As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como projetar seu esquema GraphQLO esquema GraphQL é a base de qualquer implementação de servidor de GraphQL. Cada API GraphQL é definida por um único esquema que contém tipos e campos que descrevem como os dados das solicitações serão preenchidos. Os dados que fluem pela sua API e as operações realizadas devem ser validados com base no esquema.
O sistema do tipo GraphQL descreve os recursos de um servidor de GraphQL e é usado para determinar se uma consulta é válida. Um sistema de tipo de servidor geralmente é chamado de esquema e pode consistir em diferentes tipos de objetos, escalares, entradas, entre outros. O GraphQL é declarativo e fortemente tipificado, o que significa que os tipos serão bem definidos no runtime e retornarão somente o que foi especificado.
AWS AppSync permite definir e configurar esquemas do GraphQL. A seção a seguir descreve como criar esquemas do GraphQL do zero usando AWS AppSync os serviços da.
Estruturar um esquema do GraphQL
Consulte a seção Schemas antes de continuar.
O GraphQL é uma ferramenta poderosa para implementar serviços de API. A descrição (em tradução livre) no site do GraphQL é a seguinte:
“O GraphQL é uma linguagem de consulta APIs e um tempo de execução para atender essas consultas com seus dados existentes. O GraphQL fornece uma descrição completa e compreensível dos dados em sua API, dá aos clientes o poder de pedir exatamente o que precisam e nada mais, facilita a evolução ao APIs longo do tempo e habilita ferramentas poderosas para desenvolvedores. “
Esta seção aborda a primeira parte da sua implementação do GraphQL, o esquema. De acordo com a citação acima, um esquema “fornece uma descrição completa e clara dos dados em sua API”. Em outras palavras, um esquema do GraphQL é uma representação textual dos dados, das operações e das relações entre eles referentes ao seu serviço. O esquema é considerado o principal ponto de entrada para a implementação do serviço do GraphQL. Não é de surpreender que muitas vezes seja uma das primeiras coisas que você faz em seu projeto. Consulte a seção Schemas antes de continuar.
Citando a seção Schemas, os esquemas do GraphQL são escritos em Schema Definition Language (SDL). O SDL é composto por tipos e campos com uma estrutura estabelecida:
-
Tipos: os tipos são como o GraphQL define a forma e o comportamento dos dados. O GraphQL é compatível com uma infinidade de tipos que serão explicados ainda nesta seção. Cada um dos tipos definidos em seu esquema terá um escopo próprio. Dentro do escopo, um ou mais campos vão apresentar um valor ou lógica que será usada em seu serviço do GraphQL. Os tipos têm muitas funções diferentes, sendo as mais comuns objetos ou escalares (tipos de valores primitivos).
-
Campos: os campos existem dentro do escopo de um tipo e contêm o valor solicitado do serviço do GraphQL. Eles são muito semelhantes às variáveis de outras linguagens de programação. A forma dos dados que você define em seus campos determinará como os dados são estruturados em uma request/response operação. Isso permite que os desenvolvedores prevejam o que será retornado sem saber como o back-end do serviço é implementado.
Os esquemas mais simples conterão três categorias de dados:
-
Raízes do esquema: as raízes definem os pontos de entrada do seu esquema. Elas apontam para os campos que realizarão alguma operação nos dados, como adicionar, excluir ou modificar algo.
-
Tipos: esses são tipos básicos usados para representar o formato dos dados. Eles são muito semelhantes a objetos ou representações abstratas de algo com características definidas. Por exemplo, você pode criar um objeto Person que represente uma pessoa em um banco de dados. As características de cada pessoa serão definidas dentro de Person como campos. Eles podem ser qualquer dado da pessoa, como o nome, a idade, o emprego, o endereço etc.
-
Tipos de objetos especiais: esses são os tipos que definem o comportamento das operações em seu esquema. Cada tipo de objeto especial é definido uma vez por esquema. Eles são colocados primeiro na raiz do esquema e, em seguida, definidos no corpo do esquema. Cada campo em um tipo de objeto especial define uma única operação a ser implementada pelo seu solucionador.
