本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon Neptune 入门
Amazon Neptune 是一项完全托管式图形数据库服务,可扩展到处理数十亿个关系,并允许您以毫秒延迟查询它们,而这种容量的成本却很低。
如果您正在寻找有关 Neptune 的更多详细信息,请参阅Amazon Neptune 特征概述。
如果您已经了解图表,请跳至快速开始使用 CloudShell或将 Neptune 与图形笔记本结合使用。或者,如果您想立即创建 Neptune 数据库,请参阅使用创建 Amazon Neptune 集群 AWS CloudFormation。
否则,在开始之前,你可能想更多地了解图形数据库。
图形数据库关键概念
图形数据库经过优化,可存储和查询数据项之间的关系。
它们将数据项本身存储为图形的顶点,将它们之间的关系存储为边缘。每个边缘都有一种类型,并且从一个顶点(起点)指向另一个顶点(终点)。关系可以称为谓词,也可以称为边缘,顶点有时也被称为节点。在所谓的属性图中,顶点和边缘也可以具有与之关联的其它属性。
这是一张代表社交网络中朋友和爱好的小图形
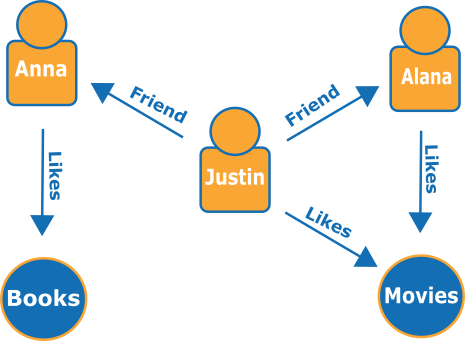
边缘显示为命名箭头,顶点代表它们连接的特定人物和爱好。
此图形的简单遍历可以告知您 Justin 朋友们的爱好。
为什么要使用图形数据库?
如果实体间的连接或关系是您正在尝试建模的数据的核心,那就适合使用图形数据库。
首先,可以很容易地将数据互连建模为图形,然后编写复杂的查询,以从图形中提取现实世界的信息。
使用关系数据库构建等效应用程序要求您创建许多包含多个外键的表,然后编写嵌套的 SQL 查询和复杂的联接。从编码的角度来看,这种方法不仅很快变得笨拙,而且随着数据量增加,其性能也会迅速下降。
相比之下,像 Neptune 这样的图形数据库可以查询数十亿个顶点之间的关系,而不会陷入困境。
您能用图形数据库做什么?
图形可以通过多种方式表示现实世界中实体的相互关系,包括操作、所有权、父母身份、购买选择、人际关系、家庭关系等。
以下是使用图形数据库的一些最常见领域:
-
知识图谱 – 知识图谱可让您组织和查询各种关联信息,以回答一般问题。使用知识图谱,您可以将主题信息添加到产品目录中,并对维基数据
中包含的不同信息进行建模。 要详细了解知识图谱的工作原理及其用途,请参阅 AWS上的知识图谱
。 -
身份图形 - 在图形数据库中,您可以存储诸如客户兴趣、朋友和购买历史记录等信息类别之间的关系,然后查询这些数据以提出个性化和相关的推荐。
