本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 Amazon EMR 中使用 Zeppelin 的 Flink 作業
簡介
Amazon EMR 6.10.0 版及更高版本支援與 Apache Flink 的 Apache Zeppelin 整合。您可以透過 Zeppelin 筆記本以互動方式提交 Flink 作業。使用 Flink 解譯器,您可以執行 Flink 查詢、定義 Flink 串流和批次作業,以及在 Zeppelin 筆記本內視覺化輸出。Flink 解譯器建置在 Flink REST API 之上。這可讓您從 Zeppelin 環境中存取和操作 Flink 作業,以執行即時資料處理和分析。
Flink 解譯器中有四個子解譯器。它們有不同的用途,但都在 JVM 中,並共用相同的 Flink 預先設定的進入點 (ExecutionEnviroment、StreamExecutionEnvironment、BatchTableEnvironment、StreamTableEnvironment)。解譯器如下:
-
%flink– 建立ExecutionEnvironment、StreamExecutionEnvironment、BatchTableEnvironment、StreamTableEnvironment,並提供 Scala 環境 -
%flink.pyflink– 提供 Python 環境 -
%flink.ssql– 提供串流 SQL 環境 -
%flink.bsql– 提供批次 SQL 環境
先決條件
-
使用 Amazon EMR 6.10.0 及更高版本建立的叢集支援 Zeppelin 與 Flink 整合。
-
若要根據這些步驟的需要檢視 EMR 叢集上託管的 Web 介面,您必須設定 SSH 通道以允許傳入存取。如需詳細資訊,請參閱設定代理設定以檢視主節點上託管的網站。
在 EMR 叢集上設定 Zeppelin-Flink
使用下列步驟將 Apache Zeppelin 上的 Apache Flink 設定為在 EMR 叢集上執行:
-
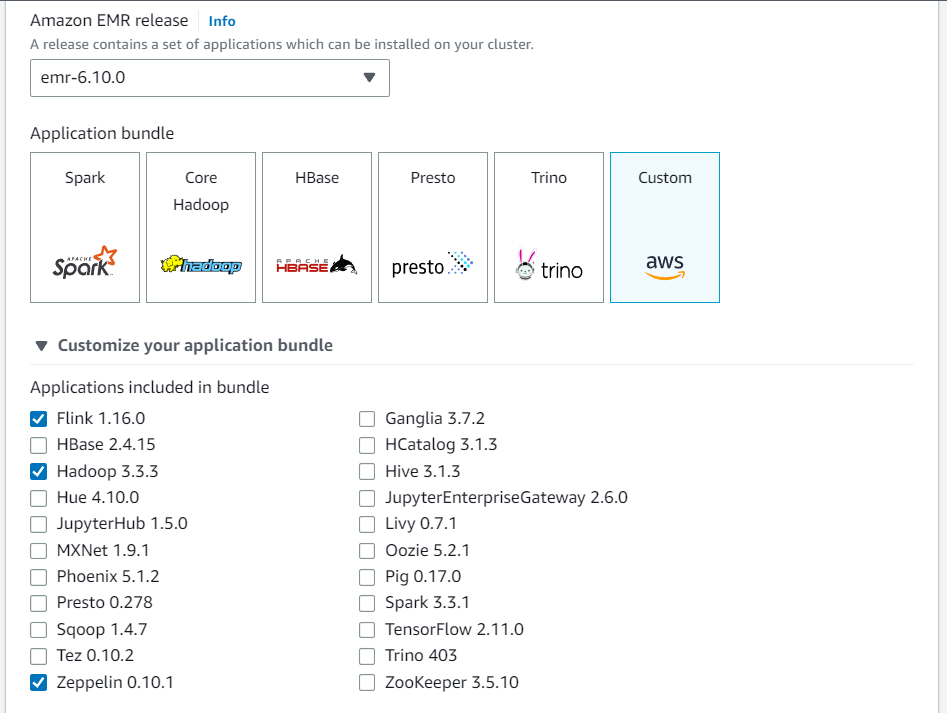