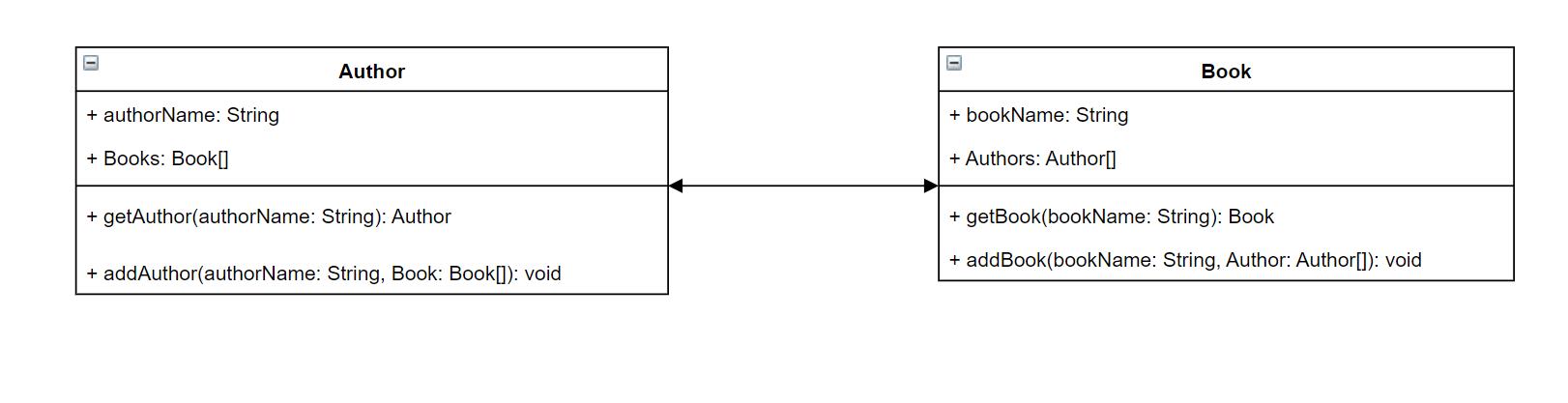
Para entender melhor, imagine que você esteja criando um serviço que armazena dados de autores de livros e suas obras. Cada autor tem um nome e uma série de livros escritos. Cada livro tem um nome e uma lista de autores associados. Além disso, queremos adicionar ou recuperar livros e autores. Uma representação UML simples desse relacionamento pode ser como esta:
No GraphQL, as entidades Author e Book representam dois tipos diferentes de objetos em seu esquema:
type Author {
}
type Book {
}
Author contém authorName e Books, enquanto Book contém bookName e Authors. Eles podem ser representados como os campos dentro do escopo de seus tipos:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
Como você pode ver, as representações de tipo estão muito próximas do diagrama. No entanto, os métodos são os pontos mais complexos. Eles serão colocados em um dos poucos tipos de objetos especiais como um campo. A categorização como objeto especial depende do comportamento dele. O GraphQL contém três tipos fundamentais de objetos especiais: consultas, mutações e assinaturas. Para obter mais informações, consulte Special objects.
Como getAuthor e getBook estão solicitando dados, eles serão colocados em um tipo de objeto especial de Query:
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
As operações são vinculadas à consulta, que por sua vez está vinculada ao esquema. Adicionar uma raiz de esquema definirá o tipo de objeto especial (neste caso, Query) como um dos seus pontos de entrada. Isso pode ser feito usando a palavra-chave schema:
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Analisando os últimos dois métodos, addAuthor e addBook estão adicionando informações ao seu banco de dados para que sejam definidos em um tipo de objeto especial Mutation. No entanto, na página Tipos, não é permitido usar entradas que fazem referência direta a objetos, porque são tipos de saída. Nesse caso, não podemos usar Author nem Book, então precisamos criar um tipo de entrada com os mesmos campos. Neste exemplo, adicionamos AuthorInput e BookInput, que aceitam os mesmos campos de seus respectivos tipos. Em seguida, criamos nossa mutação usando as entradas como nossos parâmetros:
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
Vamos analisar o que acabamos de fazer:
-
Criamos um esquema com os tipos Author e Book para representar nossas entidades.
