Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memulai dengan Amazon Neptunus
Amazon Neptune adalah layanan basis data grafik yang terkelola penuh yang diskalakan untuk menangani miliaran hubungan dan memungkinkan Anda mengkueri mereka dengan latensi milidetik, dengan biaya rendah untuk jenis kapasitas tersebut.
Jika Anda mencari informasi lebih rinci tentang Neptunus, lihat. Ikhtisar fitur Amazon Neptunus
Jika Anda sudah tahu tentang grafik, lompat ke depan ke Mulai cepat menggunakan CloudShell atauMenggunakan Neptunus dengan notebook grafik. Atau, jika Anda ingin membuat database Neptunus segera, lihat. Membuat cluster Amazon Neptunus menggunakan AWS CloudFormation
Jika tidak, Anda mungkin ingin tahu lebih banyak tentang database grafik sebelum memulai.
Konsep kunci basis data grafik
Basis data grafik dioptimalkan untuk menyimpan dan mengkueri hubungan antara item-item data.
Basis data ini menyimpan item data sendiri sebagai vertex dari grafik, dan hubungan di antara mereka sebagai edge. Setiap edge memiliki tipe, dan diarahkan dari satu vertex (awal) ke yang lain (akhir). Hubungan bisa disebut predikat serta edge, dan vertex juga kadang-kadang disebut sebagai node. Dalam apa yang disebut grafik properti, baik vertex dan edge dapat memiliki properti tambahan yang terkait dengan keduanya.
Berikut ini adalah grafik kecil yang mewakili teman dan hobi di jejaring sosial:
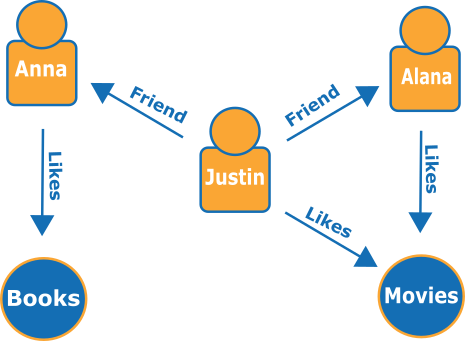
Edge ditampilkan sebagai panah bernama, dan vertex-vertex mewakili orang-orang tertentu dan hobi yang menghubungkan mereka.
Sebuah traversal sederhana dari grafik ini dapat memberi tahu Anda seperti apa teman Justin.
Mengapa menggunakan basis data grafik?
Setiap kali koneksi atau hubungan antara entitas berada pada inti dari data yang Anda coba buat modelnya, basis data grafik adalah pilihan alami Anda.
Untuk satu hal, mudah untuk membuat model interkoneksi data sebagai grafik, dan kemudian menulis kueri kompleks yang mengekstrak informasi dunia nyata dari grafik.
Membangun aplikasi setara menggunakan basis data relasional mengharuskan Anda untuk membuat banyak tabel dengan beberapa kunci asing dan kemudian menulis kueri SQL nested dan kompleks digabungkan. Pendekatan itu tidak hanya cepat menjadi berat dari perspektif pengkodean, kinerjanya terdegradasi dengan cepat karena jumlah data meningkat.
Sebaliknya, basis data grafik seperti Neptune dapat mengajukan kueri untuk hubungan antara miliaran vertex tanpa membuat macet.
Apa yang dapat Anda lakukan dengan basis data grafik?
Grafik dapat mewakili keterkaitan entitas dunia nyata dalam banyak hal, dalam hal tindakan, kepemilikan, orang tua, pilihan pembelian, koneksi pribadi, ikatan keluarga, dan sebagainya.
Berikut adalah beberapa area yang paling umum tempat basis data grafik digunakan:
-
Grafik pengetahuan — Grafik pengetahuan memungkinkan Anda mengatur dan menanyakan semua jenis informasi yang terhubung untuk menjawab pertanyaan umum. Menggunakan grafik pengetahuan, Anda dapat menambahkan informasi topikal untuk katalog produk, dan informasi beragam model seperti yang terkandung dalam Wikidata
. Untuk mempelajari lebih lanjut tentang bagaimana grafik pengetahuan bekerja dan di mana mereka sedang digunakan, lihat Grafik Pengetahuan di AWS
. -
Grafik identitas — Dalam basis data grafik, Anda dapat menyimpan hubungan antara kategori informasi seperti minat pelanggan, teman, dan riwayat pembelian, dan kemudian mengajukan kueri untuk data tersebut untuk membuat rekomendasi yang dipersonalisasi dan relevan.
