기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon EMR은 EMR RecordServer를 통합하여 SparkSQL에 대한 세분화된 액세스 제어를 제공합니다. EMR의 RecordServer는 Apache Ranger 지원 클러스터의 모든 노드에서 실행되는 권한 있는 프로세스입니다. Spark 드라이버 또는 실행기가 SparkSQL 문을 실행하면 모든 메타데이터 및 데이터 요청이 RecordServer를 통과합니다. EMR RecordServer에 대한 자세한 내용은 Apache Ranger에서 사용할 Amazon EMR 구성 요소 페이지를 참조하세요.
지원 기능
| SQL 명령문 및 Ranger 작업 | STATUS | 지원되는 EMR 릴리스 |
|---|---|---|
|
SELECT |
지원 |
5.32 기준 |
|
SHOW DATABASES |
지원 |
5.32 기준 |
|
SHOW COLUMNS |
지원 |
5.32 기준 |
|
SHOW TABLES |
지원 |
5.32 기준 |
|
SHOW TABLE PROPERTIES |
지원 |
5.32 기준 |
|
DESCRIBE TABLE |
지원 |
5.32 기준 |
|
INSERT OVERWRITE |
지원 |
5.34 및 6.4 기준 |
| INSERT INTO | 지원 | 5.34 및 6.4 기준 |
|
ALTER TABLE |
지원 |
6.4 기준 |
|
CREATE TABLE |
지원 |
5.35 및 6.7 기준 |
|
데이터베이스 생성 |
지원 |
5.35 및 6.7 기준 |
|
DROP TABLE |
지원 |
5.35 및 6.7 기준 |
|
DROP DATABASE |
지원 |
5.35 및 6.7 기준 |
|
DROP VIEW |
지원 |
5.35 및 6.7 기준 |
|
CREATE VIEW |
지원되지 않음 |
SparkSQL을 사용할 때 지원되는 기능은 다음과 같습니다.
-
Hive 메타스토어 내 테이블에 대한 세분화된 액세스 제어 및 정책을 데이터베이스, 테이블 및 열 수준에서 생성할 수 있습니다.
-
Apache Ranger 정책에는 사용자 및 그룹에 대한 권한 부여 정책과 거부 정책이 포함될 수 있습니다.
-
감사 이벤트는 CloudWatch Logs로 제출됩니다.
INSERT, ALTER 또는 DDL 문을 사용하도록 서비스 정의 재배포
참고
Amazon EMR 6.4부터 INSERT INTO, INSERT OVERWRITE 또는 ALTER TABLE과 함께 Spark SQL을 사용할 수 있습니다. Amazon EMR 6.7부터 Spark SQL을 사용하여 데이터베이스 및 테이블을 생성하거나 삭제할 수 있습니다. Apache Ranger 서버에 Apache Spark 서비스 정의가 배포된 기존 설치가 있는 경우 다음 코드를 사용하여 서비스 정의를 재배포합니다.
# Get existing Spark service definition id calling Ranger REST API and JSON processor curl --silent -f -u<admin_user_login>:<password_for_ranger_admin_user>\ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id # Download the latest Service definition wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json # Update the service definition using the Ranger REST API curl -u<admin_user_login>:<password_for_ranger_admin_user>-X PUT -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/<Spark service definition id from step 1>'
서비스 정의 설치
EMR의 Apache Spark 서비스 정의를 설치하려면 Ranger Admin 서버를 설정해야 합니다. Amazon EMR과 통합하도록 Ranger Admin 서버 설정을 참조하세요.
다음 단계에 따라 Apache Spark 서비스 정의를 설치합니다.
1단계: Apache Ranger Admin 서버에 SSH로 연결
예시:
ssh ec2-user@ip-xxx-xxx-xxx-xxx.ec2.internal2단계: 서비스 정의 및 Apache Ranger Admin 서버 플러그인 다운로드
임시 디렉터리에서 서비스 정의를 다운로드합니다. 이 서비스 정의는 Ranger 2.x 버전에서 지원됩니다.
mkdir /tmp/emr-spark-plugin/
cd /tmp/emr-spark-plugin/
wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-spark-plugin-2.x.jar
wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json3단계: Amazon EMR용 Apache Spark 플러그인 설치
export RANGER_HOME=.. # Replace this Ranger Admin's home directory eg /usr/lib/ranger/ranger-2.0.0-admin
mkdir $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
mv ranger-spark-plugin-2.x.jar $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark4단계: Amazon EMR용 Apache Spark 서비스 정의 등록
curl -u *<admin users login>*:*_<_**_password_ **_for_** _ranger admin user_**_>_* -X POST -d @ranger-servicedef-amazon-emr-spark.json \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef'이 명령이 성공적으로 실행되면 다음 이미지와 같이 Ranger Admin UI에 'AMAZON-EMR-SPARK'라는 새 서비스가 표시됩니다(Ranger 버전 2.0이 표시됨).
