翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon EMR の Zeppelin から Flink ジョブを操作する
序章
Amazon EMR リリース 6.10.0 以降では、Apache Zeppelin と Apache Flink の連携がサポートされており、Flink ジョブを Zeppelin ノートブックからインタラクティブに送信できます。Flink インタープリタを使用すると、Flink クエリの実行、Flink ストリーミングおよびバッチのジョブ定義、Zeppelin ノートブック内での出力の視覚化を行えます。Flink インタープリタは、Flink REST API をベースに構築されています。これにより、Zeppelin 環境内から Flink ジョブにアクセスして操作し、データの処理と分析をリアルタイムに実行できます。
Flink インタープリタには 4 つのサブインタープリターがあります。これらは、異なる目的を持ちますが、すべて JVM 内に存在し、事前設定された、Flink への同じエントリポイント (ExecutionEnviroment、StreamExecutionEnvironment、BatchTableEnvironment、StreamTableEnvironment) を共有しています。具体的なインタープリタは、次のとおりです。
-
%flink—ExecutionEnvironment、StreamExecutionEnvironment、BatchTableEnvironment、StreamTableEnvironmentを作成し、Scala 環境を提供する -
%flink.pyflink— Python 環境を提供する -
%flink.ssql— ストリーミング SQL 環境を提供する -
%flink.bsql— バッチ SQL 環境を提供する
前提条件
-