Misalnya, Anda dapat menggunakan basis data grafik untuk membuat rekomendasi produk kepada pengguna berdasarkan produk mana yang dibeli oleh orang lain yang mengikuti olahraga yang sama dan memiliki riwayat pembelian yang sama. Atau, Anda dapat mengidentifikasi orang yang memiliki teman yang sama tetapi belum mengenal satu sama lain, dan membuat rekomendasi persahabatan.
Grafik semacam ini dikenal sebagai grafik identitas, dan secara luas digunakan untuk personalisasi interaksi dengan pengguna. Untuk mengetahui lebih lanjut, lihat Grafik Identitas di AWS
. Untuk memulai membangun grafik identitas Anda sendiri, Anda dapat mulai dengan sampel Grafik Identitas Menggunakan Amazon Neptune . -
Grafik Penipuan — Ini adalah penggunaan umum untuk basis data grafik. Basis data dapat membantu Anda melacak pembelian kartu kredit dan lokasi pembelian untuk mendeteksi penggunaan yang tidak biasa, atau untuk mendeteksi pembeli yang mencoba menggunakan alamat email dan kartu kredit yang sama seperti yang digunakan dalam kasus penipuan yang diketahui. Mereka dapat mengizinkan Anda memeriksa beberapa orang yang terkait dengan alamat email pribadi, atau beberapa orang di lokasi fisik berbeda yang berbagi alamat IP yang sama.
Pertimbangkan grafik berikut. Grafik ini menunjukkan hubungan tiga orang dan informasi terkait identitas mereka. Setiap orang memiliki alamat, rekening bank, dan nomor jaminan sosial. Namun, kita dapat melihat bahwa Matt dan Justin berbagi nomor jaminan sosial yang sama, yang tidak biasa dan menunjukkan kemungkinan penipuan oleh salah satu dari mereka. Kueri untuk grafik penipuan dapat mengungkapkan koneksi semacam ini sehingga mereka dapat ditinjau.
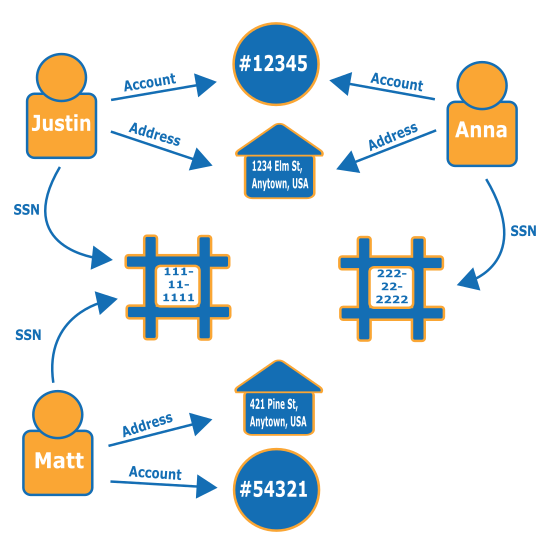
Untuk mempelajari lebih lanjut tentang grafik penipuan dan di mana mereka sedang digunakan, lihat Grafik Penipuan di AWS
. -
Jaringan sosial — Salah satu bidang pertama dan paling umum tempat basis data grafik digunakan adalah dalam aplikasi jejaring sosial.
Misalnya, anggaplah Anda ingin membangun umpan sosial ke dalam suatu situs web. Anda dapat dengan mudah menggunakan basis data grafik di ujung belakang untuk memberikan hasil kepada pengguna yang mencerminkan pembaruan terbaru dari keluarga mereka, teman mereka, dari orang-orang yang pembaruannya mereka “sukai”, dan dari orang-orang yang tinggal dekat dengan mereka.