-
Adicionamos os campos contendo as características de nossas entidades.
-
Adicionamos uma consulta para recuperar essas informações do banco de dados.
-
Adicionamos uma mutação para manipular dados no banco de dados.
-
Adicionamos tipos de entrada para substituir nossos parâmetros de objeto na mutação para cumprir as regras do GraphQL.
-
Adicionamos a consulta e a mutação ao nosso esquema raiz para que a implementação do GraphQL identifique a localização do tipo raiz.
Como você pode notar, o processo de criação de um esquema usa muitos conceitos da modelagem de dados (especialmente da modelagem de banco de dados) em geral. Podemos dizer que o esquema se ajusta à forma dos dados da fonte. Ele também serve como o modelo que o solucionador implementará. Nas seções a seguir, você aprenderá como criar um esquema usando várias ferramentas e AWS serviços suportados.
Os exemplos nas seções a seguir não devem ser executados em uma aplicação real. Eles apenas mostram os comandos para que você crie suas próprias aplicações.
Criar esquemas
Seu esquema estará em um arquivo chamadoschema.graphql. AWS AppSync permite que os usuários criem novos esquemas para seu APIs GraphQL usando vários métodos. Neste exemplo, criaremos uma API em branco junto com um esquema em branco.
- Console
-
-
Faça login no Console de gerenciamento da AWS e abra o AppSyncconsole.
-
No Painel, escolha Criar API.
-
Em Opções de API, escolha GraphQL APIs, Design from scratch e Next.
-
Para o nome da API, troque o nome pré-preenchido algo que seja necessário para a aplicação.
-
Para obter detalhes de contato, você pode inserir um ponto de contato para identificar um gerente para a API. Esse é um campo opcional.
-
Em Configuração da API privada, é possível habilitar os atributos da API privada. Uma API privada só pode ser acessada de um endpoint da VPC (VPCE) configurado. Para obter mais informações, consulte Privado APIs.
Não recomendamos habilitar esse atributo para este exemplo. Após analisar suas entradas, selecione Próximo.
-
Em Criar um tipo de GraphQL, você pode criar uma tabela do DynamoDB para usar como fonte de dados ou ignorar e fazer isso depois.
Para este exemplo, escolha Criar recursos do GraphQL mais tarde. Vamos criar um recurso em uma seção separada.
-
Revise suas entradas e selecione Criar API.
-
Você estará no painel da sua API específica. É possível identificar o nome da API na parte superior do painel. Se esse não for o caso, você pode selecionar APIsna barra lateral e escolher sua API no APIs painel.
-
Na barra lateral abaixo do nome da sua API, escolha Esquema.
-
Você pode configurar seu arquivo schema.graphql no editor de esquemas. Ele pode estar vazio ou preenchido com tipos gerados a partir de um modelo. À direita, você tem a seção Solucionadores para anexar solucionadores aos campos do esquema. Não examinaremos os solucionadores nesta seção.
- CLI
-
Ao usar a CLI, verifique se você tem as permissões certas para acessar e criar recursos no serviço. Considere definir políticas de privilégio mínimo para usuários não administradores que precisam acessar o serviço. Para obter mais informações sobre AWS AppSync políticas, consulte Gerenciamento de identidade e acesso para AWS AppSync.
Além disso, recomendamos primeiro ler a versão do console.
-
Caso ainda não tenha feito isso, instale e configure o AWS
CLI e adicione sua configuração.
-
Crie um objeto da API GraphQL executando o comando create-graphql-api.
Você precisará digitar dois parâmetros para esse comando específico:
-
O name da sua API.
