mémoire. |
|
Pour un réplica en lecture, durée du retard lors de la réplication des mises à jour à partir de l'instance principale, en millisecondes. |
|
Durée maximale du retard entre l'instance principale et chaque instance de base de données Neptune du cluster de bases de données, en millisecondes. |
|
Durée minimale du retard entre l'instance principale et chaque instance de base de données Neptune du cluster de bases de données, en millisecondes. |
|
Nombre de crédits CPU accumulés par une instance, rapporté, rapporté par intervalles de 5 minutes. Cette métrique vous permet de déterminer combien de temps une instance de base de données peut fonctionner en rafale au-delà de son niveau de performance de départ à un débit donné. |
|
Nombre de crédits CPU consommés au cours de la période spécifiée, rapporté par intervalles de 5 minutes. Cette métrique mesure le temps pendant lequel le matériel physique a CPUs été utilisé pour traiter les instructions par le virtuel CPUs alloué à l'instance de base de données. |
|
Nombre de crédits excédentaires dépensés par une instance illimitée lorsque la valeur |
|
Le nombre de crédits excédentaires dépensés qui ne sont pas remboursés par les crédits CPU gagnés et qui entraînent des frais supplémentaires. |
|
Pourcentage d’utilisation de la CPU. |
|
Temps d'exécution de l'instance, en secondes. |
|
Quantité de mémoire vive disponible, en octets. |
|
Nombre d'octets de données de journalisation transférés de la base de données principale Région AWS à la base secondaire Région AWS dans une base de données globale Neptune. |
|
Nombre d'opérations d'E/S d'écriture répliquées depuis la Région AWS principale de la base de données globale vers le volume de cluster d'une Région AWS secondaire. Les calculs de facturation pour chaque cluster de bases de données dans une base de données globale Neptune utilisent la métrique |
|
Retard du cluster secondaire en millisecondes par rapport au cluster principal pour les transactions utilisateur et système. |
|
Nombre d'erreurs côté client par seconde dans les traversées Gremlin. |
|
Nombre d'erreurs côté serveur par seconde dans les traversées Gremlin. |
|
Nombre de demandes par seconde adressées au moteur Gremlin. |
|
Le nombre de WebSocket connexions ouvertes à Neptune. |
|
Nombre d'erreurs côté client par seconde à partir des demandes du chargeur. |
|
Nombre de demandes du chargeur par seconde. |
|
Nombre d'erreurs côté serveur du chargeur par seconde. |
|
Nombre de requêtes en attente dans l'exécution de la file d'attente en entrée. Neptune commence à limiter les demandes lorsqu'elles dépassent la capacité maximale de la file d'attente. |
|
Applicable uniquement à une instance de base de données ou à un cluster de bases de données Neptune sans serveur. Au niveau de l'instance, indique un pourcentage calculé comme le nombre d'unités de capacité Neptune (NCUs) actuellement utilisées par l'instance en question, divisé par le paramètre de capacité NCU maximale du cluster. Une NCU, ou unité de capacité Neptune, se compose de 2 Gio (gibioctet) de mémoire (RAM), en plus de la capacité du processeur virtuel (vCPU) et du réseau associés. Au niveau du cluster, |
|
Quantité de débit réseau reçue des clients et transmise à ces derniers par chaque instance du cluster de bases de données Neptune, en octets par seconde. Ce débit n'inclut pas le trafic réseau entre les instances du cluster de bases de données et le volume de cluster. |
|
Quantité de débit réseau sortant transmise aux clients par chaque instance du cluster de bases de données Neptune, en octets par seconde. Ce débit n'inclut pas le trafic réseau entre les instances du cluster de bases de données et le volume de cluster. |
NumIndexDeletesPerSec |
Nombre de suppressions dans des index individuels. Les suppressions de chaque index sont comptées individuellement. Cela inclut les suppressions qui peuvent être annulées si une requête rencontre une erreur. |
NumIndexInsertsPerSec |
Nombre d'encarts dans les index individuels. Les insertions dans chaque index sont comptées séparément. Cela inclut les insertions qui peuvent être annulées si une requête rencontre une erreur. |
NumIndexReadsPerSec |
Nombre de relevés numérisés à partir de n'importe quel index. Tout modèle d'accès commence par une recherche dans un index et la lecture de toutes les instructions correspondantes. Une augmentation de cette métrique peut entraîner une augmentation de la latence des requêtes ou de l'utilisation du processeur. |
