本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
適用於 Apache Kafka 的 Amazon Athena 連接器可讓 Amazon Athena 能夠對 Apache Kafka 主題執行 SQL 查詢。使用此連接器可以在 Athena 中以資料表的形式檢視 Apache Kafka
此連接器不會使用 Glue Connections 集中 Glue 中的組態屬性。連線組態是透過 Lambda 完成。
先決條件
使用 Athena 主控台或 AWS Serverless Application Repository,將連接器部署到您的 AWS 帳戶 。如需詳細資訊,請參閱 建立資料來源連線 或 使用 AWS Serverless Application Repository 部署資料來源連接器。
限制
-
不支援寫入 DDL 操作。
-
任何相關的 Lambda 限制。如需詳細資訊,請參閱《AWS Lambda 開發人員指南》中的 Lambda 配額。
-
篩選條件中的日期和時間戳記資料類型必須轉換為適當的資料類型。
-
日期和時間戳記資料類型不受 CSV 檔案類型支援,且會被視為 varchar 值。
-
不支援映射至巢狀 JSON 欄位。連接器僅映射最上層欄位。
-
連接器不支援複雜類型。複雜類型會轉譯為字串。
-
若要擷取或使用複雜的 JSON 值,請使用 Athena 中提供的 JSON 相關函數。如需詳細資訊,請參閱從字串擷取 JSON 資料。
-
連接器不支援存取 Kafka 訊息中繼資料。
條款
-
中繼資料處理常式 - 從資料庫執行個體中擷取中繼資料的 Lambda 處理常式。
-
記錄處理常式 - 從資料庫執行個體中擷取資料記錄的 Lambda 處理常式。
-
複合處理常式 - 從資料庫執行個體中擷取中繼資料和資料記錄的 Lambda 處理常式。
-
Kafka 端點 – 與 Kafka 執行個體建立連線的文字字串。
叢集相容性
Kafka 連接器可搭配下列叢集類型使用。
-
獨立 Kafka – 直接連接至 Kafka (已進行身分驗證或未進行身分驗證)。
-
Confluent – 直接連線至 Confluent Kafka。如需有關搭配使用 Athena 與 Confluent Kafka 的資訊,請參閱 AWS 商業智慧部落格中的使用 Amazon Athena 在 Amazon QuickSight 中視覺化 Confluent 資料
。
連線至 Confluent
連線到 Confluent 需要以下步驟:
-
從 Confluent 產生一個 API 金鑰。
-
將 Confluent API 金鑰的使用者名稱和密碼儲存到 AWS Secrets Manager。
-
提供 Kafka 連接器中
secrets_manager_secret環境變數的密碼名稱。 -
請遵循本文件 設定 Kafka 連接器 一節中的步驟。
支援的身分驗證方法
連接器支援下列身分驗證方法。
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NO_AUTH
-
自我管理的 Kafka 和 Confluent 平台 – SSL、SASL/SCRAM、SASL/PLAINTEXT、NO_AUTH
-
自我管理的 Kafka 和 Confluent 雲端 – SASL/PLAIN
如需詳細資訊,請參閱設定 Athena Kafka 連接器的身分驗證。
支援的輸入資料格式
連接器支援以下輸入資料格式。
-
JSON
-
CSV
-
AVRO
-
PROTOBUF (通訊協定緩衝區)
參數
使用本節中的參數來設定 Athena Kafka 連接器。
-
auth_type – 指定叢集的身分驗證類型。連接器支援下列身分驗證類型:
-
NO_AUTH – 直接連接至 Kafka (例如,連接至透過無需使用身分驗證之 EC2 執行個體部署的 Kafka 叢集)。
-
SASL_SSL_PLAIN – 此方法使用
SASL_SSL安全通訊協定和PLAINSASL 機制。如需詳細資訊,請參閱 Apache Kafka 文件中的 SASL 組態。 -
SASL_PLAINTEXT_PLAIN – 此方法使用