-
O authentication-type, ou o tipo de credencial usado para acessar a API (IAM, OIDC etc.).
Outros parâmetros, como Region devem ser configurados, mas geralmente usam como padrão os valores de configuração da CLI.
Veja um exemplo de comando:
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
Uma saída será retornada na CLI. Veja um exemplo abaixo:
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
Esse é um comando opcional que carrega um esquema existente no serviço do AWS AppSync usando um blob Base64. Não usaremos esse comando para preservar este exemplo.
Execute o comando start-schema-creation.
Você precisará digitar dois parâmetros para esse comando específico:
-
Seu api-id da etapa anterior.
-
O esquema definition é um blob binário codificado com Base64.
Veja um exemplo de comando:
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
Uma saída será retornada:
{
"status": "PROCESSING"
}
Esse comando não retornará a saída final depois do processamento. Você deve usar um comando separado, get-schema-creation-status, para ver o resultado. Esses dois comandos são assíncronos, portanto, você pode verificar o status da saída mesmo durante a criação do esquema.
- CDK
-
Antes de usar o CDK, recomendamos revisar a documentação oficial do CDK junto com AWS AppSync a referência do CDK.
As etapas listadas abaixo mostram apenas um exemplo geral do trecho usado para adicionar um recurso específico. Isso não é uma solução funcional para seu código de produção. Também presumimos que você já tenha uma aplicação em funcionamento.
-
O ponto de partida do CDK é um pouco diferente. O ideal é que seu arquivo schema.graphql já tenha sido criado. Você só precisa criar um novo arquivo com a extensão .graphql. Ele pode ser um arquivo vazio.
-
Em geral, talvez seja necessário adicionar a diretiva de importação ao serviço que você está usando. Por exemplo, estas são as possíveis formas:
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
Para adicionar uma API GraphQL, seu arquivo de pilha precisa importar o serviço: AWS AppSync
import * as appsync from 'aws-cdk-lib/aws-appsync';
Isso significa que estamos importando todo o serviço com a palavra-chave appsync. Para usar isso em seu aplicativo, suas AWS AppSync construções usarão o formatoappsync.construct_name. Por exemplo, se quiséssemos criar uma API GraphQL, teríamos um new appsync.GraphqlApi(args_go_here). A etapa a seguir mostra isso.
-
A API mais básica do GraphQL incluirá um name para a API e o caminho do schema.
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
Vamos analisar o que esse trecho faz. Dentro do escopo da api, estamos criando uma nova API GraphQL chamando o appsync.GraphqlApi(scope: Construct, id:
string, props: GraphqlApiProps). O escopo é this, que se refere ao objeto atual. O id éAPI_ID, que será o nome do recurso da sua API GraphQL CloudFormation quando ela for criada. O GraphqlApiProps contém o name da sua API GraphQL e o schema. schemaIsso gerará um esquema (SchemaFile.fromAsset) pesquisando o caminho absoluto (__dirname) do .graphql arquivo (schema_name.graphql). Em um cenário real, seu arquivo de esquema provavelmente estará na aplicação do CDK.
Para usar as alterações feitas na sua API GraphQL, você precisará reimplantar a aplicação.
Adicionar tipos aos esquemas
Agora que você adicionou seu esquema, pode começar a adicionar os tipos de entrada e saída. Os tipos aqui não devem ser usados em código real; eles são apenas exemplos para ajudar você a entender o processo.
Primeiro, vamos criar um tipo de objeto. No código real, não é necessário começar com esses tipos. Você pode criar o tipo que preferir a qualquer momento, desde que siga as regras e a sintaxe do GraphQL.
As próximas seções usarão o editor de esquemas, portanto, mantenha-o aberto.