|
Le nombre d'erreurs du OpenCypher client par seconde. |
|
Le nombre de OpenCypher demandes par seconde. |
|
Le nombre d'erreurs OpenCypher du serveur par seconde. |
|
Le nombre de demandes mises en file d'attente par seconde. |
|
Nombre de visites dans le cache des résultats de Gremlin. |
|
Nombre de caches de résultats manquants dans le cache de résultats Gremlin. |
|
Nombre de transactions validées par seconde avec succès. |
|
Nombre de transactions ouvertes sur le serveur par seconde. |
|
Pour les requêtes d'écriture, nombre de transactions par seconde restaurées sur le serveur en raison d'erreurs. Pour les requêtes en lecture seule, cette métrique est égale au nombre de transactions en lecture seule effectuées par seconde. |
NumUndoPagesPurged |
Cette métrique indique le nombre de lots purgés. Cette métrique est un indicateur des progrès réalisés en matière de purge. La valeur concerne 0 les instances de lecteur et la métrique ne s'applique qu'à l'instance d'écriture. |
|
Nombre de demandes par seconde (HTTPS et Bolt) adressées au moteur openCypher. |
|
Nombre de connexions WebSocket ouvertes avec Bolt. |
|
Taille totale estimée (en octets) de tous les éléments mis en cache dans le cache de résultats Gremlin. |
|
Nombre d'éléments dans le cache de résultats de G705. |
|
Horodatage du plus ancien élément mis en cache dans le cache de résultats de Gremlin. |
|
Horodatage du dernier élément mis en cache dans le cache de résultats de Gremlin. |
|
En tant que métrique au niveau de l'instance, Au niveau d'un cluster, |
|
Quantité totale de stockage de sauvegarde en octets consommée par tous les instantanés pour un cluster de bases de données Neptune en dehors de sa période de rétention des sauvegardes. Incluse dans le total indiqué par la métrique |
|
Nombre d'erreurs côté client par seconde dans les requêtes SPARQL. |
|
Nombre de demandes envoyées au moteur SPARQL par seconde. |
|
Le nombre d'erreurs du serveur SPARQL par seconde. |
|
Nombre total de déclarations analysées pour les statistiques DFE depuis le démarrage du serveur. Chaque fois que le calcul des statistiques est déclenché, ce nombre augmente. Quand aucun calcul n'est effectué, il reste constant. Par conséquent, si vous le représentez sous forme de graphe au fil du temps, vous savez quand le calcul a eu lieu et quand il n'a pas eu lieu : 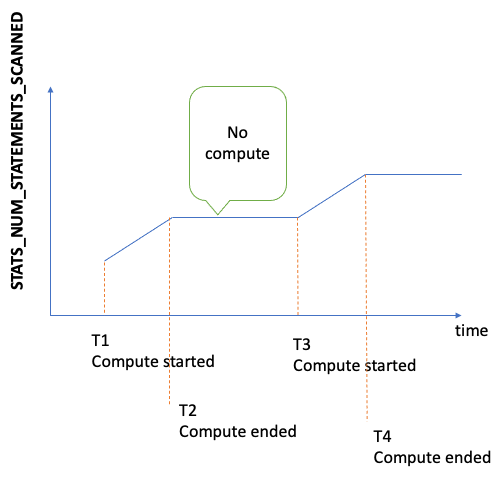
En examinant la pente du graphe aux périodes où la métrique augmente, vous pouvez également déterminer la rapidité du calcul. Si aucune métrique de ce type n'existe, cela signifie que la fonctionnalité de statistiques est désactivée sur le cluster de bases de données ou que la version du moteur que vous exécutez ne dispose pas de la fonctionnalité correspondante. Si la valeur de la métrique est nulle, cela signifie qu'aucun calcul de statistiques n'a eu lieu. |
|
Le débit réseau reçu du sous-système de stockage par chaque instance du cluster de base de données Neptune. |
StorageNetworkThroughput |
Quantité de débit réseau reçue et envoyée au sous-système de stockage par chaque instance du cluster de base de données Neptune. |
|
Quantité de débit réseau envoyée au sous-système de stockage par chaque instance du cluster de base de données Neptune. |
|
Quantité d'espace d'échange utilisé. |
|
Le nombre d'IOPS en lecture et en écriture sur le stockage local attaché à l'instance de base de données Neptune. Cette métrique représente un nombre et est mesurée une fois par seconde. |
|
La quantité de données transférées vers et depuis le stockage local associé à l'instance de base de données Neptune. Cette métrique représente des octets et est mesurée une fois par seconde. |
|
Quantité totale de stockage de sauvegarde en octets qui vous est facturée pour un cluster de bases de données Neptune spécifique. Inclut le stockage de sauvegarde mesuré par les métriques |
|
Nombre total de requêtes par seconde adressées au serveur à partir de toutes les sources. |
|
Nombre total de requêtes par seconde ayant commis une erreur en raison de problèmes côté client. |
|
Nombre total de requêtes par seconde ayant provoqué une erreur sur le serveur en raison de défaillances internes. |
|