從 Amazon EMR 主控台建立新叢集。針對 Amazon EMR 發行版本選擇 emr-6.10.0 版或更高版本。然後,選擇使用「自訂」選項自訂您的應用程式套件。在您的套件中至少包含 Flink、Hadoop 和 Zeppelin。
-
使用您喜歡的設定建立叢集的其餘部分。
-
叢集執行後,在主控台中選取叢集以查看詳細資訊,並開啟「應用程式」標籤。從「應用程式使用者介面」區段中選取 Zeppelin,以開啟 Zeppelin Web 介面。請確保您已使用主節點的 SSH 通道和代理連線設定對 Zeppelin Web 介面的存取,如 先決條件 中所述。
-
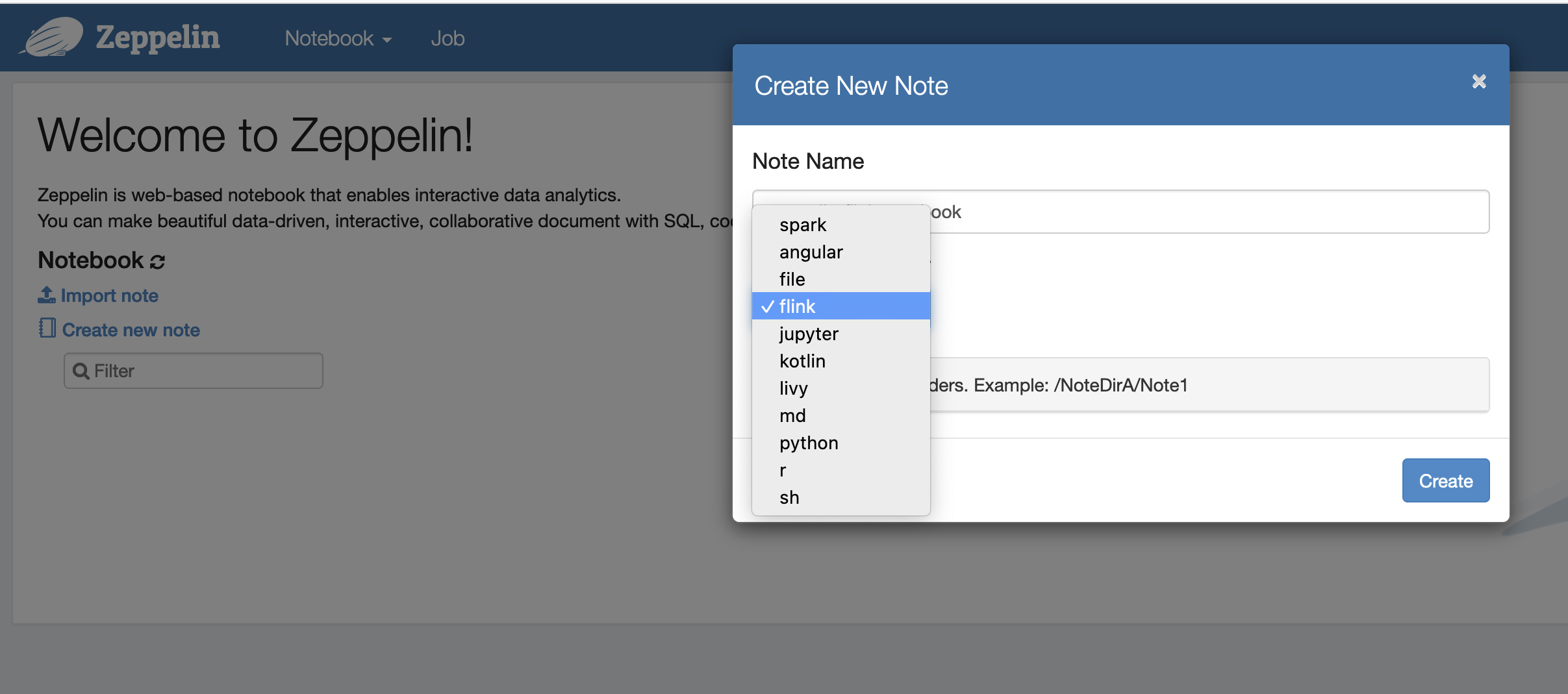
現在,您可以使用 Flink 作為預設解譯器在 Zeppelin 筆記本中建立新筆記。
-
請參閱下列程式碼範例,這些範例示範了如何從 Zeppelin 筆記本執行 Flink 作業。
在 EMR 叢集上使用 Zeppelin-Flink 執行 Flink 作業
-
範例 1. Flink Scala
