기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS Clean Rooms ML
AWS Clean Rooms ML을 사용하면 두 명 이상의 당사자가 데이터를 서로 공유할 필요 없이 데이터에 대해 기계 학습 모델을 실행할 수 있습니다. 이 서비스는 데이터 소유자가 데이터와 모델 IP를 안전하게 보호할 수 있는 개인 정보 보호 제어를 제공합니다. AWS 작성 모델을 사용하거나 자체 사용자 지정 모델을 가져올 수 있습니다.
작동하는 방식에 대한 자세한 설명은 교차 계정 작업 섹션을 참조하세요.
Clean Rooms ML 모델의 기능에 대한 자세한 내용은 다음 주제를 참조하세요.
주제
AWS Clean Rooms ML 용어
Clean Rooms ML을 사용할 때는 다음 용어를 이해하는 것이 중요합니다.
-
훈련 데이터 공급자 – 훈련 데이터를 제공하고 유사 모델을 생성 및 구성한 다음 해당 유사 모델을 공동 작업에 연결하는 역할을 합니다.
-
시드 데이터 공급자 - 시드 데이터를 제공하고 유사 세그먼트를 생성하여 유사 세그먼트를 내보내는 역할을 합니다.
-
훈련 데이터 - 유사 모델을 생성하는 데 사용되는 훈련 데이터 공급자의 데이터입니다. 훈련 데이터는 사용자 동작의 유사성을 측정하는 데 사용됩니다.
훈련 데이터에는 사용자 ID, 항목 ID 및 타임스탬프 열이 포함되어야 합니다. 필요에 따라 훈련 데이터에 다른 상호작용을 수치적 특징 또는 범주형 특징으로 포함할 수 있습니다. 상호작용의 예로는 시청한 동영상, 구매한 항목, 읽은 기사 목록 등이 있습니다.
-
시드 데이터 - 유사 세그먼트를 만드는 데 사용되는 시드 데이터 공급자의 데이터입니다. 시드 데이터는 직접 제공하거나 AWS Clean Rooms 쿼리 결과에서 가져올 수 있습니다. 유사 세그먼트는 시드 사용자와 가장 유사한 훈련 데이터의 사용자 집합입니다.
-
유사 모델 - 다른 데이터 세트에서 유사한 사용자를 찾는 데 사용되는 훈련 데이터의 기계 학습 모델입니다.
API를 사용할 때 대상 모델이라는 용어는 유사 모델과 동일하게 사용됩니다. 예를 들어 CreateAudienceModel API를 사용하여 유사 모델을 만들 수 있습니다.
-
유사 세그먼트 - 시드 데이터와 가장 유사한 훈련 데이터의 하위 집합입니다.
API를 사용할 때 StartAudienceGenerationJob API를 사용하여 유사 세그먼트를 생성합니다.
훈련 데이터 공급자의 데이터는 시드 데이터 공급자와 공유되지 않으며 시드 데이터 공급자의 데이터도 훈련 데이터 공급자와 공유되지 않습니다. 유사 세그먼트 출력은 훈련 데이터 공급자와 공유되지만 시드 데이터 공급자와는 공유되지 않습니다.
AWS Clean Rooms ML이 AWS 모델과 작동하는 방식
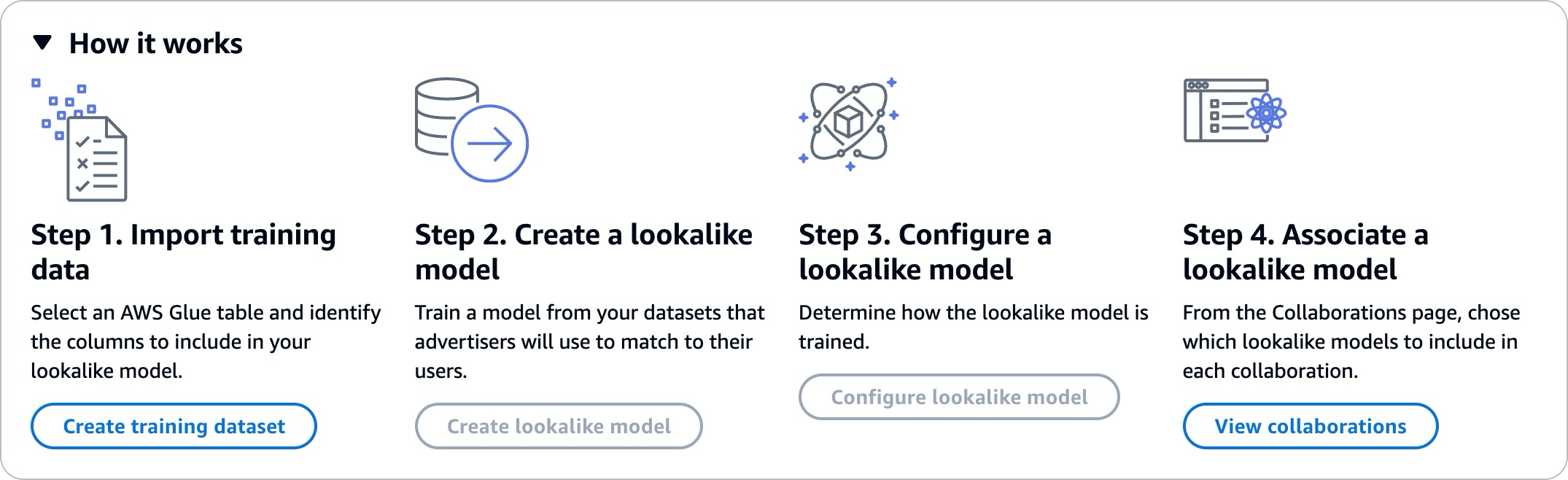
유사 모델을 사용하려면 훈련 데이터 공급자와 시드 데이터 공급자라는 두 당사자가 순차적으로에서 작업 AWS Clean Rooms 하여 데이터를 공동 작업으로 가져와야 합니다. 훈련 데이터 공급자가 먼저 완료해야 하는 워크플로는 다음과 같습니다.