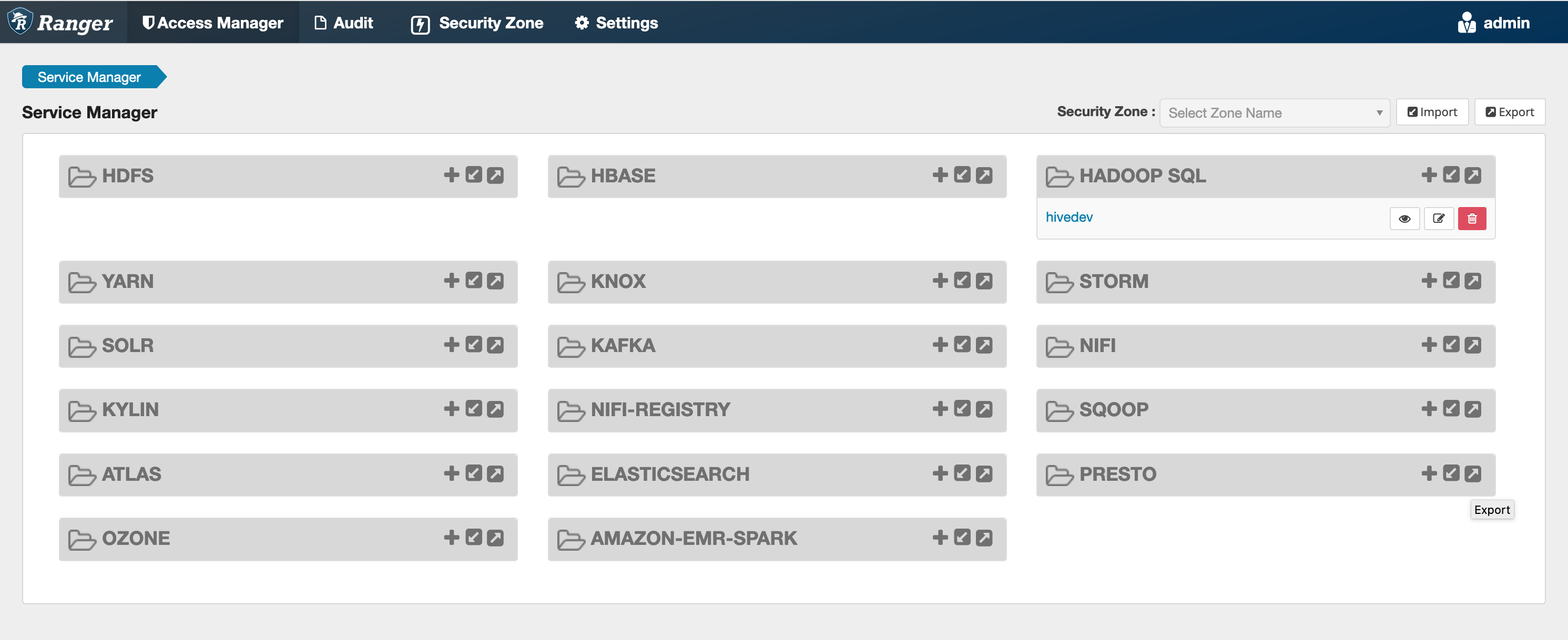
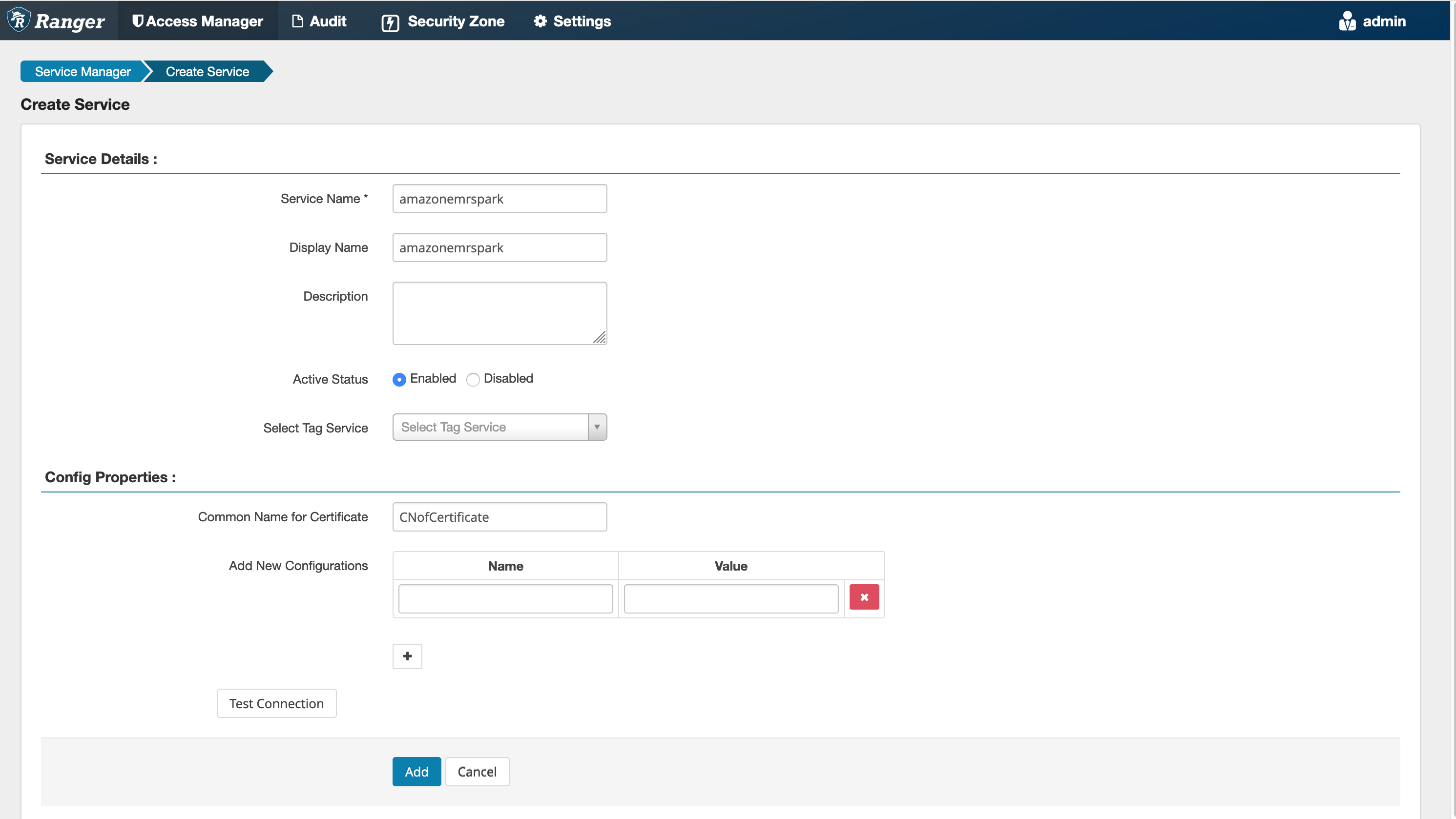
5단계: AMAZON-EMR-SPARK 애플리케이션의 인스턴스 생성
서비스 이름(표시된 경우): 사용할 서비스 이름. 제안된 값은 amazonemrspark입니다. EMR 보안 구성을 생성할 때 필요하므로 이 서비스 이름을 기록해 둡니다.
표시 이름: 이 인스턴스에 표시될 이름. 제안된 값은 amazonemrspark입니다.
인증서의 일반 이름: 클라이언트 플러그인에서 관리 서버에 연결하는 데 사용되는 인증서 내 CN 필드. 이 값은 플러그인용으로 생성된 TLS 인증서의 CN 필드와 일치해야 합니다.
참고
이 플러그인의 TLS 인증서는 Ranger Admin 서버의 트러스트 스토어에 등록되어 있어야 합니다. 자세한 내용은 Amazon EMR과의 Apache Ranger 통합을 위한 TLS 인증서 섹션을 참조하세요.