- Console
-
-
Você pode criar um tipo de objeto usando a palavra-chave type junto com o nome do tipo:
type Type_Name_Goes_Here {}
Dentro do escopo do tipo, você pode adicionar campos que representam as características do objeto:
type Type_Name_Goes_Here {
# Add fields here
}
Veja um exemplo abaixo:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Nesta etapa, adicionamos um tipo de objeto genérico com um campo obrigatório id armazenado como ID, um campo title armazenado como String, e um campo date armazenado como AWSDateTime. Para visualizar uma lista de tipos e campos e o que eles fazem, consulte Schemas. Para visualizar uma lista de escalares e o que eles fazem, consulte a Type reference.
- CLI
-
Recomendamos que seja feita a leitura da versão do console primeiro.
-
Você pode criar um tipo de objeto executando o comando create-type.
Você precisará inserir alguns parâmetros para esse comando específico:
-
O api-id da sua API.
-
A definition, ou o conteúdo do seu tipo. No exemplo do console, tínhamos:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
O format da sua entrada. Neste exemplo, usamos o SDL.
Veja um exemplo de comando:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
Uma saída será retornada na CLI. Veja um exemplo abaixo:
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
Nesta etapa, adicionamos um tipo de objeto genérico com um campo obrigatório id armazenado como ID, um campo title armazenado como String, e um campo date armazenado como AWSDateTime. Para visualizar uma lista de tipos e campos e o que eles fazem, consulte Schemas. Para visualizar uma lista de escalares e o que eles fazem, consulte Type reference.
Além disso, inserir a definição diretamente funciona para tipos menores, mas é inviável para adicionar tipos maiores ou vários tipos. Você pode adicionar tudo em um arquivo .graphql e depois transmiti-lo como a entrada.
- CDK
-
Antes de usar o CDK, recomendamos revisar a documentação oficial do CDK junto com AWS AppSync a referência do CDK.
As etapas listadas abaixo mostram apenas um exemplo geral do trecho usado para adicionar um recurso específico. Isso não é uma solução funcional para seu código de produção. Também presumimos que você já tenha uma aplicação em funcionamento.
Para adicionar um tipo, você precisa adicioná-lo ao seu arquivo .graphql. Por exemplo, o exemplo do console foi:
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Você pode adicionar seus tipos diretamente ao esquema, como qualquer outro arquivo.
Para usar as alterações feitas na sua API GraphQL, você precisará reimplantar a aplicação.
O tipo de objeto tem campos que são tipos escalares, como cadeias de caracteres e números inteiros. AWS AppSync também permite que você use tipos escalares aprimorados, como AWSDateTime adição aos escalares básicos do GraphQL. Qualquer campo que termine com um ponto de exclamação é um campo obrigatório.
O tipo de escalar ID é um identificador exclusivo que pode ser String ou Int. É possível controlar isso nos modelos de mapeamento do solucionador para atribuição automática.
Há semelhanças entre tipos de objetos especiais de Query e tipos de objetos “comuns”, como no exemplo acima, pois ambos usam a palavra-chave type e são considerados objetos. No entanto, para os tipos de objetos especiais (Query, Mutation eSubscription), o comportamento deles é muito diferente porque eles são expostos como pontos de entrada da sua API. Eles também priorizam a modelagem de operações em vez dos dados. Para obter mais informações, consulte The query and mutation types.
No tópico dos tipos de objetos especiais, a próxima etapa pode ser adicionar um ou mais deles para realizar operações nos dados modelados. Em um cenário real, todo esquema do GraphQL deve ter pelo menos um tipo de consulta-raiz para solicitar dados. Você pode pensar na consulta como um dos pontos de entrada (ou endpoints) do seu servidor do GraphQL. Vamos adicionar uma consulta como exemplo.