Petunjuk arah mengemudi — Grafik dapat membantu menemukan rute terbaik dari titik awal ke tujuan, mempertimbangkan lalu lintas saat ini dan pola lalu lintas yang khas.
Logistik — Grafik dapat membantu mengidentifikasi cara paling efisien untuk menggunakan sumber daya pengiriman dan distribusi yang tersedia untuk memenuhi kebutuhan pelanggan.
Diagnosis — Grafik dapat mewakili pohon diagnostik kompleks yang dapat diajukan kueri untuk mengidentifikasi sumber masalah dan kegagalan yang diamati.
Penelitian ilmiah — Dengan database grafik, Anda dapat membangun aplikasi yang menyimpan dan menavigasi data ilmiah dan bahkan informasi medis sensitif menggunakan enkripsi saat istirahat. Misalnya, Anda bisa menyimpan model interaksi penyakit dan gen. Anda dapat mencari pola grafik dalam jalur protein untuk menemukan gen lain yang mungkin terkait dengan suatu penyakit. Anda dapat membuat model senyawa kimia sebagai grafik dan mengajukan kueri untuk pola dalam struktur molekul. Anda dapat mengorelasikan data pasien dari rekam medis dalam sistem yang berbeda. Anda dapat secara topikal mengatur publikasi penelitian untuk menemukan informasi yang relevan dengan cepat.
Aturan peraturan — Anda dapat menyimpan persyaratan peraturan yang kompleks sebagai grafik, dan mengajukan kueri untuk persyaratan tersebut untuk mendeteksi situasi yang mungkin berlaku untuk operasi bisnis sehari-hari Anda.
-
Topologi dan peristiwa jaringan — Basis data grafik dapat membantu Anda mengelola dan melindungi jaringan IT. Ketika Anda menyimpan topologi jaringan sebagai grafik, Anda juga dapat menyimpan dan memproses berbagai jenis peristiwa di jaringan. Anda dapat menjawab pertanyaan seperti berapa banyak host yang menjalankan aplikasi tertentu. Anda dapat mengajukan kueri untuk pola yang mungkin menunjukkan bahwa host tertentu telah diganggu oleh program berbahaya, dan kueri untuk koneksi data yang dapat membantu melacak program ke host asli yang mengunduhnya itu.
Bagaimana Anda menanyakan grafik?
Neptunus mendukung tiga bahasa query tujuan khusus yang dirancang untuk query data grafik dari berbagai jenis. Anda dapat menggunakan bahasa-bahasa ini untuk menambah, memodifikasi, menghapus, dan menanyakan data dalam database grafik Neptunus:
-
Gremlin adalah bahasa traversal grafik untuk grafik properti. Sebuah kueri di Gremlin adalah sebuah traversal yang terdiri dari langkah-langkah berlainan, yang masing-masing mengikuti edge ke simpul. Lihat dokumentasi Gremlin di Apache TinkerPop
untuk informasi lebih lanjut. Implementasi Neptunus dari Gremlin memiliki beberapa perbedaan dari implementasi lain, terutama ketika Anda Gremlin-Groovy menggunakan (kueri Gremlin dikirim sebagai teks serial). Untuk informasi selengkapnya, lihat Kepatuhan standar Gremlin di Amazon Neptune.
-
OpenCypherOpenCypher adalah bahasa query deklaratif untuk grafik properti yang awalnya dikembangkan oleh Neo4j, kemudian open-source pada tahun 2015, dan berkontribusi pada proyek OpenCypher di bawah lisensi open-source Apache 2.
Lihat Referensi Bahasa Kueri Cypher (Versi 9) untuk spesifikasi bahasa, serta Panduan Gaya Cypher untuk informasi tambahan. -
SPARQL adalah bahasa query deklaratif untuk data RDF
, berdasarkan pencocokan pola grafik yang distandarisasi oleh World Wide Web Consortium (W3C) dan dijelaskan dalam SPARQL 1.1 Ikhtisar) dan spesifikasi SPARQL 1.1 Query Language. Lihat Kepatuhan standar SPARQL di Amazon Neptunus untuk detail spesifik tentang implementasi Neptunus SPARQL.