Zeppelin と Flink の連携は、Amazon EMR 6.10.0 以降で作成されたクラスターでサポートされています。
-
これらの手順に応じて EMR クラスターでホストされているウェブインターフェイスを表示するには、SSH トンネルを設定してインバウンドアクセスを許可する必要があります。詳細については、「プライマリノードでホストされるウェブサイトを表示するようにプロキシを設定する」を参照してください。
EMR クラスターで Zeppelin と Flink の連携を設定する
Apache Zeppelin で動作する Apache Flink が EMR クラスター上で稼働できるよう設定するには、次の手順に従います。
-
Amazon EMR コンソールからクラスターを新規作成します。emr-6.10.0 以降の Amazon EMR リリースを選択します。次に、[カスタム] オプションを使用して、アプリケーションバンドルのカスタマイズを選択します。バンドルには、少なくとも Flink、Hadoop、Zeppelin を含めてください。
![Amazon EMR コンソールで、[カスタム] オプションを使用して、アプリケーションバンドルをカスタマイズします。バンドルには、少なくとも Flink、Hadoop、Zeppelin を含めてください。](images/emr-flink-zeppelin-console.png)
-
残りのクラスターは、任意の設定で作成します。
-
クラスターを稼働させたら、そのクラスターをコンソールから選択して詳細を表示し、[アプリケーション] タブを開きます。[アプリケーションユーザーインターフェイス] セクションから [Zeppelin] を選択して、Zeppelin ウェブインターフェイスを開きます。前提条件 の説明どおり、プライマリノードへの SSH トンネルとプロキシ接続を介して、Zeppelin ウェブインターフェイスにアクセスできるよう設定されていることを確認します。
-