- Console
-
-
Para criar uma consulta, basta adicioná-la ao arquivo do esquema como qualquer outro tipo. Uma consulta exigiria um tipo de Query e uma entrada na raiz como esta:
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
Observe que Name_of_Query em um ambiente de produção simplesmente será chamado Query na maioria dos casos. Recomendamos manter esse valor baixo. Dentro do tipo de consulta, você pode adicionar campos. Cada campo executará uma operação na solicitação. Como resultado, a maioria desses campos, se não todos, serão anexados a um solucionador. No entanto, não vamos abordar esse assunto nesta seção. Em relação ao formato da operação do campo, ela pode ser como esta:
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
Veja um exemplo abaixo:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Nesta etapa, adicionamos um tipo de Query e o definimos na raiz do nosso schema. Nosso tipo de Query definiu um campo getObj que retorna uma lista de objetos Obj_Type_1. Esse Obj_Type_1 é o objeto da etapa anterior. No código de produção, suas operações de campo normalmente trabalharão com dados moldados por objetos como Obj_Type_1. Além disso, campos como getObj normalmente terão um solucionados para executar a lógica de negócios. Isso será abordado em outra seção.
Como observação adicional, adiciona AWS AppSync automaticamente uma raiz do esquema durante as exportações, então, tecnicamente, você não precisa adicioná-la diretamente ao esquema. Nosso serviço processará esquemas duplicados de maneira automática. Essa é uma prática recomendada.
- CLI
-
Recomendamos que seja feita a leitura da versão do console primeiro.
-
Crie um schema raiz com uma definição da query executando o comando create-type.
Você precisará inserir alguns parâmetros para esse comando específico:
-
O api-id da sua API.
-
A definition, ou o conteúdo do seu tipo. No exemplo do console, tínhamos:
schema {
query: Query
}
-
O format da sua entrada. Neste exemplo, usamos o SDL.
Veja um exemplo de comando:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
Uma saída será retornada na CLI. Veja um exemplo abaixo:
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
Se você tiver cometido um erro no comando create-type, poderá atualizar a raiz do esquema (ou qualquer tipo no esquema) executando o comando update-type. Neste exemplo, alteraremos temporariamente a raiz do esquema para conter uma definição de subscription.
Você precisará inserir alguns parâmetros para esse comando específico:
-
O api-id da sua API.
-
O type-name do seu tipo. No exemplo do console, tínhamos schema.
-
A definition, ou o conteúdo do seu tipo. No exemplo do console, tínhamos:
schema {
query: Query
}
O esquema após a adição de um subscription será semelhante a este:
schema {
query: Query
subscription: Subscription
}
-
O format da sua entrada. Neste exemplo, usamos o SDL.
Veja um exemplo de comando:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
Uma saída será retornada na CLI. Veja um exemplo abaixo:
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
Adicionar arquivos pré-formatados ainda funcionará neste exemplo.
-
Crie uma Query executando o comando create-type.
Você precisará inserir alguns parâmetros para esse comando específico:
-
O api-id da sua API.
-
A definition, ou o conteúdo do seu tipo. No exemplo do console, tínhamos:
type Query {
getObj: [Obj_Type_1]
}
-
O format da sua entrada. Neste exemplo, usamos o SDL.
Veja um exemplo de comando:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
Uma saída será retornada na CLI. Veja um exemplo abaixo:
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
Nesta etapa, adicionamos um tipo de Query e o definimos na raiz do seu schema. Nosso tipo de Query definiu um campo getObj que retornou uma lista de objetos Obj_Type_1.
Na query: Query do código-raiz do schema, a parte query: indica que uma consulta foi definida em seu esquema, enquanto a parte Query representa o nome real do objeto especial.
- CDK
-
Antes de usar o CDK, recomendamos revisar a documentação oficial do CDK junto com AWS AppSync a referência do CDK.
As etapas listadas abaixo mostram apenas um exemplo geral do trecho usado para adicionar um recurso específico. Isso não é uma solução funcional para seu código de produção. Também presumimos que você já tenha uma aplicação em funcionamento.
Você precisará adicionar sua consulta e a raiz do esquema ao arquivo do .graphql. Nosso exemplo se parece com o exemplo abaixo, mas considere substituí-lo pelo código do seu esquema real:
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Você pode adicionar seus tipos diretamente ao esquema, como qualquer outro arquivo.