SASL_PLAINTEXT安全通訊協定和PLAINSASL 機制。如需詳細資訊,請參閱 Apache Kafka 文件中的 SASL 組態。 -
SASL_SSL_SCRAM_SHA512 – 您可以使用此身分驗證類型來控制對 Apache Kafka 叢集的存取。此方法會將使用者名稱和密碼存放在 中 AWS Secrets Manager。秘密必須與 Kafka 叢集相關聯。如需詳細資訊,請參閱 Apache Kafka 文件中的使用 SASL/SCRAM 進行身分驗證
。 -
SASL_PLAINTEXT_SCRAM_SHA512 – 此方法使用
SASL_PLAINTEXT安全通訊協定和SCRAM_SHA512 SASL機制。此方法使用您的使用者名稱和密碼存放在 中 AWS Secrets Manager。如需詳細資訊,請參閱 Apache Kafka 文件中的 SASL 組態一節。 -
SSL – SSL 身分驗證使用金鑰存放區和信任存放區檔案來連接 Apache Kafka 叢集。您必須產生信任存放區和金鑰存放區檔案,將其上傳至 Amazon S3 儲存貯體,並在部署連接器時提供 Amazon S3 參考。金鑰存放區、信任存放區和 SSL 金鑰會存放在其中 AWS Secrets Manager。部署連接器時,您的用戶端必須提供 AWS 私密金鑰。如需詳細資訊,請參閱 Apache Kafka 文件中的使用 SSL 進行加密和身分驗證
。 如需詳細資訊,請參閱設定 Athena Kafka 連接器的身分驗證。
-
-
certificates_s3_reference – 包含憑證 (金鑰存放區和信任存放區檔案) 的 Amazon S3 位置。
-
disable_spill_encryption - (選用) 當設定為
True時,停用溢出加密。預設為False,因此溢出 S3 的資料會使用 AES-GCM 進行加密 — 使用隨機產生的金鑰或 KMS 來產生金鑰。停用溢出加密可以提高效能,尤其是如果溢出位置使用伺服器端加密。 -
kafka_endpoint – 提供給 Kafka 的端點詳細資訊。
-
schema_registry_url – 結構描述登錄檔的 URL 地址 (例如
http://schema-registry.example.org:8081)。適用於AVRO和PROTOBUF資料格式。Athena 僅支援 Confluent 結構描述登錄檔。 -
secrets_manager_secret – 用來儲存憑證的 AWS 祕密的名稱。
-
溢出參數 –Lambda 函數會將不適用記憶體的資料暫時存放 (「溢出」) 至 Amazon S3。由相同 Lambda 函數存取的所有資料庫執行個體溢出到相同的位置。請使用以下資料表中的參數來指定溢出位置。
參數 描述 spill_bucket必要。Lambda 函數可在其中溢出資料的 Amazon S3 儲存貯體的名稱。 spill_prefix必要。Lambda 函數可在其中溢出資料的溢出儲存貯體的字首。 spill_put_request_headers(選用) 用於溢出的 Amazon S3 putObject請求的請求標頭和值的 JSON 編碼映射 (例如,{"x-amz-server-side-encryption" : "AES256"})。如需了解其他可能的標頭,請參閱《Amazon Simple Storage Service API 參考》中的 PutObject。 -
Subnet IDs – 一個或多個子網路 ID,其對應於 Lambda 函數可用來存取資料來源的子網路。
-
公有 Kafka 叢集或標準 Confluent 雲端叢集 – 將連接器與具有 NAT 閘道的私有子網路建立關聯。
-
Confluent 雲端叢集與私有連線 – 將連接器與具有對 Confluent 雲端叢集的路由的私有子網路建立關聯。
-
對於 AWS Transit Gateway
,子網路必須位於連接至 Confluent 雲端使用的同一傳輸閘道的 VPC 中。 -
對於 VPC 對等連線
,子網路必須位於對等連線至 Confluent 雲端 VPC 的 VPC 中。 -
對於 AWS PrivateLink