SparkSQL 정책 생성
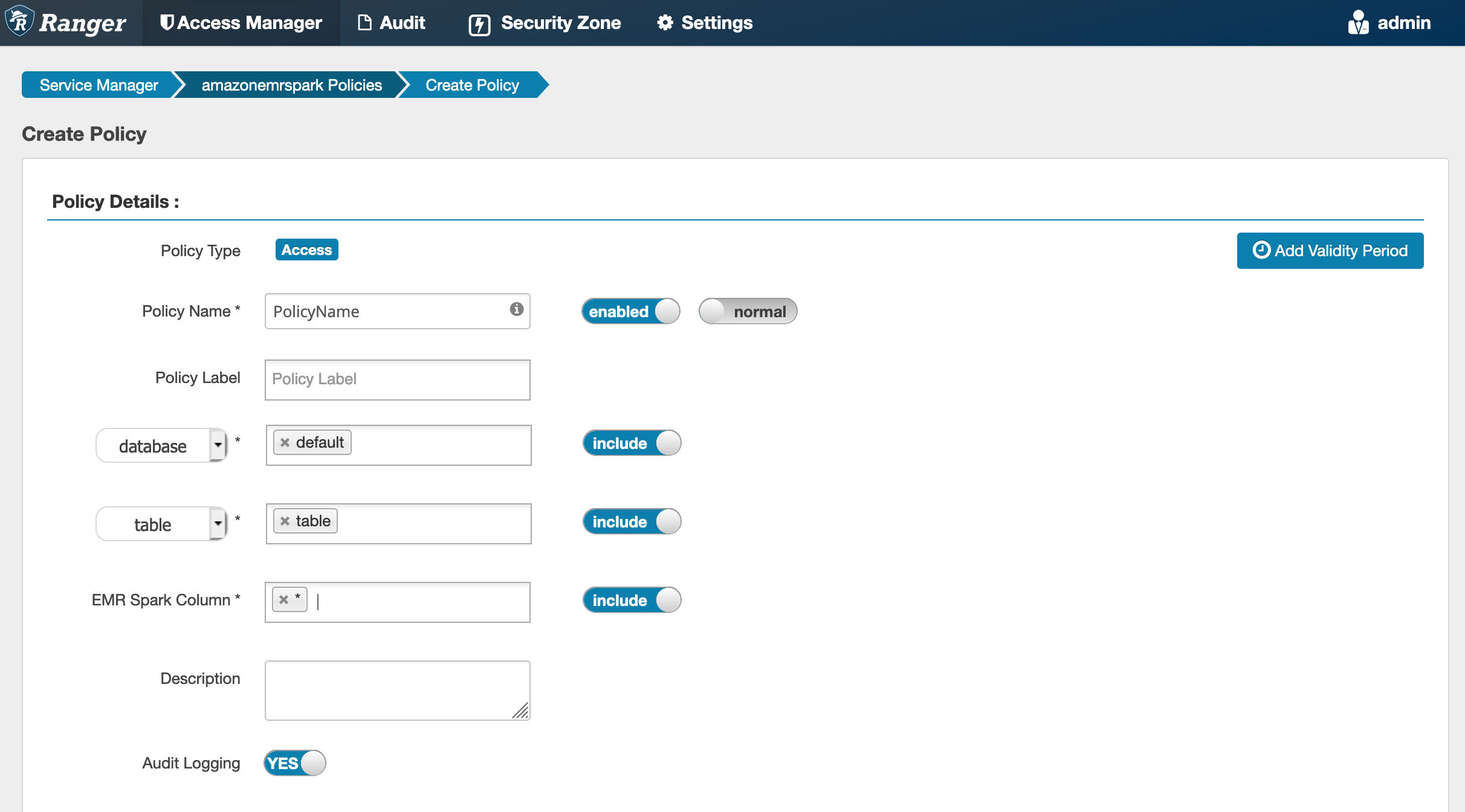
새 정책을 생성할 때 입력할 필드는 다음과 같습니다.
정책 이름: 이 정책의 이름입니다.
정책 레이블: 이 정책에 적용할 수 있는 레이블입니다.
데이터베이스: 이 정책이 적용되는 데이터베이스. 와일드카드 '*'는 모든 데이터베이스를 나타냅니다.
테이블: 이 정책이 적용되는 테이블입니다. 와일드카드 '*'는 모든 테이블을 나타냅니다.
EMR Spark 열: 이 정책이 적용되는 열입니다. 와일드카드 '*'는 모든 열을 나타냅니다.
설명: 이 정책에 대한 설명입니다.
사용자 및 그룹을 지정하려면 권한을 부여할 사용자 및 그룹을 아래에 입력합니다. 허용 조건 및 거부 조건에 대한 제외 항목을 지정할 수도 있습니다.