これで、Flink をデフォルトのインタープリタとして使用して、Zeppelin ノートブックにノートを新規作成できるようになりました。
-
Zeppelin ノートブックから Flink ジョブを実行する方法については、次のコード例を参照してください。
Zeppelin と Flink が連携する EMR クラスターで Flink ジョブを実行する
-
例 1: Flink Scala
a) バッチの WordCount の例 (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) ストリーミングの WordCount の例 (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()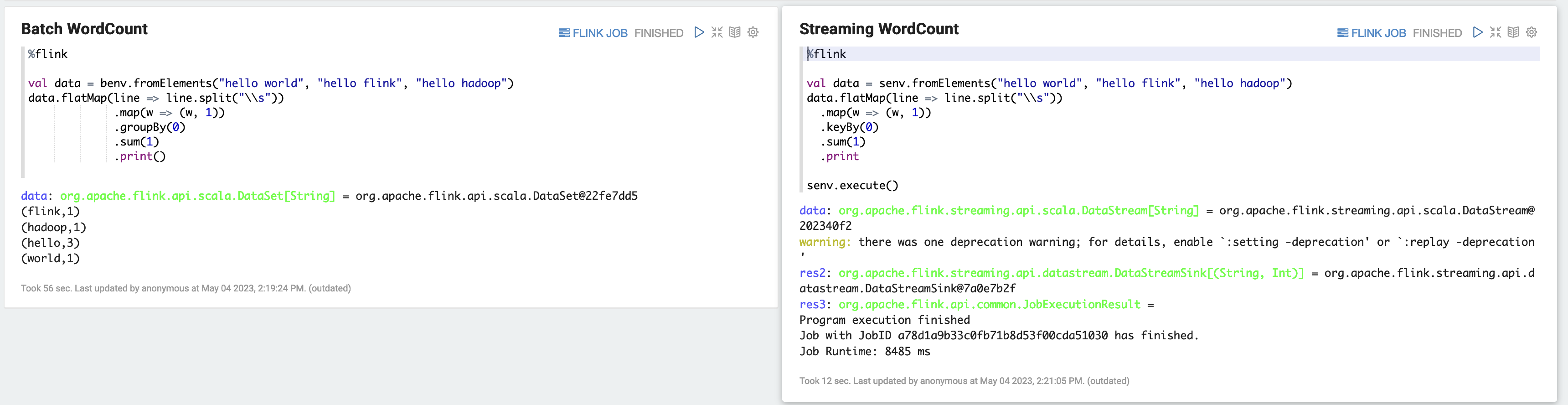
-
例 2: Flink ストリーミング SQL
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;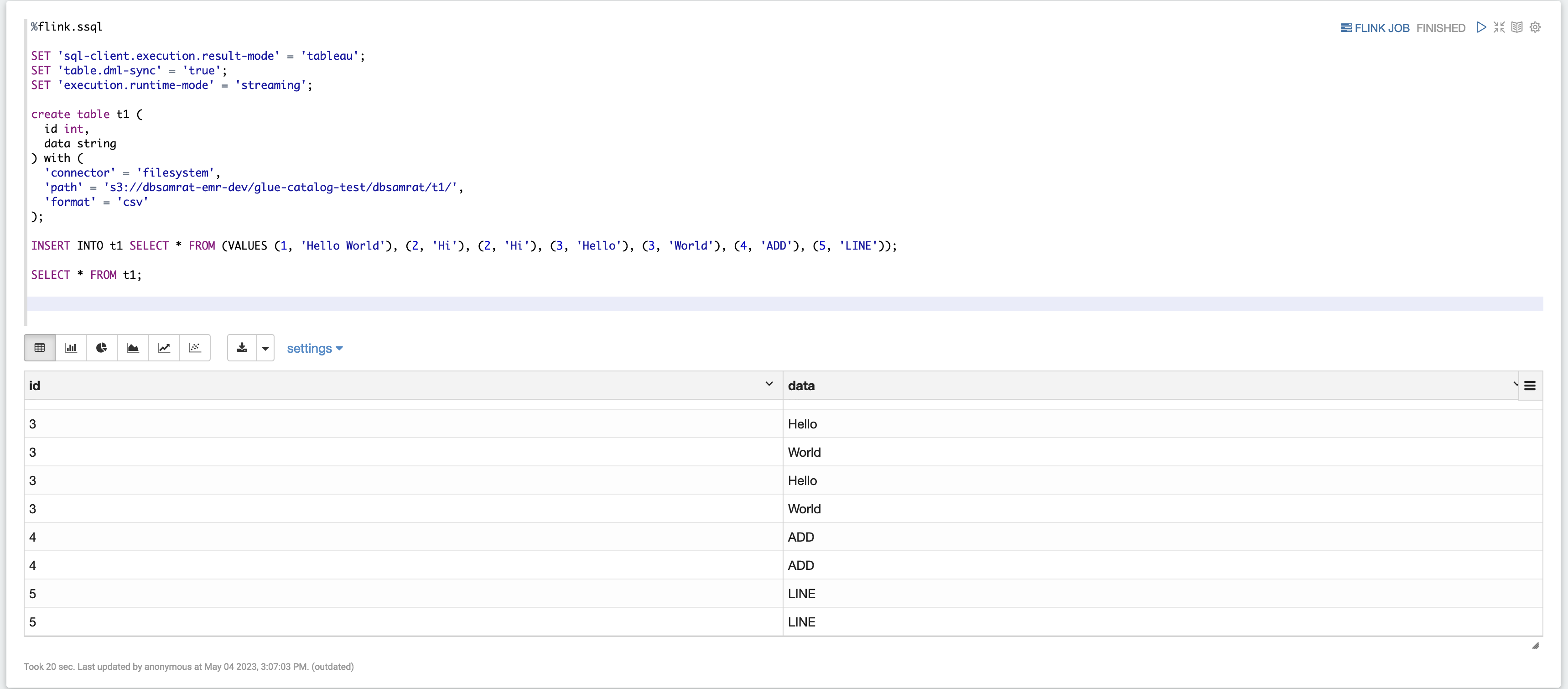
-
例 3: Pyflink
word.txtという名前のサンプルテキストファイルを S3 バケットにアップロードする必要があることに注意してください。%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
Zeppelin UI で [FLINK JOB] を選択すると、Flink ウェブの UI にアクセスし、表示を行えます。
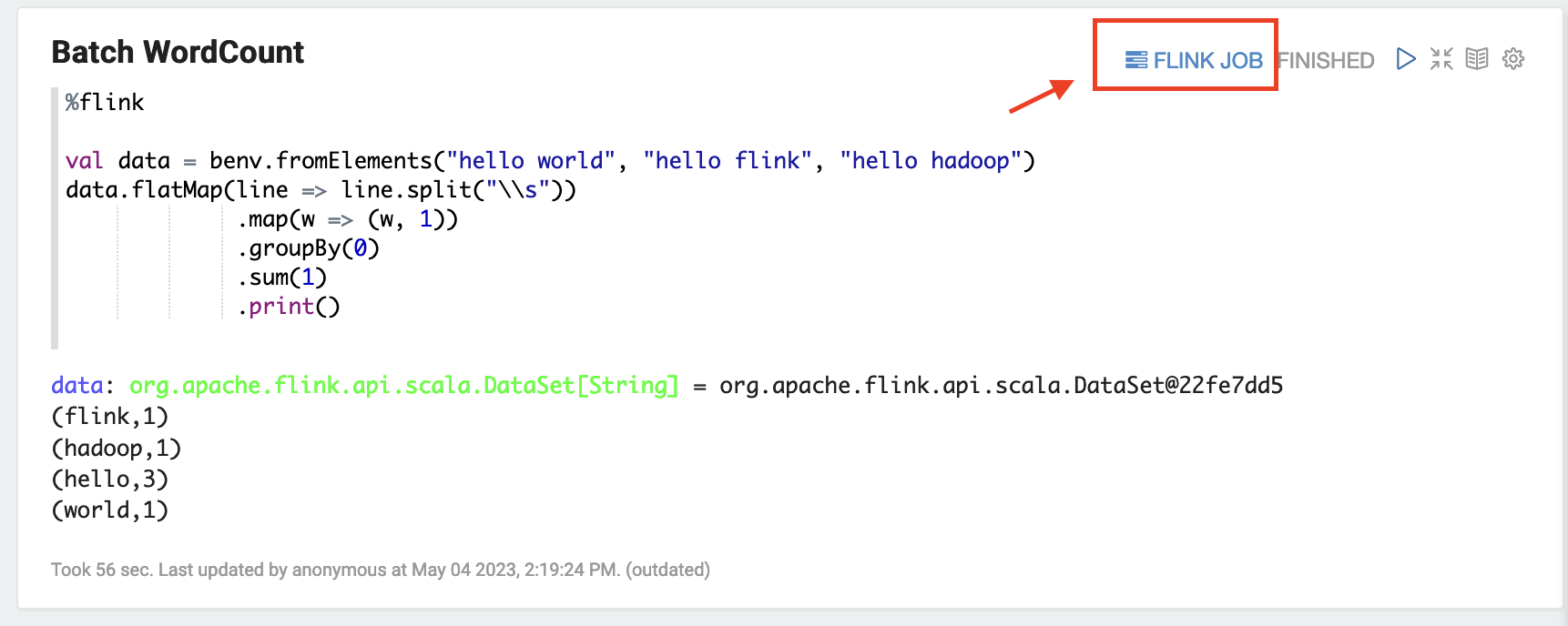
-
[FLINK JOB] を選択すると、Flink ウェブコンソールにルーティングされ、そのページがブラウザの別のタブで開きます。
![[FLINK JOB] を選択すると、Flink ウェブコンソールがブラウザの別のタブで開きます。](images/flink-web-console.png)