Contoh pencocokan kueri Gremlin dan SPARQL
Mengingat grafik orang (node) berikut dan hubungan mereka (edge), Anda dapat mengetahui siapa “teman dari teman” dari orang tertentu - misalnya, teman-teman dari teman-temannya Howard.
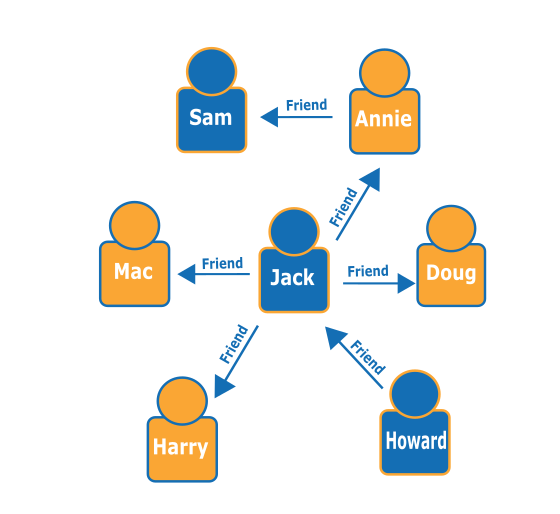
Melihat grafiknya, Anda dapat melihat bahwa Howard memiliki satu teman, Jack, dan Jack memiliki empat teman: Annie, Harry, Doug, dan Mac. Ini adalah contoh sederhana dengan grafik sederhana, tetapi jenis kueri ini dapat diskalakan dalam kompleksitas, ukuran dataset, dan ukuran hasil.
Berikut ini adalah kueri traversal Gremlin yang mengembalikan nama-nama teman-teman dari teman-teman Howard:
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
Berikut ini adalah kueri SPARQL yang mengembalikan nama-nama teman-teman dari teman-teman Howard:
prefix : <#> select ?names where { ?howard :name "Howard" . ?howard :friend/:friend/:name ?names . }
catatan
Setiap bagian dari triple Resource Description Framework (RDF) mana pun memiliki URI terkait dengan bagian tersebut. Dalam contoh di atas, prefiks URI sengaja singkat.
Ikuti kursus online tentang menggunakan Amazon Neptune
Jika Anda suka belajar dengan video, AWS menawarkan kursus online di AWS Online Tech Talks
Pengenalan Database Grafik, penyelaman mendalam, dan demo dengan Amazon Neptunus
Menggali lebih dalam arsitektur referensi grafik
Ketika Anda berpikir tentang masalah apa yang dapat dipecahkan oleh database grafik untuk Anda, dan bagaimana mendekatinya, salah satu tempat terbaik untuk memulai adalah proyek arsitektur referensi grafik Neptunus
Di sana Anda dapat menemukan penjelasan detail tentang jenis beban kerja grafik, dan tiga bagian untuk membantu Anda merancang basis data grafik yang efektif:
Model Data dan Bahasa Kueri
— Bagian ini memandu Anda melalui perbedaan antara Gremlin dan SPARQL dan bagaimana memilih di antara mereka. Pemodelan Data Grafik
— Ini adalah diskusi menyeluruh tentang bagaimana membuat keputusan pemodelan data grafik, termasuk panduan detail pemodelan grafik properti menggunakan pemodelan Gremlin dan RDF menggunakan SPARQL. Mengonversi Model Data Lain ke Model Grafik
— Di sini Anda dapat mengetahui bagaimana cara menerjemahkan model data relasional ke dalam model grafik.
Ada juga tiga bagian yang memandu Anda melalui langkah-langkah khusus untuk menggunakan Neptune:
Menghubungkan ke Amazon Neptune dari Klien di Luar VPC Neptune
— Bagian ini menunjukkan beberapa pilihan untuk menghubungkan ke Neptune dari luar VPC tempat klaster DB Anda berada. Mengakses Amazon Neptunus dari Fungsi Lambda - Di sini Anda akan mengetahui cara menghubungkan dengan andal ke AWS Neptunus
dari fungsi Lambda. Menulis ke Amazon Neptune dari Amazon Kinesis Data Stream
— Bagian ini dapat membantu Anda menangani skenario throughput tulis tinggi dengan Neptune.