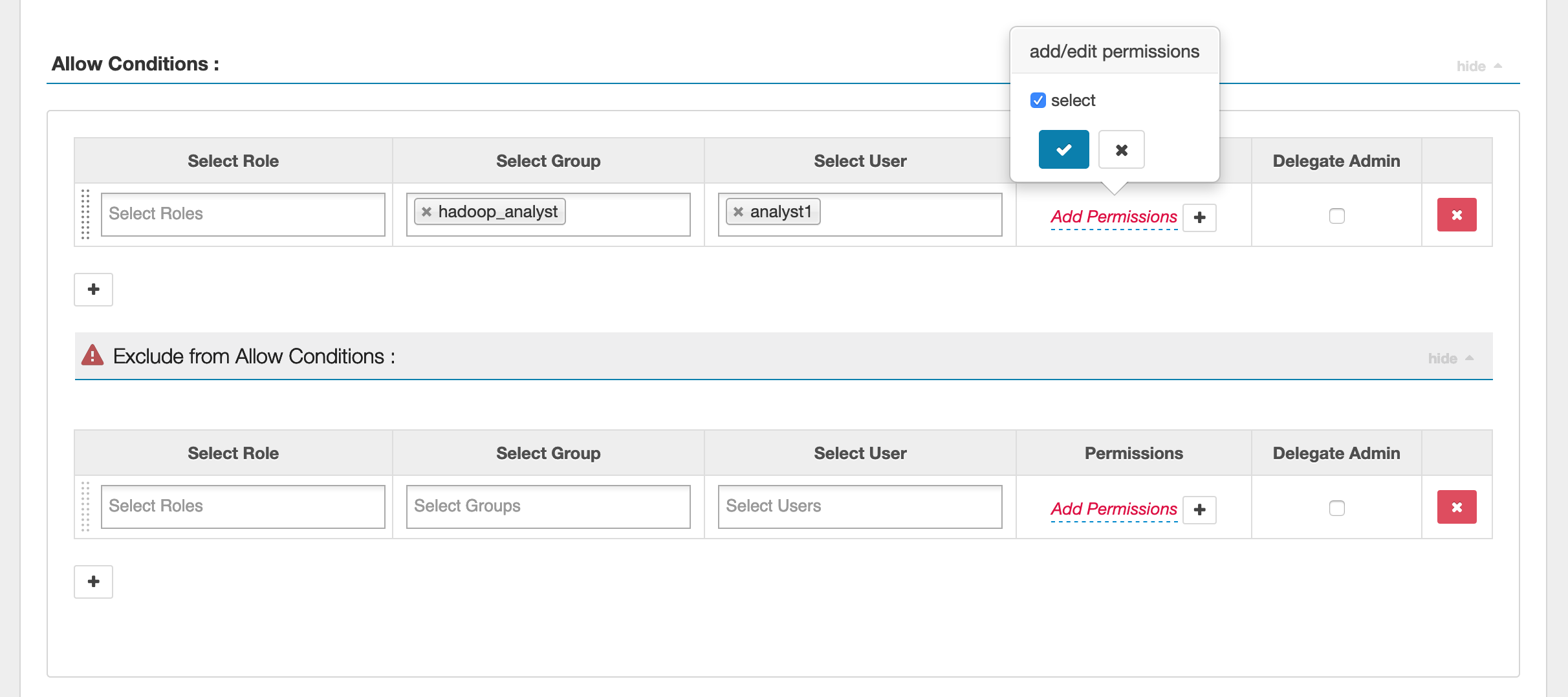
허용 및 거부 조건을 지정한 후 저장을 클릭합니다.
고려 사항
EMR 클러스터 내 각 노드는 포트 9083에서 프라이머리 노드에 연결할 수 있어야 합니다.
제한 사항
Apache Spark 플러그인의 현재 제한 사항은 다음과 같습니다.
-
Record Server는 항상 Amazon EMR 클러스터에서 실행되는 HMS에 연결됩니다. 필요한 경우 원격 모드에 연결하도록 HMS를 구성합니다. Apache Spark Hive-site.xml 구성 파일에 구성 값을 넣으면 안 됩니다.
-
CSV 또는 Avro에서 Spark 데이터 소스를 사용하여 생성한 테이블은 EMR RecordServer를 사용하여 읽을 수 없습니다. Hive를 사용하여 레코드를 통해 데이터를 생성하고 작성하며 읽습니다.
-
Delta Lake, Hudi 및 Iceberg 테이블은 지원되지 않습니다.
-
사용자는 기본 데이터베이스에 대한 액세스 권한이 있어야 합니다. Apache Spark의 요구 사항입니다.
-
Ranger Admin 서버는 자동 완성 기능을 지원하지 않습니다.
-
Amazon EMR용 SparkSQL 플러그인은 행 필터 또는 데이터 마스킹을 지원하지 않습니다.
-
Spark SQL에서 ALTER TABLE을 사용하는 경우 파티션 위치는 테이블 위치의 하위 디렉터리여야 합니다. 파티션 위치가 테이블 위치와 다른 파티션에 데이터를 삽입할 수 없습니다.