,子網路必須位於已路由至連線至 Confluent 雲端的 VPC 端點的 VPC 中。
-
-
注意
如果您將連接器部署到 VPC 中以存取私有資源,並且還想要連接到可公開存取的服務 (例如 Confluent),則必須將連接器與具有 NAT 閘道的私有子網路建立關聯。如需詳細資訊,請參閱《Amazon VPC 使用者指南》中的 NAT 閘道。
支援的資料類型
下表顯示 Kafka 和 Apache Arrow 支援的相應資料類型。
| Kafka | Arrow |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP | 毫秒 |
| DATE | DAY |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOUBLE | FLOAT8 |
分割區和分隔
Kafka 主題會分為多個分割區。每個分割區都已排序。分割區中的每個訊息都有一個稱為位移的增量 ID。每個 Kafka 分割區可再細分為多個分隔,用於並行處理。資料在 Kafka 叢集中設定的保留期間內可供使用。
最佳實務
最佳實務是在您查詢 Athena 時使用述詞下推,如以下範例所示。
SELECT *
FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name"
WHERE integercol = 2147483647SELECT *
FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name"
WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'設定 Kafka 連接器
您必須先設定 Apache Kafka 叢集、使用 AWS Glue 結構描述登錄檔來定義結構描述,以及為連接器設定身分驗證,才能使用連接器。
使用 AWS Glue 結構描述登錄檔時,請注意下列事項:
-
請確定 AWS Glue 結構描述登錄檔的 Description (描述) 欄位中的文字包含字串
{AthenaFederationKafka}。您搭配 Amazon Athena Kafka 連接器使用的 AWS Glue 登錄檔需要此標記字串。 -
為了獲得最佳效能,請僅使用小寫作為資料庫名稱和資料表名稱。使用混合大小寫會導致連接器執行運算密集程度較高的不區分大小寫搜尋。
設定您的 Apache Kafka 環境和 AWS Glue 結構描述登錄檔
-
設定 Apache Kafka 環境。
-
將 JSON 格式的 Kafka 主題描述檔案 (即其結構描述) 上傳至 AWS Glue 結構描述登錄檔。如需詳細資訊,請參閱《 AWS Glue 開發人員指南》中的與 AWS Glue 結構描述登錄檔整合。
-
若要在結構描述登錄檔中定義AWS Glue結構描述時使用
AVRO或PROTOBUF資料格式:-
對於結構描述名稱,在與原始 相同的大小寫中輸入 Kafka 主題名稱。
-
針對資料格式,選擇 Apache Avro 或通訊協定緩衝區。
如需範例結構描述,請參閱下一節。
-
將結構描述上傳至 AWS Glue 結構描述登錄檔時,請使用本節中的範例格式。
JSON 類型結構描述範例
在下列範例中,要在結構描述登錄檔中建立的 AWS Glue 結構描述指定 json 做為 的值dataFormat,並datatypejson用於 topicName。
注意
topicName 的值應使用與 Kafka 中的主題名稱相同的大小寫。
{
"topicName": "datatypejson",
"message": {
"dataFormat": "json",
"fields": [
{
"name": "intcol",
"mapping": "intcol",
"type": "INTEGER"
},
{
"name": "varcharcol",
"mapping": "varcharcol",
"type": "VARCHAR"
},
{
"name": "booleancol",
"mapping": "booleancol",
"type": "BOOLEAN"
},
{