a) 批次 WordCount 範例 (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) 串流 WordCount 範例 (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()
-
範例 2. Flink 串流 SQL
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;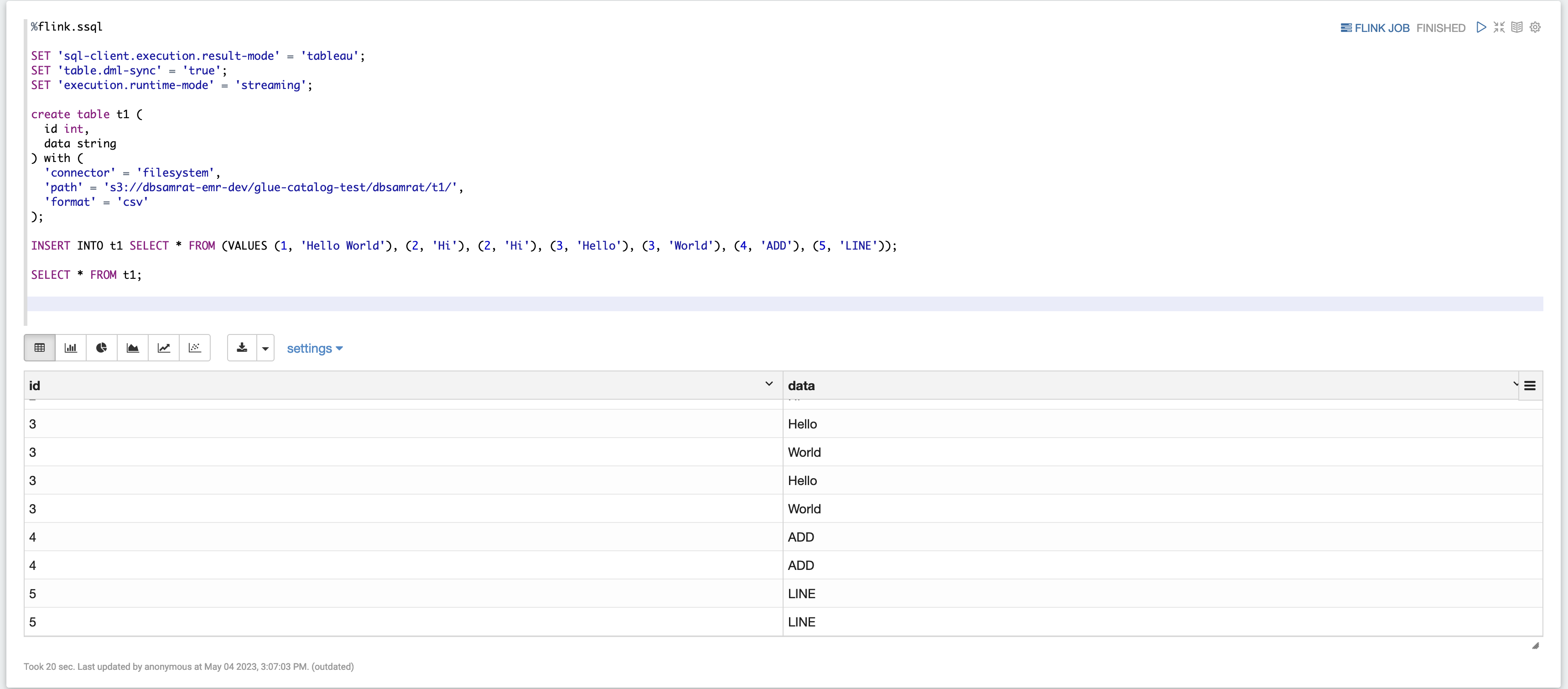
-
範例 3,Pyflink。請注意,您必須將自己的名為 的範例文字檔案上傳至 S3
word.txt儲存貯體。%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
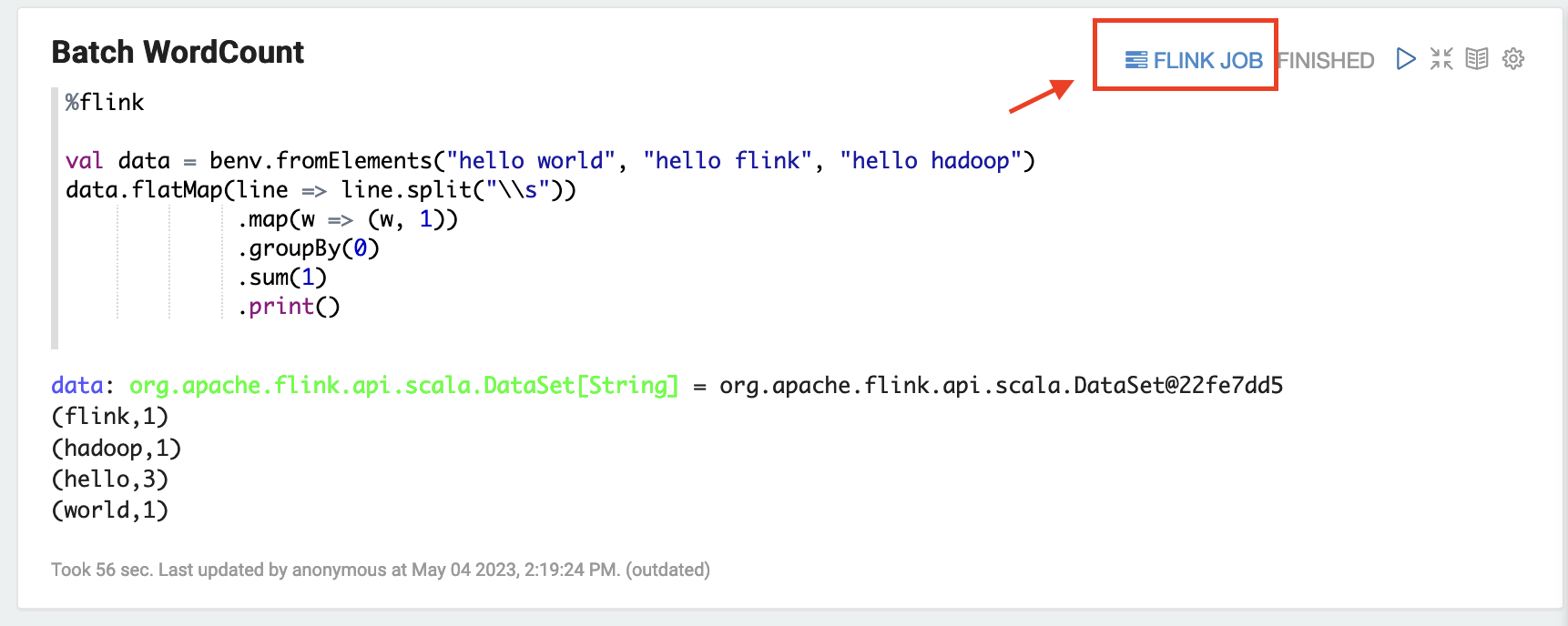
在 Zeppelin UI 中,選擇 FLINK JOB 以存取和檢視 Flink Web UI。
-
選擇 FLINK JOB 會路由至您瀏覽器的另一個標籤中的 Flink Web 主控台。