例如,您可以使用图形数据库,根据关注相同运动内容且具有类似购买历史记录的其他人购买的产品,向用户提供产品推荐。或者,您可以识别有共同好友但还不认识对方的人员,然后提供好友推荐。
这种图形称为身份图形,广泛用于个性化与用户之间的互动。要了解更多信息,请参阅 AWS上的身份图形
。要开始构建自己的身份图形,您可以从使用 Amazon Neptune 的身份图形 示例开始。 -
欺诈图形 - 这是图形数据库的常用用途。它们可以帮助您跟踪信用卡购买和购买地点,以发现不寻常的使用情况,或者检测购买者正在尝试使用与已知欺诈案件中相同的电子邮件地址和信用卡。这些图形可以让您检查与个人电子邮件地址关联的多个人,或者多个位于不同物理位置但共享同一 IP 地址的人。
请考虑以下图形。它显示了三个人员之间的关系以及他们的身份相关信息。每个人员都有一个地址、一个银行账户和一个身份证号。但是,我们可以看到,Matt 和 Justin 共享同一身份证号,这不正常,并表示可能其中一个人进行了诈骗。对欺诈图形的查询可以揭示此类联系,以便对其进行审查。
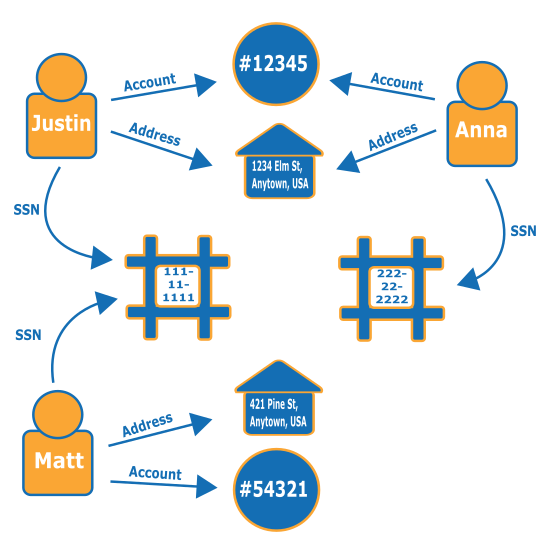
要了解有关欺诈图形及其使用位置的更多信息,请参阅 AWS上的欺诈图形
。 -
社交网络 – 使用图形数据库的首要也是最常见的领域之一是社交网络应用程序。
例如,假设您要构建一个馈入网站的社交媒体源。您可以轻松地使用后端的图形数据库向用户提供结果,这些结果反映了来自用户的家人、朋友、用户“喜欢”其动态的人以及住在其身边的人的最新动态。
行车路线 – 根据当前的路况和典型的路况模式,图形可以帮助找到从起点到目的地的最佳路线。
物流 – 图形可以帮助确定使用提供的运输和配送资源以满足客户要求的最有效方式。
诊断 - 图形可以表示复杂的诊断树,可以对这些树进行查询以确定观察到的问题和故障的来源。
科学研究 – 借助图形数据库,您可以构建应用程序,以使用静态加密来存储和浏览科学数据,甚至敏感的医疗信息。例如,您可以存储疾病与基因相互作用的模型。您可以在蛋白质通路中寻找图形模式,以找到可能与疾病相关的其他基因。您可以将化合物建模为图形,并查询分子结构中的模式。您可以关联不同系统内医疗记录中的患者数据。您可以按主题组织研究出版物,以便快速找到相关信息。
监管规则 - 您可以将复杂的监管要求存储为图形,并对其进行查询,以发现它们可能适用于您的日常业务运营的情况。
-
网络拓扑和事件 - 图形数据库可以帮助您管理和保护 IT 网络。将网络拓扑存储为图形时,还可以在网络上存储和处理许多不同类型的事件。您可以回答诸如有多少台主机在运行给定应用程序之类的问题。您可以查询可能显示给定主机已被恶意程序入侵的模式,并查询连接数据,以帮助将该程序追踪到下载该程序的原始主机。
如何查询图形?