-
훈련 데이터 공급자의 데이터는 사용자-항목 상호 작용의 AWS Glue 데이터 카탈로그 테이블에 저장되어야 합니다. 훈련 데이터에는 최소한 사용자 ID 열, 상호 작용 ID 열 및 타임스탬프 열이 포함되어야 합니다.
-
훈련 데이터 공급자는 훈련 데이터를에 등록합니다 AWS Clean Rooms.
-
훈련 데이터 공급자는 여러 시드 데이터 공급자와 공유할 수 있는 유사 모델을 생성합니다. 유사 모델은 신경망이며, 훈련하는 데 최대 24시간이 걸릴 수 있습니다. 자동으로 재훈련되지 않으므로 매주 모델을 재훈련하는 것이 좋습니다.
-
훈련 데이터 공급자는 관련성 지표 공유 여부 및 출력 세그먼트의 Amazon S3 위치를 포함하여 유사 모델을 구성합니다. 훈련 데이터 공급자는 단일 유사 모델에서 구성된 유사 모델을 여러 개 생성할 수 있습니다.
-
훈련 데이터 공급자는 구성된 대상 모델을 시드 데이터 공급자와 공유하는 공동 작업에 연결합니다.
시드 데이터 공급자가 다음으로 완료해야 하는 워크플로는 다음과 같습니다.
-
시드 데이터 공급자의 데이터는 Amazon S3 버킷에 저장하거나 쿼리 결과에서 가져올 수 있습니다.
-
시드 데이터 공급자는 훈련 데이터 공급자와 공유하는 공동 작업을 엽니다.
-
시드 데이터 공급자는 공동 작업 페이지의 Clean Rooms ML 탭에서 유사 세그먼트를 만듭니다.
-
시드 데이터 공급자는 관련성 지표가 공유된 경우 이를 평가하고 유사 세그먼트를 내보내 AWS Clean Rooms외부에서 사용할 수 있습니다.
AWS Clean Rooms ML이 사용자 지정 모델과 작동하는 방식
Clean Rooms ML을 사용하면 공동 작업 구성원이 Amazon ECR에 저장된 도킹된 사용자 지정 모델 알고리즘을 사용하여 데이터를 공동 분석할 수 있습니다. 이렇게 하려면 모델 공급자가 이미지를 생성하고 Amazon ECR에 저장해야 합니다. Amazon Elastic Container Registry 사용 설명서의 단계에 따라 사용자 지정 ML 모델을 포함할 프라이빗 리포지토리를 생성합니다.
올바른 권한이 있는 경우 공동 작업의 모든 구성원이 모델 공급자가 될 수 있습니다. 공동 작업의 모든 구성원은 훈련 데이터, 추론 데이터 또는 둘 다를 모델에 제공할 수 있습니다. 이 안내서의 목적상 데이터를 제공하는 구성원을 데이터 공급자라고 합니다. 공동 작업을 생성하는 구성원은 공동 작업 생성자이며,이 구성원은 모델 공급자, 데이터 공급자 중 하나 또는 둘 다일 수 있습니다.
가장 높은 수준에서 사용자 지정 ML 모델링을 수행하기 위해 완료해야 하는 단계는 다음과 같습니다.
-
공동 작업 생성자는 공동 작업을 생성하고 각 구성원에게 적절한 구성원 기능 및 결제 구성을 할당합니다. 공동 작업 생성자는 모델 출력을 수신하거나 추론 결과를 수신할 수 있는 구성원 기능을이 단계의 적절한 구성원에게 할당해야 합니다. 공동 작업이 생성된 후에는 업데이트할 수 없기 때문입니다. 자세한 내용은 AWS Clean Rooms ML에서 공동 작업 생성 및 참여 단원을 참조하십시오.