"name": "bigintcol",
"mapping": "bigintcol",
"type": "BIGINT"
},
{
"name": "doublecol",
"mapping": "doublecol",
"type": "DOUBLE"
},
{
"name": "smallintcol",
"mapping": "smallintcol",
"type": "SMALLINT"
},
{
"name": "tinyintcol",
"mapping": "tinyintcol",
"type": "TINYINT"
},
{
"name": "datecol",
"mapping": "datecol",
"type": "DATE",
"formatHint": "yyyy-MM-dd"
},
{
"name": "timestampcol",
"mapping": "timestampcol",
"type": "TIMESTAMP",
"formatHint": "yyyy-MM-dd HH:mm:ss.SSS"
}
]
}
}CSV 類型結構描述範例
在下列範例中,要在結構描述登錄檔中建立的 AWS Glue 結構描述指定 csv 做為 的值dataFormat,並datatypecsvbulk用於 topicName。topicName 的值應使用與 Kafka 中的主題名稱相同的大小寫。
{
"topicName": "datatypecsvbulk",
"message": {
"dataFormat": "csv",
"fields": [
{
"name": "intcol",
"type": "INTEGER",
"mapping": "0"
},
{
"name": "varcharcol",
"type": "VARCHAR",
"mapping": "1"
},
{
"name": "booleancol",
"type": "BOOLEAN",
"mapping": "2"
},
{
"name": "bigintcol",
"type": "BIGINT",
"mapping": "3"
},
{
"name": "doublecol",
"type": "DOUBLE",
"mapping": "4"
},
{
"name": "smallintcol",
"type": "SMALLINT",
"mapping": "5"
},
{
"name": "tinyintcol",
"type": "TINYINT",
"mapping": "6"
},
{
"name": "floatcol",
"type": "DOUBLE",
"mapping": "7"
}
]
}
}AVRO 類型結構描述範例
下列範例用於在結構描述登錄檔 AWS Glue 中建立以 AVRO 為基礎的結構描述。當您在結構描述登錄檔中定義 AWS Glue 結構描述時,對於結構描述名稱,您可以在與原始 相同的大小寫中輸入 Kafka 主題名稱,對於資料格式,您可以選擇 Apache Avro。由於您直接在登錄檔中指定此資訊,因此不需要 dataformat和 topicName 欄位。
{
"type": "record",
"name": "avrotest",
"namespace": "example.com",
"fields": [{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
]
}PROTOBUF 類型結構描述範例
下列範例用於在結構描述登錄檔中建立以 PROTOBUF 為基礎的 AWS Glue 結構描述。當您在 AWS Glue 結構描述登錄檔中定義結構描述時,對於結構描述名稱,您可以在與原始名稱相同的大小寫中輸入 Kafka 主題名稱,對於資料格式,您可以選擇通訊協定緩衝區。由於您直接在登錄檔中指定此資訊,因此不需要 dataformat和 topicName 欄位。第一行將結構描述定義為 PROTOBUF。
syntax = "proto3"; message protobuftest { string name = 1; int64 calories = 2; string colour = 3; }