A atualização da raiz do esquema é opcional. Nós a adicionamos a esse exemplo como uma prática recomendada.
Para usar as alterações feitas na sua API GraphQL, você precisará reimplantar a aplicação.
Mostramos um exemplo de criação de objetos comuns e objetos especiais (consultas). Também abordamos como eles se interconectam para descrever dados e operações. Pode haver esquemas apenas com a descrição dos dados e uma ou mais consultas. No entanto, gostaríamos de adicionar outra operação para incluir dados na fonte de dados. Adicionaremos outro tipo de objeto especial chamado Mutation que modifica os dados.
- Console
-
-
Uma mutação será chamada de Mutation. Como a Query, as operações de campo em Mutation descrevem uma operação e serão anexadas a um solucionador. Além disso, precisamos defini-lo na raiz do schema porque é um tipo de objeto especial. Veja um exemplo de mutação abaixo:
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
Uma mutação típica será listada na raiz como uma consulta. A mutação é definida usando a type palavra-chave junto com o nome. Name_of_Mutationnormalmente serão chamadosMutation, por isso recomendamos que continue assim. Cada campo também executará uma operação. Em relação ao formato da operação do campo, ela pode ser como esta:
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
Veja um exemplo abaixo:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
Nesta etapa, adicionamos um tipo de Mutation com um campo addObj. Vamos resumir o que esse campo faz:
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
O addObj usa o objeto Obj_Type_1 para realizar uma operação. Isso é evidente ao observar os campos, mas a sintaxe prova isso no tipo de retorno : Obj_Type_1. Em addObj, os campos id, title e date do objeto Obj_Type_1 como parâmetros. Como podemos notar, ela se parece muito com uma declaração de método. No entanto, ainda não descrevemos o comportamento do nosso método. Conforme mencionado anteriormente, o esquema só existe para definir quais serão os dados e as operações e não a forma como operam. A implementação da lógica de negócios real será abordada quando criarmos nossos primeiros solucionadores.
Depois de concluir o esquema, há uma opção para exportá-lo como um arquivo schema.graphql. No Editor de esquemas, você pode escolher Exportar esquema para fazer download do arquivo em um formato compatível.
Como observação adicional, adiciona AWS AppSync automaticamente uma raiz do esquema durante as exportações, então, tecnicamente, você não precisa adicioná-la diretamente ao esquema. Nosso serviço processará esquemas duplicados de maneira automática. Essa é uma prática recomendada.
- CLI
-
Recomendamos que seja feita a leitura da versão do console primeiro.
-
Atualize seu esquema-raiz executando o comando update-type.
Você precisará inserir alguns parâmetros para esse comando específico:
-
O api-id da sua API.
-
O type-name do seu tipo. No exemplo do console, tínhamos schema.
-
A definition, ou o conteúdo do seu tipo. No exemplo do console, tínhamos:
schema {
query: Query
mutation: Mutation
}
-
O format da sua entrada. Neste exemplo, usamos o SDL.
Veja um exemplo de comando:
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
Uma saída será retornada na CLI. Veja um exemplo abaixo:
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
Crie uma Mutation executando o comando create-type.
Você precisará inserir alguns parâmetros para esse comando específico:
-
O api-id da sua API.
-
A definition, ou o conteúdo do seu tipo. No exemplo do console, tínhamos
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
O format da sua entrada. Neste exemplo, usamos o SDL.
Veja um exemplo de comando:
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
Uma saída será retornada na CLI. Veja um exemplo abaixo:
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
Antes de usar o CDK, recomendamos revisar a documentação oficial do CDK junto com AWS AppSync a referência do CDK.
As etapas listadas abaixo mostram apenas um exemplo geral do trecho usado para adicionar um recurso específico. Isso não é uma solução funcional para seu código de produção. Também presumimos que você já tenha uma aplicação em funcionamento.