-
모델 공급자는 컨테이너화된 ML 모델을 구성하여 공동 작업에 연결하고 내보낸 데이터에 대해 개인 정보 보호 제약 조건이 설정되도록 합니다. 자세한 내용은 AWS Clean Rooms ML에서 모델 알고리즘 구성 단원을 참조하십시오.
-
데이터 공급자는 데이터를 공동 작업에 기여하고 개인 정보 보호 요구 사항이 지정되도록 합니다. 데이터 공급자는 모델이 데이터에 액세스할 수 있도록 허용해야 합니다. 자세한 내용은 AWS Clean Rooms ML에서 훈련 데이터 기여 및 AWS Clean Rooms ML에서 구성된 모델 알고리즘 연결 섹션을 참조하세요.
-
공동 작업 구성원은 모델 아티팩트 또는 추론 결과를 내보낼 위치를 정의하는 ML 구성을 생성합니다.
-
공동 작업 구성원은 훈련 컨테이너 또는 추론 컨테이너에 입력을 제공하는 ML 입력 채널을 생성합니다. ML 입력 채널은 모델 알고리즘의 컨텍스트에서 사용할 데이터를 정의하는 쿼리입니다.
-
공동 작업 구성원은 ML 입력 채널과 구성된 모델 알고리즘을 사용하여 모델 훈련을 호출합니다. 자세한 내용은 AWS Clean Rooms ML에서 훈련된 모델 생성 단원을 참조하십시오.
-
(선택 사항) 모델 트레이너는 모델 내보내기 작업을 호출하고 모델 아티팩트는 모델 결과 수신기로 전송됩니다. 유효한 ML 구성을 가진 멤버와 모델 출력을 수신하는 멤버 기능만 모델 아티팩트를 수신할 수 있습니다. 자세한 내용은 AWS Clean Rooms ML에서 모델 아티팩트 내보내기 단원을 참조하십시오.
-
(선택 사항) 공동 작업 구성원은 ML 입력 채널, 훈련된 모델 ARN 및 추론 구성 모델 알고리즘을 사용하여 모델 추론을 호출합니다. 추론 결과는 추론 출력 수신기로 전송됩니다. ML 구성이 유효하고 추론 출력을 수신할 수 있는 멤버만 추론 결과를 수신할 수 있습니다.
다음은 모델 공급자가 완료해야 하는 단계입니다.
-
SageMaker AI 호환 Amazon ECR Docker 이미지를 생성합니다. Clean Rooms ML은 SageMaker AI 호환 도커 이미지만 지원합니다.
-
SageMaker AI 호환 도커 이미지를 생성한 후 이미지를 Amazon ECR로 푸시합니다. Amazon Elastic Container Registry 사용 설명서의 지침에 따라 컨테이너 훈련 이미지를 생성합니다.
-
Clean Rooms ML에서 사용할 모델 알고리즘을 구성합니다.
-
Amazon ECR 리포지토리 링크와 모델 알고리즘을 구성하는 데 필요한 인수를 제공합니다.
-
Clean Rooms ML이 Amazon ECR 리포지토리에 액세스할 수 있는 서비스 액세스 역할을 제공합니다.
-
구성된 모델 알고리즘을 공동 작업과 연결합니다. 여기에는 컨테이너 로그, 실패 로그, CloudWatch 지표 및 컨테이너 결과에서 내보낼 수 있는 데이터의 양에 대한 제한에 대한 제어를 정의하는 개인 정보 보호 정책 제공이 포함됩니다.
-
다음은 데이터 공급자가 사용자 지정 ML 모델과 협업하기 위해 완료해야 하는 단계입니다.
-
사용자 지정 분석 규칙을 사용하여 기존 AWS Glue 테이블을 구성합니다. 이렇게 하면 사전 승인된 특정 쿼리 세트 또는 사전 승인된 계정이 데이터를 사용할 수 있습니다.
-
구성된 테이블을 공동 작업과 연결하고 AWS Glue 테이블에 액세스할 수 있는 서비스 액세스 역할을 제공합니다.
-
구성된 모델 알고리즘 연결이 구성된 테이블에 액세스할 수 있도록 하는 공동 작업 분석 규칙을 테이블에 추가합니다.
-
Clean Rooms ML에서 모델과 데이터를 연결하고 구성한 후 쿼리를 실행할 수 있는 구성원은 SQL 쿼리를 제공하고 사용할 모델 알고리즘을 선택합니다.
모델 훈련이 완료되면 해당 구성원은 모델 훈련 아티팩트 또는 추론 결과의 내보내기를 시작합니다. 이러한 아티팩트 또는 결과는 훈련된 모델 출력을 수신할 수 있는 기능을 가진 멤버에게 전송됩니다. 결과 수신자는 모델 출력을 수신하기 MachineLearningConfiguration 전에를 구성해야 합니다.