如需在結構描述登錄檔中 AWS Glue 新增登錄檔和結構描述的詳細資訊,請參閱 AWS Glue 文件中的結構描述登錄檔入門。
設定 Athena Kafka 連接器的身分驗證
您可以使用各種方法對 Apache Kafka 叢集進行身分驗證,包括 SSL、SASL/SCRAM、SASL/PLAIN 和 SASL/PLAINTEXT。
下表顯示了連接器的身分驗證類型,以及每種連接器的安全通訊協定和 SASL 機制。如需有關詳細資訊,請參閱 Apache Kafka 文件的安全性
| auth_type | security.protocol | sasl.mechanism | 叢集類型相容性 |
|---|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
|
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
|
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
|
SASL_PLAINTEXT_SCRAM_SHA512 |
SASL_PLAINTEXT |
SCRAM-SHA-512 |
|
SSL |
SSL |
N/A |
|
SSL
如果叢集經過 SSL 身分驗證,您必須產生信任存放區和金鑰存放區檔案,並將其上傳到 Amazon S3 儲存貯體。部署連接器時,您必須提供此 Amazon S3 參考。金鑰存放區、信任存放區和 SSL 金鑰會儲存在 AWS Secrets Manager中。部署連接器時,您會提供 AWS 私密金鑰。
如需有關在 Secrets Manager 中建立祕密的詳細資訊,請參閱建立 AWS Secrets Manager 祕密。
若要使用此身分驗證類型,請設定環境變數,如下表所示。
| 參數 | Value |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
包含憑證的 Amazon S3 位置。 |
secrets_manager_secret |
AWS 私密金鑰的名稱。 |
在 Secrets Manager 中建立祕密之後,您可以在 Secrets Manager 主控台中進行檢視。
若要檢視 Secrets Manager 中的祕密
前往以下位置開啟機密管理員控制台:https://console.aws.amazon.com/secretsmanager/
。 -
在導覽窗格中,選擇 Secrets (祕密)。
-
在 Secrets (祕密) 頁面中,選擇祕密的連結。
-
在祕密的詳細資訊頁面上,選擇 Retrieve secret value (擷取祕密值)。
下圖顯示了具有三個金鑰/值對的祕密範例:
keystore_password、truststore_password和ssl_key_password。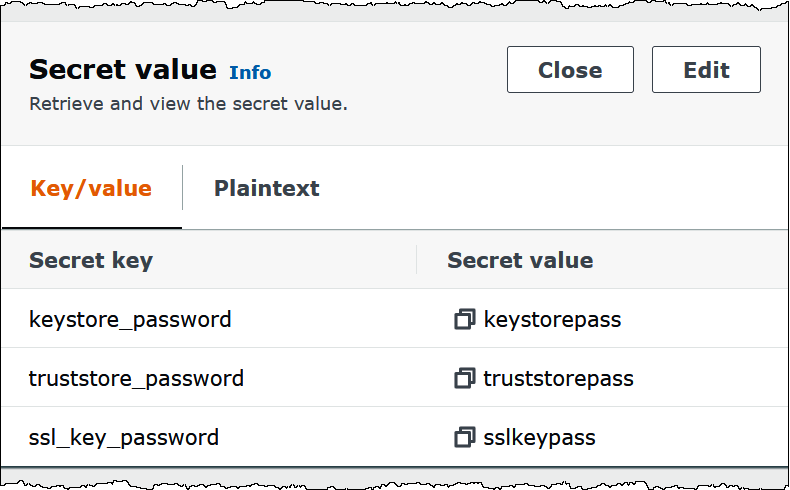
如需有關使用 SSL with Kafka 的詳細資訊,請參閱 Apache Kafka 文件中的使用 SSL 進行加密和身分驗證
SASL/SCRAM
如果您的叢集使用 SCRAM 身分驗證,則請在部署連接器時提供與叢集相關聯的 Secrets Manager 金鑰。使用者的 AWS 憑證 (祕密金鑰和存取金鑰) 可用於向叢集進行身分驗證。
設定環境變數,如下表所示。
| 參數 | Value |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
AWS 私密金鑰的名稱。 |
下圖顯示了 Secrets Manager 主控台中含有兩個金鑰/值對的祕密範例:一個用於 username,另一個用於 password。
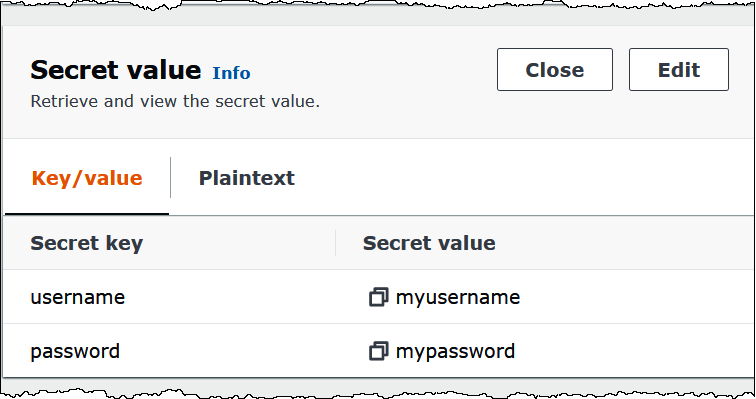
如需有關使用 SASL/SCRAM with Kafka 的詳細資訊,請參閱 Apache Kafka 文件中的使用 SASL/SCRAM 進行身分驗證
授權資訊
使用此連接器,即表示您確認已包含第三方元件,可在此連接器的 pom.xml
其他資源
如需此連接器的其他資訊,請造訪 GitHub.com 上的相應網站