Nombre de journaux d'annulation figurant dans la liste des journaux d'annulation. Les journaux d'annulation contiennent des enregistrements de transactions validées qui expirent lorsque toutes les transactions actives sont plus récentes que la date de validation. Les enregistrements ayant expiré sont régulièrement purgés. La purge des enregistrements de suppression peut prendre plus de temps que celle des enregistrements relatifs aux autres types de transactions. La purge étant effectuée exclusivement par l'instance d'enregistreur du cluster de bases de données, le taux de purge dépend du type d'instance d'enregistreur. Si la valeur De même, si vous effectuez une mise à niveau vers une version du moteur |
|
Quantité totale de stockage allouée à votre cluster de bases de données Neptune en octets. Il s'agit de la quantité de stockage pour laquelle vous êtes facturé. Il s'agit de la quantité maximale de stockage allouée à votre cluster DB à tout moment de son existence, et non de la quantité que vous utilisez actuellement (voir Facturation du stockage Neptune). |
|
Le nombre total d'opérations d'E/S de lecture facturées à partir d'un volume de cluster, indiqué à intervalles de 5 minutes. Les opérations de lecture facturées sont calculées au niveau du volume de cluster, regroupées à partir de toutes les instances du cluster de bases de données Neptune, puis rapportées par intervalles de 5 minutes. |
VolumeWriteIOPs |
Nombre total d'opérations d'E/S de disque d'écriture sur le volume du cluster, indiqué à intervalles de 5 minutes. |
CloudWatch Métriques désormais obsolètes dans Neptune
L'utilisation de ces métriques Neptune est désormais obsolète. Elles sont toujours prises en charge, mais pourraient être éliminées à l'avenir à mesure que des métriques nouvelles et meilleures deviennent disponibles.
Métrique |
Description |
|---|---|
|
Nombre de réponses HTTP 1xx pour le point de terminaison Gremlin par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre de réponses HTTP 2xx pour le point de terminaison Gremlin par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 4xx pour le point de terminaison Gremlin par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 5xx pour le point de terminaison Gremlin par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs dans le parcours Gremlin. |
|
Nombre de demandes envoyées au moteur Gremlin. |
|
Nombre de WebSocket connexions réussies au point de terminaison Gremlin par seconde. |
|
Nombre d'erreurs WebSocket client sur le point de terminaison Gremlin par seconde. |
|
Nombre d'erreurs de WebSocket serveur sur le point de terminaison Gremlin par seconde. |
|
Nombre de WebSocket connexions potentielles actuellement disponibles. |
|
Nombre de réponses HTTP 100 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre de réponses HTTP 101 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre de réponses HTTP 1xx pour le point de terminaison par seconde. |
|
Nombre de réponses HTTP 200 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre de réponses HTTP 2xx pour le point de terminaison par seconde. |
|
Nombre d'erreurs HTTP 400 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 403 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 405 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 413 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 429 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 4xx pour le point de terminaison par seconde. |
|
Nombre d'erreurs HTTP 500 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 501 pour le point de terminaison par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 5xx pour le point de terminaison par seconde. |
|
Nombre d'erreurs depuis des demandes de chargeur. |
|
Nombre de demandes de chargeur. |
|
Nombre de réponses HTTP 1xx pour le point de terminaison SPARQL par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre de réponses HTTP 2xx pour le point de terminaison SPARQL par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 4xx pour le point de terminaison SPARQL par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs HTTP 5xx pour le point de terminaison SPARQL par seconde. Nous vous recommandons d'utiliser plutôt la nouvelle métrique combinée |
|
Nombre d'erreurs dans les requêtes SPARQL. |
|
Nombre de demandes envoyées au moteur SPARQL. |
|
Nombre d'erreurs depuis le point de terminaison de statut. |
|
Nombre de demandes envoyées au point de terminaison de statut. |