Você precisará adicionar sua consulta e a raiz do esquema ao arquivo do .graphql. Nosso exemplo se parece com o exemplo abaixo, mas considere substituí-lo pelo código do seu esquema real:
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
A atualização da raiz do esquema é opcional. Nós a adicionamos a esse exemplo como uma prática recomendada.
Para usar as alterações feitas na sua API GraphQL, você precisará reimplantar a aplicação.
Considerações opcionais: usar enumerados como status
Neste ponto, você já sabe como criar um esquema básico. No entanto, há muitos elementos que você pode adicionar para aumentar a funcionalidade do esquema. Uma coisa comum encontrada nas aplicações é o uso de enumerados como status. Você pode usar um enumerado para aplicar um valor específico de um conjunto de valores a ser escolhido quando chamado. Isso é bom para elementos que não mudarão drasticamente por longos períodos. Hipoteticamente falando, poderíamos adicionar um enumerado que retorna o código de status ou string na resposta.
Como exemplo, vamos supor que estamos criando uma aplicação de mídia social que armazena os dados de postagem de um usuário no back-end. Nosso esquema contém um tipo de Post que representa os dados de uma postagem individual:
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
Nossa Post conterá um único id, um title, uma date de postagem e um enumerado chamado de PostStatus, que representa o estado da postagem conforme ela é processada pela aplicação. Para nossas operações, teremos uma consulta que retornará todos os dados da postagem:
type Query {
getPosts: [Post]
}
Também teremos uma mutação que adiciona postagens à fonte de dados:
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
Analisando nosso esquema, o enumerado PostStatus pode ter vários status. É possível termos os três estados básicos chamados de success (postagem processada com sucesso), pending (postagem sendo processada) e error (postagem que não foi processada). Para adicionar o enumerado, podemos fazer o seguinte:
enum PostStatus {
success
pending
error
}
O esquema completo pode ser semelhante a este:
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
Se um usuário adicionar uma Post à aplicação, a operação addPost será chamada para processar esses dados. À medida que o solucionador anexado à addPost processa os dados, ele vai atualizar o poststatus continuamente com o status da operação. Quando consultado, a Post vai mostrar o status final dos dados. Aqui só descrevemos como queremos que os dados funcionem no esquema. Fazemos muitas suposições sobre a implementação de nossos solucionadores, que implementarão a lógica comercial real para lidar com os dados e atender à solicitação.
Considerações opcionais: assinaturas
As assinaturas em AWS AppSync são invocadas como resposta a uma mutação. Isso pode ser configurado com um tipo Subscription e diretiva @aws_subscribe() no esquema para indicar quais mutações invocam uma ou mais assinaturas. Consulte Real-time data para obter mais informações sobre como configurar assinaturas.
Considerações opcionais: relações e paginação
Suponha que você tenha um milhão de Posts armazenadas em uma tabela do DynamoDB e queira retornar alguns desses dados. No entanto, o exemplo de consulta fornecido acima retorna todas as postagens. Não é fácil buscar tudo isso sempre que fizer uma solicitação. O melhor é paginar todas elas. Faça as seguintes alterações ao esquema:
-
No campo getPosts, adicione dois argumentos de entrada: nextToken (iterador) e limit (limite de iteração).
-
Adicione um novo tipo de PostIterator contendo Posts (isso recupera a lista de objetos Post) e campos nextToken (iterador).
-
Altere getPosts para que retorne PostIterator, não uma lista de objetos Post.
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
O tipo PostIterator permite que você retorne parte da lista de objetos de Post e um nextToken para obter a próxima parte. Em PostIterator, há uma lista de itens da Post ([Post]) que é retornada com um token de paginação (nextToken). Em AWS AppSync, isso seria conectado ao Amazon DynamoDB por meio de um resolvedor e gerado automaticamente como um token criptografado. Isso converte o valor do argumento limit no parâmetro maxResults e o argumento nextToken no parâmetro exclusiveStartKey. Para ver exemplos e exemplos de modelos integrados no AWS AppSync console, consulte Referência do Resolver (JavaScript).