Neptune 支持三种特殊用途的查询语言,它们专为查询不同类型的图形数据而设计。您可以使用以下语言来添加、修改、删除和查询 Neptune 图形数据库中的数据:
-
Gremlin 是用于属性图的图形遍历语言。Gremlin 中的查询是由离散步骤组成的遍历,每个步骤都沿着一个边缘到达一个节点。有关更多信息,请参阅 Apache
上的 Gremlin 文档 TinkerPop。 Gremlin 的 Neptune 实现与其他实现有一些区别,尤其是在你使用 Gremlin-Groovy (Gremlin 查询作为序列化文本发送)时。有关更多信息,请参阅 Amazon Neptune 中的 Gremlin 标准合规性。
-
openCypher – openCypher 是一种用于属性图的声明式查询语言,最初由 Neo4j 开发,然后于 2015 年开源,并在 Apache 2 开源许可证下为 openCypher
项目做出了贡献。有关语言规范,请参阅密码查询语言参考(版本 9) ,有关其它信息,请参阅密码风格指南 。 -
SPARQL 是一种用于 RDF
数据的声明性查询语言,基于由万维网联盟 (W3C) 标准化的图形模式匹配,并在 SPARQL 1.1 概述 和 SPARQL 1.1 查询语言规范 中描述)。有关 SPARQL 的 Neptune 实现的具体细节,请参阅Amazon Neptune 中的 SPARQL 标准合规性。
匹配 Gremlin 和 SPARQL 查询的示例
假设有如下的人员(节点)及其关系(边缘)的图形,您可以找出特定人员的“好友的好友”是谁,例如,Howard 的好友的好友。
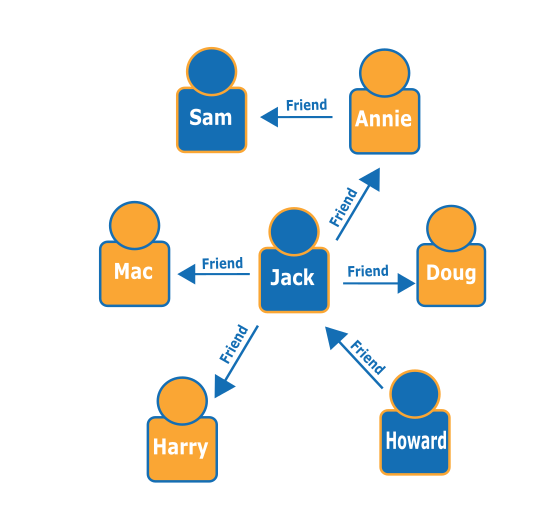
通过观察该图形,您可以看到 Howard 有一个好友 Jack,而 Jack 有四个好友:Annie、Harry、Doug 和 Mac。这是一个包含简单图形的简单示例,但这些类型的查询可以降低复杂性、数据集大小和结果大小。
此处是一个 Gremlin 遍历查询,该查询将返回 Howard 的好友的好友的姓名:
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
此处是一个 SPARQL 遍历查询,该查询将返回 Howard 的好友的好友的姓名:
prefix : <#> select ?names where { ?howard :name "Howard" . ?howard :friend/:friend/:name ?names . }
注意
任何资源描述框架 (RDF) 三角的各个部分都有与之关联的 URI。在上述示例中,URI 前缀经过故意缩短。
参加有关使用 Amazon Neptune 的在线课程
如果你喜欢通过视频学习,可以在在线技术讲座中 AWS 提供AWS 在线
Amazon Neptune 中的图形数据库简介、深入研究和演示
更深入地研究图形参考架构
当你思考图形数据库可以为你解决哪些问题以及如何解决这些问题时,最好的起点之一是 Nep tune 图形参考架构 GitHub 项目
在这里,您可以找到图形工作负载类型的详细描述,以及三个章节来帮助您设计有效的图形数据库:
数据模型和查询语言
– 本节将向您演练 Gremlin 和 SPARQL 之间的区别以及如何在它们之间进行选择。 图形数据建模
– 这是对如何做出图形数据建模决策的详尽讨论,包括使用 Gremlin 进行属性图建模和使用 SPARQL 进行 RDF 建模的详细演练。 将其它数据模型转换为图形模型
– 在这里,您可以了解如何将关系数据模型转换为图形模型。
还有三个章节将引导您完成使用 Neptune 的具体步骤:
从 Neptune VPC 外部的客户端连接到 Amazon Neptune
– 本节向您展示从数据库集群所在的 VPC 外部连接到 Neptune 的几个选项。 通过 Lambda 函数访问亚马逊 Neptune — 在这里,你将了解如何通过 AWS Lambda 函数
可靠地连接到 Neptune。 从 Amazon Kinesis Data Streams 写入 Amazon Neptune
– 本节可以帮助您使用 Neptune 处理高写入吞吐量的场景。
